







PaddlePaddle高层API学习笔记与代码实践记录
课程链接:https://aistudio.baidu.com/aistudio/course/introduce/6771
情感分析是自然语言处理领域一个老生常谈的任务。句子情感分析目的是为了判别说者的情感倾向,比如在某些话题上给出的的态度明确的观点,或者反映的情绪状态等。情感分析有着广泛应用,比如电商评论分析、舆情分析等。

环境介绍
-
PaddlePaddle框架,AI Studio平台已经默认安装最新版2.0。
-
PaddleNLP,深度兼容框架2.0,是飞桨框架2.0在NLP领域的最佳实践。
使用的是beta版本。AI Studio平台后续会默认安装PaddleNLP,在此之前可使用如下命令安装。
# 下载paddlenlp
# !pip install --upgrade paddlenlp==2.0.0b4 -i https://pypi.org/simple
查看安装的版本
import paddle
import paddlenlp
print(paddle.__version__, paddlenlp.__version__)
2.0.0 2.0.0b4
PaddleNLP和Paddle框架是什么关系?

- Paddle框架是基础底座,提供深度学习任务全流程API。PaddleNLP基于Paddle框架开发,适用于NLP任务。
PaddleNLP中数据处理、数据集、组网单元等API未来会沉淀到框架paddle.text中。
- 代码中继承
class TSVDataset(paddle.io.Dataset)
相关导入
import numpy as np
from functools import partial
import paddle.nn as nn
import paddle.nn.functional as F
import paddlenlp as ppnlp
from paddlenlp.data import Pad, Stack, Tuple
from paddlenlp.datasets import MapDatasetWrapper
from utils import load_vocab, convert_example
数据集和数据处理
自定义数据集
映射式(map-style)数据集需要继承paddle.io.Dataset
-
__getitem__: 根据给定索引获取数据集中指定样本,在 paddle.io.DataLoader 中需要使用此函数通过下标获取样本。 -
__len__: 返回数据集样本个数, paddle.io.BatchSampler 中需要样本个数生成下标序列。
class SelfDefinedDataset(paddle.io.Dataset):
def __init__(self, data):
super(SelfDefinedDataset, self).__init__()
self.data = data
def __getitem__(self, idx):
return self.data[idx]
def __len__(self):
return len(self.data)
def get_labels(self):
return ["0", "1", "2"]
# 三分类
def txt_to_list(file_name):
res_list = []
for line in open(file_name):
res_list.append(line.strip().split('\t'))
return res_list
trainlst = txt_to_list('train.txt')
devlst = txt_to_list('dev.txt')
testlst = txt_to_list('test.txt')
# 通过get_datasets()函数,将list数据转换为dataset。
# get_datasets()可接收[list]参数,或[str]参数,根据自定义数据集的写法自由选择。
# 使用内置数据集
#train_ds, dev_ds, test_ds = ppnlp.datasets.ChnSentiCorp.get_datasets(['train', 'dev', 'test'])
train_ds, dev_ds, test_ds = SelfDefinedDataset.get_datasets([trainlst, devlst, testlst])
查看部分数据
label_list = train_ds.get_labels()
print(label_list)
for i in range(10):
print (train_ds[i])
['0', '1', '2']
['环境不错,叉烧包小孩爱吃,三色煎糕很一般', '2']
