






BSANet:移动和Web应用的边界感知分割网络
摘要:尽管深度模型极大地提高了图像分割的精度和鲁棒性,但获得具有高精度边界和精细结构的分割结果仍然是一个具有挑战性的问题。在本文中,我们提出了一个简单而强大的边界感知分割网络(BASNet),它包括预测-细化架构和混合损失,用于高精度的图像分割。预测-细化结构由密集监督的编码器-解码器网络和残差细化模块组成,分别用于预测和细化分割概率图。混合损失是二值交叉熵、结构相似性和相交过并损失的组合,它引导网络学习三层(即像素级、补丁级和地图级)层次表示。我们在两个反向任务中评估了我们的BASNet,包括显著目标分割,伪装目标分割,表明它在清晰的分割边界下取得了非常有竞争力的性能。重要的是,BASNet在单个GPU上以超过70 fps的速度运行,这有利于许多潜在的实际应用。基于BASNet,我们进一步开发了两个(接近)商业应用:AR COPY & PASTE,其中BASNet与增强现实相结合,用于“复制”和“P ASTING”现实世界的对象,以及OBJECT CUT,这是一个基于web的自动对象背景删除工具。这两个应用程序已经引起了大量的关注,并对现实世界产生了重要的影响。
1 介绍
图像分割已经使用传统方法研究了几十年,在过去的几年里使用了深度学习。在过去的几十年里,人们研究了几种不同的传统图像分割方法,如交互式方法、活动轮廓(水平集方法)、图论方法、感知分组方法等。然而,在边界复杂的情况下,自动方法就失效了。交互式方法让人类解决复杂的案例。交互式方法[99]、[114]、[8]、[91]通常能够产生准确而稳健的结果,但需要花费大量的时间。活动轮廓[82],[48],[1],[118],[6],[7],[124],图论[120],[16],[101],[100],[112]和感知分组[47],[20],[73],[2],[21],[97],[92],[88],方法几乎不需要人工干预使它们比交互式方法更快。然而,它们相对不那么健壮。
近年来,为了实现准确、鲁棒和快速的性能,人们开发了许多深度学习模型[77]用于图像分割。语义图像分割[70],[40]是最受欢迎的主题之一,其目的是用几个预定义的类标签之一标记图像中的每个像素。它已广泛应用于许多应用,如场景理解[65]、[145]、自动驾驶[28]、[15]等。这些应用中的目标通常尺寸较大,因此大多数现有方法都侧重于实现具有高区域精度的鲁棒性。对边界和精细结构的高空间精度关注较少。然而,许多其他应用,如图像分割/编辑[90],[46],[31],[91]和操作[45],[76],视觉跟踪[57],[89],[93],视觉引导机械手操作[88]等,都需要高度精确的目标边界和精细结构。在图像的精确分割中存在两个主要的挑战:第一,大规模特征相对于局部特征能够提供更多的语义信息,在像素分类中起着重要的作用。然而,大规模特征通常是通过深度低分辨率特征图或大尺寸核获得的,牺牲了空间分辨率。简单地将低分辨率特征图上采样到高分辨率是无法恢复精细结构的[70]。因此,许多编码器-解码器架构[98]已经开发用于分割边缘或薄结构。它们的跳变连接和逐步上采样操作在恢复高分辨率概率图中起着重要作用。另外,不同的级联
或者引入迭代架构[125],[115],[18],[113],通过逐步细化粗预测来进一步提高分割精度,有时会导致网络架构复杂和计算瓶颈。其次,大多数图像分割模型使用交叉熵(CE)损失来监督训练过程。CE损失通常对这些严重错误的预测给予更大的惩罚(例如,将“1”预测为“0.1”或将“0”预测为“0.9”)。因此,使用CE损失进行训练的深度模型更倾向于预测具有非承诺“0.5”的“硬”样本。在图像分割任务中,目标的边界像素通常是硬样本,这将导致预测分割概率图的边界模糊。其他损失,如交叉过并(intersection - over-union, IoU)损失[96]、[75]、[80]、F-score损失[141]和Dice-score损失[27],也被引入到图像分割任务中,用于处理有偏差的训练集。它们有时能够达到更高的(区域)评价指标,例如IoU, F-score,因为它们的优化目标与这些指标一致。然而,它们并不是专门为捕捉精细结构而设计的,往往会产生“有偏差”的结果,往往会强调大的结构而忽略精细的细节。
