







文章目录
精读笔记 - HeteroFL:Computation and Communication Efficient Federated Learning for Heterogeneous Clients
1. 基本信息
| 论文标题 | HeteroFL:Computation and Communication Efficient Federated Learning for Heterogeneous Clients |
|---|---|
| 论文作者 | Enmao Diao, Jie Ding, Vahid Tarokh |
| 科研机构 | Duke University, University of Minnesota-Twin Cities Minneapolis |
| 会议年份 | ICLR 2021 |
| 摘要概括 | 系统异质问题是当今联邦学习研究中一大挑战。此项工作作者提出了 HeteroFL 联邦学习训练框架。具体而言,服务端以客户端当前的计算与通信资源为依据,分配全局模型的子模型作为客户端的局部模型;客户端上传经局部迭代后的局部模型参数至服务端;服务端通过特定的聚合规则构成一个全局模型。该框架有效解决客户端因本地计算和通信资源效率低问题。 |
| 开源代码 | https://github.com/dem123456789/HeteroFL-Computation-and-Communication-Efficient-Federated-Learning-for-Heterogeneous-Clients |
2. 研究动机
当前已提出联邦学习框架中存在一个广泛的共识是客户端模型必须与全局模型为同一架构。然而,联邦学习系统效率受限于本地计算与通信资源最少的客户端。因此作者围绕如何解决具有不同的本地计算和通信资源的异构客户端,以提升异构客户端在计算与通信资源效率的问题开展研究工作。
3. 基本原理
3.1 系统概述
3.1.1 全局子模型划分
- HeteroFL 算法框架核心在于服务器以客户端当前的计算与通信资源为依据分配全局模型子模型供客户端进行本地训练。
- 服务器对客户端的计算与通信资源划分 P P P 个层级,每一个层级对应一种类别的全局子模型。
- 全局子模型依据不同的层级对每一层的输入输出通道按固定比率缩小。
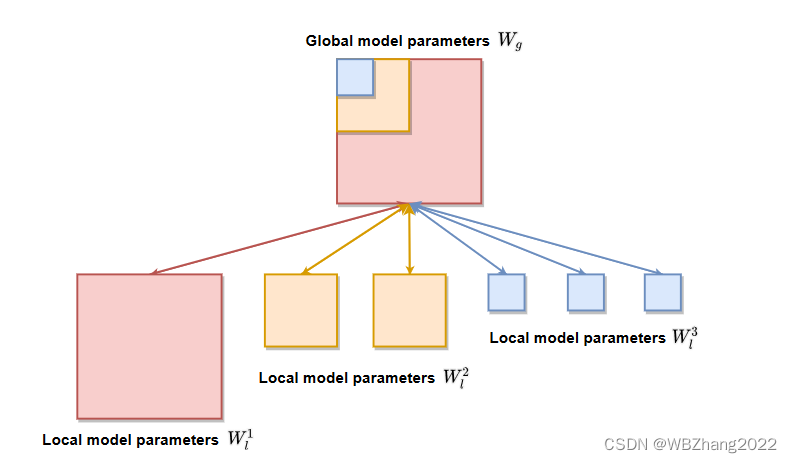
【注解】:如上图所示,该联邦学习系统存在6个客户端。其中,6个客户端根据计算与通信资源大小划分为3个层级,计算与通信资源最多通常情况下不对全局模型进行放缩,其余层级对全局模型每一层的输入输出通道按照固定的比率进行缩小。
3.1.2 符号定义 与 说明
| 符号 | 含义 |
|---|---|
| X 1 , X 2 , . . . , X m X_1,X_2,...,X_m X1,X2,...,Xm | 客户端本地私有数据 |
| W g W_g Wg | 全局模型参数 |
| W 1 , W 2 , . . . , W m W_1,W_2,...,W_m W1,W2,...,Wm | 局部模型参数 |
| r 1 , r 2 , . . . , r m r_1,r_2,...,r_m r1,r2,...,rm | 客户端对本地模型每一层通道缩放比率 |
| d g , k g d_g, k_g dg,kg | 全局模型每一层输入通道数与输出通道数 |
| d i , k i ( i = 1 , 2 , . . . , m ) d_i, k_i\quad (i=1,2,...,m) di,ki(i=1,2,...,m) | 局部模型每一层输入通道数与输出通道数 |
| M p ( p = 1 , 2 , . . . , P ) M_p \quad (p=1,2,...,P) Mp(p=1,2,...,P) | 不同层级对应的客户端数量 |
