







目录
1. 图的定义
图是一种较线性表和树更加复杂的数据结构。在图形结构中,结点之间的关系可以是任意的,图中任意两个数据元素之间都可能相关。
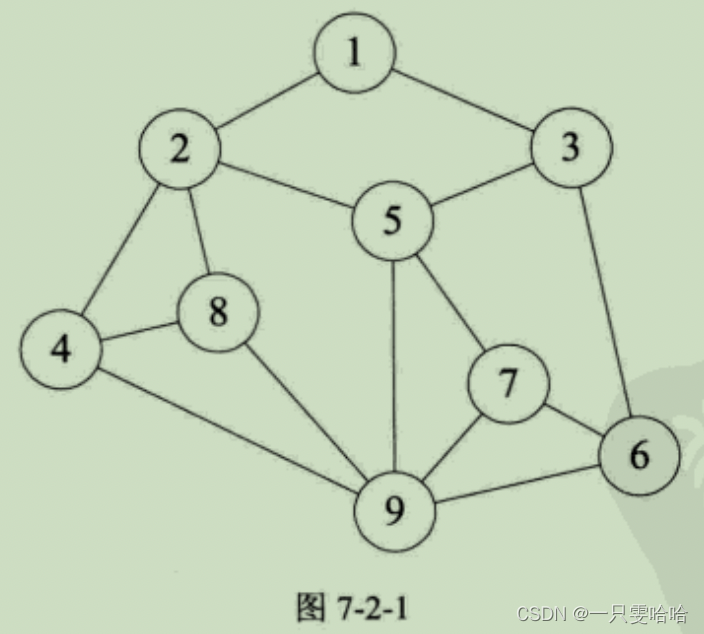
图(Graph)是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:G(V, E),其中,G表示一个图,V是图G中顶点的集合,E是图G中边的集合。
- 线性表中我们把数据元素叫元素,树中将数据元素叫结点,在图中数据元素,我们则称之为顶点(Vertex)。
- 线性表中可以没有数据元素,称为空表。树中可以没有结点,叫做空树。而在图结构中,不允许没有顶点。在定义中,若V是顶点的集合,则强调了顶点集合V有穷非空。
- 线性表中,相邻的数据元素之间具有线性关系;树结构中,相邻两层的结点具有层次关系;而图中,任意两个顶点之间都可能有关系,顶点之间的逻辑关系用边来表示,边集可以是空的。
各种图定义
无向边:若顶点vi到vj之间的边没有方向,则称这条边为无向边(Edge),用无序偶对(vi, vj)来表示。如果图中任意两个顶点之间的边都是无向边,则称该图为无向图(Undirected graphs)。 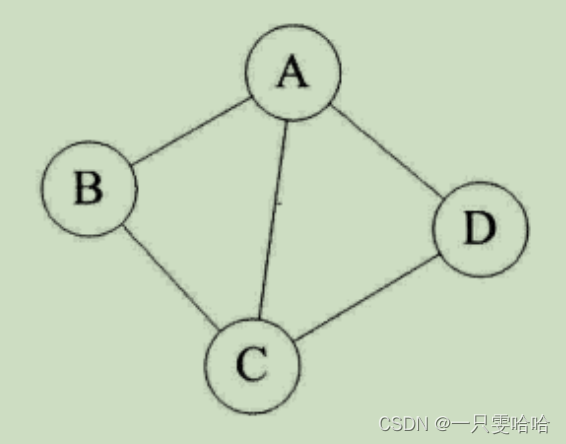
有向边:若从顶点 vi 到 vj 的边有方向,则称这条边为有向边,也称为弧(Arc)。用有序偶<vi, vj>来表示,vj 称为弧尾(Tail),vi 称为弧头(Head)。如果图中任意两个顶点之间的边都是有向边,则称该图为有向图(Directed graphs)。
无向边用小括号"()"表示,而有向边则是用尖括号" <> "表示。
在图中,若不存在顶点到其自身的边,且同一条边不重复出现,则称这样的图为简单图。我们课程里要讨论的都是简单图。
在无向图中,如果任意两个顶点之间都存在边,则称该图为无向完全图。含有n个顶点的无向完全图有 n(n-1)/2 条边。其中每个顶点都要与除它以外的顶点连线。 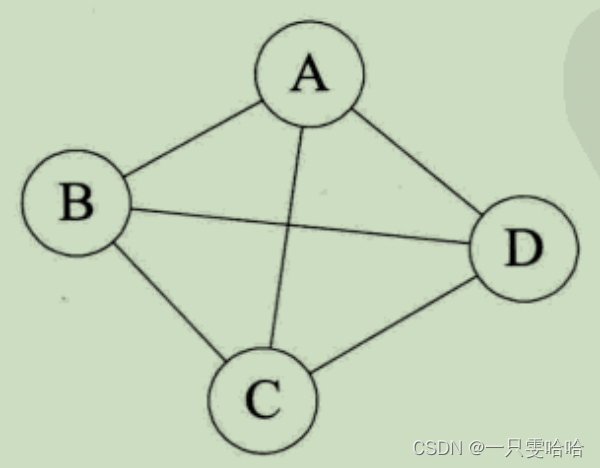
在有向图中,如果任意两个顶点之间都存在方向互为相反的两条弧,则称该图为有向完全图。含有n个顶点的有向完全图有 n(n-1) 条边。 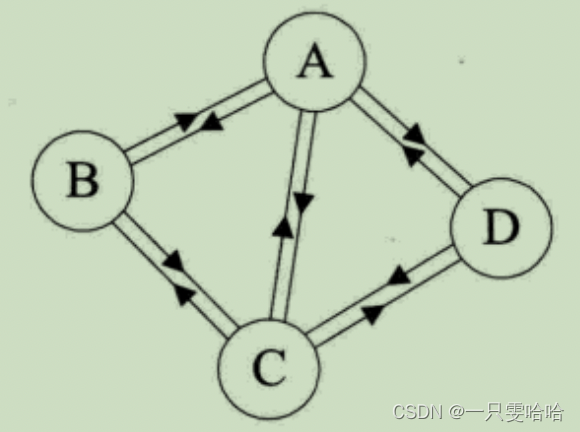 B 和 D 之间少了方向互为相反的两条弧。