为了解决上述问题,我们提出了一种新颖但简单的边界感知分割网络(BASNet),它由预测-精炼网络和混合损失组成,用于高精度的图像分割。预测-改进体系结构的目的是对预测的概率图进行预测和改进。它由一个类似u - net的[98]深度监督[56],[123]“重”编码器-解码器网络和一个具有“轻”编码器-解码器结构的残差细化模块组成。“重”编码器-解码器网络将输入图像转换为分割概率图,而“轻”细化模块通过学习粗图与地面真值(GT)之间的残差来细化预测图。与[85]、[43]、[18]等在多尺度的显著性预测或中间特征图上迭代使用细化模块不同,我们的细化模块只在分割图的原始尺度上使用一次。总的来说,我们的预测-改进架构简洁且易于使用。混合损失结合了二元交叉熵(BCE)[17]、结构相似性(SSIM)[117]和IoU损失[75],在像素级、补丁级和地图级三个层次上监督训练过程。我们没有使用显式的边界损失(NLDF+ [72], C2S [61], BANet[104]),而是在混合损失中隐式地注入精确边界预测的目标,考虑到这可能有助于减少从边界和其他区域学习到的信息在图像上交叉传播的虚假误差(见图1)。

图1所示。BASNet在显著目标检测(上)和伪装目标检测(下)上的样本结果。
除了提出新的分割技术外,开发新的分割应用对分割领域的发展也起着非常重要的作用。
因此,我们开发了两个新的基于basnet的应用程序:AR COPY & PASTE1和OBJECT CUT2。AR复制和粘贴是建立在我们的BASNet模型和增强现实技术的移动应用程序。通过使用手机,它提供了一种新颖的交互式用户体验
可以“复制”现实世界的目标,并将其“粘贴”到桌面软件中。具体来说,AR COPY & PASTE允许用户使用移动设备拍摄对象的照片。
然后,我们的远程BASNet服务器返回的背景删除对象将显示在摄像机视图中。在这个视图中,“复制”对象与真实场景视频流重叠。用户可以移动并将移动摄像头对准桌面屏幕上的特定位置。然后轻敲移动设备屏幕,触发“粘贴”操作,将对象从移动设备传输到桌面打开的软件中。同时,OBJECT CUT基于我们的BASNet模型提供了基于web的图像背景自动去除服务。
可以从本地机器或通过URL上传图像。这个应用程序极大地方便了没有图像编辑经验或软件的用户的背景删除。主要贡献如下:
•我们开发了一种新的边界感知图像分割网络BASNet,该网络由深度监督编码器-解码器和残差细化模块组成,以及融合BCE、SSIM和IoU的新型混合损失,在像素级、补丁级和地图级三个层次上监督准确图像分割的训练过程。
•我们对所提出的方法进行了全面的评估,包括在6个广泛使用的公共显著目标分割数据集上与25种最先进(SOTA)方法进行比较,在SOC(杂波中显著目标)数据集上与16种模型进行比较,并在3个公共COD数据集上与13种隐蔽目标检测(COD)模型进行比较。BASNet在区域评估指标方面实现了非常有竞争力的性能,而在边界评估指标方面优于其他模型。
•我们开发了两个(接近)商业应用,AR复制粘贴和对象剪切,基于我们的BASNet。这两个应用进一步证明了该模型的简单性、有效性和高效性。
与本工作的CVPR版本[95]相比,做了以下扩展:首先,对杂化损耗设计进行了更深入的理论解释。其次,在不同的数据集上,包括在杂波中突出目标(SOC)和COD上进行更全面和深入的实验。第三,开发了两个(接近)商业应用,AR复制粘贴和对象剪切。
2 相关工作
2.1传统的图像分割方法
分水岭[108]、图切[52]、[53]、活动轮廓[82]、感知分组[92]以及基于这些方法的交互方法主要依赖于精心设计的手工特征、目标函数和优化算法。分水岭和图割方法是基于区域像素相似度对图像进行分割,因此它们在分割非常精细的结构和实现平滑准确的分割边界方面效果较差。
活动轮廓和感知分组方法可以看作是基于边界的方法。活动轮廓法通过三维函数的水平集来表示二维分割轮廓。该方法不直接对二维轮廓进行演化,而是对三维函数进行演化以找到最优分割轮廓,避免了复杂的二维轮廓分割和合并问题。感知分组方法通过对给定图像中检测到的边缘片段或线段子集进行选择和分组,形成待分割目标的闭合或开放轮廓,从而对图像进行分割。然而,尽管这些方法能够产生相对准确的边界,但它们对噪声和局部极小值非常敏感,这通常导致鲁棒性较差且性能不可靠。
2.2 基于补丁的深度模型
为了提高鲁棒性和准确性,深度学习方法被广泛引入到图像分割中[87]。早期的深度方法使用现有的图像分类网络作为特征提取器,并将图像分割任务制定为基于patch的图像像素(超像素)[58],[69],[109],[142],[60]分类问题。
由于深度神经网络具有较强的拟合能力,这些模型极大地提高了某些任务的分割鲁棒性。然而,它们仍然无法产生高的空间精度,更不用说分割精细结构了。
主要原因可能是,在逐块模型中,像素是基于每个斑块内部的局部特征独立分类的,而没有使用更大尺度的空间背景。
2.3 FCN及其变体
