






文章目录
- 一些联邦学习论文阅读
- DEPTHFL: DEPTHWISE FEDERATED LEARNING FOR HETEROGENEOUS CLIENTS
- EFFICIENT SPLIT-MIX FEDERATED LEARNING FOR ON-DEMAND AND IN-SITU CUSTOMIZATION
- HeteroFL: Computation and Communication Efficient Federated Learning for Heterogeneous Clients
- 几篇Client选择
- Fair Resource Allocation In Federated Learning
- Client Selection in Federated Learning: Convergence Analysis and Power-of-Choice Selection Strategies
- Diverse Client Selection Federated Learning via Submodular Maximization
- FedPAQ: A communication-efficient federated learning method with periodic averaging and quantization
- 自己想法
- 几篇Client聚类---->偏向于数据异构
一些联邦学习论文阅读
DEPTHFL: DEPTHWISE FEDERATED LEARNING FOR HETEROGENEOUS CLIENTS
技术点
主要创新:深度缩放+自我蒸馏(self distillation)
后续又在FedDyn结构上应用DepthFL,在资源异构、数据异构的双重易构背景下进行实验
额外收获
同样思路的框架:HeteroFL,FjoRD,Split-Mix,InclusiveFL
开山鼻祖:HeteroFL
知识背景
自我蒸馏
自我蒸馏是一种通过使用同一模型的不同层之间的知识传递来提升模型性能的技术
自我蒸馏是通过将模型的高层输出用作目标来训练低层网络,以使低层网络学习从高层网络中提取的更加抽象和有用的特征。本文的使用方式相反,从低层网络中蒸馏出有用的信息给高层网络
通道裁剪与深度裁剪
通道裁剪:对所有层剪枝一些通道
深度裁剪:剪枝全局模型的一个或多个最高层
DSN网络
DSN的核心思想是在神经网络的中间层添加多个辅助分类器,这些分类器与最终输出的主分类器共同组成网络的结构
DSN通过在网络的不同层级上添加辅助分类器来提供额外的监督。这些辅助分类器在训练过程中与主分类器一起进行反向传播,并为中间层的特征提供额外的梯度信号
设计原因
总体思路
HeteroFL通过修剪通道(即基于宽度的缩放)来将本地模型创建为全局模型的子集,但是通过修剪通道(即基于宽度的缩放)来将本地模型创建为全局模型的子集,导致通道参数不匹配,精度较低,因此选择深度缩放
单纯使用深度缩放存在的问题:
算力大:网络模型更深
算力小:网络模型浅
算力大,数据量大√;算力大,数据量小×
为解决分配较大模型,但是数据集太少的问题,这种情况下的效果会很差—>对每个C的模型的分类器之间,应用自我蒸馏
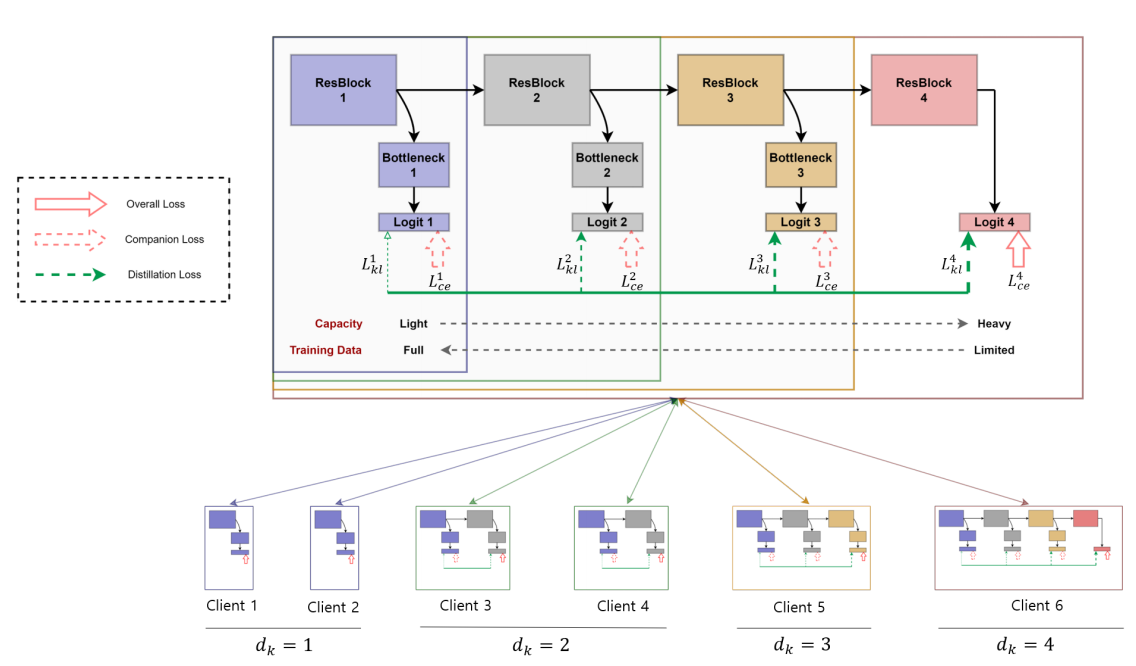
模型设计---->为模型按照深度分割服务
深度裁剪的时候,裁剪后的模型,由于最高层完全被剪,需要额外的瓶颈层(bottleneck layer)构成独立的分类器
这个要求,需要全局模型应该在不同的深度上有不同的分类器,满足这种要求的网络–>深度监督网络DSN
聚合方式
将相同深度的局部模型参数聚合在一起,最终聚合的结果是:靠近输入的浅层聚集了大量的局部模型参数,而靠近输出的深层聚集了少量的局部模型参数
回答问题
1.如何定义算力?
没讲,直接根据模型参数大小自己划的
2.如何进行模型缩放?
直接切深度,针对切完深度后的模型有效性,采用的自我蒸馏和DSN是本文的创新点
3.如何聚合?
简单每层聚每层的
EFFICIENT SPLIT-MIX FEDERATED LEARNING FOR ON-DEMAND AND IN-SITU CUSTOMIZATION
额外收获
开山鼻祖:HeteroFL
设计原因
设计初衷

