






最近在基于深度学习编译器做一些开发,这里记录一下学习历程
首先讲述一下我们最常接触到的训练框架,其中已经内含了深度学习编译器,而深度学习编译系统则包括深度学习框架与其它工具,提供全面的深度学习解决方案。
深度学习框架与深度学习编译器到底有何区别与联系?
目前对于这方面比较浅的理解是:最大的不同点应该体现在节点与后端硬件映射的粒度或是否是自动映射上,深度学习框架一般都是图中节点一对一有后端算子,算子手写;而编译器要做的就是不需要这种一对一性,可以对节点进行拆分或者合并,然后进行一系列优化,比如转成for形式和一些细粒度指令(通过像ansor这种自动搜索等的方式),然后通过代码生成 生成效率较高的算子,或者对接LLVM或者其它算子库。前者需要手动将写好的算子与节点匹配,而后者可以对节点进行优化,自动生成高性能算子。
New Bing:深度学习框架和深度学习编译器是两个不同的概念,但也有一定的联系。深度学习框架是一种用于构建、训练和部署深度学习模型的软件库,例如TensorFlow、PyTorch、MXNet等。深度学习编译器是一种用于将深度学习模型转换为针对特定硬件平台的高效代码的软件工具,例如TVM、Glow、Tensor Comprehension等。
深度学习框架和深度学习编译器的区别主要体现在以下几个方面:
- 深度学习框架一般都是图中节点一对一有后端算子,算子手写或者调用第三方库,例如cuDNN、MKL-DNN等。而深度学习编译器要做的就是不需要这种一对一性,可以对节点进行计算拆分,比如转成for形式和一些细粒度指令,通过自动搜索或者优化算法来生成高性能的代码
- 深度学习框架的优化主要集中在图级别,例如算子融合、常量传播、代数简化等。而深度学习编译器的优化涉及多个层次,包括图级别、中间表示(IR)级别和目标代码级别,例如循环变换、存储重排、向量化等
- 深度学习框架的可移植性较低,因为它们依赖于特定硬件平台的算子库或者手工优化的代码。而深度学习编译器的可移植性较高,因为它们可以利用通用的编译器基础设施,例如LLVM、OpenCL等,来支持多种硬件体系结构
深度学习框架和深度学习编译器的联系主要体现在以下几个方面:
- 深度学习编译器可以作为深度学习框架的一个组件或者插件,来提升框架的性能和效率。例如TensorFlow XLA就是一个基于XLA编译器技术的TensorFlow加速器3。
- 深度学习编译器可以兼容多种深度学习框架的模型格式,从而实现跨框架的部署。例如TVM可以支持TensorFlow、PyTorch、ONNX等多种模型格式4。
- 深度学习编译器可以借鉴深度学习框架中的一些设计思想和技术,例如计算图表示、自动求导机制等。例如Glow就使用了PyTorch中的自动求导机制来实现反向传播3。
一、深度学习框架
早期在写神经网络代码时,需要完成网络结构定义,生成计算图,算子优化,生成机器码等环节,越靠后的环节工作量越大且可以重复利用率越高。因此为了减少造轮子,把后端整合成一个一个API,前端网络定义后,解析计算图,会自动调用相关的API,生成机器码。这样一个结构就形成了早期的深度学习框架

学术界和业界公认的最老牌的框架Caffe等的出现让大家基于框架套用原有模型借助框架可以在不编写代码的情况下就很容易进行深度学习的研究,但Caffe也存在缺少灵活性的问题,Caffe是基于层的网络结构,要添加实现一个新层,必须使用C++实现它的前向传播和反向传播代码,如果新层需要运行在GPU则还需要实现CUDA代码,这使得对模型进行调整往往需要C++或CUDA编程。
Theano是一个比较底层的Python库,专门用于定义、优化和求值数学表达式,是第一个主要的Python深度学习框架,通过对符号式语言定义的程序进行编译来高效运行于GPU或CPU上,这为后来深度学习框架奠定了以计算图为框架核心,采用GPU加速的设计理念。
Torch是一个基于一种小型加强版C的Lua编程语言开源的深度学习框架,它提供了许多的深度学习算法,但由于Python已经在深度学习领域建立起完整生态,因此Torch推广发展受到了限制。