随着全卷积网络(fully convolutional network, FCN)的发展[70],深度卷积神经网络已经成为图像分割问题的标准解决方案。已经提出了大量的深度卷积模型[77]用于图像分割。FCN采用VGG[102]、GoogleNet[105]、ResNet[35]和DenseNet[40]等分类主干,通过丢弃全连通层,直接对特定尺度的卷积层的输出特征进行上采样,构建全卷积图像分割模型。然而,从低分辨率直接上采样无法捕获准确的结构。因此,DeepLab家族[10],[11],[12]用属性卷积代替池化操作,避免降低特征图的分辨率。此外,他们还引入了密集连接的条件随机场(CRF)来改善分割结果。然而,在高分辨率地图上应用亚属性卷积会导致
较大的内存成本和CRF通常会产生嘈杂的分割边界。提出了整体边缘检测(holisticedge Detection, HED)[123]、RCF b[29]和CASENet[130],充分利用图像分类主干的浅、深两个阶段的特征,直接分割边缘。此外,FCN的许多变体[59]、[50]、[37]也被提出用于显著目标检测(二分类图像分割)[116]。这些工作大多集中在开发新的多尺度特征聚合策略或设计新的多尺度特征提取模块上。Zhang等人(Amulet)[136]开发了一个通用框架,用于聚合VGG主干的多级卷积特征。受HED[123]的启发,Hou等人(DSS+)[36]在HED的skiplayer结构中引入了短连接,以更好地利用深层特征。
Chen等人(RAS)开发了一个反向注意力模型,以迭代地改进类似hed架构的侧输出。Zhang等人(LFR)[135]设计了一种对称的全卷积网络,以图像及其反射作为输入,从互补输入空间中学习显著性特征。Zhang等(BMPM)[133]不再采用单向(深到浅或浅到深)的方式传递信息,而是采用可控的双向传递模块在浅层和深层之间传递信息。
2.4编码器-解码器架构
SegNet[3]和U-Net[98]不是直接从骨干网的深层上采样特征,而是采用类似编码器-解码器的结构逐步上采样深层低分辨率特征图。结合跳跃连接,他们能够恢复更多的细节。这些模型的主要特点之一是对称的下采样和上采样操作。为了减少预测中的棋盘伪影,Zhang等人(UCF)[137]重新制定了dropout,并为上采样操作开发了一个混合模块。为了更好地利用骨干提取的特征,Liu等人(PoolNet)[66]使用他们新开发的特征聚合、金字塔池化和全局制导模块构建了解码器部分。此外,堆叠的HourglassNet[81]、CU-UNet[106]、UNet++[146]和U2-Net[94]进一步探索了通过级联或嵌套堆叠来改进编码器-解码器架构的各种方法。
2.5 深度循环模型
递归技术在图像分割模型中得到了广泛的应用。Kuen等人[51]提出使用循环框架对图像子区域进行顺序分割,从而获得完全分割的结果。Liu等(PiCANetR)[68]分别沿特征图的行和列部署双向LSTM,生成逐像素的注意图,用于显著目标检测。Hu等人(SAC-Net)[38]开发了与[68]类似的策略来捕获用于图像分割的空间衰减上下文。
Zhang等人(PAGRN)[138]提出通过多径循环连接将全局信息从深层传输到较浅层。Wang等(RFCN)[111]通过堆叠多个编码器-解码器构建了级联网络反复修正前一阶段的预测错误。Hu等人(RADF+)[39]不是对分割结果进行迭代细化[111],而是对多层深度特征进行循环聚合和细化,以获得准确的分割结果。然而,由于每个循环步骤之间的串行连接,使用“循环”技术的模型在时间成本方面效率相对较低。
2.6 深度粗到精模型
这组模型旨在通过逐步细化粗预测来改善分割结果。Lin等人(RefineNet)[63]开发了一种多路径细化分割网络,该网络利用远程残差连接沿下采样过程挖掘信息。Liu等人(DHSNet)[67]提出了一种分层递归卷积神经网络(HRCNN),以从粗到精的方式对分割结果进行分层渐进的细化。Wang等人(SRM)[113]开发了一种多阶段分割图细化框架,每一阶段从上一阶段提取输入图像和较低分辨率的分割图,以产生更高分辨率的结果。Deng等人(R3Net+)[18]提出了基于浅分辨率、高分辨率和深分辨率低分辨率特征图对分割结果进行交替细化的方法。Wang等人(DGRL)[115]开发了一种global-to-local框架,该框架首先对待分割目标进行全局定位,然后使用局部边界细化模块对这些目标进行细化。从粗到细的模型减少了过拟合的概率,并在精度上显示出有希望的改进。
2.7 边界辅助深度模型
区域和边界是相互决定的。因此,许多模型引入边界信息来辅助分割。Luo等人(NLDF)[72]提出通过融合交叉熵和Mumford-Shah[79]启发的边界IoU来监督从VGG-16改编的4×5网格结构。Li等人(C2S)[61]试图从分割的轮廓中恢复区域显著性分割。Su等人(BANet)[104]开发了一种边界感知分割网络,其中包含三个独立的流:分别用于边界、区域和边界/区域过渡预测的边界定位流、内部感知流和过渡补偿流。Zhao等(EGNet)[140]通过显式建模和融合互补区域和边界信息,提出了一种用于显著目标分割的边缘引导网络。这一类中的大多数模型都明确地使用边界信息作为额外的监督损失或辅助预测流来推断区域段。
