






错误一:a non-zero exit code 13. Error file: prelaunch.err. Last 4096 bytes of prelaunch.err :
这个错误整整困扰了我两天,用client模式提交没有问题,一旦切换成cluster模式就报错
Application application_1659522163899_1043 failed 2 times due to AM Container for appattempt_1659522163899_1043_000002 exited with exitCode: 13
Failing this attempt.Diagnostics: [2022-08-04 17:47:23.976]Exception from container-launch.
Container id: container_e207_1659522163899_1043_02_000001
Exit code: 13
[2022-08-04 17:47:24.174]Container exited with a non-zero exit code 13. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
22/08/04 17:47:22 INFO util.SignalUtils: Registering signal handler for TERM
22/08/04 17:47:22 INFO util.SignalUtils: Registering signal handler for HUP
22/08/04 17:47:22 INFO util.SignalUtils: Registering signal handler for INT
22/08/04 17:47:22 INFO spark.SecurityManager: Changing view acls to: yarn,hdfs
22/08/04 17:47:22 INFO spark.SecurityManager: Changing modify acls to: yarn,hdfs
22/08/04 17:47:22 INFO spark.SecurityManager: Changing view acls groups to:
22/08/04 17:47:22 INFO spark.SecurityManager: Changing modify acls groups to:
22/08/04 17:47:22 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(yarn, hdfs); groups with view permissions: Set(); users with modify permissions: Set(yarn, hdfs); groups with modify permissions: Set()
22/08/04 17:47:22 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
22/08/04 17:47:23 INFO yarn.ApplicationMaster: ApplicationAttemptId: appattempt_1659522163899_1043_000002
22/08/04 17:47:23 INFO yarn.ApplicationMaster: Starting the user application in a separate Thread
22/08/04 17:47:23 INFO yarn.ApplicationMaster: Waiting for spark context initialization...
22/08/04 17:47:23 ERROR yarn.ApplicationMaster: User application exited with status 1
22/08/04 17:47:23 INFO yarn.ApplicationMaster: Final app status: FAILED, exitCode: 13, (reason: User application exited with status 1)
22/08/04 17:47:23 ERROR yarn.ApplicationMaster: Uncaught exception:
org.apache.spark.SparkException: Exception thrown in awaitResult:
at org.apache.spark.util.ThreadUtils$.awaitResult(ThreadUtils.scala:301)
at org.apache.spark.deploy.yarn.ApplicationMaster.runDriver(ApplicationMaster.scala:509)
at org.apache.spark.deploy.yarn.ApplicationMaster.run(ApplicationMaster.scala:273)
at org.apache.spark.deploy.yarn.ApplicationMaster$$anon$3.run(ApplicationMaster.scala:913)
at org.apache.spark.deploy.yarn.ApplicationMaster$$anon$3.run(ApplicationMaster.scala:912)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1878)
at org.apache.spark.deploy.yarn.ApplicationMaster$.main(ApplicationMaster.scala:912)
at org.apache.spark.deploy.yarn.ApplicationMaster.main(ApplicationMaster.scala)
Caused by: org.apache.spark.SparkUserAppException: User application exited with 1
at org.apache.spark.deploy.PythonRunner$.main(PythonRunner.scala:103)
at org.apache.spark.deploy.PythonRunner.main(PythonRunner.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.yarn.ApplicationMaster$$anon$2.run(ApplicationMaster.scala:737)
22/08/04 17:47:23 INFO yarn.ApplicationMaster: Deleting staging directory hdfs://cluster/user/hdfs/.sparkStaging/application_1659522163899_1043
22/08/04 17:47:23 WARN shortcircuit.DomainSocketFactory: The short-circuit local reads feature cannot be used because libhadoop cannot be loaded.