['刚来的时候让我们等位置,我们就在门口等了十分钟左右,没有见到有人离开,然后有工作人员让我们上来二楼,上来后看到有十来桌是没有人的,既然有位置,为什么非得让我们在门口等位!!!本以为有座位后就可以马上吃饭了,让人内心崩溃的是点菜就等了十分钟才有人有空过来理我们。上菜更是郁闷,端来了一锅猪肚鸡,但是没人开火,要点调味料也没人管,服务质量太差,之前来过一次觉得还可以,这次让我再也不想来这家店了!真心失望', '0']
['口味还可以服务真的差到爆啊我来过45次真的次次都只给差评东西确实不错但你看看你们的服务还收服务费我的天干蒸什么的60块比太古汇翠园还贵主要是没人收台没人倒水谁还要自己倒我的天给你服务费还什么都自己干我接受不了钱花了服务没有实在不行', '0']
['出品不错老字号就是好有山有水有树有鱼赞', '1']
['在江南大道这间~服务态度好差,食物出品平凡,应该唔会再去了', '1']
['我是个挺食得咸的人,但那个黑糖叉烧真是太咸了。招牌的菠萝包,分量好大,可是味道呢,只不过是普通酥皮包里面加了陷,而且那个陷,食不到菠萝,食不到菠萝味,只是一堆糖酱。水鬼重和粉丝煲味道算OK,不过那个鱼腐太硬。必须吐槽一下服务!一个稍胖的女服务员爱理不理的,解释菜式时一副不屑的样子!', '0']
['Theplacewasgoodwasat29floorofplazaThefoodwetried:beeffriedrice..veryplaindoesn’thaveanyspecialtastenotevenanegginsidePorkbelly:nyummyworthtotryDurianpuffpastry:TOOsweet!Beefbraised:wasunderexpectationVegetable:so..sotheservicewasTERRIBLEThewaitressnotkind,doesn’thavewarmgreetingtoforeigner..Underexpectation..', '0']
['早上要11点才开门,排队又要在广场上排,大热天,等死人了,为什么不可以让人进入大堂去等候呢?须要改进', '0']
['应小伙伴的邀请,我评价一下"空中一号"吧,两个---失望(无奈),我两从一进去一看那茶杯就开始吐槽,期待着菜肴能好点,结果一道道的失望[难过][难过]。不好吃!!想来想去,它也就能边吃边看看小蛮腰吧,如此罢了。餐厅玻璃还很脏!!', '0']
['菜色一般,价格高了点而且上碟量少,服务还可以。', '0']
数据处理
为了将原始数据处理成模型可以读入的格式,本项目将对数据作以下处理:
- 首先使用jieba切词,之后将jieba切完后的单词映射词表中单词id。
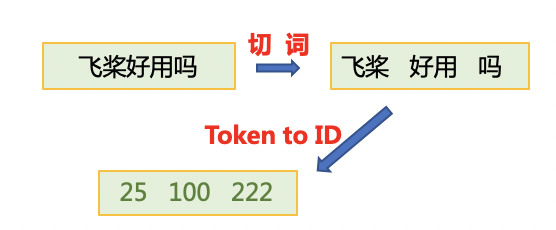
- 使用
paddle.io.DataLoader接口多线程异步加载数据。
其中用到了PaddleNLP中关于数据处理的API。PaddleNLP提供了许多关于NLP任务中构建有效的数据pipeline的常用API
| API | 简介 |
|---|---|
paddlenlp.data.Stack | 堆叠N个具有相同shape的输入数据来构建一个batch,它的输入必须具有相同的shape,输出便是这些输入的堆叠组成的batch数据。 |
paddlenlp.data.Pad | 堆叠N个输入数据来构建一个batch,每个输入数据将会被padding到N个输入数据中最大的长度 |
paddlenlp.data.Tuple | 将多个组batch的函数包装在一起 |
更多数据处理操作详见: https://github.com/PaddlePaddle/PaddleNLP/blob/develop/docs/data.md
# 下载词汇表文件word_dict.txt,用于构造词-id映射关系。
# !wget https://paddlenlp.bj.bcebos.com/data/senta_word_dict.txt
# 加载词表
vocab = load_vocab('./senta_word_dict.txt')
for k, v in vocab.items():
print(k, v)
break
[PAD] 0
构造dataloder
下面的create_data_loader函数用于创建运行和预测时所需要的DataLoader对象。
-
paddle.io.DataLoader返回一个迭代器,该迭代器根据batch_sampler指定的顺序迭代返回dataset数据。异步加载数据。 -
batch_sampler:DataLoader通过 batch_sampler 产生的mini-batch索引列表来 dataset 中索引样本并组成mini-batch -
collate_fn:指定如何将样本列表组合为mini-batch数据。传给它参数需要是一个callable对象,需要实现对组建的batch的处理逻辑,并返回每个batch的数据。在这里传入的是prepare_input函数,对产生的数据进行pad操作,并返回实际长度等。