B 和 D 之间少了方向互为相反的两条弧。
结论:对于具有 n 个顶点和 e 条边数的图,无向图 0≤e≤n(n-1)/2,有向图 0≤e≤n(n-1)。
有很少条边或弧的图称为稀疏图,反之称为稠密图。这里稀疏和稠密是模糊的概念,都是相对而言的。
有些图的边或弧具有与它相关的数字,这种与图的边或弧相关的数叫做权(Weight)。这些权可以表示从一个顶点到另一个顶点的距离或耗费。这种带权的图通常称为网(Network)。
假设有两个图 G=(V, {E}) 和 G'=(V', {E'}),如果V'⊆V且E'⊆E,则称G'为G的子图(Subgraph)。 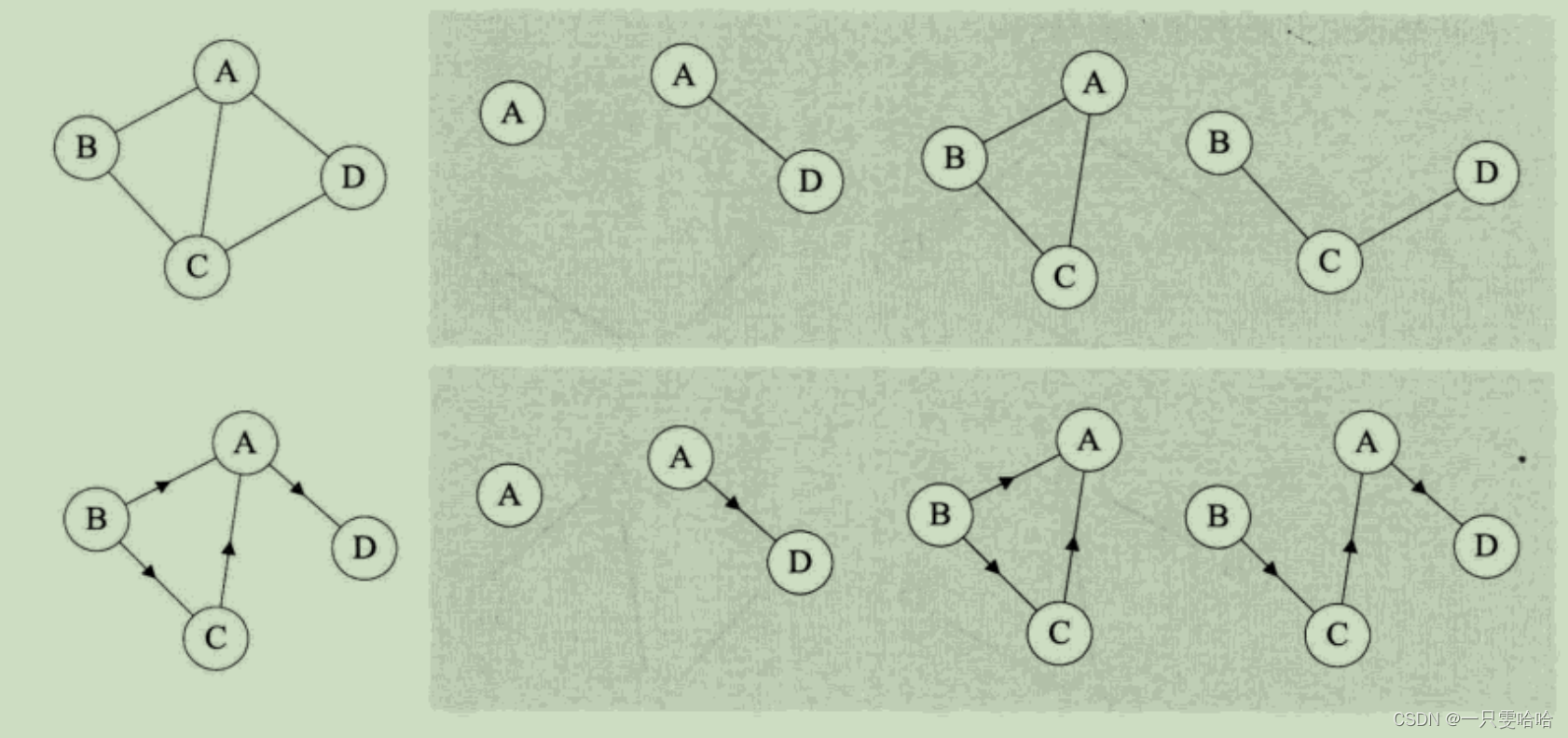
图的顶点与边间关系
对于无向图 G=(V, {E}),如果边(v, v')∈E,则称顶点 v 和 v' 互为邻接点(Adjacent),即 v 和 v’ 相邻接。边(v,v’)依附(incident)于顶点v和v’,或者说(v, v')与顶点v和v’相关联。顶点v的度(Degree)是和v相关联的边的数目,记为TD(v)。 其中边数其实就是各顶点度数和的一半。
对于有向图 G=(V, {E}),如果弧<v, v'>∈E,则称顶点 v 邻接到顶点 v',顶点 v' 邻接自顶点 v。弧<v,v‘>和顶点v,v’相关联。以顶点 v 为头的弧的数目称为v 的入度(InDegree),记为ID(v);以 v 为尾的弧的数目称为 v 的出度(OutDegree),记为OD(v);顶点 v 的度为 TD(v)=ID(v) + OD(v)。其中各顶点的出度和等于各顶点的入度和。
无向图 G=(V, {E}) 中从顶点v 到顶点v’的路径(Path)是一个顶点序列,如果G是有向图,则路径也是有向的。路径的长度是路径上的边或弧的数目。
第一个顶点到最后一个顶点相同的路径称为回路或环(Cycle)。序列中顶点不重复出现的路径称为简单路径。除了第一个顶点和最后一个顶点之外,其余顶点不重复出现的回路,称为简单回路或简单环。
连通图相关术语
在无向图G中,如果从顶点v到顶点v'有路径,则称v和v'是连通的。如果对于图中任意两个顶点 vi、vj∈E,vi和vj都是连通的,则称G是连通图(Connected Graph)。
