







解决卡在 critical point 的第三种办法 —— 自适应学习率调整(Adaptive Learning Rate)
一、使用场合
当loss函数表面崎岖不平时,可以采用这招。

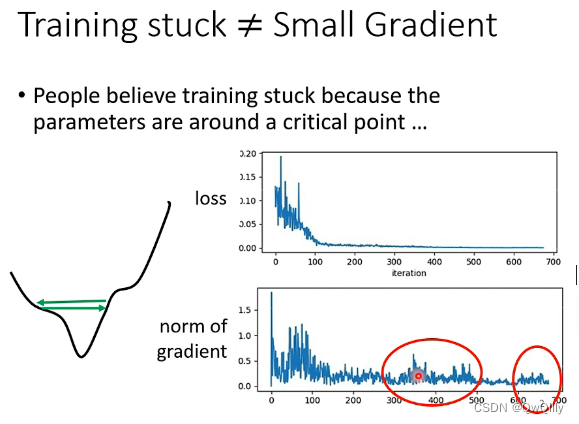
现象1:Training stuck ≠ Small Gradient
训练卡住的原因不一定是因为 gradient 太小,即critical point,也有可能是因为振荡。
如何看出是因为振荡导致训练 loss 降不下去:在训练过程中,gradient的大小有较大的波动(红色框中)。而产生振荡的原因就是 learning rate设定太大 。
被困住时不一定是小梯度,还有可能在峡谷两端来回跳跃,下不去了
现象2:采用固定的学习率yita 将会很难达到最优解
及时不面对critical point问题,当采用固定的学习率yita 时,也将很难训练到最优解。
1)采用较大的学习率 时:会在最优解附近来回横跳。
2)采用较小的学习率 时:会在开始时向最优解较为稳定的移动,但是在靠近最优解后,会移动的十分缓慢。
当误差表面是凸函数(可以想成长轴很大的椭圆)时,可能在峡谷两端交替,再次减小学习率时,可能update很多次但走的贼慢,很难到达目标。
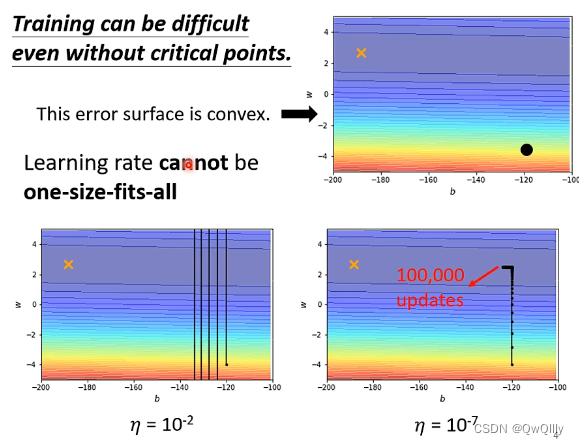
如上图举例:有个 error surface 是凸面,横轴参数的 loss 变化很小,而纵轴参数的 loss 变化快,坡度陡峭。黑点是初始点,叉叉是 loss 最低点。
假如设置个较大的 learning rate,纵轴参数更新时变化幅度大,会振荡;
假如设置个较小的 learning rate,纵轴参数能较好更新,而横轴参数却更新很慢,因为横轴坡度本来就平缓,再设个小的 lr 更新速度会更慢
总结:没有哪个 learning rate能一劳永逸,适应所有参数更新速度
二、解决方法
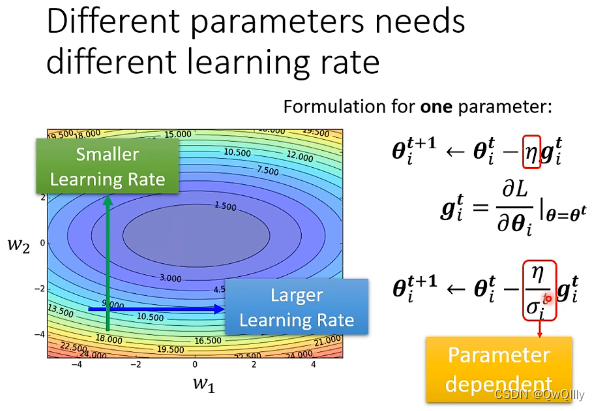
1、客制化“梯度” ⇒ 不同的参数(大小)需要不同的学习率
不同的状态需要不同的学习率,所以引入yita

