







paddle深度学习高层API第四天
大家好,这里是三岁,别的不会,擅长白话,今天就是我们的白话系列,内容是paddle2.0新出的高程API,在这里的七日打卡营0基础学习,emmm我这个负基础的也来凑凑热闹,那么就开始吧~~~~
注:以下白话内容为个人理解,如有不同看法和观点及不对的地方欢迎大家批评指正!
课程传送门
注:由于播放器的进度条遮挡,小姐姐的全貌比较难截全,希望各位见谅,特别是小姐姐见谅[戳戳手]
- 老师提到的要点都已经拿 粗体加斜体 标注了!!!(尽职课代表系列)

课程回看
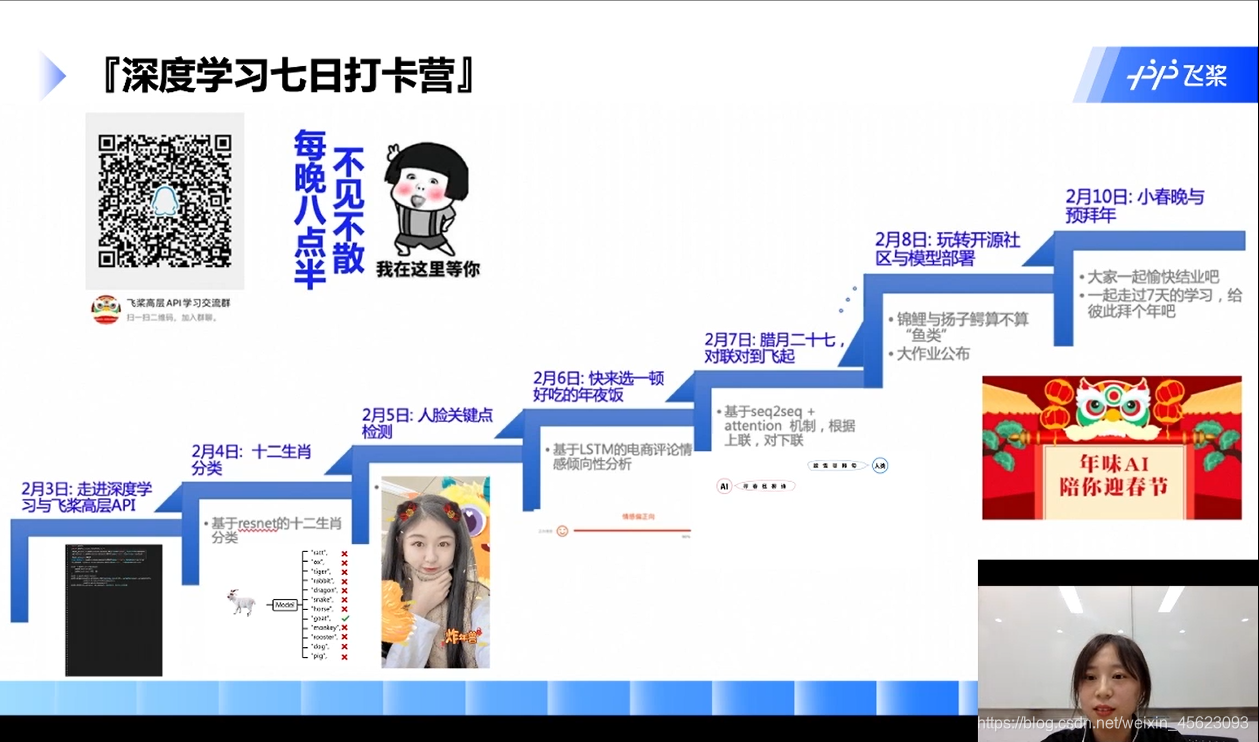
任务目标
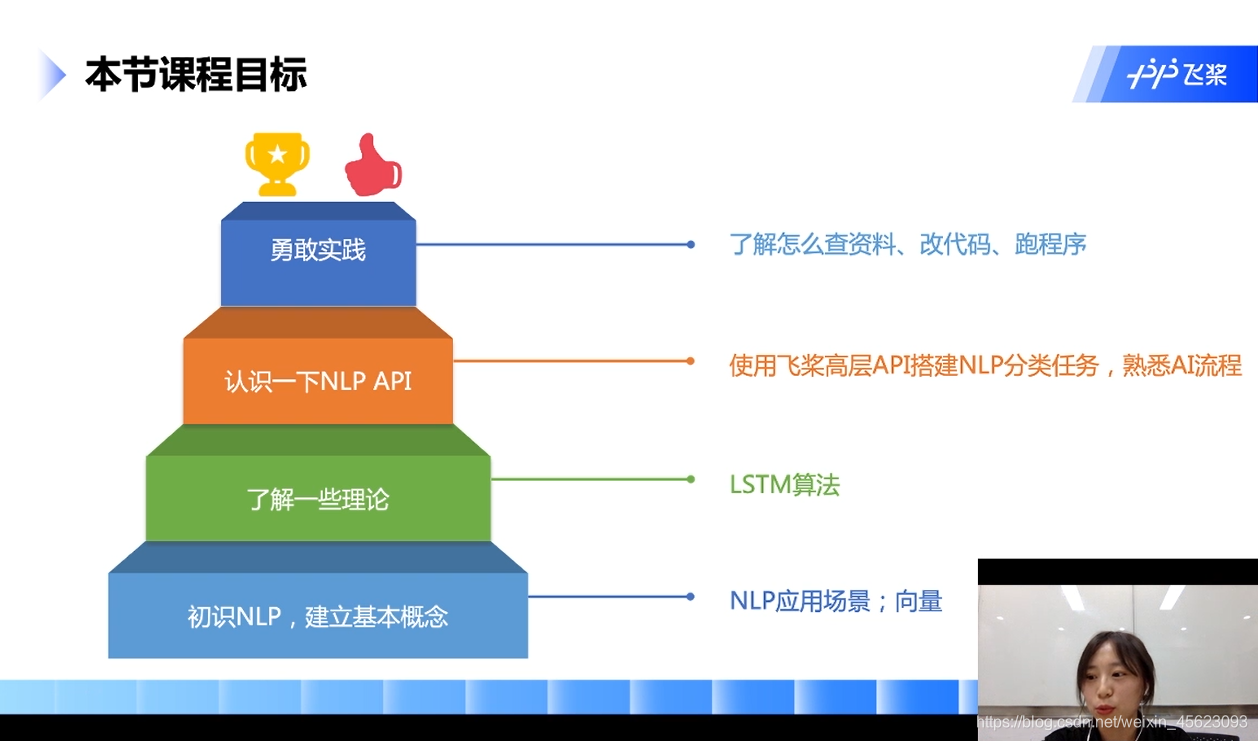
基本概念

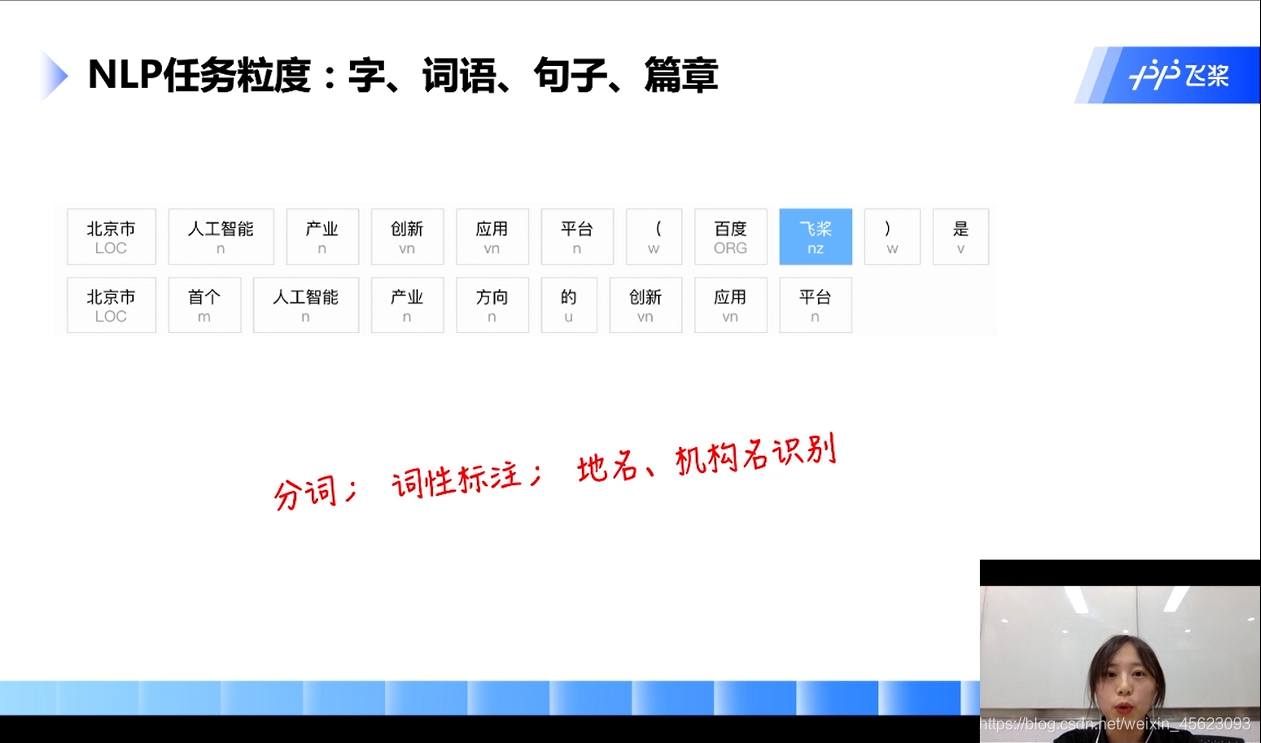
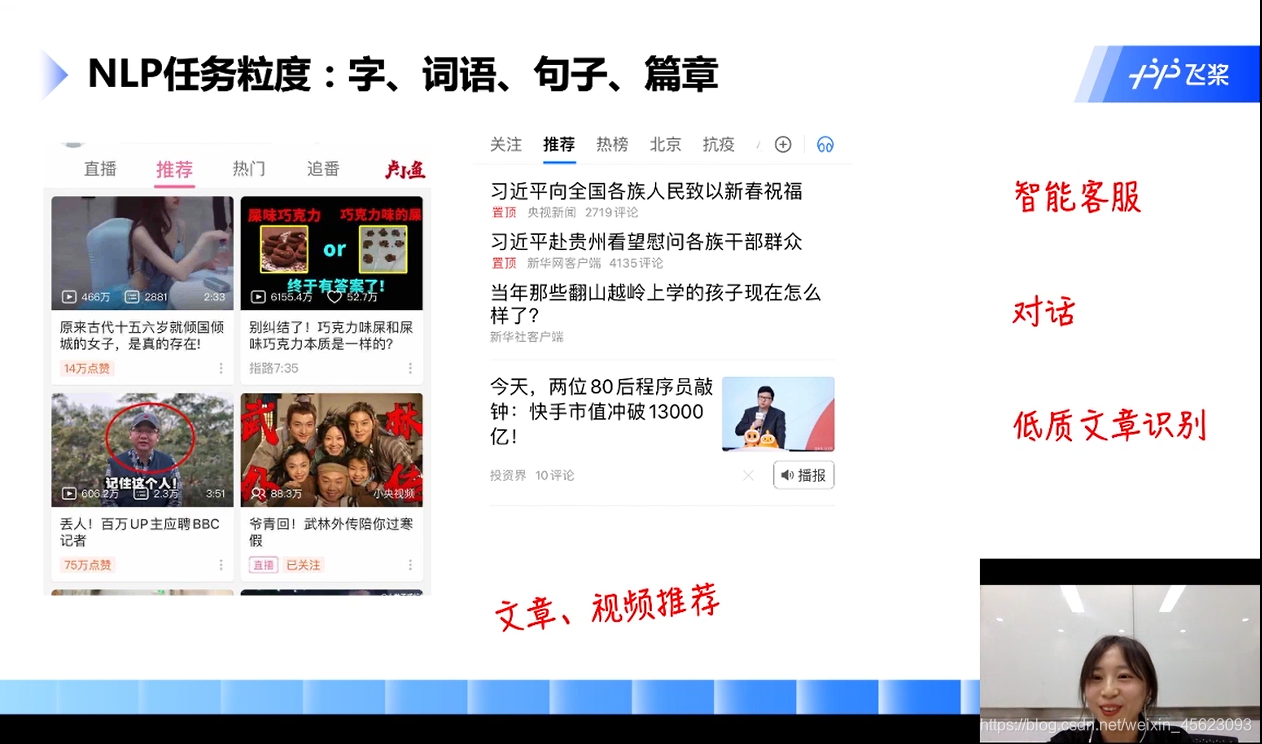
