






一、深度学习编译器背景
深度学习框架调用算子库来进行计算,但这存在两个问题
- 算子越来越多,难以维护算子库
- 硬件多样性,可移植性差
深度学习编译器可以在优化过程中进行自动或者半自动的代码生成,这样就不需要人工再去优化然后再选择算子了。
二、深度学习编译器比较
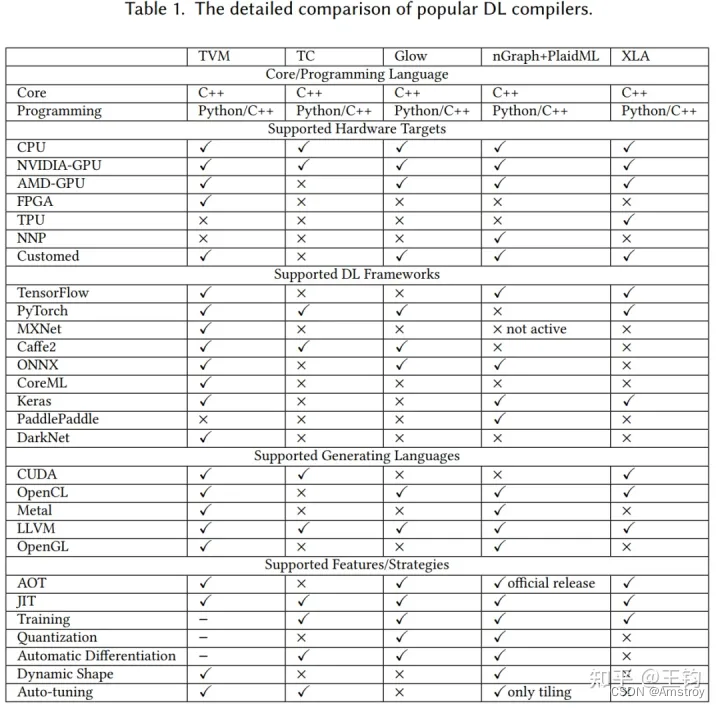
三、深度学习编译器架构
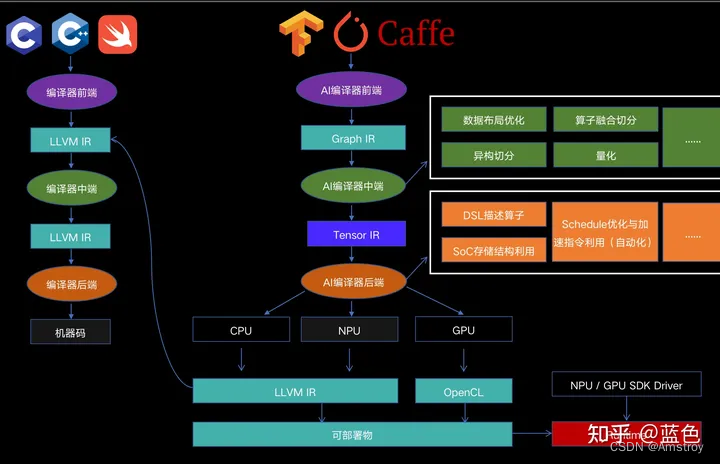
四、深度学习通用设计
编译器通常包括编译器前端与编译器后端,前端对计算图与硬件无关优化,后端对张量图进行硬件相关优化,代码生成与编译
高阶IR也称为图IR,用于表示与硬件无关的计算和控制流。高阶IR的设计难点在于如何抽象计算和控制流,有了这种抽象能力就可以捕获和表达各种DL模型。高阶IR的目标是建立控制流以及算子与数据之间的依赖关系,并为图级优化提供接口。此外,高阶IR还应包含编译所需的语义信息,并为自定义算子提供可扩展性。
低阶IR主要设计用于各种硬件相关的优化和代码生成。因此,低阶IR应该注重设计细节,反映硬件特性,准确表示硬件相关的优化。低阶IR应该能够在编译器后端(例如Halide、多面体模型和LLVM)中使用成熟的第三方工具链
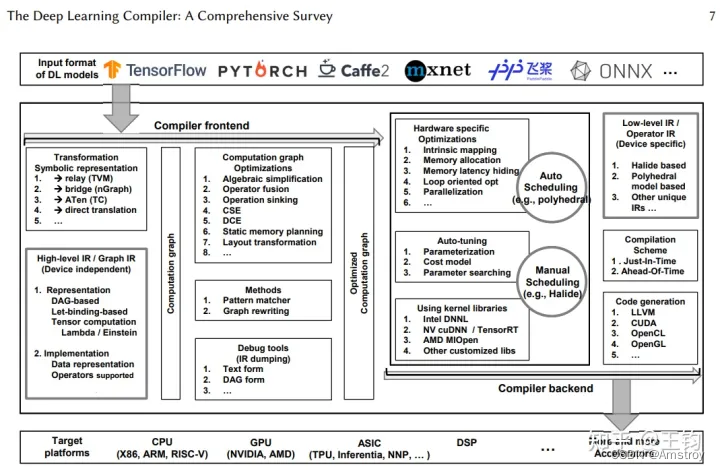
前端是DL编译器中最重要的组件之一,负责从DL模型到计算图高级IR的转换,以及基于高阶IR的硬件无关优化。虽然不同AI芯片编译器前端实现在高阶IR的数据表示和算子定义上有所不同,但与硬件无关的优化都可以分为三个层次:节点级、块级和数据流级。每个层次的优化方法都利用了DL特有方法和常规的编译优化技术,从而减少了计算冗余,提高了DL模型在计算图层次的性能。
DL编译器后端通常包括各种硬件相关优化、自动调优技术和优化的内核库。硬件相关优化可以针对不同硬件目标实现高效的代码生成,自动调优技术可以极大减轻推导最佳参数配置的手动工作量,高度优化的内核库广泛用于通用处理器和定制DL加速器。
在代码生成方面,传统编译器的目标是生成优化的通用代码,而AI编译器的目标是为特定算子(如卷积,矩阵乘等)生成性能达到或超过手动调优算子的代码实现。作为代价,AI编译器可能要牺牲编译时间去搜索最优配置。
后端将高阶IR转换为低阶IR,并执行特定于硬件的优化。一方面,后端可以直接将高阶IR转换为LLVM IR等第三方工具链,如此一来就可以利用已有编译器工具完成通用优化和代码生成。另一方面,后端可以利用DL模型和硬件特性的先验知识,通过定制的编译pass更有效地生成代码。常用的硬件相关的优化包括硬件intrinsic映射、内存分配和提取、内存延迟隐藏、并行化以及针对循环的优化。为了在大型优化空间中确定最佳参数设置,在现有的DL编译器中广泛采用自动调度(如多面体模型)和自动调优(如AutoTVM)这两种方法。优化后的低阶IR通过JIT或AOT编译,生成针对不同硬件目标的代码。
4.1 IR处理
传统编译器里分为前端,优化和后端,其中前端和语言打交道,后端和机器打交道,现代编译器的的前端和后端分的很开,而他们之间的共同桥梁就是IR。IR可以说是一种胶水语言,注重逻辑而去掉了平台相关的各种特性,这样为了支持一种新语言或新硬件都会非常方便。