- 客户端计算与通信资源大小分为 P P P 个层级,此项工作中,定义层级 p = 1 p=1 p=1 为最大计算与通信资源, p = 2 , . . . , P p=2,...,P p=2,...,P 依次类推逐一减小;不同的层级对于全局子模型输入输出通道数为固定缩小比率 r p − 1 , p = 1 , 2 , . . . , P r^{p-1} ,\quad p=1,2,...,P rp−1,p=1,2,...,P,得到不同层级全局子模型输入输出通道数为 d i = r p − 1 ⋅ d g , k i = r p − 1 ⋅ k g d_i = r^{p-1}\cdot d_g,\quad k_i = r^{p-1}\cdot k_g di=rp−1⋅dg,ki=rp−1⋅kg
- 每一个客户端局部模型每一层输入输出通道取全局模型前 d i , k i d_i, k_i di,ki 个输入输出通道。构成了局部模型 W i ⊆ W g W_i \subseteq W_g Wi⊆Wg
3.2 组成模块
3.2.1 分配全局子模型 与 局部迭代
每一轮全局迭代 t t t,服务器随机选取 M t M_t Mt 个客户端参与联邦训练;
- 服务端对 M t M_t Mt 个客户端当前的计算与通信资源大小进行评估,以计算与通信资源大小作为依据划分不同类型的全局子模型给 M t M_t Mt 个客户端;
- 客户端获取到服务端分发的全局子模型后,基于本地数据集进行更新迭代得到局部模型;
- 客户端上传迭代完成后的局部模型参数于服务端,服务端按照特定的聚合规则实现局部模型参数聚合得到新一轮的全局模型参数;

3.2.2 提升性能小策略
3.2.2.1 Static Batch Normalization & Mask Trick
- Static Batch Normalization: 加快全局模型收敛速度,不对训练过程中对每一个batch的数据均值与方差进行跟踪,即在PyTorch实验平台中使用nn.BatchNormalization API时, 设置参数 track_running_stats=False;
- Mask Trick: 解决客户端数据服从非独立同分布的情形,在输出层仅更新对应类别的权重其余的类别权重保持不变;
3.2.2.2 Scaler
HeteroFL 框架中由于不同计算与通信资源的客户端模型会出现不同幅度的偏离,为了同一偏离幅度每一个batch经过隐藏层输出的结果乘上
1
r
p
−
1
\frac{1}{r^{p-1}}
rp−11
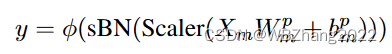
3.2.3 局部模型聚合规则
- 从最小计算与通信资源的客户端模型开始,寻找层级从 P − 1 , P − 2 , . . . , 1 P-1,P-2,...,1 P−1,P−2,...,1 的客户端模型与 层级 P P P 客户端模型参数重叠部分进行均值联邦 得到 W P W^P WP;
- 对比层级所有 P P P 与 P − 1 P-1 P−1 客户端模型,寻找两个层级客户端模型参数不重叠的部分,对该部分模型参数进行均值联邦 得到 ( W P − 1 \ W P ) (W^{P-1} \backslash W^{P}) (WP−1\WP),依次类推得到 ( W P − 2 \ W P − 1 ) , . . . , ( W 1 \ W 2 ) (W^{P-2} \backslash W^{P-1}),...,(W^{1} \backslash W^{2}) (WP−2\WP−1),...,(W1\W2)
- 分组均值联邦的结果以此按照每层通道的顺序拼接起来构成新一轮的全局模型参数
W
g
=
W
P
∪
(
W
P
−
2
\
W
P
−
1
)
∪
,
.
.
.