# Reads data and generates mini-batches.
def create_dataloader(dataset,
trans_function=None,
mode='train',
batch_size=2,
pad_token_id=0,
batchify_fn=None):
if trans_function:
dataset = dataset.apply(trans_function, lazy=True)
# return_list 数据是否以list形式返回
# collate_fn 指定如何将样本列表组合为mini-batch数据。传给它参数需要是一个callable对象,需要实现对组建的batch的处理逻辑,并返回每个batch的数据。在这里传入的是`prepare_input`函数,对产生的数据进行pad操作,并返回实际长度等。
dataloader = paddle.io.DataLoader(
dataset,
return_list=True,
batch_size=batch_size,
collate_fn=batchify_fn)
return dataloader
# python中的偏函数partial,把一个函数的某些参数固定住(也就是设置默认值),返回一个新的函数,调用这个新函数会更简单。
trans_function = partial(
convert_example,
vocab=vocab,
unk_token_id=vocab.get('[UNK]', 1),
is_test=False)
# 将读入的数据batch化处理,便于模型batch化运算。
# batch中的每个句子将会padding到这个batch中的文本最大长度batch_max_seq_len。
# 当文本长度大于batch_max_seq时,将会截断到batch_max_seq_len;当文本长度小于batch_max_seq时,将会padding补齐到batch_max_seq_len.
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=vocab['[PAD]']), # input_ids
Stack(dtype="int64"), # seq len
Stack(dtype="int64") # label
): [data for data in fn(samples)]
train_loader = create_dataloader(
train_ds,
trans_function=trans_function,
batch_size=128,
mode='train',
batchify_fn=batchify_fn)
dev_loader = create_dataloader(
dev_ds,
trans_function=trans_function,
batch_size=128,
mode='validation',
batchify_fn=batchify_fn)
test_loader = create_dataloader(
test_ds,
trans_function=trans_function,
batch_size=128,
mode='test',
batchify_fn=batchify_fn)
模型搭建
使用LSTMencoder搭建一个BiLSTM模型用于进行句子建模,得到句子的向量表示。
然后接一个线性变换层,完成二分类任务。
paddle.nn.Embedding组建word-embedding层ppnlp.seq2vec.LSTMEncoder组建句子建模层paddle.nn.Linear构造二分类器
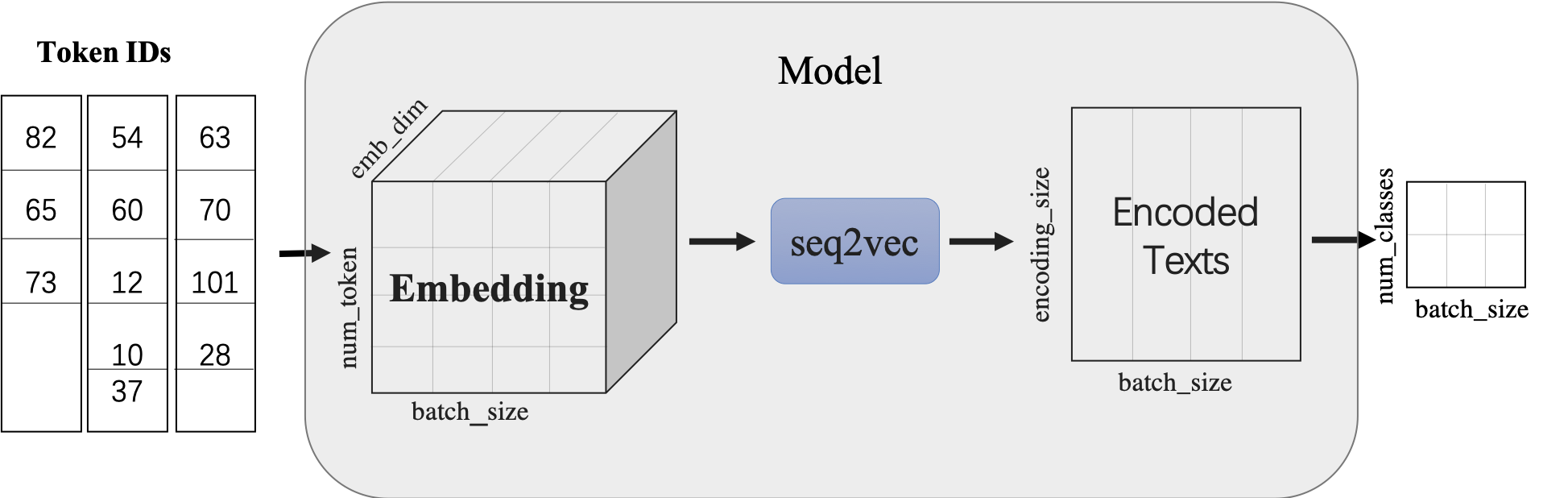
- 除LSTM外,
seq2vec还提供了许多语义表征方法,详细可参考:seq2vec介绍
class LSTMModel(nn.Layer):
def __init__(self,
vocab_size,
num_classes,
emb_dim=128,
padding_idx=0,
lstm_hidden_size=198,
direction='forward',
lstm_layers=1,
dropout_rate=0,
pooling_type=None,
fc_hidden_size=96):
super().__init__()
# 首先将输入word id 查表后映射成 word embedding
self.embedder = nn.Embedding(
num_embeddings=vocab_size,
embedding_dim=emb_dim,
padding_idx=padding_idx)