出发点:
在资源不受限的情况下,模型确实越大越好
在资源受限情况下,在小数据集上训练大模型效果很差,需要进行模型定制
算法流程
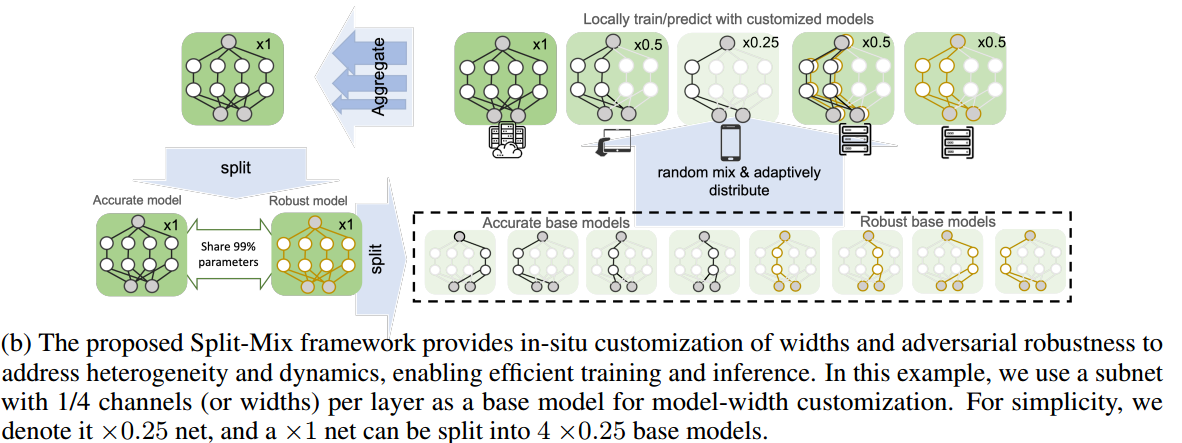
- 根据模型宽度和鲁棒性水平将大型模型中的完整知识分成几个小的基本子网络(分片)
- 在所有客户端上训练每个子网络
- 根据客户端算力,组合不同的子网络
HeteroFL: Computation and Communication Efficient Federated Learning for Heterogeneous Clients
ICLR/2021 引用数:219
代码:https://github.com/diaoenmao/HeteroFL-Computation-and-Communication-Efficient-Federated-Learning-for-Heterogeneous-Clients
技术点
通道裁剪+静态批处理+类似于dropout的缩放小设计
一些收获
资源异构:不同算力,不同通信能力
提到这种方式的一点局限:局部和全局模型体系结构也在同一个模型类中
系统设计
总体思想
改变隐藏层通道的宽度