在本文中,我们提出了一个简单的预测-细化架构,它利用了编码器-解码器架构和粗到精策略。此外,我们没有明确地使用边界损失或额外的边界预测流,而是设计了一个简单的混合损失,该混合损失隐式地描述了分割预测与地面真相在像素级,补丁级和地图级三个级别之间的不相似性。预测-细化体系结构结合混合损失为图像分割提供了一个简单而强大的解决方案,并且一些接近商业应用。
3 方法
3.1概述
我们的BASNet架构由两个模块组成,如图2所示。预测模块是一个类似u - net的密集监督编码器-解码器网络[98],它从输入图像中学习预测分割概率图。多尺度残差细化模块(RRM)通过学习粗映射和GT之间的残差来细化预测模块的结果映射。

3.2预测模块
与U-Net[98]和SegNet[3]的精神相同,我们将分割预测模块设计为编码器-解码器时尚,因为这种架构能够同时捕获高级全局上下文和低级细节。为了减少过拟合,受HED[123]的启发,每个解码器阶段的最后一层由GT监督(见图2)。编码器有一个输入卷积层和六个由基本res_block组成的阶段。输入卷积层和前4级采用ResNet-34[35]。不同之处在于,我们的输入层有64个卷积过滤器,大小为3×3,步幅为1,而不是大小为7×7,步幅为2。此外,在输入层之后没有池化操作。这意味着第二阶段之前的特征图与输入图像具有相同的空间分辨率。这与最初的ResNet-34不同,它的分辨率是第一个特征图的四分之一。这种自适应使网络在较早的层中获得更高分辨率的特征图,同时减少了总体的接受域。为了获得与ResNet-34[35]相同的感受野,我们在ResNet-34的第四阶段之后增加了两个阶段。在大小为2的非重叠最大池化层之后,这两个阶段都由三个基本的res-block组成,具有512个过滤器。为了进一步捕获全局信息,我们在编码器和解码器之间添加了一个桥接级。它由三个卷积层组成,有512个膨胀(膨胀=2)[129]3×3滤波器。每个卷积层后面都有一个批处理归一化[42]和一个ReLU激活函数[32]。我们的解码器几乎与编码器对称。每个阶段由三个卷积层组成,然后是批处理归一化和ReLU激活函数。每个级的输入是其前一级和编码器中相应级的上采样输出的连接特征映射。为了实现侧输出映射,桥级和每个解码器级的多通道输出被馈送到一个普通的3 × 3卷积层,然后是双线性上采样和一个s型函数。因此,给定一个输入图像,我们的预测模块在训练过程中产生7个分割概率图。虽然每个预测的地图都被上采样到与输入图像相同的大小,但最后一个地图的精度最高,因此被作为预测模块的最终输出。该输出被传递给细化模块。
3.3 残差细化模块
细化模块(RMs)[43]、[18]通常被设计为残差块[125],用于细化粗分割
通过学习粗糙映射和GT之间的残差Sresidual来映射scoass,如Sref = scoass + Sresidual。(1)在介绍我们的细化模块之前,必须确定术语“粗”。这里的“粗”包括两个方面。一种是模糊和嘈杂的边界(见图3(b)中的一维插图)。另一个是不均匀预测的区域概率(见图3(c))。
如图3(d)所示,真实的预测粗图通常包含两种粗情况

图3所示。一维粗预测的不同方面示意图:(a)红色:GT的概率图,(b)绿色:粗边界与GT不对齐的概率图,(c)蓝色:概率过低的粗区域,(d)紫色:真正的粗预测通常同时存在(b&c)两种问题。
基于局部上下文的残差细化模块(RRM LC),如图4(a),最初是为边界细化而设计的[85]。由于其接受场较小,Islam等人[43]和Deng等人[18]迭代或循环地使用它来细化不同尺度上的分割概率图。Wang等[113]采用[34]中的金字塔池化模块,其中串联了三尺度金字塔池化特征。为了避免池化操作导致的细节丢失,RRM MS(图4(b))使用不同核大小和扩展的卷积[129],[133]来捕获多尺度上下文。然而,这些模块很浅,因此很难捕获高级信息以进行细化。
为了改进图像区域和边界的粗分割图中的不准确性,我们开发了一种新的残差细化模块。我们的RRM采用残差编码器-解码器架构,RRM Our(见图2和图4(c))。它的主要架构与我们的预测模块相似,但更简单。它包含一个输入层、一个编码器、一个桥接、一个解码器和一个输出层。与预测模块不同的是,编码器和解码器都有四个阶段。每个阶段只有一个卷积层。每层有64个大小为3 × 3的过滤器,然后是一个批处理归一化和一个ReLU激活函数。桥接阶段也有一个卷积层,包含64个大小为3 × 3的滤波器,然后进行批处理归一化和ReLU激活。非重叠最大池化用于下采样在编码器中,采用双线性插值对解码器进行上采样。该RM模块的输出作为BASNet最终生成的分割结果。