无向图中的极大连通子图称为连通分量。 强调: 要是子图; 子图要是连通的;
连通子图含有极大顶点数;
具有极大顶点数的连通子图包含依附于这些顶点的所有边。
在有向图G中,如果对于每一对vi、vj∈V、vi≠vj,从 vi 到 vj 和从 vj 到 vi 都存在路径,则称G是强连通图。有向图中的极大强连通子图称做有向图的强连通分量。
一个连通图的生成树是一个极小的连通子图,它含有图中全部的n个顶点,但只有足以构成一棵树的n-1条边。如果一个图有 n 个顶点和小于n-1条边,则是非连通图,如果它多于n-1边条,必定构成一个环,不过有n一1条边并不一定是生成树。 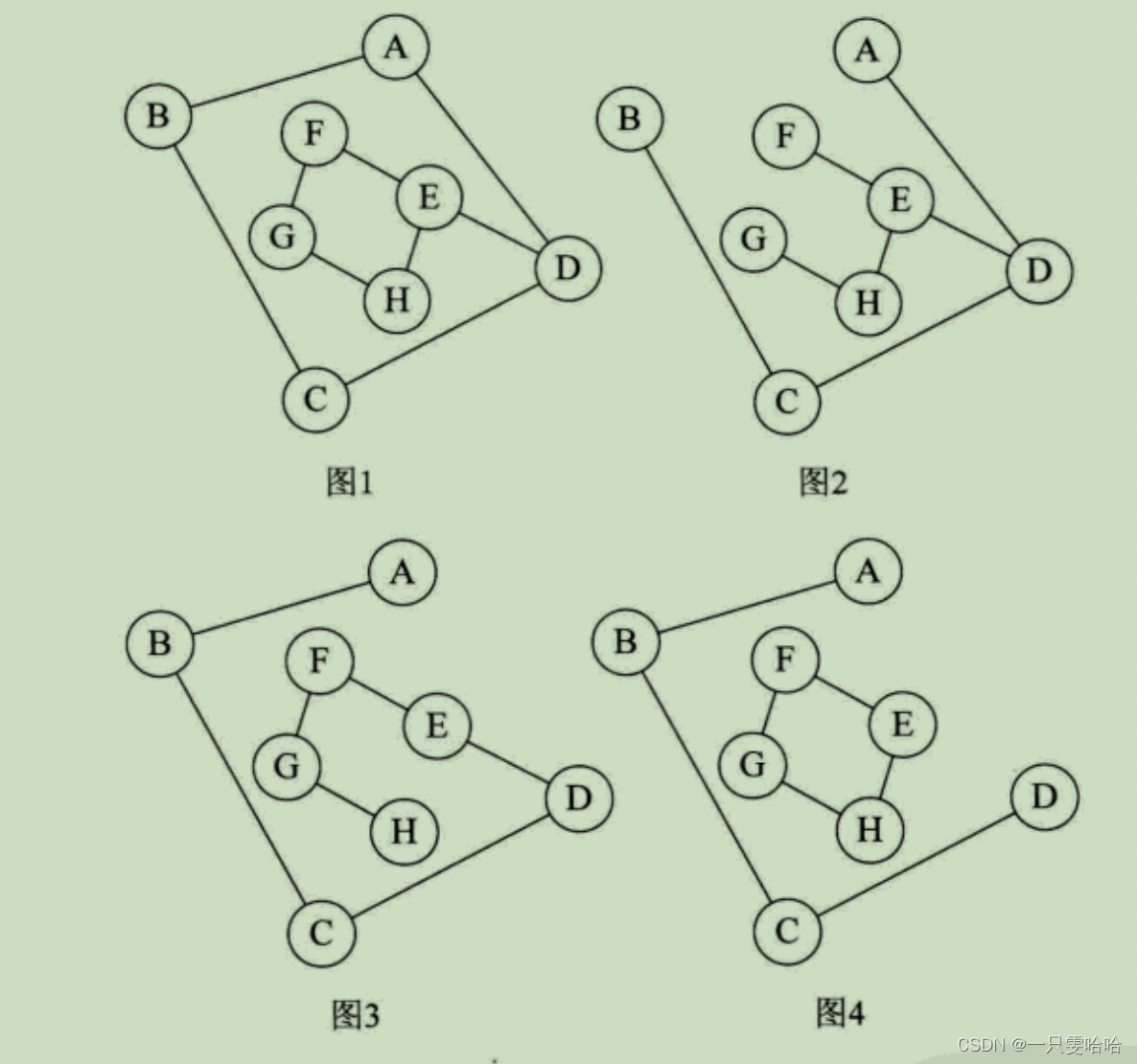
如果一个有向图恰有一个顶点的入度为0,其余顶点的入度均为1,则是一棵有向树。对有向树的理解比较容易,所谓入度为0其实就相当于树中的根结点,其余顶点入度为1就是说树的非根结点的双亲只有一个。一个有向图的生成森林由若干棵有向树组成,含有图中全部顶点,但只有足以构成若干棵不相交的有向树的弧。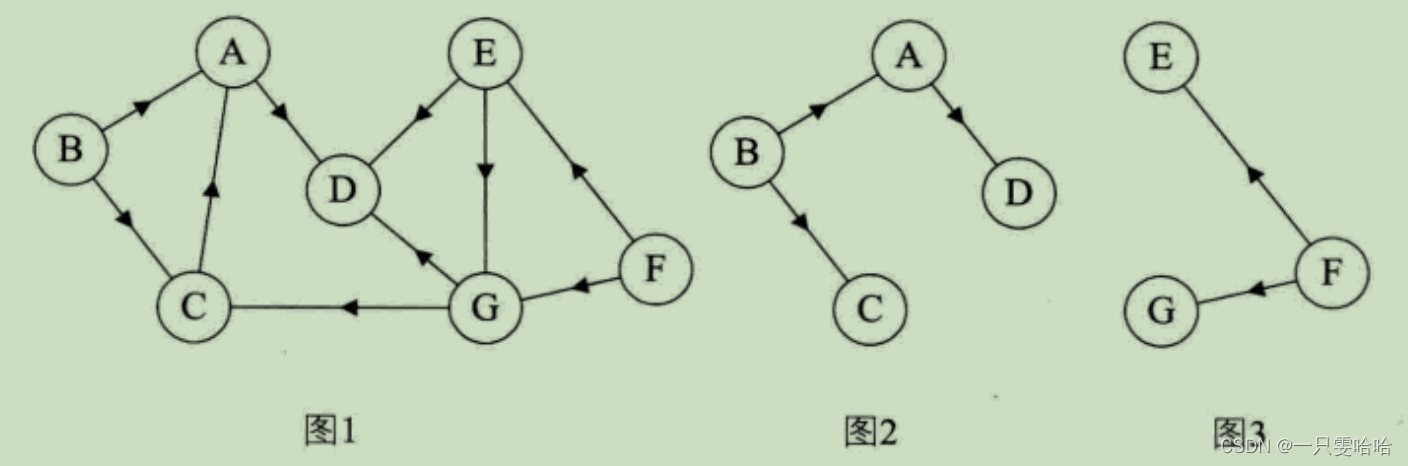
图的定义与术语总结
图按照有无方向分为无向图和有向图。无向图由顶点和边构成,有向图由顶点和弧构成。弧有弧尾和弧头之分。
图按照边或弧的多少分稀疏图和稠密图。如果任意两个顶点之间都存在边叫完全图,有向的叫有向完全图。若无重复的边或顶点到自身的边则叫简单图。
图中顶点之间有邻接点、依附的概念。无向图顶点的边数叫做度,有向图顶点分为入度和出度。
图上的边或弧上带权则称为网。
图中顶点间存在路径,两顶点存在路径则说明是连通的,如果路径最终回到起始点则称为环,当中不重复叫简单路径。若任意两顶点都是连通的,则图就是连通图,有向则称强连通图。图中有子图,若子图极大连通则就是连通分量,有向的则称强连通分量。
无向图中连通且n个顶点n-1条边叫生成树。有向图中一顶点入度为0其余顶点入度为1的叫有向树。一个有向图由其中的若干棵有向树构成生成森林。
2. 图的抽象数据类型

3. 图的存储结构
邻接矩阵
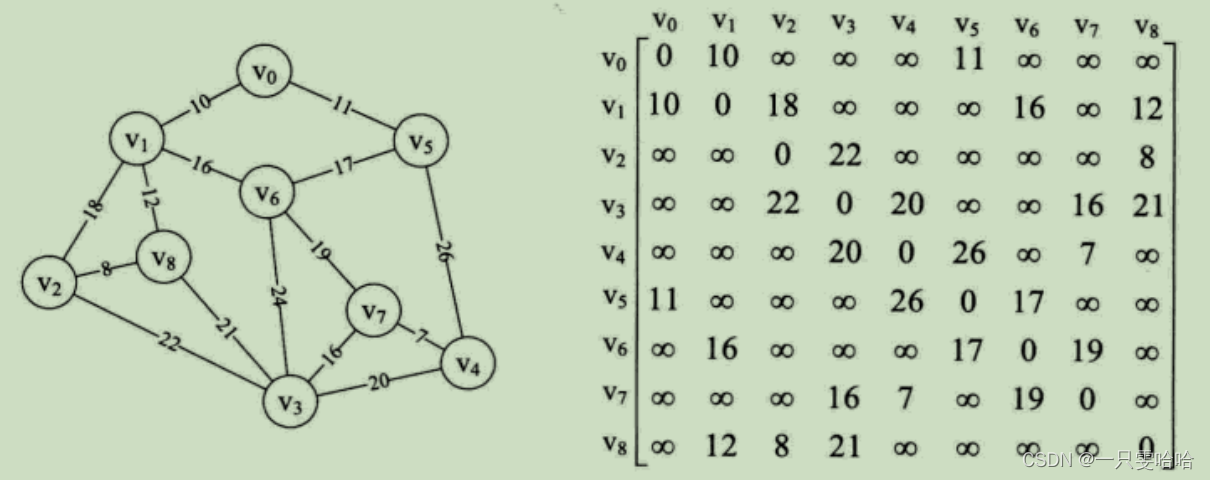
图的邻接矩阵(Adjacency Matrix)存储方式是用两个数组来表示图。一个一维数组存储图中顶点信息,一个二维数组(称为邻接矩阵)存储图中的边或弧的信息。