为了解决早期深度学习框架中出现的问题,并进一步减少造轮子,现代主流深度学习框架可以满足
- 无需手写代码支持多GPU
- 容易构建大的计算图
- 自动实现计算图中的梯度计算等
当前的主流深度学习框架十分依赖于硬件厂商提供的张量算子库,例如TensorFLow,首先由高级语言Python等描述的网络结构解析生成计算图(其中节点表示算子也就是操作,边表示依赖关系)后,执行器执行到某个节点,(这是Eagle模式的嘛?)会调用硬件厂商提供的张量算子库来完成具体节点的执行。
静态图执行模式:
在TensorFlow中,运行计算图操作的过程涉及到图执行引擎的执行,以便将操作映射到实际的计算设备(如CPU或GPU),并执行它们。这个过程可以分为以下几个步骤,其中最终的机器码生成通常由底层的TensorFlow运行时系统和硬件驱动程序处理:
1. 操作依赖解析:在运行计算图操作之前,TensorFlow会分析操作之间的依赖关系。这确保了操作按正确的顺序执行。TensorFlow会根据操作的输入和输出张量之间的依赖性来确定操作的执行顺序。
2. 计算张量的值:在执行操作之前,TensorFlow会计算操作的输入张量的值。这可能涉及到对之前的操作进行计算,以确保所有必要的输入都可用。如果输入是占位符(placeholder),则需要提供相应的数据。
3. 操作调度和分配:一旦确定了操作的执行顺序,TensorFlow将决定在哪个设备上执行这些操作(如CPU或GPU)。这个决策通常受到硬件配置、操作的类型以及TensorFlow配置的影响。
4. 操作执行:操作被分配给具体的执行设备后,TensorFlow会将它们的计算任务发送给底层硬件或运行时系统。这是TensorFlow的关键部分,通常由底层的TensorFlow运行时系统执行。运行时系统会负责将操作转化为适用于硬件的低级代码(例如CUDA代码或CPU指令集),并将其传递给硬件驱动程序。
5. 硬件执行:底层硬件驱动程序接收到低级代码并在硬件上执行操作。例如,在GPU上执行矩阵乘法操作时,GPU驱动程序会利用GPU的并行处理能力执行矩阵乘法计算。
6. 结果返回:一旦操作执行完成,结果将返回到TensorFlow的计算图中。这个结果可以是张量的值,可以用于进一步的计算或输出。
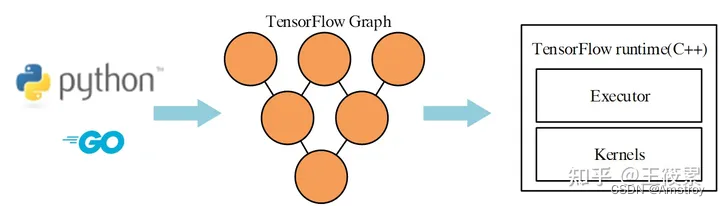
通过这一流程可以发现,一个算子会有很多逻辑上等效的实现,也就是有多个kernel可以对应,不同kernel优化程度不同,适应设备也不同。因此kernel开发与选择会有非常大的工作量。能不能根据算子,通过硬件设备等信息,自动生成kernel或者可执行代码呢?这就是深度学习编译器的工作了。
二、深度学习编译器

传统编译器的流程为,前端接受不同的语言生成LLVM IR,针对此IR进行硬件无关优化,之后传给编译器后端,编译器后端进行硬件相关优化并生成硬件相关的机器码。

深度学习编译器的流程为,前端接受不同的语言生成图IR,针对图IR进行硬件无关优化,然后后端进行硬件相关优化并生成硬件相关机器码或者执行引擎的接口代码
例如TVM编译器

Import将前端语言转为TVM中间表示 Relay IR,然后针对此IR进行硬件无关优化(算子融合,数据布局优化),然后Lower为TIR,此时DNN计算被分解为矩阵-向量,矩阵乘法等形式的张量计算,对其进行硬件相关优化,例如tiling大小,fusion策略,最后由Codegen生成可执行程序??
















 676
676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