# 将word embedding经过LSTMEncoder变换到文本语义表征空间中
# 更换模型
# self.lstm_encoder = ppnlp.seq2vec.BoWEncoder(
# emb_dim,
# lstm_hidden_size,
# num_layers=lstm_layers,
# direction=direction,
# dropout=dropout_rate,
# pooling_type=pooling_type
# )
self.lstm_encoder = ppnlp.seq2vec.LSTMEncoder(
emb_dim,
lstm_hidden_size,
num_layers=lstm_layers,
direction=direction,
dropout=dropout_rate,
pooling_type=pooling_type)
# LSTMEncoder.get_output_dim()方法可以获取经过encoder之后的文本表示hidden_size
self.fc = nn.Linear(self.lstm_encoder.get_output_dim(), fc_hidden_size)
# 最后的分类器
self.output_layer = nn.Linear(fc_hidden_size, num_classes)
def forward(self, text, seq_len):
# text shape: (batch_size, num_tokens)
# print('input :', text.shape)
# Shape: (batch_size, num_tokens, embedding_dim)
embedded_text = self.embedder(text)
# print('after word-embeding:', embedded_text.shape)
# Shape: (batch_size, num_tokens, num_directions*lstm_hidden_size)
# num_directions = 2 if direction is 'bidirectional' else 1
text_repr = self.lstm_encoder(embedded_text, sequence_length=seq_len)
# print('after lstm:', text_repr.shape)
# Shape: (batch_size, fc_hidden_size)
fc_out = paddle.tanh(self.fc(text_repr))
# print('after Linear classifier:', fc_out.shape)
# Shape: (batch_size, num_classes)
logits = self.output_layer(fc_out)
# print('output:', logits.shape)
# probs 分类概率值
probs = F.softmax(logits, axis=-1)
# print('output probability:', probs.shape)
return probs
model= LSTMModel(
len(vocab),
len(label_list),
direction='bidirectional',
padding_idx=vocab['[PAD]'])
# 另一方式更换模型
# model = paddlenlp.models.Senta(network='bilstm', vocab_size=len(vocab), num_classes=len(label_list))
model = paddle.Model(model)
模型配置和训练
模型配置
optimizer = paddle.optimizer.Adam(
parameters=model.parameters(), learning_rate=5e-4)
loss = paddle.nn.CrossEntropyLoss()
metric = paddle.metric.Accuracy()
model.prepare(optimizer, loss, metric)
# 设置visualdl路径
log_dir = './visualdl'
callback = paddle.callbacks.VisualDL(log_dir=log_dir)
模型训练
model.fit(train_loader, dev_loader, epochs=25, save_dir='./checkpoints', save_freq=5, callbacks=callback)
The loss value printed in the log is the current step, and the metric is the average value of previous step.