22/08/04 17:47:23 INFO util.ShutdownHookManager: Shutdown hook called
[2022-08-04 17:47:24.184]Container exited with a non-zero exit code 13. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
22/08/04 17:47:22 INFO util.SignalUtils: Registering signal handler for TERM
22/08/04 17:47:22 INFO util.SignalUtils: Registering signal handler for HUP
22/08/04 17:47:22 INFO util.SignalUtils: Registering signal handler for INT
22/08/04 17:47:22 INFO spark.SecurityManager: Changing view acls to: yarn,hdfs
22/08/04 17:47:22 INFO spark.SecurityManager: Changing modify acls to: yarn,hdfs
22/08/04 17:47:22 INFO spark.SecurityManager: Changing view acls groups to:
22/08/04 17:47:22 INFO spark.SecurityManager: Changing modify acls groups to:
22/08/04 17:47:22 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(yarn, hdfs); groups with view permissions: Set(); users with modify permissions: Set(yarn, hdfs); groups with modify permissions: Set()
22/08/04 17:47:22 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
22/08/04 17:47:23 INFO yarn.ApplicationMaster: ApplicationAttemptId: appattempt_1659522163899_1043_000002
22/08/04 17:47:23 INFO yarn.ApplicationMaster: Starting the user application in a separate Thread
22/08/04 17:47:23 INFO yarn.ApplicationMaster: Waiting for spark context initialization...
22/08/04 17:47:23 ERROR yarn.ApplicationMaster: User application exited with status 1
22/08/04 17:47:23 INFO yarn.ApplicationMaster: Final app status: FAILED, exitCode: 13, (reason: User application exited with status 1)
22/08/04 17:47:23 ERROR yarn.ApplicationMaster: Uncaught exception:
org.apache.spark.SparkException: Exception thrown in awaitResult:
at org.apache.spark.util.ThreadUtils$.awaitResult(ThreadUtils.scala:301)
at org.apache.spark.deploy.yarn.ApplicationMaster.runDriver(ApplicationMaster.scala:509)
at org.apache.spark.deploy.yarn.ApplicationMaster.run(ApplicationMaster.scala:273)
at org.apache.spark.deploy.yarn.ApplicationMaster$$anon$3.run(ApplicationMaster.scala:913)
at org.apache.spark.deploy.yarn.ApplicationMaster$$anon$3.run(ApplicationMaster.scala:912)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1878)
at org.apache.spark.deploy.yarn.ApplicationMaster$.main(ApplicationMaster.scala:912)
at org.apache.spark.deploy.yarn.ApplicationMaster.main(ApplicationMaster.scala)
Caused by: org.apache.spark.SparkUserAppException: User application exited with 1
at org.apache.spark.deploy.PythonRunner$.main(PythonRunner.scala:103)
at org.apache.spark.deploy.PythonRunner.main(PythonRunner.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.yarn.ApplicationMaster$$anon$2.run(ApplicationMaster.scala:737)
22/08/04 17:47:23 INFO yarn.ApplicationMaster: Deleting staging directory hdfs://cluster/user/hdfs/.sparkStaging/application_1659522163899_1043
22/08/04 17:47:23 WARN shortcircuit.DomainSocketFactory: The short-circuit local reads feature cannot be used because libhadoop cannot be loaded.
22/08/04 17:47:23 INFO util.ShutdownHookManager: Shutdown hook called
For more detailed output, check the application tracking page: http://wj-hdp-3:8088/cluster/app/application_1659522163899_1043 Then click on links to logs of each attempt.
. Failing the application.