静态批处理设计原因
深度学习采用批处理归一化(Batch Normalization, BN)来促进和稳定优化---->
FedAvg没用这个方法,因为BN需要对每个隐藏层的表示进行估计,通信成本大,还会隐私泄露---->
提出静态批处理规范化(sBN),只规范化批数据,不对隐藏层的表示进行估计
SCALER设计原因
局部模型参数会偏离不同的尺度,为了在推理阶段直接使用完整的模型---->dropout
dropout---->类似于切掉部分网络
HeteroFL已经切掉了部分网络---->为了在推理阶段直接使用完整的模型---->
在参数层之后和sBN层激活层之前附加了一个Scaler模块,表示一个缩放---->
这样聚合时就无需进行缩放,直接聚合
回答问题
1.如何定义算力?
没讲,直接根据模型参数大小自己划分
2.如何进行模型缩放?
隐藏层的通道裁剪
3.如何聚合?
简单各自聚合各自的

每个参数,将从其分配的参数矩阵包含该参数的那些客户端中,取平均值
**小细节:**为每个复杂度的网络,定义了一个固定模型
几篇Client选择
Fair Resource Allocation In Federated Learning
使局部损失大的参与者权重更高,降低准确率分布方差,使模型性能更均匀分布,实现联邦学习公平性
Client Selection in Federated Learning: Convergence Analysis and Power-of-Choice Selection Strategies
选择具有较高局部损失的客户端可以实现更快的收敛,和lazy聚合比较类似
Diverse Client Selection Federated Learning via Submodular Maximization
通过子模最大化来选择携带代表性梯度信息的客户端

FedPAQ: A communication-efficient federated learning method with periodic averaging and quantization
周期性上传+每一轮随机选择客户端+量化
自己想法
结合上文的,资源易构情况下,数据量大的客户端,其loss是否更有价值?
几篇Client聚类---->偏向于数据异构
聚类目的:在非IID数据中找到IID的客户端组成集群,针对集群进行聚合和训练
An Efficient Framework for Clustered Federated Learning
假设客户端被划分到不同的集群中,为每个集群训练模型
主要特性:迭代式聚类/簇间共享
主要挑战:
1.识别每个集群的客户端成员
2.在分布式设置中优化每个集群模型
提出IFCA,估计聚类身份和最小化损失函数之间交替
- 每一轮,客户端要计算局部损失和自己的身份值
- 客户端根据身份值来分别聚合
初始化定义簇个数K,每个簇内的节点都共享一组平均参数
每一轮迭代,重新计算每个簇的簇心(平均值),计算每个点新的归属簇


Clustered Federated Learning: Model-Agnostic Distributed Multitask Optimization Under Privacy Constraints
TNNLS/2020
主要特性:迭代式聚类/簇间不共享















 4270
4270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