Epoch 1/25
step 10/251 - loss: 1.0968 - acc: 0.3203 - 121ms/step
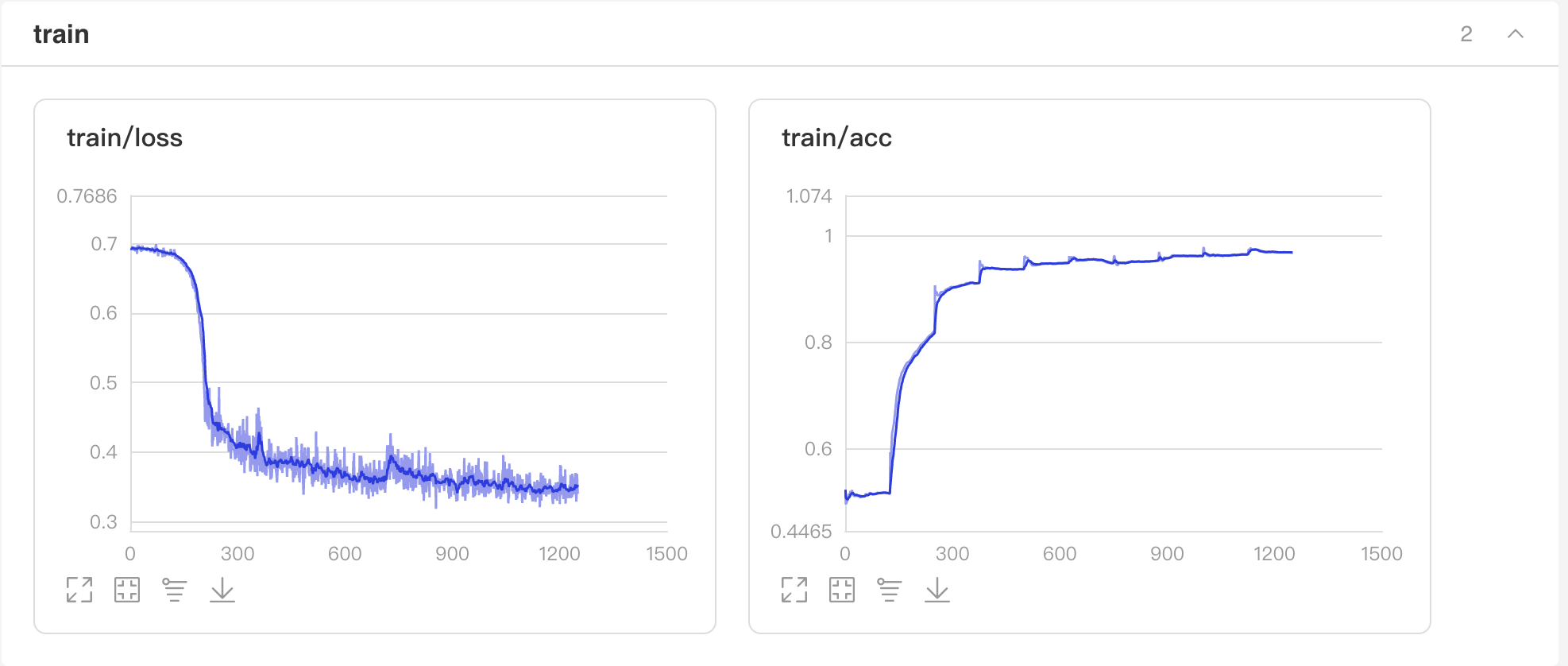
启动VisualDL查看训练过程可视化结果
启动步骤:
- 1、切换到本界面左侧「可视化」
- 2、日志文件路径选择 ‘visualdl’
- 3、点击「启动VisualDL」后点击「打开VisualDL」,即可查看可视化结果:
Accuracy和Loss的实时变化趋势如下:
results = model.evaluate(dev_loader)
print("Finally test acc: %.5f" % results['acc'])
预测
label_map = {0: 'negative', 1: 'positive', 2: 'superduper'}
results = model.predict(test_loader, batch_size=128)[0]
predictions = []
for batch_probs in results:
# 映射分类label
idx = np.argmax(batch_probs, axis=-1)
idx = idx.tolist()
labels = [label_map[i] for i in idx]
predictions.extend(labels)
# 看看预测数据前5个样例分类结果
for idx, data in enumerate(test_ds.data[:10]):
print('Data: {} \t Label: {}'.format(data[0], predictions[idx]))
更换网络
model = paddlenlp.models.Senta(network='bilstm', vocab_size=len(vocab), num_classes=len(label_list))
自定义数据集修改为三分类
class SelfDefinedDataset(paddle.io.Dataset):
def __init__(self, data):
super(SelfDefinedDataset, self).__init__()
self.data = data
def __getitem__(self, idx):
return self.data[idx]
def __len__(self):
return len(self.data)
def get_labels(self):
return ["0", "1", "2"]
使用内置数据集
train_ds, dev_ds, test_ds = ppnlp.datasets.ChnSentiCorp.get_datasets(['train', 'dev', 'test'])














 3548
3548











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