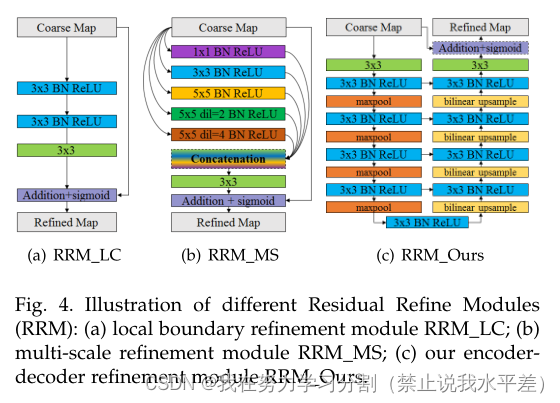
图4所示。不同残差细化模块(RRM)示意图:(a)局部边界细化模块RRM LC;(b)多尺度细化模块RRM MS;(c)我们的编解码器优化模块RRM我们的。
3.4混合损失
我们的训练损失定义为所有输出的总和: L = Σᴷₖ=₁αₖL(k),其中 L(k)是第k个侧输出的损失,K表示输出的总数,αₖ是每个损失的权重。如第3.2节和第3.3节所描述,我们的分割模型在八个输出上进行深度监督,即K = 8,包括来自预测模块的七个输出和来自细化模块的一个输出。
为了获得高质量的区域分割和清晰的边界,我们提出将L(k)定义为混合损失: L(k) = L(k)bce + L(k)ssim + L(k)iou,其中L(k)bce、L(k)ssim和L(k)iou分别表示二元交叉熵损失[17]、结构相似性损失[117]和交并比损失[75]。
二元交叉熵损失L(BCE)[17]是二元分类和分割中最广泛使用的损失,其定义如下: Lbce = - Σ(r,c)[G(r,c) * log(S(r,c)) + (1-G(r,c)) * log(1-S(r,c))],其中G(r,c) ∈ {0, 1}是像素(r, c)的真实标签,S(r,c)是分割对象的预测概率。
结构相似性损失(SSIM)[117]最初是为了图像质量评估而设计的,它捕捉图像的结构信息。因此,我们将其集成到我们的训练损失中,以学习真实标签的结构信息。设x = {xj:j = 1,...,N²}和y = {yj:j = 1,...,N²}分别是从预测概率图S和二元GT掩模G中裁剪的两个相应大小为N×N的补丁的像素值。x和y的SSIM定义如下: Lssim = 1 - (2µxµy + C1)(2σxy + C2) / ((µ²x + µ²y + C1)(σ²x + σ²y + C2)),其中µx、µy和σx、σy分别是x和y的均值和标准差,σxy是协方差,C1 = 0.012,C2 = 0.032 用于避免除以0。
交并比损失(IoU)最初是用于衡量两个集合之间的相似性[44],已成为目标检测和分割的标准评估指标。最近,它已被用作训练损失。为确保其可微分性,我们采用了[75]中使用的IoU损失: Liou = 1 - Σ(r=1,...,H) Σ(c=1,...,W) S(r,c)G(r,c) / (Σ(r=1,...,H) Σ(c=1,...,W) [S(r,c)+G(r,c)-S(r,c)G(r,c)]),其中G(r,c) ∈ {0, 1}是像素(r, c)的真实标签,S(r,c)是分割对象的预测概率。
图5展示了每个损失的影响。图5(a)和(b)是输入图像及其地面真相分割掩模。值得注意的是,图5中的概率图是通过拟合一对图像和其地面真相(GT)掩模生成的。因此,经过一定数量的迭代,所有损失都能够产生完美的结果,因为过度拟合。在这里,我们忽略最终的拟合结果,旨在观察不同的特性。
以及这些损失在拟合过程中存在的问题。(c)、(d)、(e)、(f)列表示中间概率图随训练进度的变化情况。BCE损失是按像素计算的。它不考虑邻域的标签,并且对前景和背景像素的权重相等。这有助于所有像素的收敛,并保证一个相对较好的局部最优。因为明显错误的预测(预测0 0.1 0.9或预测1)公元前产生大的损失,模型训练与公元前损失抑制这些错误给预测在边界值约为0.5,这常常会模糊边界和精细结构,我们可以看到从第二排列(c),在整个前台区域模糊的轮廓,和第三行,下面的电缆背包是较低的概率值。SSIM损失是一种补丁级度量,它考虑每个像素的局部邻域。它为位于前景和背景之间的过渡缓冲区域的像素分配更高的权重,例如边界,精细结构,因此边界周围的损失更高,即使边界和前景其他部分的预测概率相同。值得注意的是,背景区域的损失与前景区域相似,有时甚至更高。然而,背景损失对训练没有贡献,直到背景像素的预测非常接近GT,此时损失从1迅速下降到零。由于SSIM损耗(式5)中的µy、σxy、µxµy、σ2y在背景区域均为零,故SSIM损耗近似为:

由于C1 = 0.012, C2 = 0.032,所以只有当预测x接近于零时,SSIM损失(公式7)才会成为主导项。图5列(d)的第二行和第三行表明,在训练开始的过程中,使用SSIM损失训练的模型能够在前景区域和边界上预测正确的结果,而忽略了背景精度。SSIM损耗的这一特性有助于优化将重点放在边界和前景区域。随着训练的进行,前景的SSIM损失减少,背景的SSIM损失减少
“损失”成为了主导词汇。这是有帮助的,因为预测通常只有在训练过程的后期才接近于零,此时BCE损失变得平缓。SSIM损失保证了仍然有足够的梯度来驱动学习过程。因此,背景预测看起来更清晰,因为概率被推到零。