,
∪
(
W
1
\
W
2
)
W_g=W^P \cup (W^{P-2} \backslash W^{P-1})\cup,...,\cup(W^{1} \backslash W^{2})
Wg=WP∪(WP−2\WP−1)∪,...,∪(W1\W2)
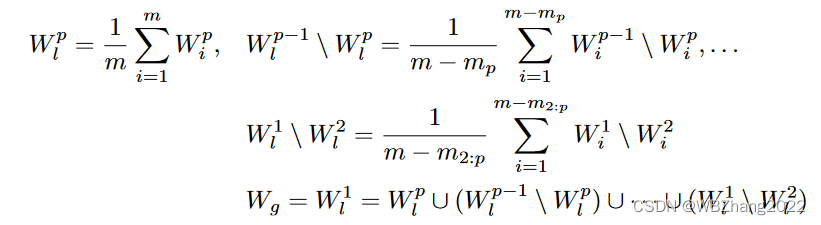
4. 实验结果 与 结论分析
4.1 实验设置
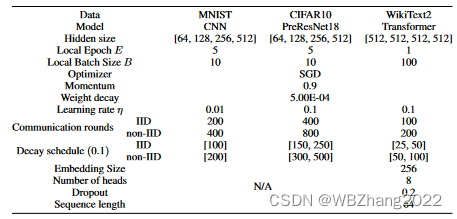
4.1.1 模型架构 与 基准数据集
4.1.2 联邦学习系统设置
- 联邦学习系统客户端设置: 100 100 100 个客户端,每一轮全局迭代随机选取 10 10 10 个客户端参与联邦训练;
- 客户端数据划分:分为独立同分布(iid)与非独立同分布(non-iid),特别注意:非独立同分布考虑每一个客户端所拥有的数据类别不超过 2 2 2 个;
- 客户端层级划分:划分为 5 5 5 个层级 { a , b , c , d , e } \{a,b,c,d,e\} {a,b,c,d,e},缩减比率基数 r = 0.5 r=0.5 r=0.5。