设图G有n个顶点,则邻接矩阵是一个n×n的方阵,定义为: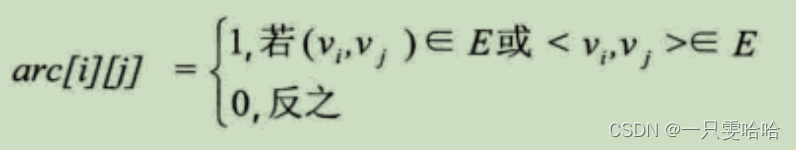
如无向图:无向图的边数组是一个对称矩阵。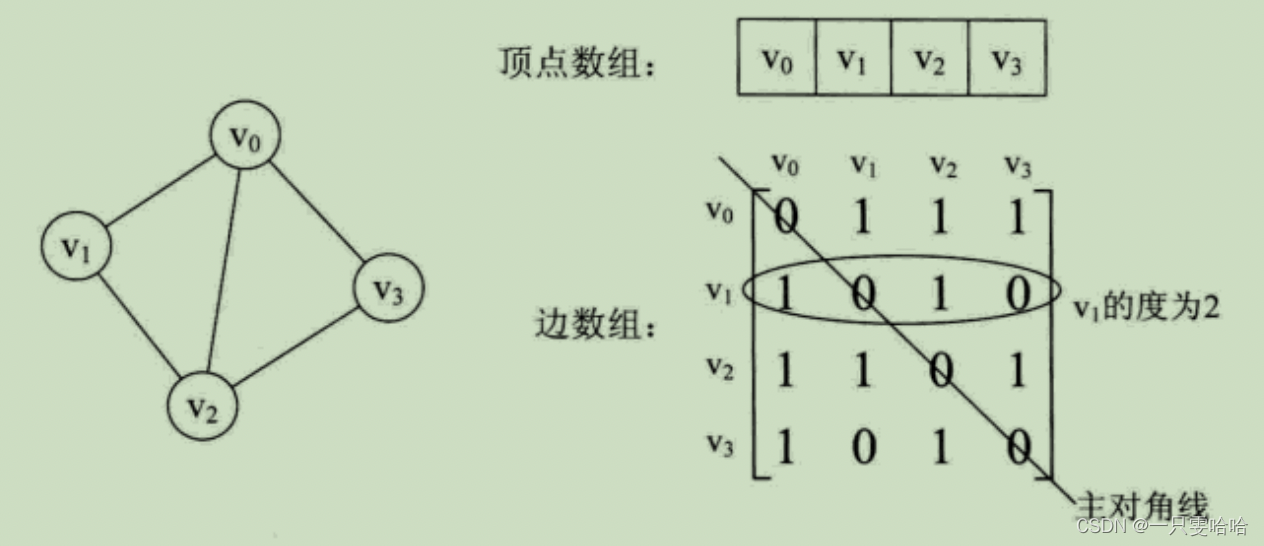
对称矩阵:就是 n 阶矩阵的元满足 aij=aji, (0≤i, j≤n)。即从矩阵的左上角到右下角的主对角线为轴,右上角的元与左下角相对应的元全都是相等的。
有了这个矩阵,我们就可以很容易地知道图中的信息。
1.我们要判定任意两顶点是否有边无边就非常容易了。
2.我们要知道某个顶点的度,其实就是这个顶点vi在邻接矩阵中第i行(或第i列)的元素之和。比如顶点v1的度就是1+0+1+0=2。
3.求顶点vi的所有邻接点就是将矩阵中第i行元素扫描一遍,arc[i][j] 为1就是邻接点。
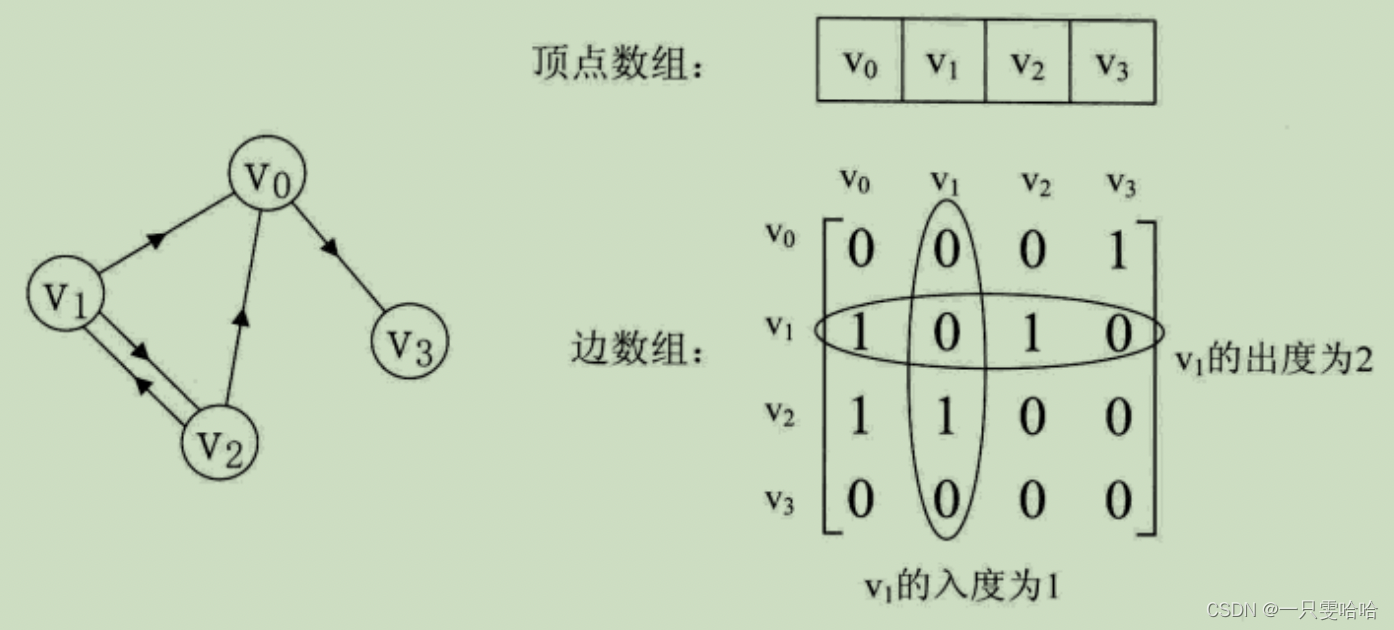
如有向图:邻接矩阵的行为出度,列为入度。
如网图(有向、无向): 每条边或弧上带有权的图叫做网。
设图G是网图,有n个顶点,则邻接矩阵是一个n×n的方阵,定义为: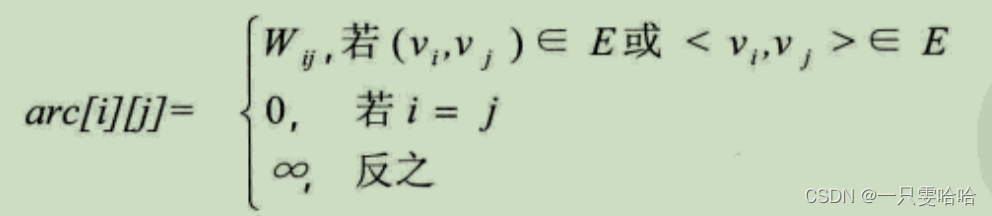
如有向网图:
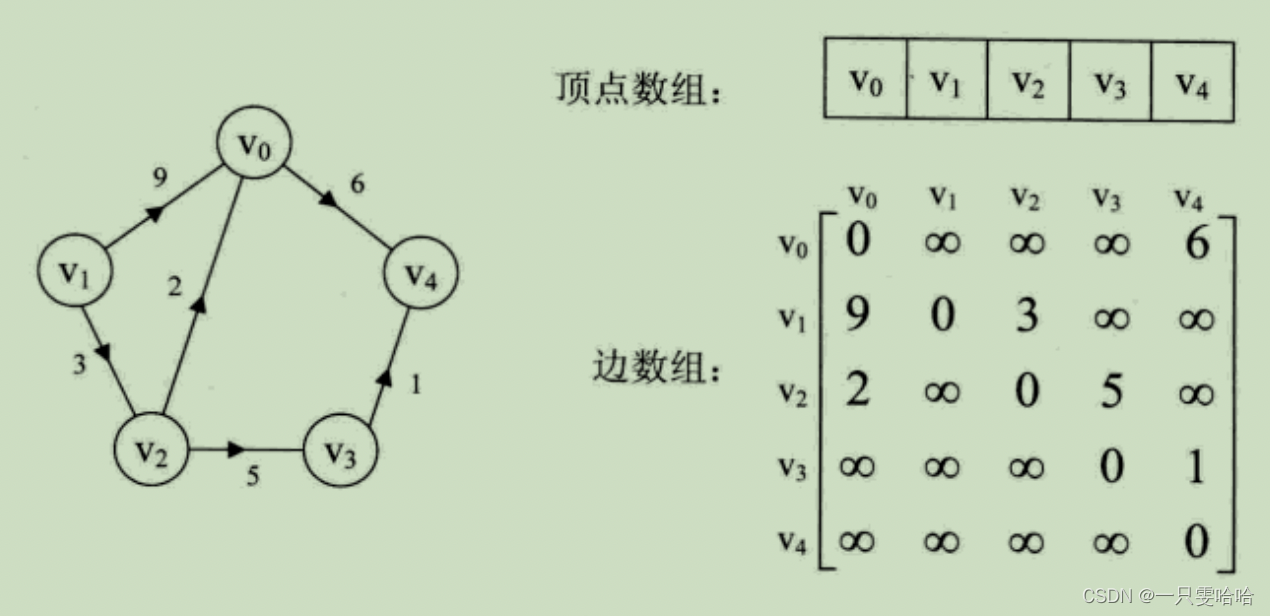
图的邻接矩阵存储结构

无向网图的创建


从代码中可以得到,n 个顶点和 e 条边的无向网图的创建,时间复杂度为O(n+n^2+e),其中对邻接矩阵G.arc的初始化耗费了O(n^2) 的时间。
邻接表
邻接矩阵对于边数相对顶点较少的图,存在对存储空间的极大浪费。
把数组与链表相结合的存储方法称为邻接表(Adjacency List)。
邻接表的处理办法:
1.图中顶点用一个一维数组存储,当然,顶点也可以用单链表来存储,不过数组可以较容易地读取顶点信息,更加方便。另外,对于顶点数组中,每个数据元素还需要存储指向第一个邻接点的指针,以便于查找该顶点的边信息。
2. 图中每个顶点vi的所有邻接点构成一个线性表,由于邻接点的个数不定,所以用单链表存储,无向图称为顶点 vi 的边表,有向图则称为顶点 vi 作为弧尾的出边表。
如无向图的邻接表结构: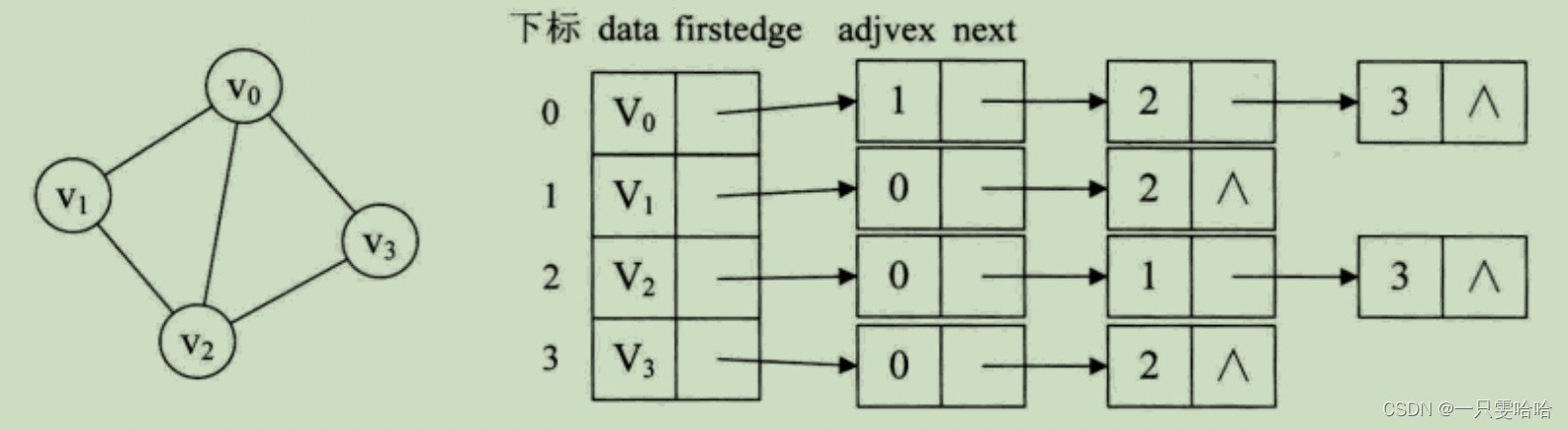