借据是一种地图级别的度量。更大的区域对IoU的贡献更大,因此用IoU损失训练的模型更强调大的前景区域,因此能够为这些区域产生相对均匀和更可信(更白)的概率。然而,这些模型在精细结构上经常产生假阴性。如图5 (e)列所示,第二排人头和第二、三排背包绳均缺失。
为了充分利用以上三种损耗,我们将它们组合在一起形成混合损耗。BCE用于保持所有像素的平滑梯度,而IoU用于将更多焦点放在前景上。SSIM用于鼓励预测尊重原始图像的结构,通过在边界附近使用更大的损失,并进一步将背景预测推至零。

4 实验
本文的研究重点是提高分割结果的空间精度。因此,我们对两种反向二值类图像分割任务进行了实验:显著目标分割[110]和伪装目标分割[25]。突出目标分割是计算机视觉中的一个热门任务,其目的是根据突出区域的背景对其进行分割。在这个任务中,目标通常与背景有很高的对比度。然而,伪装对象分割是最具挑战性的,因为伪装对象通常具有与其背景相似的外观意味着它们很难被感知和分割。此外,许多伪装对象具有非常复杂的结构和边界。
4.1 实现与设置
我们使用公开可用的Pytorch 1.4.0[84]来实现我们的网络。一台带有AMD Threadripper 2950x 3.5 GHz CPU (64GB 3000 MHz RAM)和RTX Titan GPU (24GB内存)的16核PC用于培训和测试。在训练期间,每个图像首先调整大小为320×320,然后随机裁剪为288×288。一些编码器参数是从ResNet34模型[35]初始化的。其他卷积层由Xavier[30]初始化。我们使用Adam优化器[49]来训练我们的网络,它的超参数被设置为默认值,其中初始学习率lr=1e-4, beta =(0.9, 0.999), eps=1e-8,权重衰减=0。我们训练网络直到损失收敛,而不使用验证集。
训练损失在400k次迭代后收敛,批大小为8个,整个训练过程耗时约110小时。在测试过程中,将输入图像的大小调整为320×320并输入到网络中,得到其分割概率图。然后,概率图(320×320)被调整回输入图像的原始大小。两个调整大小的过程都使用双线性插值。对于320×320图像的推断只需要0.015s (70 fps,与我们的CVPR版本[95]中报道的不同,其中包括IO时间)。
4.2 评价指标
五个指标被用来评估所提出的模型的性能。(1)加权F测度F wβ[74]对精度和召回率进行了全面、平衡的评价,能够更好地利用插值、依赖和等重要缺陷。(2)采用松弛边界F-测度F bβ[19]定量评价预测图的边界质量。(3)平均绝对误差M[86]反映了概率图与GT掩模之间的平均每像素差。(4)平均结构测度Sα[22]量化了预测概率图与GT掩模之间的结构相似性。(5)平均增强对准测度Emφ[23]同时考虑了全局相似性和局部相似性。
4.3 显著目标分割实验
4.3.1数据集
对于显著目标分割任务3,我们使用DUTS-TR[110]数据集训练网络,该数据集有10553张图像。在训练之前,通过水平翻转到21106张图像来增强数据集。对于显著目标分割任务,我们在6个常用的显著目标分割基准数据集上对我们的方法进行了评估:SOD[78]、ECSSD[127]、DUT-OMRON[128]、PASCAL-S[62]、HKUIS[58]、DUTS-TE[110]。DUT-OMRON有5168张带有一个或多个对象的图像。这些对象中的大多数在结构上都很复杂。PASCAL-S最初是为语义图像分割创建,由850个具有挑战性的图像组成。DUTS是一个比较大的显著目标分割数据集。它有两个子集:DUTS-TR和DUTS-TE。DUTS-TR中有10553张图片用于训练,DUTS-TE中有5019张图片用于测试。在我们的实验中,使用DUTS-TR来训练显著目标分割模型。HKU-IS包含4,447幅图像,其中许多图像包含多个前景物体。ECSSD包含1,000张语义上有意义的图像。然而,这些图像中前景物体的结构是复杂的。SOD包含300个非常具有挑战性的图像。这些图像要么有单个复杂的大型前景物体与图像边界重叠,要么有多个对比度较低的突出物体。

图6所示。消融研究中不同配置的定性比较。第一行显示了用BCE损失训练的不同架构和用bsi损失训练的BASNet的预测概率图。第二行显示了我们提出的用不同损失训练的预测精化架构的分割图。相应的定量结果见表1。

4.3.2消融研究
在本节中,我们验证了我们模型中使用的每个关键组件的有效性。消融研究分为两个部分:架构消融和损失消融。为了简化,消融实验在ECSSD数据集上进行。这里使用了与第4.1节中描述的相同的超参数。体系结构:为了证明BASNet的有效性,我们报告了我们的模型与其他相关体系结构的定量比较结果。我们以U-Net[98]作为基准网络。然后,我们从提出的编码器-解码器网络开始,并逐步扩展其密集侧输出监督和不同的残差细化模块,包括RRM LC, RRM MS和