主要的有:分词、词性标注、地名、机构名、快递单信息抽签、搜索、视频文章推荐、智能客服、对话、低质量文章识别……
什么是情感分析
通过一个自然语句的输入分析,这一句话的情感,可以分为正向、负向、中性
文本分类通用步骤
输入:一个自然语言的句子
通过:分词阶段
生成:词向量
接入:一个任务网络(分类器)
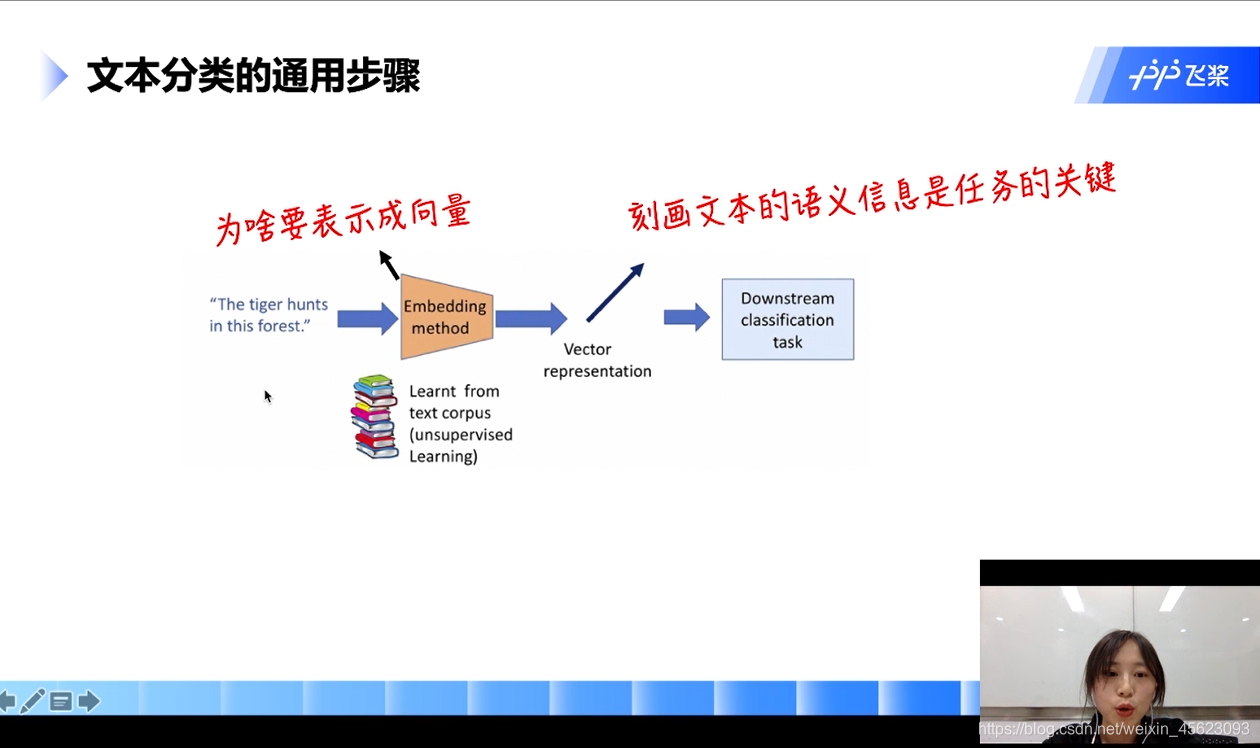
- 为什么词语要以向量的方式来表示?