具体而言, a a a 全局子模型缩减比率为 0.5 0.5 0.5, a a a 全局子模型缩减比率为 1.0 1.0 1.0, b b b 全局子模型缩减比率为 0.5 0.5 0.5, c c c 全局子模型缩减比率为 0.25 0.25 0.25, d d d 全局子模型缩减比率为 0.125 0.125 0.125, e e e 全局子模型缩减比率为 0.0625 0.0625 0.0625;
- 客户端计算与通信资源情况:分为动态与静态考虑。所谓动态客户端在每一全局迭代因计算与通信资源会发变化分配到不同大小的全局子模型。静态则与动态情形相反。
- 对比 baseline:Standalone/FedAvg/LG-FedAvg
4.2 实验结果
4.2.1 同一模型组合,类别比率不同
本组实验设置客户端的数据服从独立同分布,设置不同的组合,在同一个组合中调整类别之间的比率观察其对全局模型性能的影响。
注意:下图实验结果横坐标计算方法。以 a-b 作为例子,a模型参数大小 × × × a所占的比率 + + + b模型参数大小 × × × b所占的比率
-
CIFAR10
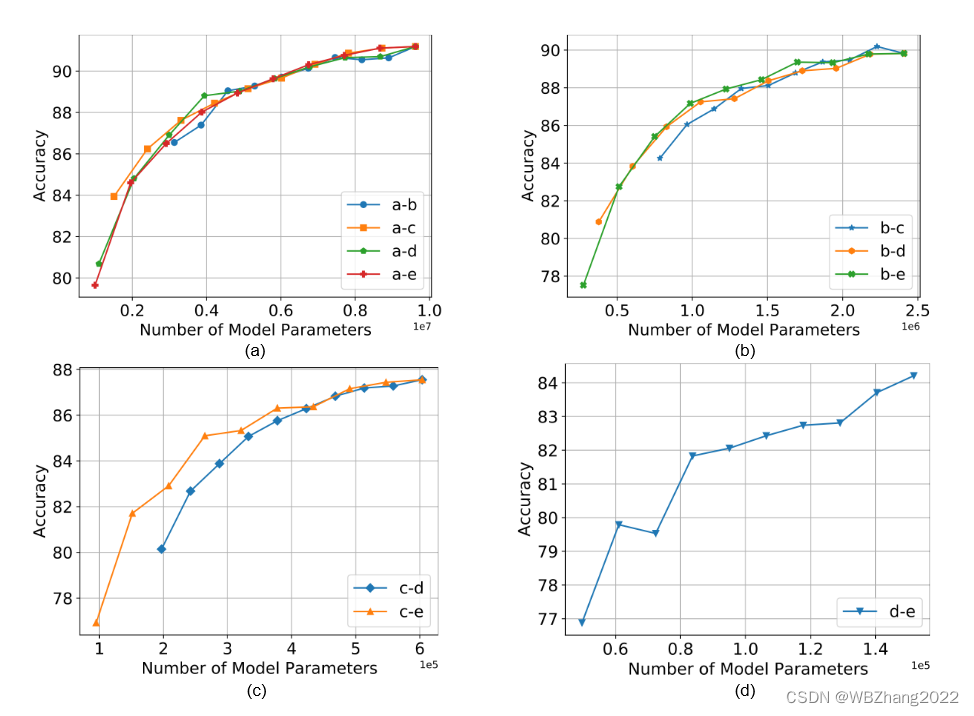
-
MNIST
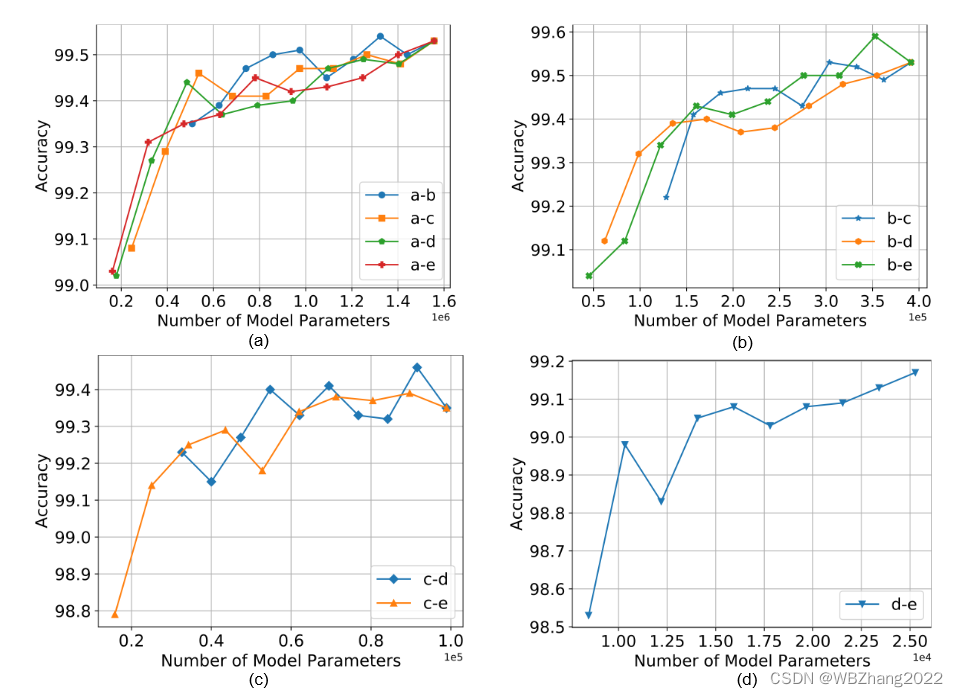
-
WikiText2
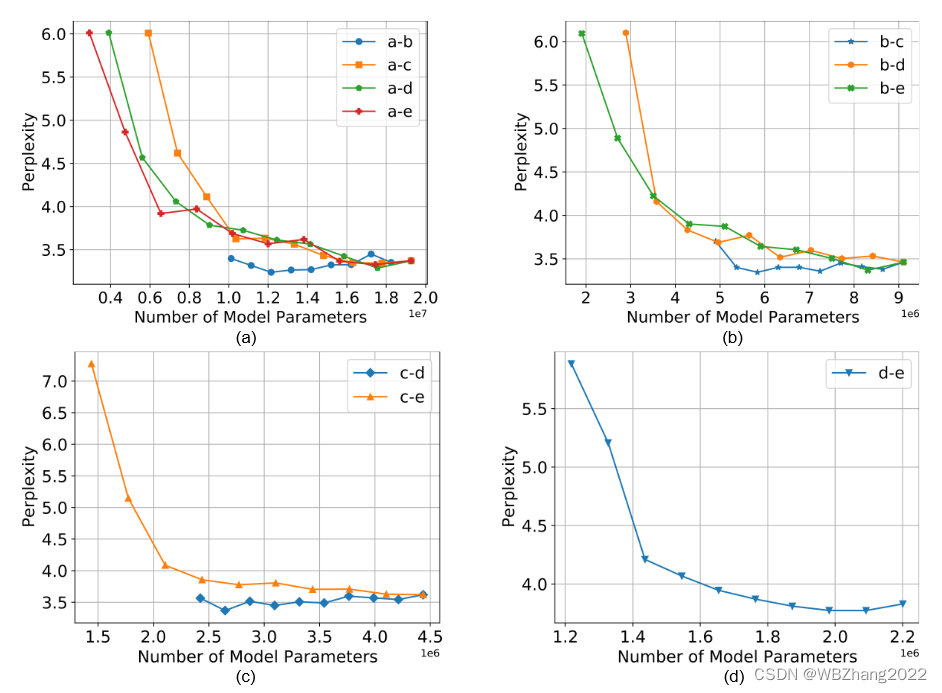
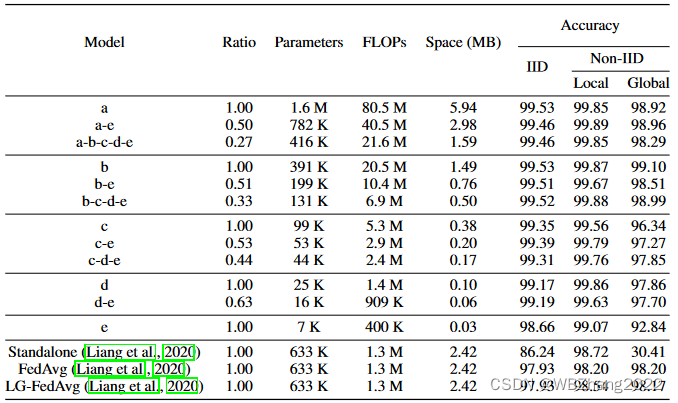
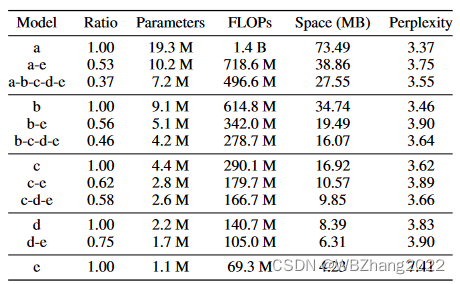
4.2.2 不同模型组合
本组实验考虑客户端计算与通信资源是静态的条件下,对于不同的模型组合分别比较独立同分布与非独立同分布情形下全局模型性能;
-
CIFAR10
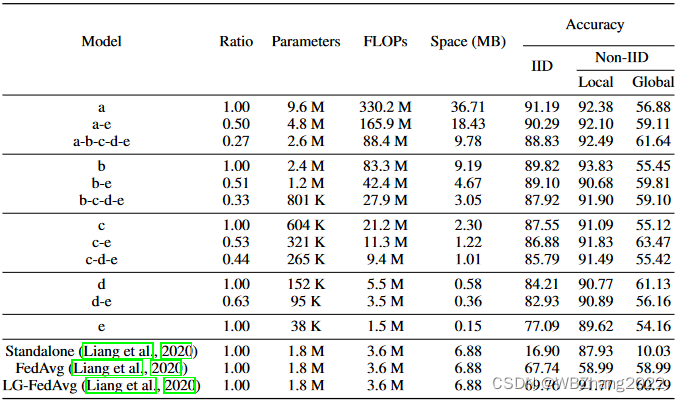
-
MNIST
-
WikiText2
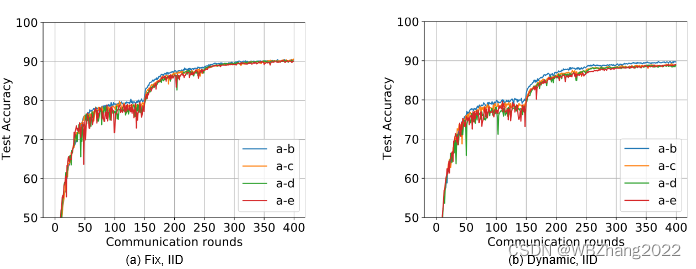
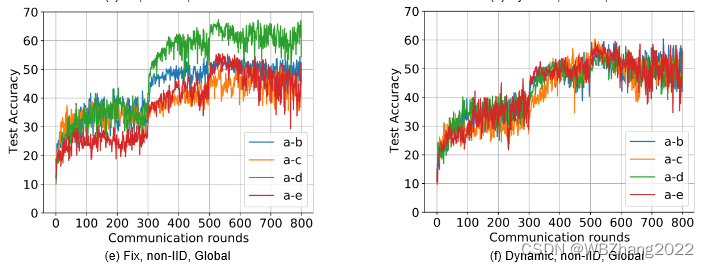
4.2.3 客户端计算与通信资源是否为动态变化