RRM我们。表1的上半部分和图6的第一行分别给出了建筑烧蚀研究的定性和定量结果。正如我们所看到的,我们的BASNet体系结构在所有配置中实现了最佳性能。
损失:为了证明我们提出的融合损失的有效性,我们基于我们的BASNet架构在不同的损失上进行了一组实验。表1的结果表明,所提出的混合bsi损耗大大提高了性能,特别是在边界质量方面。可见,我们的杂化损失取得了较好的定性结果,如图6第二行所示。
我们将我们的方法与包括MDF[60]、UCF[137]、Amulet[136]、NLDF[72]、DSS[36]、LFR[135]、C2S[61]、RAS[13]、RADF[39]、PAGRN[138]、BMPM[133]、PiCANet[68]、MLMS[119]、AFNet[26]、MSWS[131]、R3-Net[18]、CapSal[134]、SRM[113]、DGRL[115]、CPD[121]、PoolNet[66]、BANet[104]、EGNet[140]、MINet[83]和GateNet[144]在内的25个最优模型进行显著目标分割任务的比较。为了公平的比较,我们要么使用作者发布的分割图,要么使用他们的默认设置运行他们的公开可用模型。
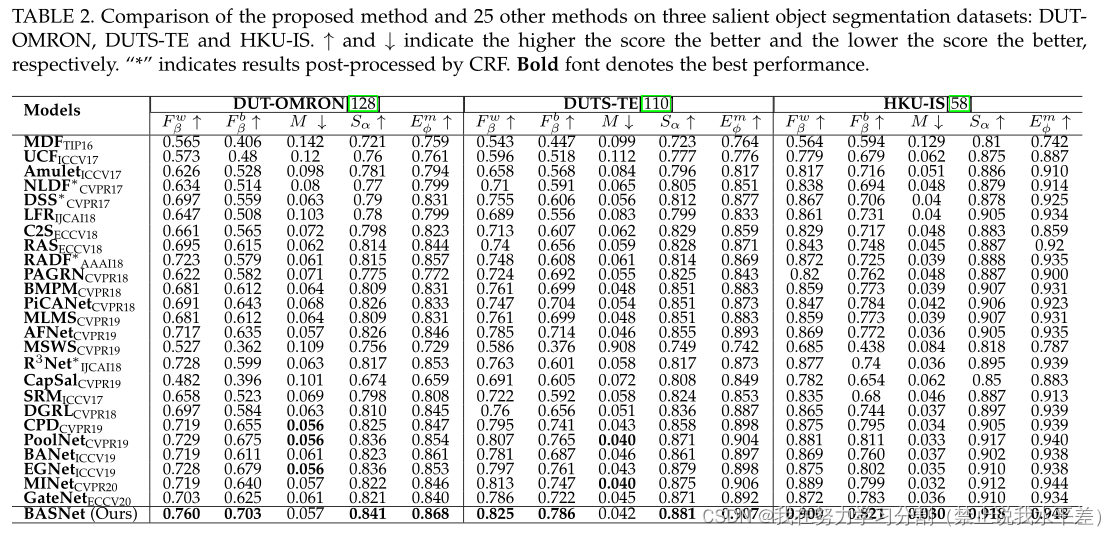
定量评价:表2和表3提供了六个突出的目标分割数据集的定量比较。我们的BASNet在DUT-OMRON、dut - te、HKU-IS、ECSSD和SOD数据集上的几乎所有指标都优于其他模型,除了DUT-OMRON和DUTS-TE上的M指标和SOD上的Sα指标。在PASCAL-S数据集上,MINet在三个指标方面表现最好:F wβ, M AE和Emφ。值得注意的是
BASNet在所有6个数据集上都获得了最高的松弛边界F-测度F bβ,表明其捕获边界和精细结构的能力较强。
定性评价:图7显示了我们的BASNet与其他5个典型模型的定性比较。正如我们所看到的,我们的BASNet能够处理不同的具有挑战性的情况,例如对比度相对较低的小目标(第一行),具有复杂边界的大目标(第二行),具有中空结构的目标(第三行)和具有非常精细结构的目标(第四行)。图7的第三和第四行显示了鼓舞人心的结果,其中我们的BASNet预测的分割图包含比GT更多的细节,这些细节揭示了训练数据集和测试数据集的标签之间可能存在的不一致。虽然这些细节的检测通常会导致我们模型的定量评价分数的下降,但它比好的分数更有实际意义。



4.3.4失败案例我们的BASNet在SOD数据集上的三个典型失败案例如图9所示。例如,在非常复杂的场景中,模型有时会失效,在这些场景中似乎没有明显的物体,如图9第一行所示。第二行给出了“显著性混淆”的典型失败案例,即场景包含多个独立的“显著”目标,但其中只有一个被标记。在这些情况下,我们的BASNet有时会失败,因为缺乏识别多个连接目标之间微小显著性差异的能力。最近的不确定性模型[132]可能是解决方案之一。
4.3.5基于属性的分析除了最常用的显著目标分割数据集,我们还在另一个数据集SOC[24]上测试了我们的模型。SOC数据集包含复杂的场景,比之前的6个SOD数据集更具挑战性。此外,SOC数据集还根据图像的属性将图像分为AC (Appearance Change)、BO (Big Object)、CL (Clutter)、HO (Heterogeneous Object)、MB (Motion Blur)、OC (Occlusion)、OV (off - view)、SC (Shape Complexity)和SO (Small Object)等9组。我们在DUTS-TR和SOC数据集[24]的训练集(1800张带有显著目标的图像)上训练我们的BASNet,并评估它们在SOC- sal测试集上的性能。测试集中总共有600张带有显著目标的图像。每个图像可以被分类为一个或多个属性(例如ac和BO)。
定量评估:表4展示了我们的BASNet与其他16个最先进的模型之间的比较,这些模型包括Amulet[136]、DSS[36]、NLDF[72]、c3s - net[61]、SRM[113]、R3Net[18]、BMPM[133]、DGRL[115]、PiCANetR (PiC(R))[68]、RANet[14]、AFNet[26]、CPD[121]、PoolNet[66]、EGNet[140]、BANet[104]和SCRN[122],基于属性的性能。正如我们所看到的,我们的BASNet实现了对现有方法的明显改进。特别是,我们的BASNet将不同属性的边界度量F bβ提高了很大的幅度(超过5%,有时超过10%)。