这样的结构,对于我们要获得图的相关信息也是很方便的。比如我们要想知道某个顶点的度,就去查找这个顶点的边表中结点的个数。若要判断顶点 vi 到 vj 是否存在边,只需要测试顶点 vi 的边表中adjvex是否存在结点 vj 的下标 j 就行了。若求顶点的所有邻接点,其实就是对此顶点的边表进行遍历,得到的adjvex域对应的顶点就是邻接点。
如有向图的邻接表结构: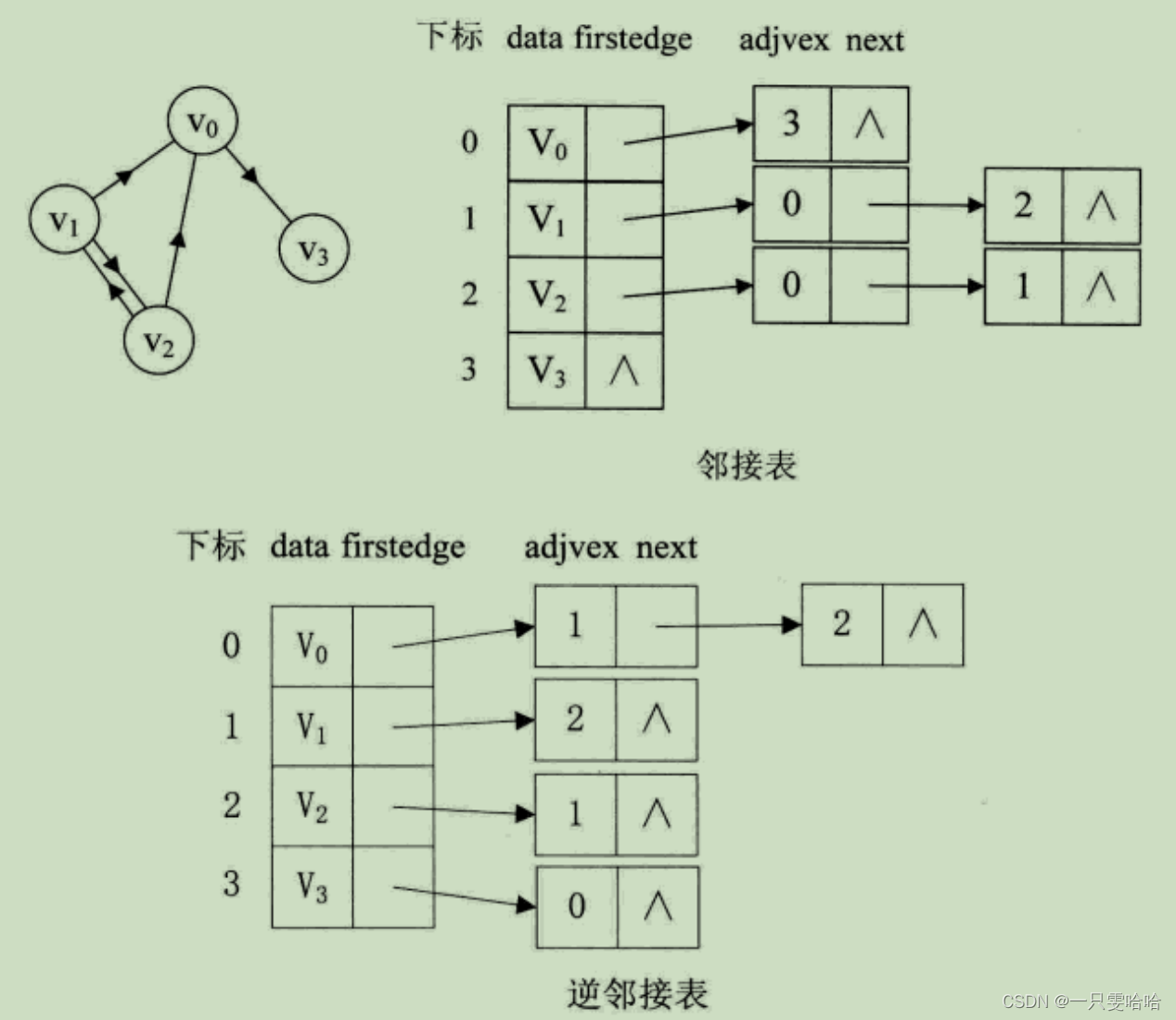
有向图由于有方向,我们是以顶点为弧尾来存储边表的,这样很容易就可以得到每个顶点的出度。但也有时为了便于确定顶点的入度或以顶点为弧头的弧,我们可以建立一个有向图的逆邻接表,即对每个顶点vi都建立一个链接为vi为弧头的表。
此时很容易就可以算出某个顶点的入度或出度是多少,判断两顶点是否存在弧也很容易实现。
如带权值网图的邻接表结构:在边表结点定义中再增加一个 weight 的数据域,存储权值信息。 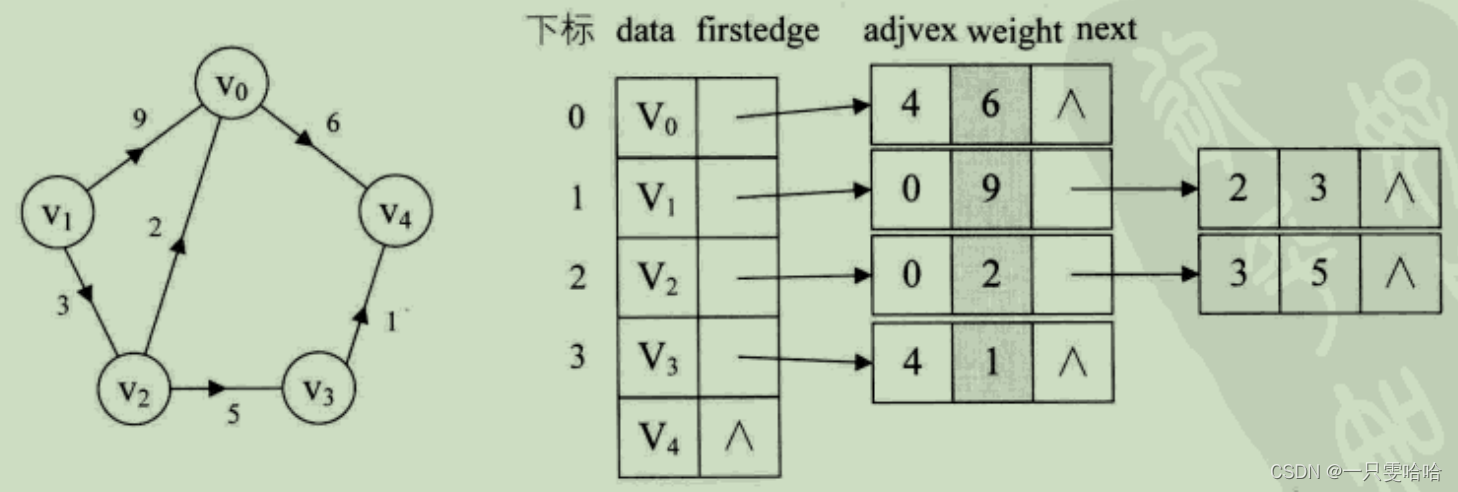
关于节点定义的代码: 
无向图的邻接表创建: 

这里加粗代码应用了我们在单链表创建中讲解到的头插法,由于对于无向图,一条边对应都是两个顶点,所以在循环中,一次就针对 i 和 j 分别进行了插入。本算法的时间复杂度,对于n个顶点e条边来说,很容易得出是 O(n+e)。
十字链表
有向图的一种优化存储方式,把邻接表与逆邻接表结合起来,能同时了解入度和出度情况。
顶点表节点结构:![]()
其中firstin表示入边表头指针,指向该顶点的入边表中第一个结点,firstout表示出边表头指针,指向该顶点的出边表中的第一个结点。
边表节点结构:![]()
其中 tailvex 是指弧起点在顶点表的下标,headvex 是指弧终点在顶点表中的下标,headlink 是指入边表指针域,指向终点相同的下一条边,taillink 是指边表指针域,指向起点相同的下一条边。如果是网,还可以再增加一个weight域来存储权值。
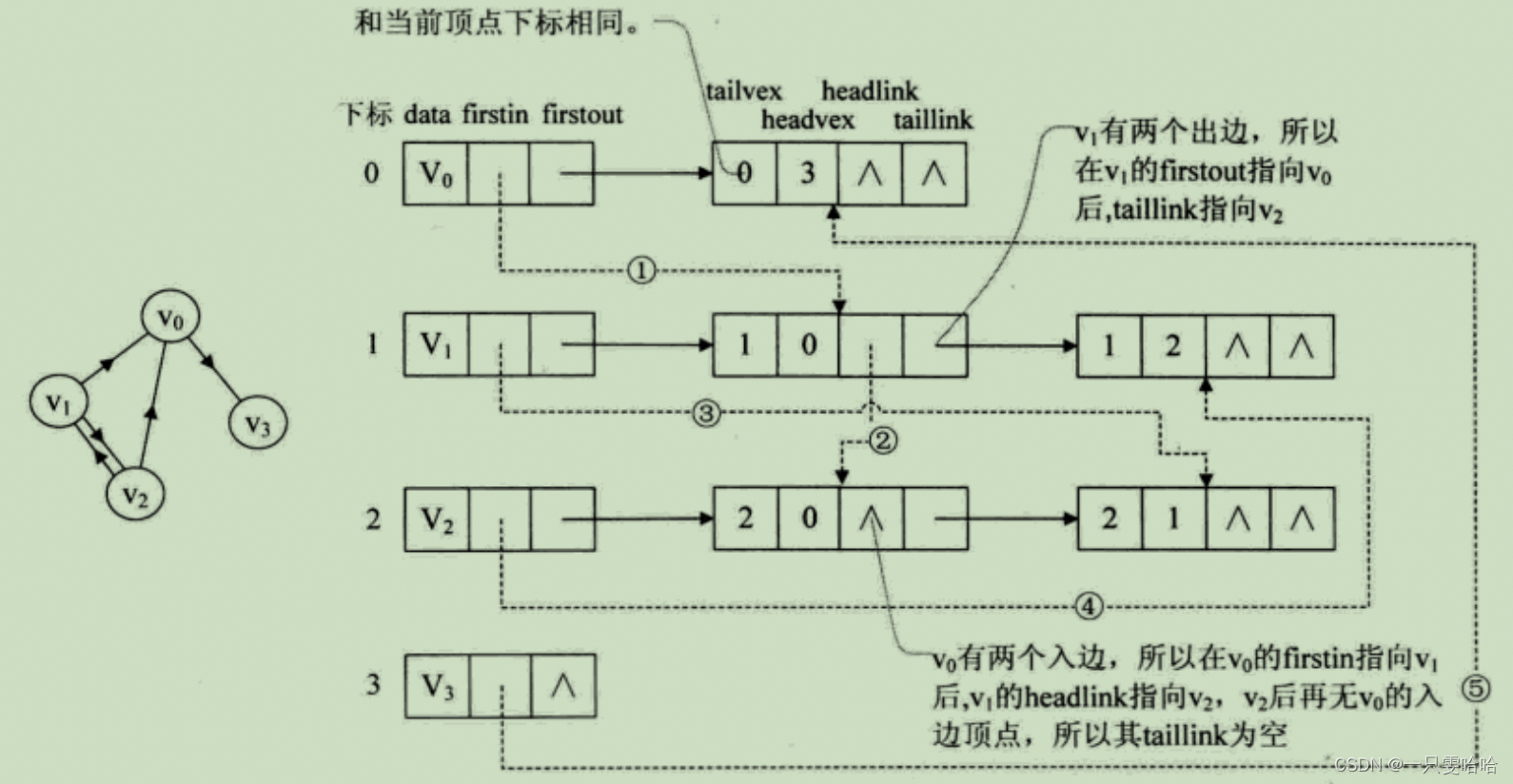
十字链表的好处就是因为把邻接表和逆邻接表整合在了一起,这样既容易找到以vi为尾的弧,也容易找到以vi为头的弧,因而容易求得顶点的出度和入度。而且它除了结构复杂一点外,其实创建图算法的时间复杂度是和邻接表相同的,因此,在有向图的应用中,十字链表是非常好的数据结构模型。
邻接多重表