各种查资料,网上也没有一样得问题,仅有得两个问题都没有答案,疯了,打开yarn看不到日志,打开spark webui更是连application都没有,最后尝试着用yarn logs -applicationId application_1659522163899_1651
看了一下,结果发现,报错导入模块失效,可是我明明安装了呀
End of LogType:stderr
***********************************************************************
Container: container_e207_1659522163899_1651_02_000001 on wj-hdp-9_45454_1659674465064
LogAggregationType: AGGREGATED
======================================================================================
LogType:stdout
LogLastModifiedTime:Fri Aug 05 12:41:05 +0800 2022
LogLength:151
LogContents:
Traceback (most recent call last):
File "pyspark_test.py", line 3, in <module>
import findspark
ModuleNotFoundError: No module named 'findspark'
End of LogType:stdout
最后看见那个 on wj-hdp-,明白了,由于我是用的pyspark集群模式运行,你的代码在每个服务器乱窜,所以当前节点安装对应模块根本没用,得在所有节点全部安装才行。这就是为什么客户端模式运行没问题,因为当前节点是有这个模块的。然后集群模式其他节点没有,最后全部安装上相关模块成功了。重点是yarn logs查看日志,上面简单的报错信息根本没用。
错误二:hive表或视图找不到
这个简单,把hive的hive-site.xml复制到spark的conf目录下就ok了,或者也可以在代码里添加config
spark = SparkSession.builder.config('','').enableHiveSupport().getOrCreate()
里面填hive-site.xml里复制过来的东西,或者把hive-site.xml在提交的时候通过–files的方式加上也行。
目前还有一个问题,就是我的–files好像不起作用的样子,随后在研究。
补充:确定问题了,用客户端模式执行时,–files不起作用,用集群模式时能正常作用
错误三: You may get a different result due to the upgrading of Spark 3.0: Fail to parse ‘2022-04-14 17:41:05’ in the new parser. You can set spark.sql.legacy.timeParserPolicy to LEGACY to restore the behavior before Spark 3.0, or set to CORRECTED and treat
根据官网的说法,时spark3用了和之前不同的计算方式,所以读取不到正确的时间,解决方式有两个
1.–conf spark.sql.legacy.timeParserPolicy=LEGACY 用之前的计算方式计算
2.–conf spark.sql.legacy.timeParserPolicy=CORRECTED 把该时间视为错误的时间
错误四:Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical memory used; 2.2 GB of 2.1 GB virtual memory used. Killing container.
这是driver端的虚拟内存溢出,通常是通过collect() 或其他返回函数一下为客户端返回大量数据导致的,,适当增加–driver-memory 的大小即可,不过不建议程序中大量返回给客户端数据
错误五:同一个sql,hive和spark的查询结果不一致
为了优化读取parquet格式文件,spark默认选择使用自己的解析方式读取数据,结果读出的数据就有问题。可以选择配置参数
spark.sql.hive.convertMetastoreParquet=false
spark.sql.hive.convertMetastoreOrc=false
默认是true,改成false会降低效率,但是会保证和hive一致,
但是此处我设置了这两个参数后爆出了另一个异常;
java.lang.ClassCastException: org.apache.hadoop.hive.ql.io.orc.OrcStruct cannot be cast to org
后来检查发现hive表不是parquet和orc,重新建表后解决,而且连查询结果不一致的问题也一起解决了(没有设置参数),
这个问题又一次证明了hive建表最好使用orc或者parquet格式
错误六:
org.apache.spark.SparkException: Job aborted due to stage failure: Task 3 in stage 273.0 failed 4 times, most recent failure: Lost task 3.3 in stage 273.0 (TID 763) (wj-hdp-7 executor 1): java.io.FileNotFoundException:
File does not exist: hdfs://cluster/warehouse/tablespace/external/hive/dwd.db/dwd_zyfdm_movie_info_share_2ha/own=zhongying/part-00001-34773a3a-8a38-43ec-905a-298212ec114b.c000.snappy.parquet
It is possible the underlying files have been updated. You can explicitly invalidate
the cache in Spark by running ‘REFRESH TABLE tableName’ command in SQL or by
recreating the Dataset/DataFrame involved.