计算机处理的二进制的数据,只有用向量(张量)表示才能够跟好的处理
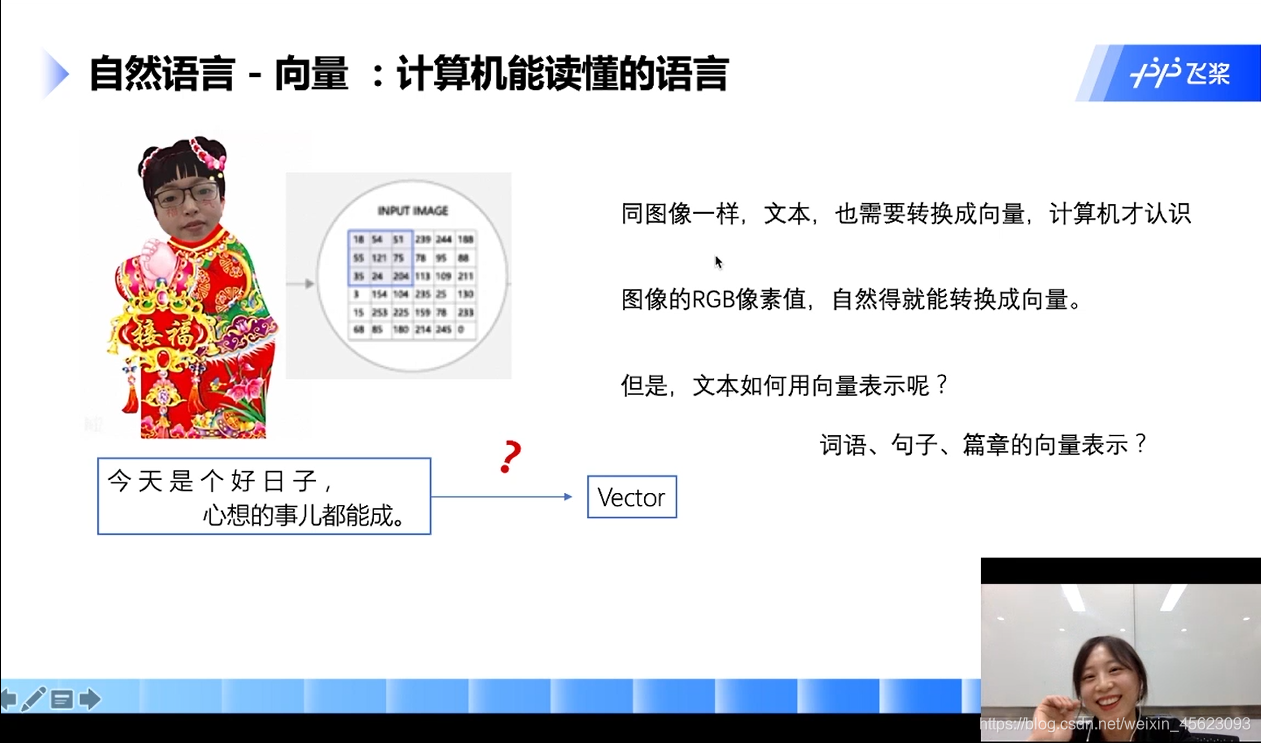
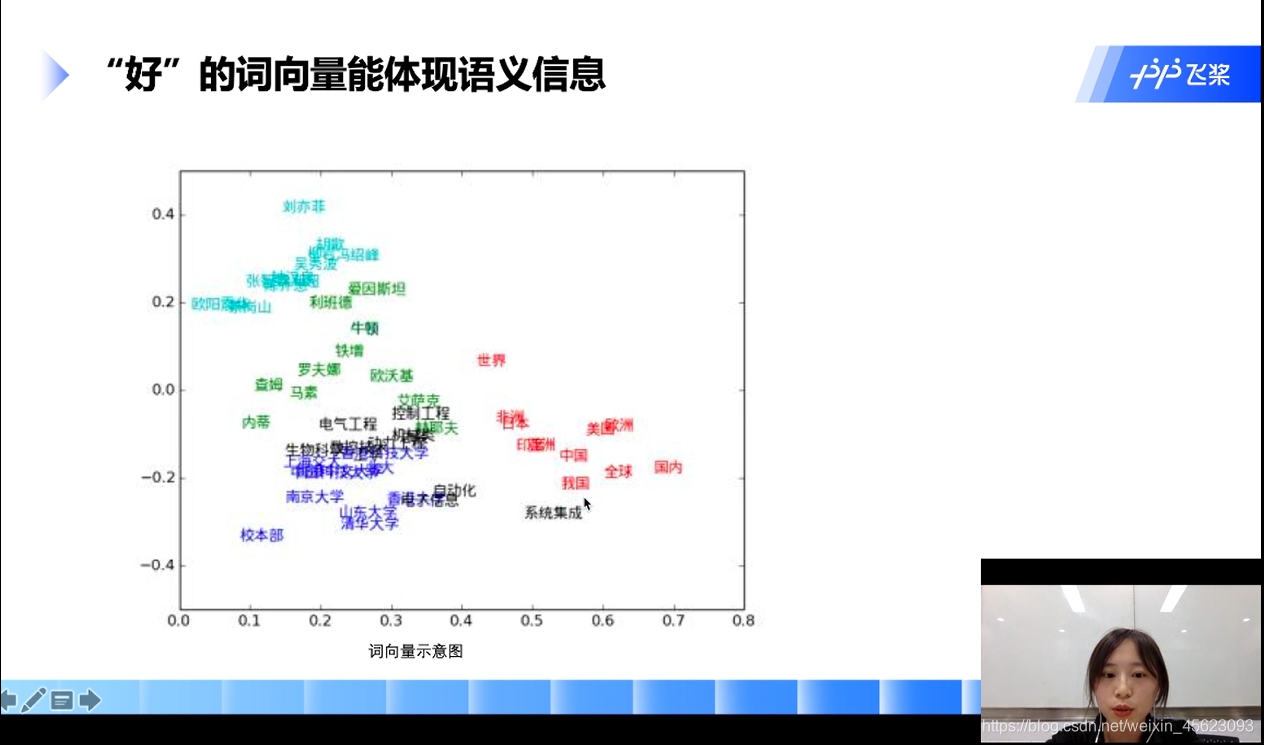
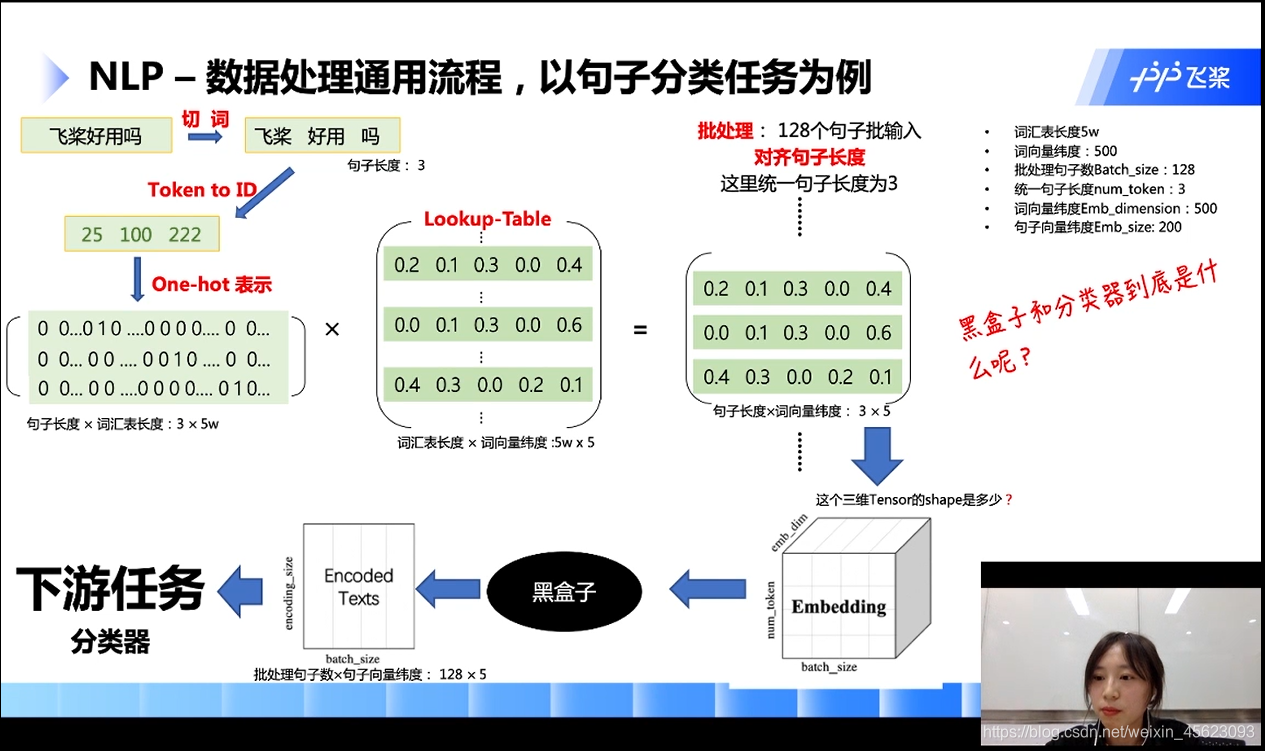
原理介绍

第一步:输入一个自然语言
第二步:切词(或者切字)