对于无向图的邻接表,如果我们在无向图的应用中,关注的重点是顶点,那么邻接表是不错的选择,但如果我们更关注边的操作,比如对已访问过的边做标记,删除某一条边等操作,那就意味着,需要找到这条边的两个边表结点进行操作,这其实还是比较麻烦的。
因此,我们也仿照十字链表的方式,对边表结点的结构进行一些改造:
![]()
其中ivex和jvex是与某条边依附的两个顶点在顶点表中下标。ilink 指向依附顶点ivex的下一条边,jlink指向依附顶点jvex的下一条边。这就是邻接多重表结构。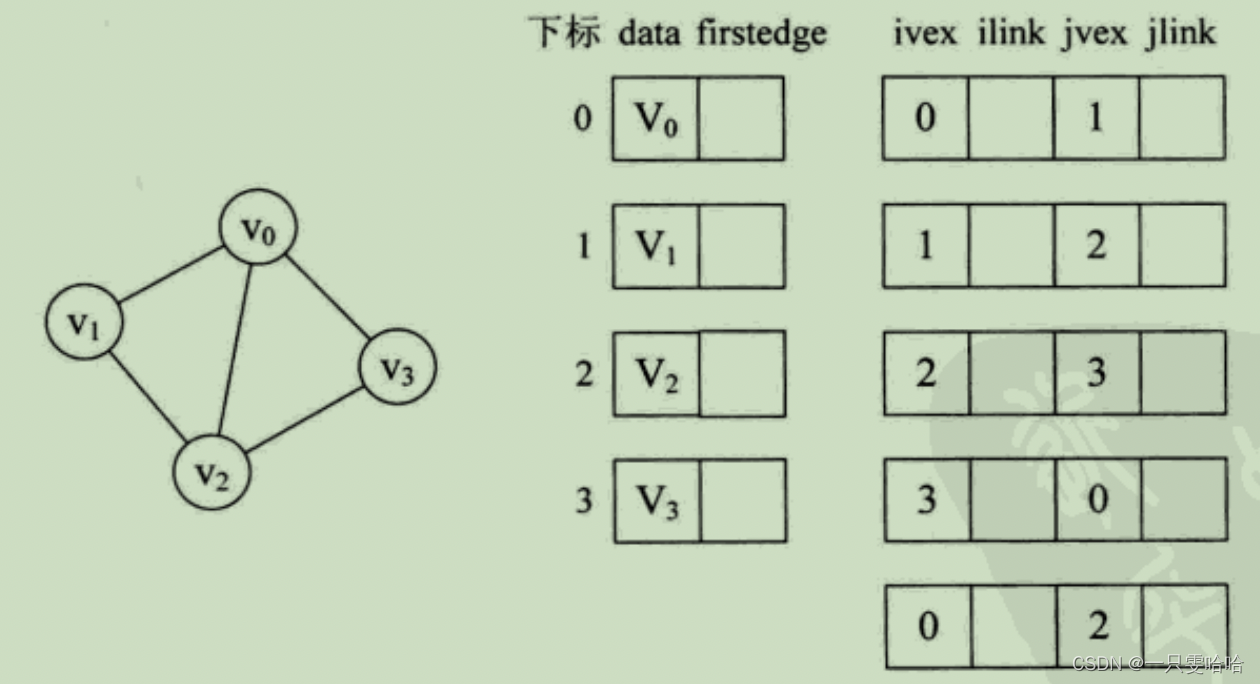
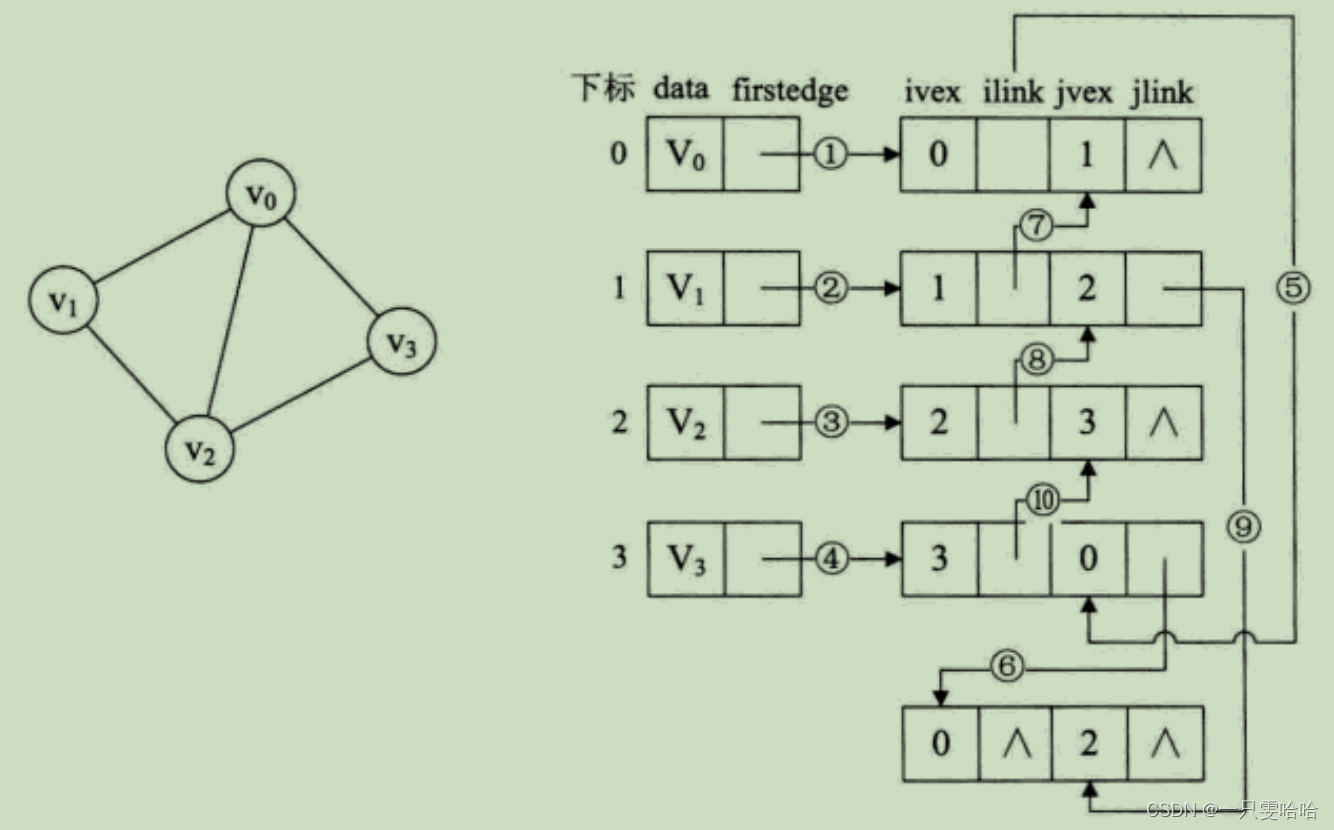
注意 ilink 指向的结点的 jvex 一定要和它本身的 ivex 的值相同, jlink 指向的结点的 jvex 一定要和它本身的 jvex 的值相同。
邻接多重表与邻接表的差别,仅仅是在于同一条边在邻接表中用两个结点表示,而在邻接多重表中只有一个结点。这样对边的操作就方便多了。
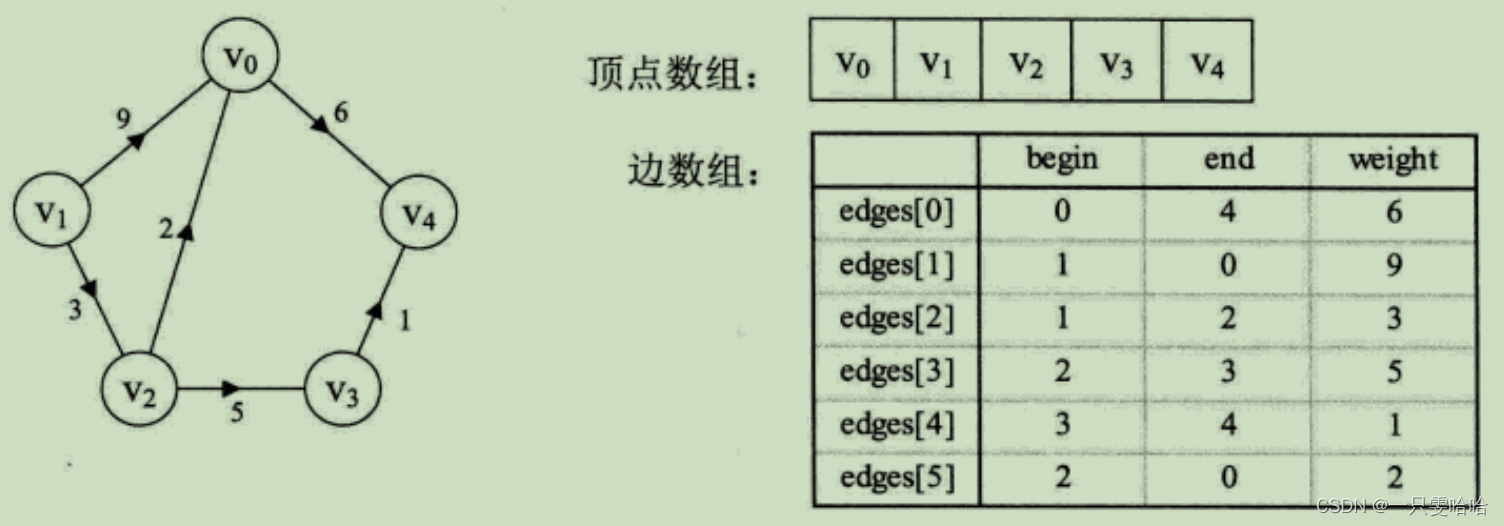
边集数组
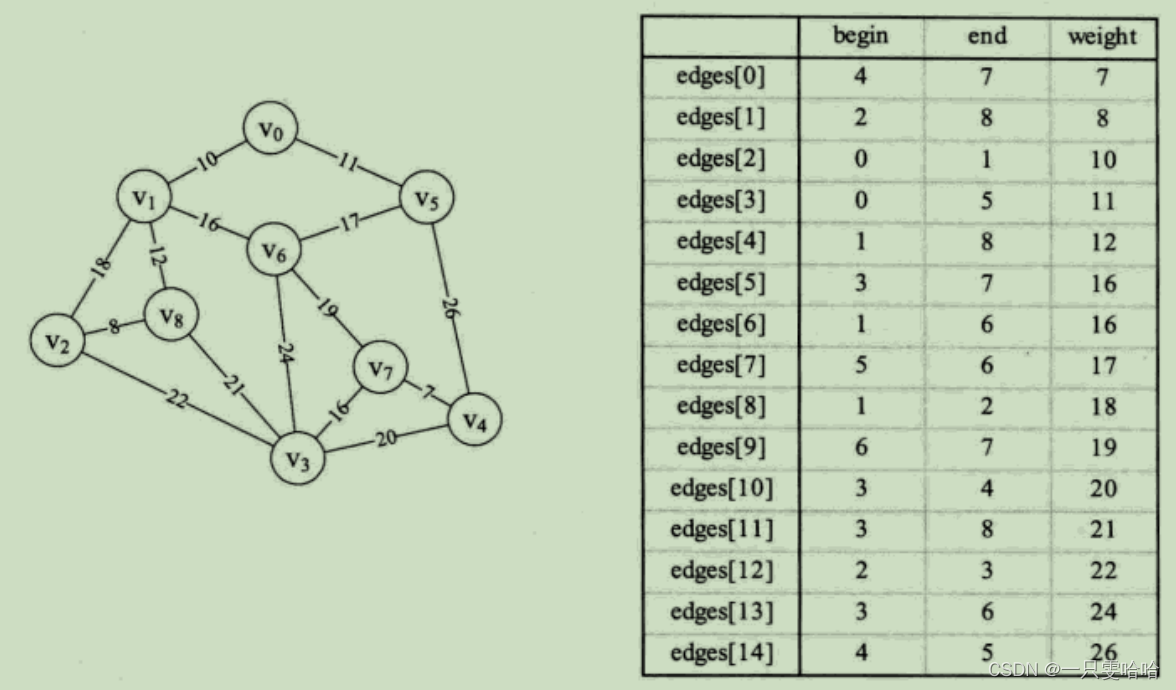
边集数组是由两个一维数组构成。一个是存储顶点的信息;另一个是存储边的信息,这个边数组每个数据元素由一条边的起点下标(begin)、终点下标(end)和权(weight)组成。
显然边集数组关注的是边的集合,在边集数组中要查找一个顶点的度需要扫描整个边数组,效率并不高。因此它更适合对边依次进行处理的操作,而不适合对顶点相关的操作。
定义的边数组结构:其中begin是存储起点下标,end是存储终点下标,weight是存储权值。![]()
4. 图的遍历
图的遍历是和树的遍历类似,我们希望从图中某一顶点出发访遍图中其余顶点,且使每一个顶点仅被访问一次,这一过程就叫做图的遍历(Traversing Graph)。
深度优先遍历
深度优先遍历(Depth_First_Search),也有称为深度优先搜索,简称为 DFS。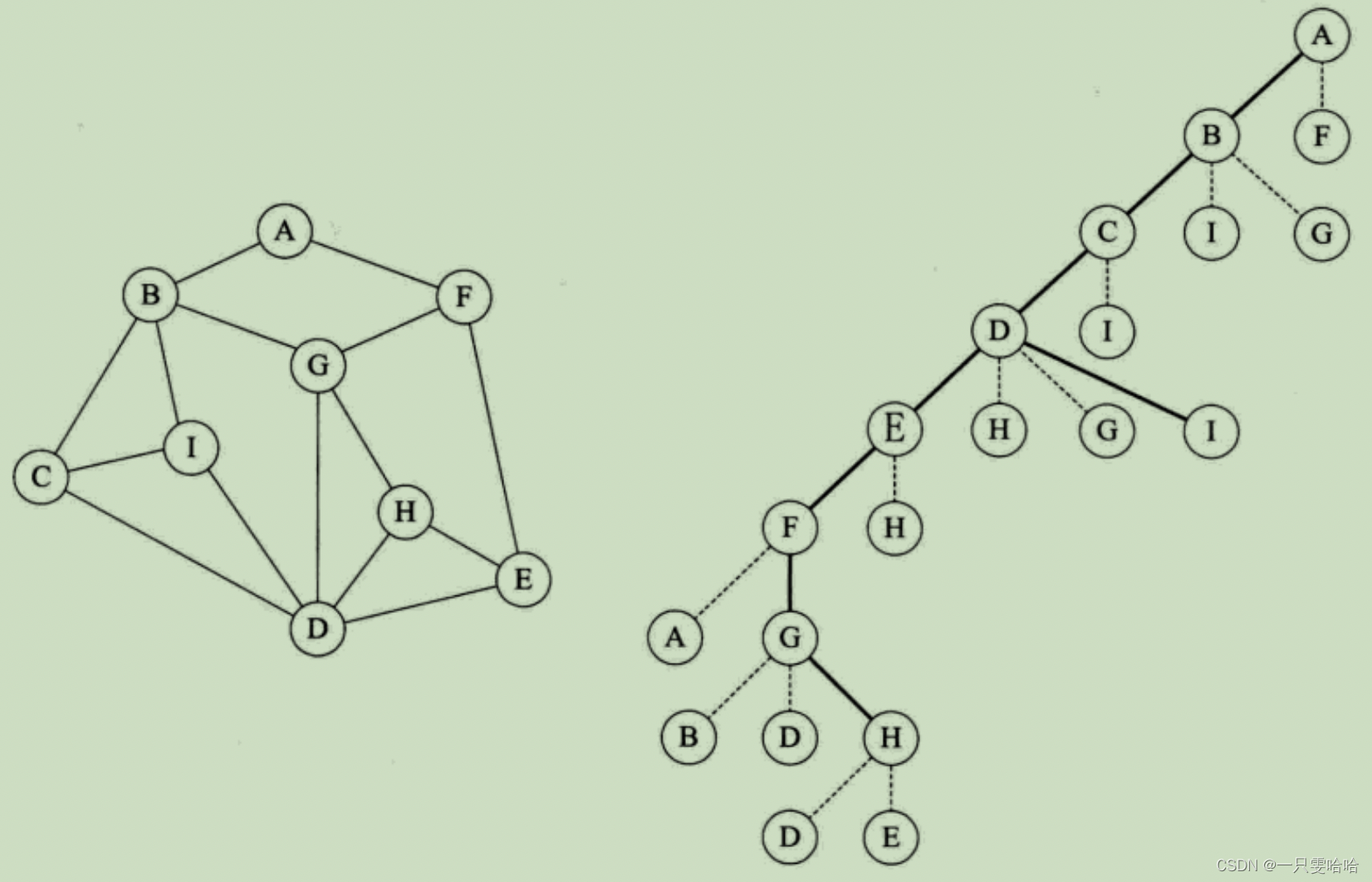