定性评价:图8提供了我们的BASNet和其他基线模型的定性比较。正如我们所看到的,BASNet能够处理不同的挑战,

包括小物体(第1行)、视野外物体(第2行)、遮挡目标(第3行)和形状复杂物体(第4行)。
4.4 伪装目标分割实验
为了进一步评估所提出的BASNet的性能,我们还在伪装对象分割(COS)任务上对其进行了测试[126],[55],[25]。与显著目标分割相比,COS是一项相对较新的、更具挑战性的任务。因为伪装后的目标和背景之间的对比度有时非常低。
此外,目标通常具有与其背景相似的颜色和纹理。此外,这些目标的形状或结构有时可能非常复杂。
4.4.1的数据集
我们在CHAMELEON[103]、CAMO-Test[54]和COD10K-Test数据集[25]上测试了我们的模型。变色龙[103]包含76张由独立摄影师拍摄的图像。
这些照片被摄影师标记为伪装动物的好例子。CAMO[54]包含伪装和非伪装子集。我们使用伪装子集,它包括两个子集:CAMO-Train(1000张图像)和CAMO-Test(250张图像)。
COD10K[25]是目前最大的伪装目标检测数据集。它包括各种自然场景中的78个物体类别的10,000张图像。有5066张图像被精确的(消光级)二元掩模密集标记。
COD10K由3040张用于训练的图像(COD10KTrain)和2026张用于测试的图像(COD10K- test)组成。公平相比之下,我们使用与SINet[25]相同的训练集。

4.4.2 与先进的技术比较
为了验证提出的BASNet在伪装目标分割任务上的性能,我们将BASNet与13种最先进的模型进行了比较,包括FPN[64]、MaskRCNN[33]、PSPNet[139]、UNet++[146]、PiCANet[68]、MSRCN[41]、PFANet[143]、HTC[9]、PoolNet[66]、ANetSRM[54]、CPD[121]、EGNet[140]和SINet[25]。为了公平比较,不同模型的结果要么由作者提供,要么使用相同的训练数据,使用默认设置对模型进行重新训练。
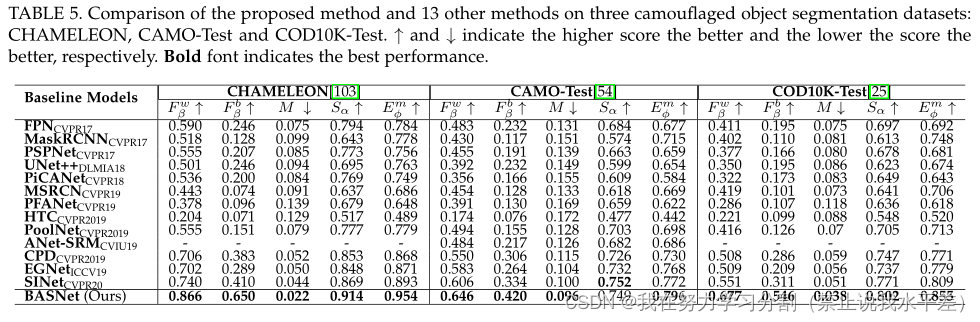
定量评价:定量评价结果如表5所示。正如我们所看到的,我们的BASNet在几乎所有指标中都实现了最佳性能,具有很大的优势。SINet是第二好的模型。
EGNet和CPD相互竞争,可以排在第三和第四名。我们的BASNet提高了加权F-度量F- β↑,边际较大(CHAMELEON, CAMO-Test和COD10K-Test分别为12.6%,4.0%和12.6%)。特别是,在CHAMELEON, CAMO-Test和COD10K-Test数据集上,我们的BASNet在松弛边界F-measure F bβ↑方面比第二好的模型SINet高出24.0%,8.6%和23.5%。
这揭示了我们的BASNet在捕获边界和精细结构方面的有效性和准确性。在M↓方面,我们的BASNet在三个数据集上分别降低了50.0%、4.0%和25.5%的度量。对于结构测量,Sα↑,我们的BASNet相对于第二最佳模型的改进也很显著(4.5%和3.1%)
在CHAMELEON和COD10K-Test数据集上),而在CAMO-Test数据集上s - α下降了0.3%。与SINet相比,Emφ↑同时考虑了局部和全局结构相似性。正如我们所看到的,我们的BASNet在Emφ↑中比在Sα↑中实现了更大的改进(分别在三个数据集上实现了6.1%,2.4%和4.6%)。
定性评价:与几个基线模型的定性比较如图11所示。
我们可以看到,我们的BASNet(第三列)能够处理不同类型的具有挑战性的伪装情况,包括低对比度的复杂前景目标(第一行),前景结构非常薄的目标(第2和第5行),被精细物体遮挡的目标(第3行),复杂边界的目标(第4行),极其复杂的中空结构的目标(第5行),低对比度的多个目标(第6行)等。与其他模型的结果相比,我们的BASNet的结果显示了其出色的感知精细结构和复杂边界的能力,这也解释了为什么我们的BASNet能够在伪装目标分割数据集上获得如此高的边界评价分数F bβ↑(见表5)。
4.4.3 故障案例
虽然我们的BASNet优于其他伪装对象分割(COS)模型,并且很少产生完全错误的结果,但在许多COS案例中仍然存在一些假阴性(图10中的第一行)和假阳性预测(图10中的第二行)。值得注意的是,在这些具有挑战性的情况下,其他模型通常具有相同甚至更差的结果。尽管这些失败案例可能不会对评估指标产生巨大影响,但它们会以某种方式限制应用程序并降低用户体验。
















 462
462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