4.1.1 高级IR
为了克服传统编译器采用的IR限制了AI模型中使用的复杂计算的表达的问题,现有的DL编译器利用图IR和经过特殊设计的数据结构来进行有效的代码优化。
4.1.2 低级IR
相比高级IR,低级IR以更细粒度的表示形式描述了AI模型的计算,该模型通过提供接口来调整计算和内存访问,从而实现了与目标有关的优化。它还允许开发人员在编译器后端使用成熟的第三方工具链,例如Halide和多面体模型。将低级IR可分为三类:基于Halide的IR,基于多面体模型的IR和其他独特的IR。如果感兴趣深度学习框架中的IR处理,可以阅读金雪峰老师的AI框架中图层IR的分析。
4.2 前端优化
构造计算图后,前端将应用图级优化。因为图提供了计算的全局概述,所以更容易在图级发现和执行许多优化。这些优化仅适用于计算图,而不适用于后端的实现。因此,它们与硬件无关,这意味着可以将计算图优化应用于各种后端目标。
前端优化分为三类:
1)节点级优化(如零维张量消除、nop消除)
2)块级优化(如代数简化、融合)
3)数据流级优化(如CSE、DCE)。
前端是DL编译器中最重要的组件之一,负责从AI模型到高级IR(即计算图)的转换以及基于高级IR的独立于硬件的优化。尽管在不通过在DL编译器上前端的实现在高级IR的数据表示形式和运算符定义上有所不同,但与硬件无关的优化在节点级别,块级别和数据流级别这三个级别上相似。
4.3 后端优化
4.3.1 特定硬件的优化
在DL编译器的后端,针对硬件的优化(也称为依赖于目标的优化)用于针对特定硬件体系结构获取高性能代码。应用后端优化的一种方法是将低级IR转换为LLVM IR,以便利用LLVM基础结构生成优化的CPU/GPU代码。另一种方法是使用DL域知识设计定制的优化,这可以更有效地利用目标硬件。
4.3.2 自动调整
由于在特定硬件优化中用于参数调整的搜索空间巨大,因此有必要利用自动调整来确定最佳参数设置。Halide/TVM允许程序员首先定义特定硬件的优化(调度),然后使用自动调节来得出最佳参数设置。这样,Halide/TVM编程人员可以通过反复检查特定参数设置的性能来更新或重新设计规划。另外,自动调整也可以应用多面体模型进行参数调整。
4.3.3 优化的内核库
目前还有几个高度优化的内核库,广泛用于各种硬件上的加速DL训练和推理。当特定的高度优化的原语可以满足计算要求时,使用优化的内核库可显著提高性能,否则可能会受到进一步优化的约束,并且性能较差。
















 895
895











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