从图中某个顶点v出发,访问此顶点,然后从v的未被访问的邻接点出发深度优先遍历图,直至图中所有和 v 有路径相通的顶点都被访问到。事实上,我们这里讲到的是连通图,对于非连通图,只需要对它的连通分量分别进行深度优先遍历,即在先前一个顶点进行一次深度优先遍历后,若图中尚有顶点未被访问,则另选图中一个未曾被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。
广度优先遍历
广度优先遍历(Breadth_First_Search),又称为广度优先搜索,简称 BFS。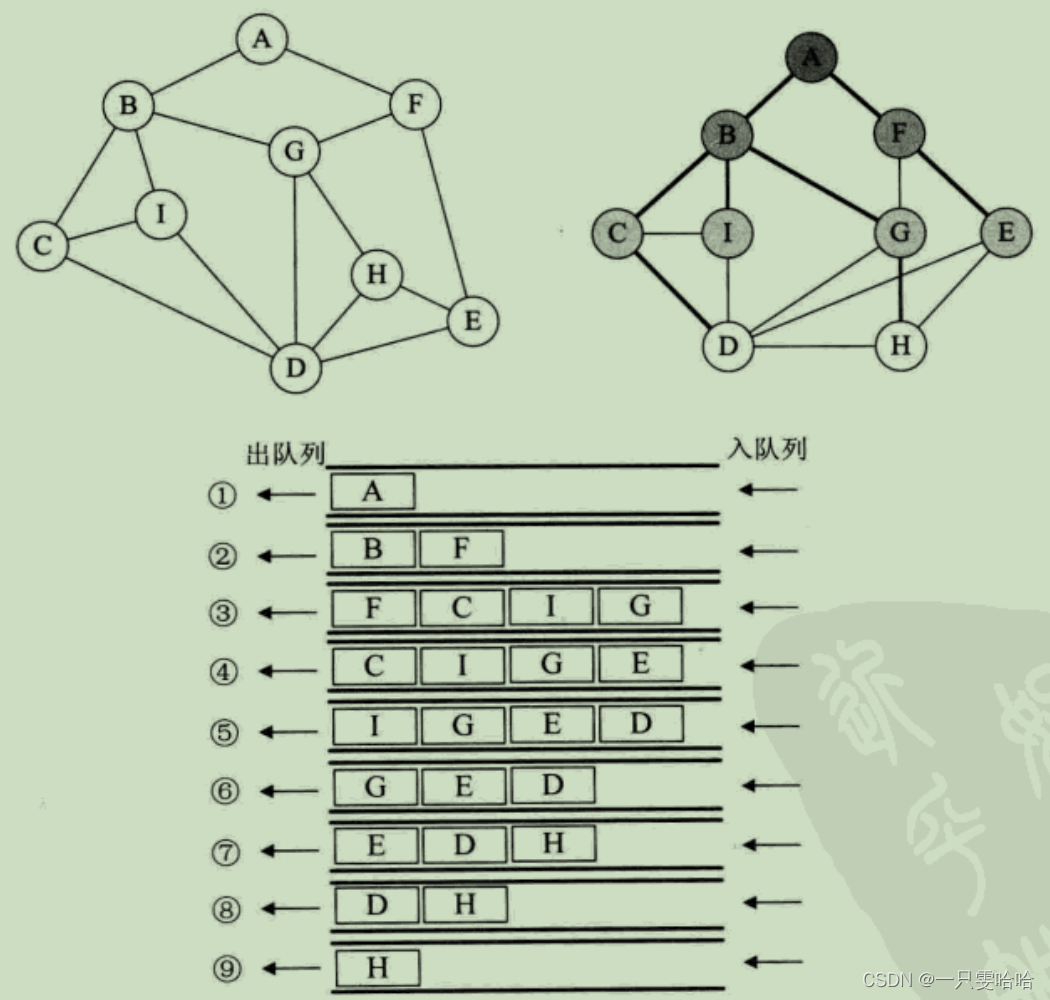
5. 最小生成树
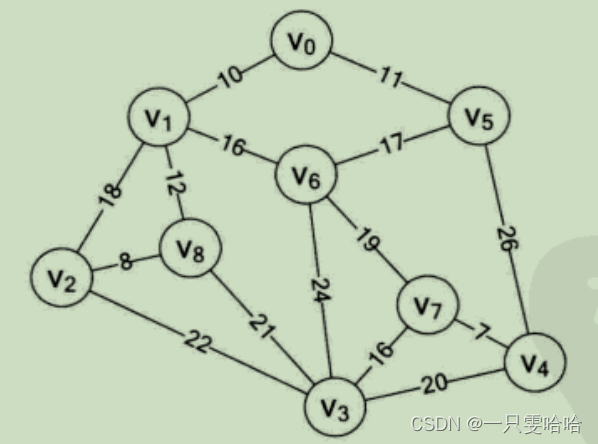
显然这是一个带权值的图,即网结构。所谓的最小成本,就是n个顶点,用n-1 条边把一个连通图连接起来,并且使得权值的和最小。在这个例子里,每多一公里就多一份成本,所以只要让线路连线的公里数最少,就是最少成本了。
一个连通图的生成树是一个极小的连通子图,它含有图中全部的顶点,但只有足以构成一棵树的n-1条边。我们把构造连通网的最小代价生成树称为最小生成树(Minimum Cost Spanning Tree)。 找连通网的最小生成树,经典的有两种算法,普里姆算法和克鲁斯卡尔算法。
普里姆(Prim)算法
克鲁斯卡尔(Kruskal)算法
用到时再学,先搭个知识框架。
6. 最短路径
在网图和非网图中,最短路径的含义是不同的。由于非网图它没有边上的权值,所谓的最短路径,其实就是指两顶点之间经过的边数最少的路径;而对于网图来说,最短路径,是指两顶点之间经过的边上权值之和最少的路径,并且我们称路径上的第一个顶点是源点,最后一个顶点是终点。显然,我们研究网图更有实际意义,就地图来说,距离就是两顶点间的权值之和。而非网图完全可以理解为所有的边的权值都为1的网。
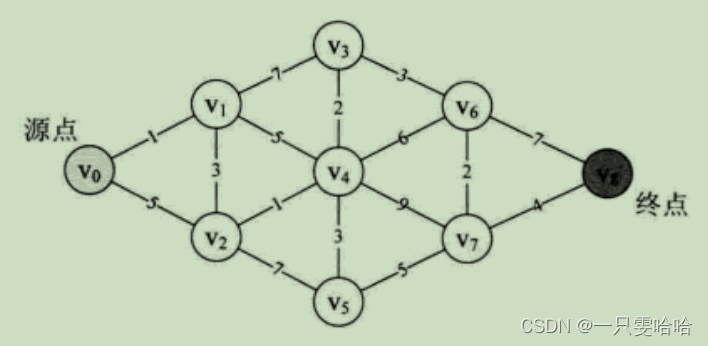
迪杰斯特拉(Dijkstra)算法
这是一个按路径长度递增的次序产生最短路径的算法。
它并不是一下子就求出了两点之间的最短路径,而是一步步求出它们之间顶点的最短路径,过程中都是基于已经求出的最短路径的基础上,求得更远顶点的最短路径,最终得到你要的结果。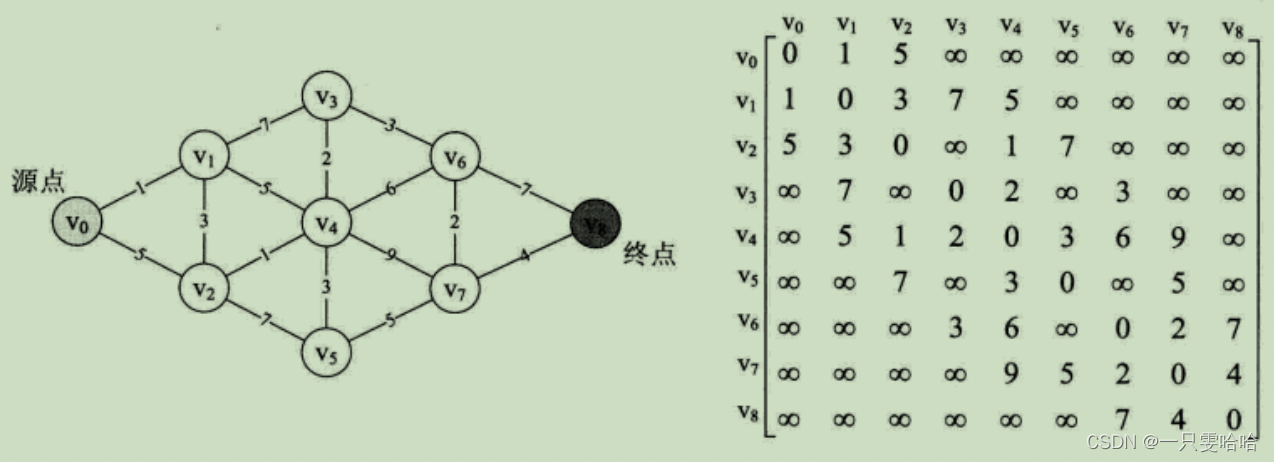
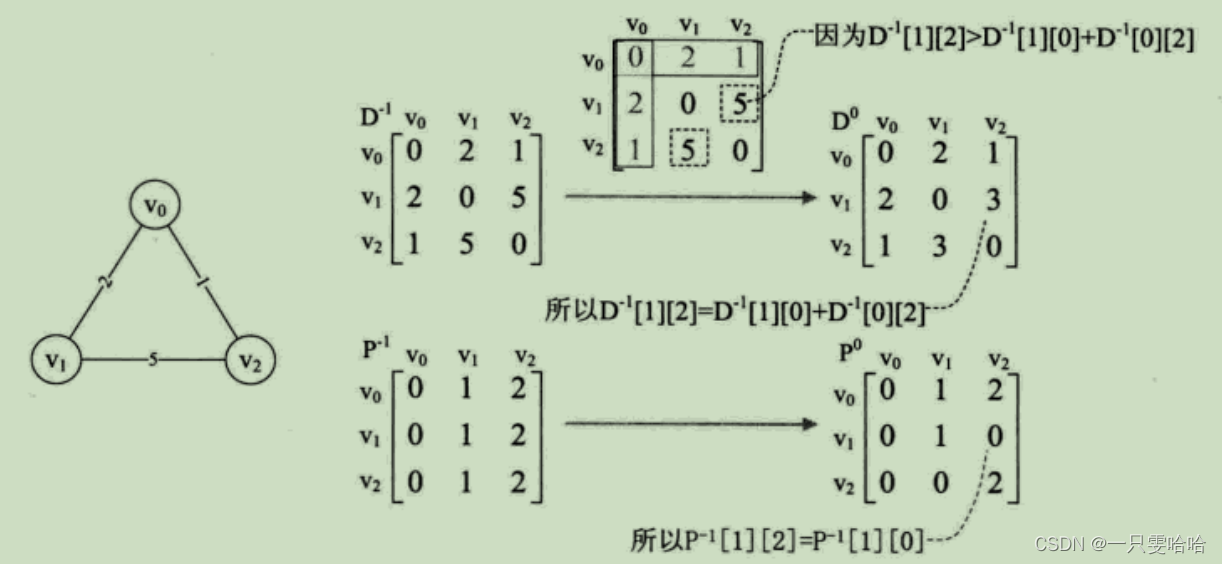
弗洛伊德(Floyd)算法
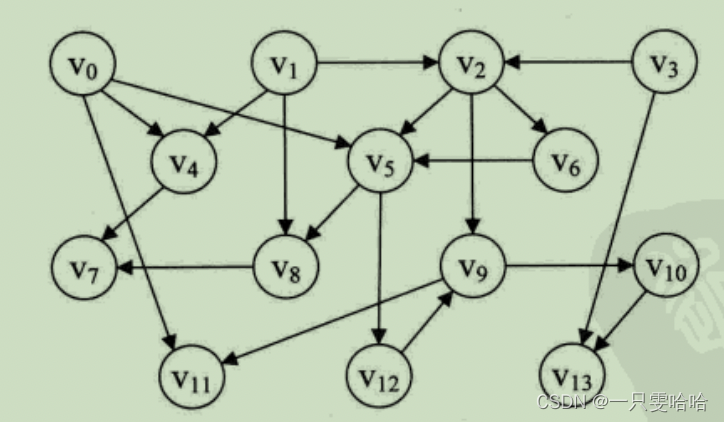