第三步:转换成ID(根据词语在词汇表的位置也就是id)
第四步:生成数组(在id位置是1其他位置是0)
注:按照图中的情况进行假设词汇表的长度是5w,那么3个词生成的数组就是(3,5w)
第五步:上面的数组乘以数组(数组的维度是词汇表长度*5的矩阵)
第六步:生成一个新的矩阵(句子长度 * 词向量的长度)
以图为例子: 3个词每一个词用5维的向量表示
第六步:批量处理
如下图:128个数据进行统一的处理就生成了一个3 * 5* 128的三维Tensor,Tensor的大小就是(128, 5, 3)[在里面句子的长度要相等长的要截断,短的要补齐]
第七步:通过黑盒得到一个句子向量(句子的长度这个维度被抹除了)
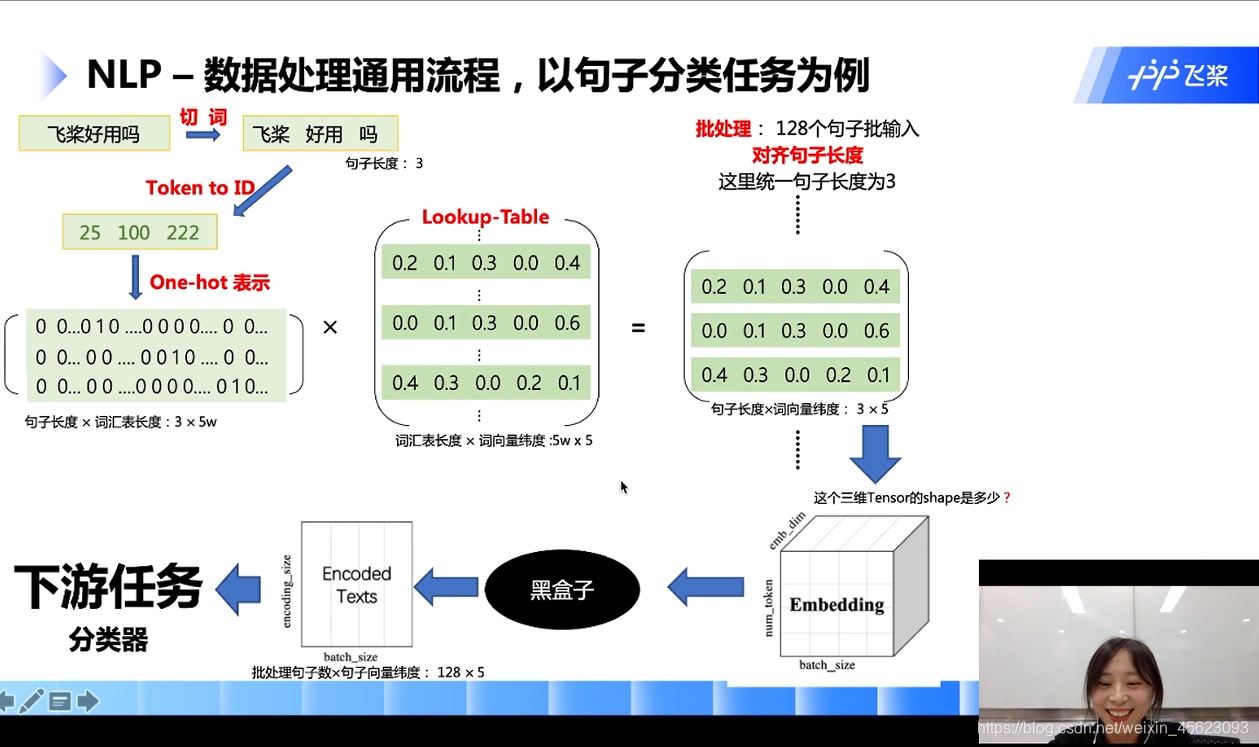
词向量到句子向量
- 加权平均法:
把单个的词向量加起来就是句子向量