本组实验验证客户端计算与通信资源在静态/动态情形下分别在独立同分布/非独立同分布下对全局模型性能影响。注意:不同的实验组合仅有两种模型,且占比皆为 50 % 50\% 50%
-
CIFAR10
-
MNIST
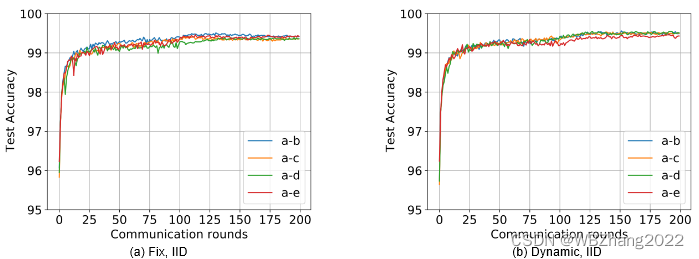
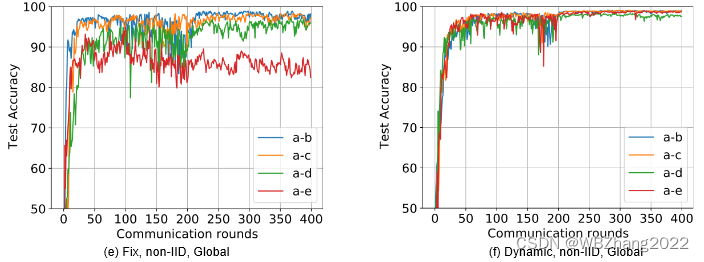
-
WikiText2
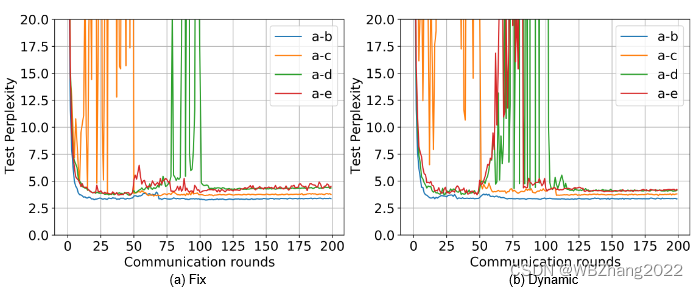
5. 实验结论 与 未来展望
作者提出了 HeteroFL 联邦学习训练框架。客户端因计算与通信资源的差异分配不同大小的全局子模型。服务器使用特定的聚合规则聚合不同大小的局部模型以构成一个全局模型。该算法有效提高联邦学习系统计算与通信资源使用效率。
在后续研究中,可以围绕异构的小样本学习,多模态学习以及多任务学习等方向开展研究。














 595
595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