7. 拓扑排序
无环的图应用,无环——即图中没有回路的意思。
拓扑排序介绍
在一个表示工程的有向图中,用顶点表示活动,用弧表示活动之间的优先关系,这样的有向图为顶点表示活动的网,我们称为AOV网(Activity On Vertex Network)。AOV 网中的弧表示活动之间存在的某种制约关系,另外就是AOV网中不能存在回路。
设G=(V,E)是一个具有n个顶点的有向图,V中的顶点序列V1,V2,……,Vn,满足若从顶点vi 到 vj 有一条路径,且在顶点序列中顶点 vi 必在顶点 vj 之前。则我们称这样的顶点序列为一个拓扑序列。
所谓拓扑排序,其实就是对一个有向图构造拓扑序列的过程。构造时会有两个结果,如果此网的全部顶点都被输出,则说明它是不存在环(回路)的AOV网;如果输出顶点数少了,哪怕是少了一个,也说明这个网存在环(回路),不是AOV网。
拓扑排序算法
对AOV 网进行拓扑排序的基本思路是:从AOV 网中选择一个入度为0的顶点输出,然后删去此顶点,并删除以此顶点为尾的弧,继续重复此步骤,直到输出全部顶点或者AOV网中不存在入度为0的顶点为止。
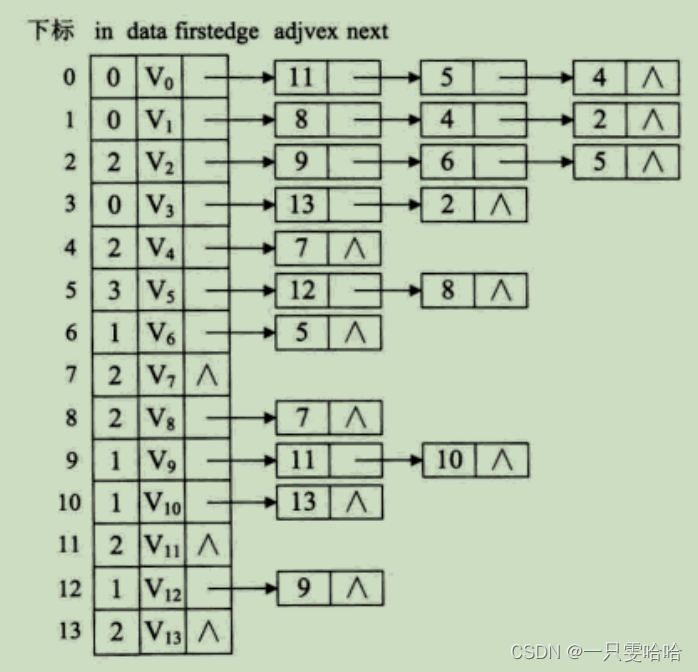
8. 关键路径
在一个表示工程的带权有向图中,用顶点表示事件,用有向边表示活动,用边上的权值表示活动的持续时间,这种有向图的边表示活动的网,我们称之为AOE网(Activity On Edge Network)。我们把AOE网中没有入边的顶点称为始点或源点,没有出边的顶点称为终点或汇点。
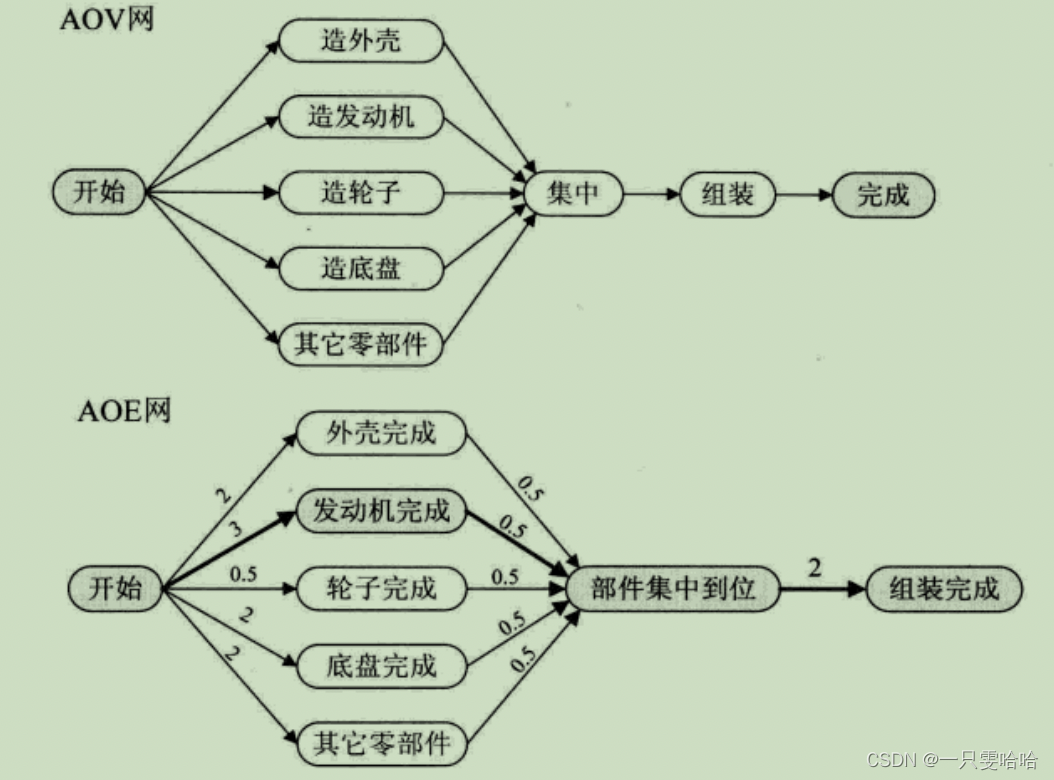
我们把路径上各个活动所持续的时间之和称为路径长度,从源点到汇点具有最大长度的路径叫关键路径,在关键路径上的活动叫关键活动。
关键路径算法原理
我们只需要找到所有活动的最早开始时间和最晚开始时间,并且比较它们,如果相等就意味着此活动是关键活动,活动间的路径为关键路径。如果不等,则就不是。
关键路径算法
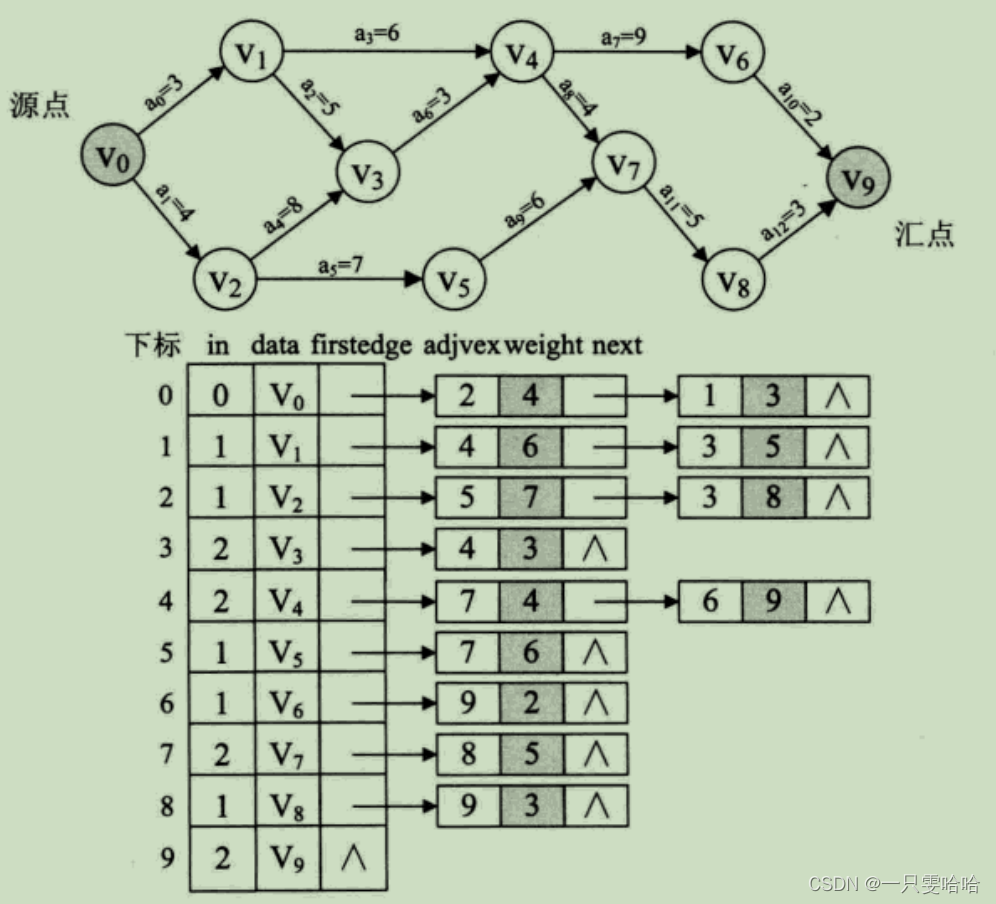
9. 总结
再复杂的问题也是从基本的算法开始入手的。

















 759
759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