这个错误其实是因为spark在读取hive的时候为了加快速度会把元数据进行缓存,而在缓存后如果hive元数据发生了改变就会报这个错,此处也提示了,可以使用spark.sql(‘refresh table database.table’) 或者 spark.catalog.refreshTable(databalse.table) 刷新缓存来解决,但是这种方式在hive更新的同时如果进行了refresh 刷新,会出现数据没有写进去的情况,不知道是什么原因引起的。 而默认缓存数量是1000,也就是说,当达到1000后会释放开始缓存的部分,所以也可以把缓存数量置为0,以实现不缓存的目的,在spark2以前只能通过重写源码的方式来处理,在spark3中对这点进行了优化,只需要设置参数 ‘spark.sql.filesourceTableRelationCacheSize’=0 即可。这种方式会带来性能损耗。
参考:Spark Catalyst 缓存机制
spark元数据缓存踩过的坑
错误七
HVE_UNION SUBDIR 1 is a directorywhich is not supported by the record reader when 'mapreduce.input.fileinputformat.input.dir.recursive’ is false
原因是该hive表是通过union all的方式加载的,使用Hive的insert overwrite/into select … union all生成的Hive表数据时,会在原本的数据表目录下生成多个子目录(HIVE_UNION_SUBDIR_1、HIVE_UNION_SUBDIR_2),以存放数据文件(正常情况下数据文件会直接存放在数据表目录下)。这时,如果使用spark-sql去查询该数据表的时候,会报 Not a file 的异常:
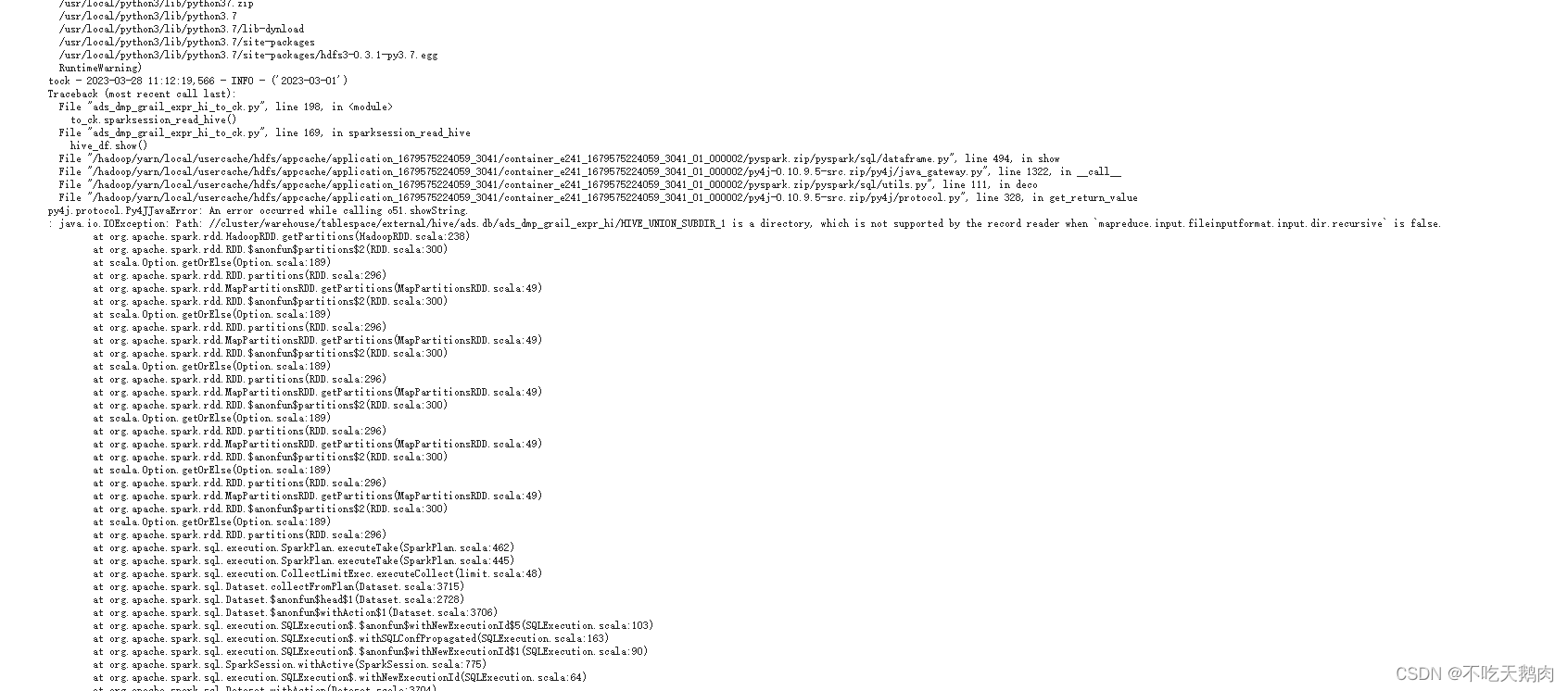
解决方案:
–conf spark.hive.mapred.supports.subdirectories=true
–conf spark.hadoop.mapreduce.input.fileinputformat.input.dir.recursive=true

















 1440
1440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