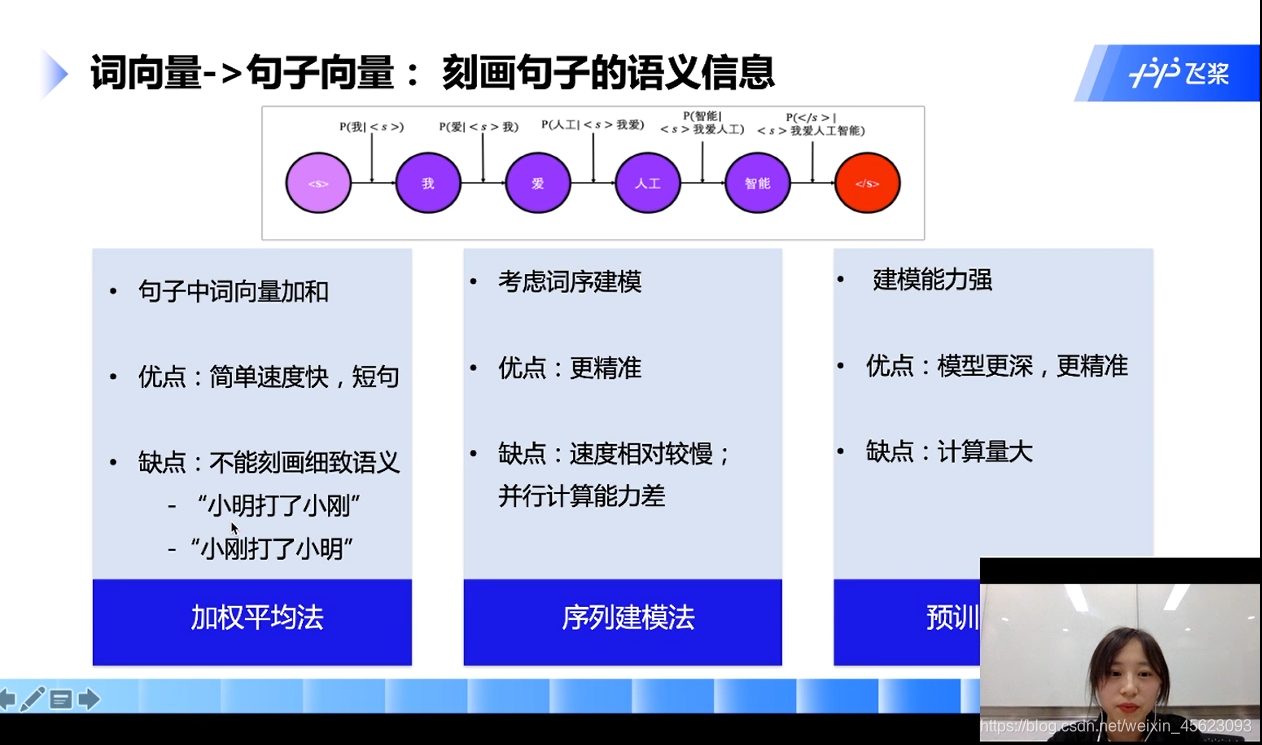
- 序列建模法:
针对加权法的缺点改进的建模方法
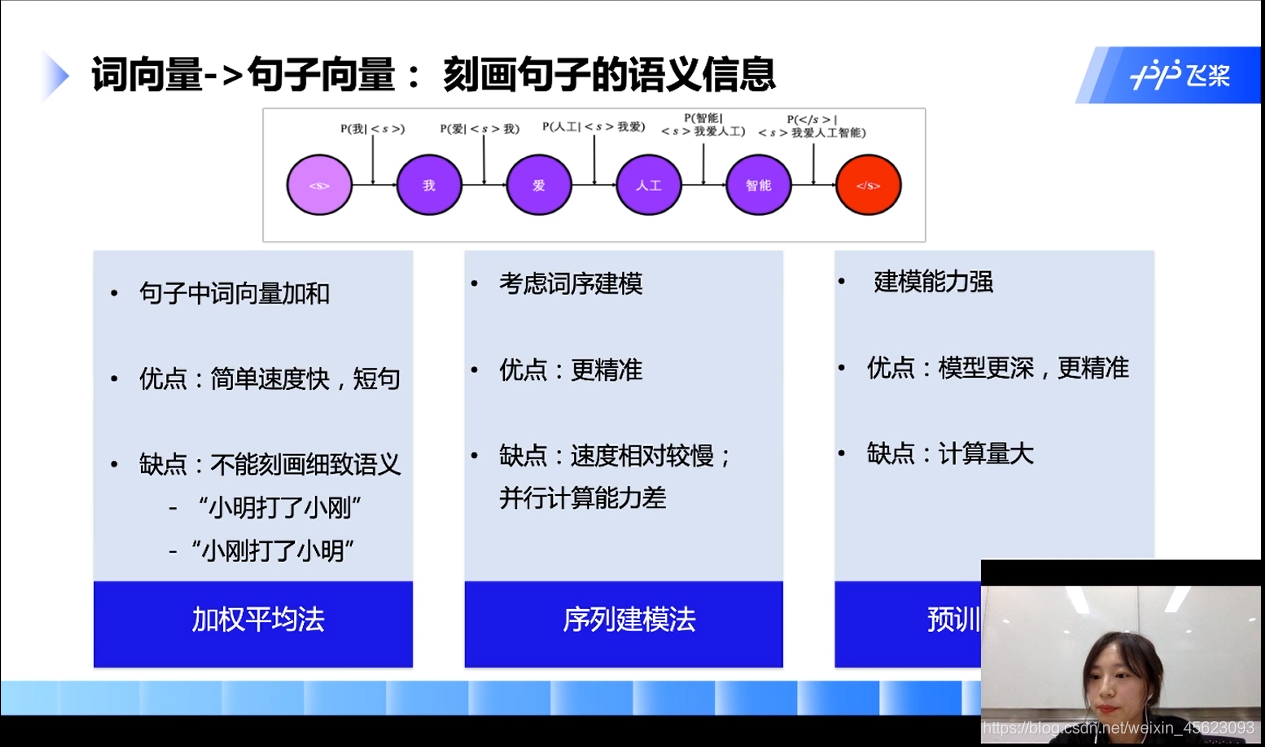
- 预训练模型法
循环神经网络RNN
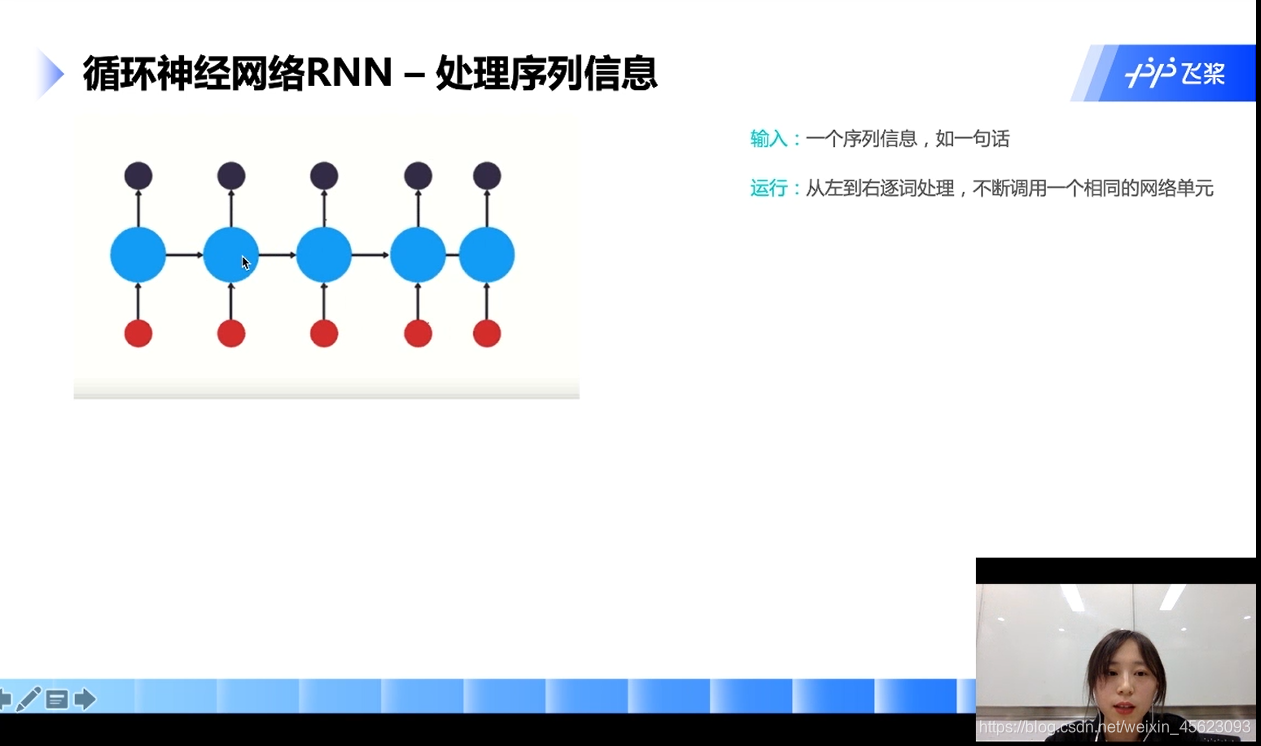
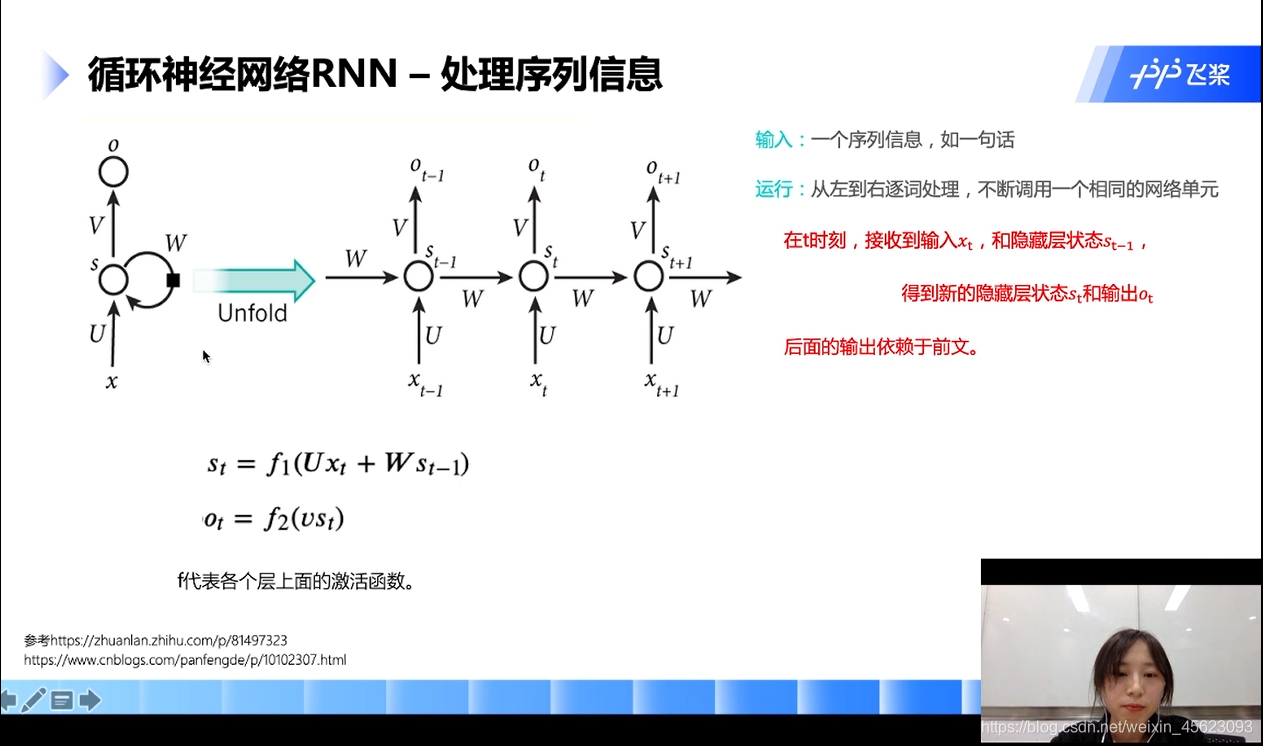
RNN的关键点:词向量从左往右逐词处理,不断的挑整网络。
每个时刻调用的是同一个网络
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2896
2896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