![]()
基本原则:
- 某一个方向上gradient的值很小,非常的平坦 ⇒ learning rate调大一点
- 某一个方向上非常的陡峭,坡度很大 ⇒ learning rate可以设得小一点
2、 求取Σ的方式
① Root Mean Square
整体思路:将历史梯度绝对值的大小进行考虑(可以理解为过往梯度的平均值),使得随着网络的训练,learning rate的值越来越小,从而保证梯度在不断的训练过程中越来越小,达到最终收敛的目的,防止在最优解附近来回横跳。
与前面的所有梯度有关(注意只与梯度大小有关)
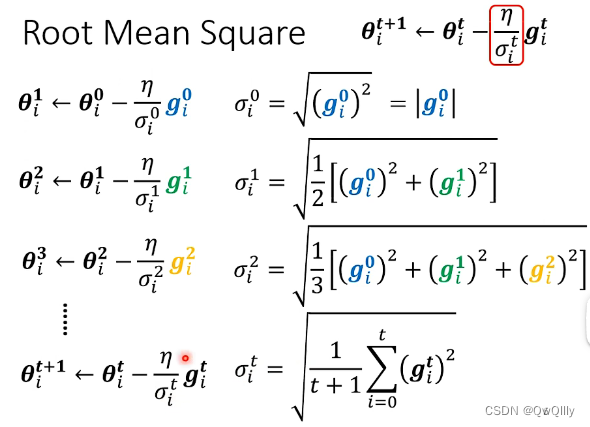
小梯度时大步走,大梯度时小步走

将 Root Mean Square 的思路方式使用在 Adagrad 中。
gradient 比较大(Loss 趋于陡峭),σ 就比较大 , 在 update 的时候 参数 update 的步长就比较小;gradient 比较小(Loss 趋于平缓),σ 就比较大 , 在 update 的时候 参数 update 的步长就比较大。
缺点:不能 “实时” 考虑梯度的变化情况
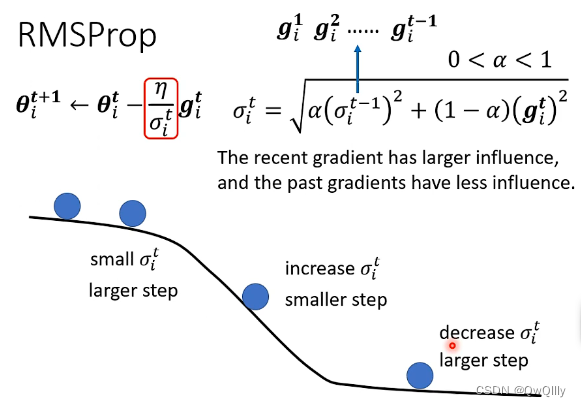
② RMS Prop—— 调整 “当前步” 梯度 与 “历史” 梯度的比重关系
再引入α,控制比例(被以前梯度影响的多少)
整体思路:Root Mean Square方式中,learning rate随着训练不断降低,可以达到梯度随着训练逐步降低,最终达到收敛的效果。然而当一个参数在训练过程中,其梯度的大小往往会出现实大实小的情况,这个时候需要在梯度较小时采用较大的 learning rate,在梯度较大时采用较小的learning rate,从而保证正确而快速的收敛。
方法:添加参数α(表示当前梯度大小对于 learning rate 的影响比重,是一个超参数(hyperparameter)
- α 设很小趋近於0,就代表这一步算出的 gᵢ 相较于之前所算出来的 gradient 而言比较重要
- α 设很大趋近於1,就代表现在算出来的 gᵢ 比较不重要,之前算出来的 gradient 比较重要
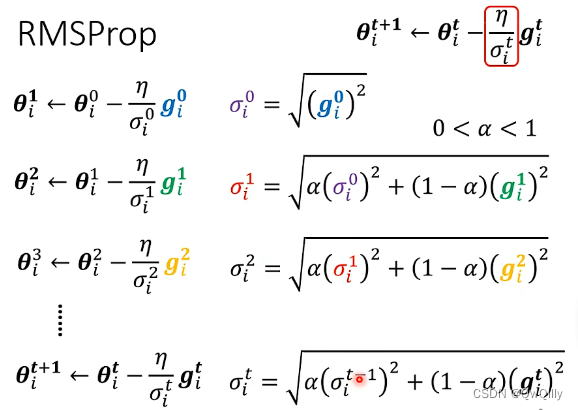
③ 最常用的策略:Adam = RMSProp + Momentum
经常用的Adam优化器,就是采用了RMSProp和动量的结合
动量是与梯度方向有关的,但RMSProp只与其大小有关,所以不会抵消掉!!

3、求取yita 的方式
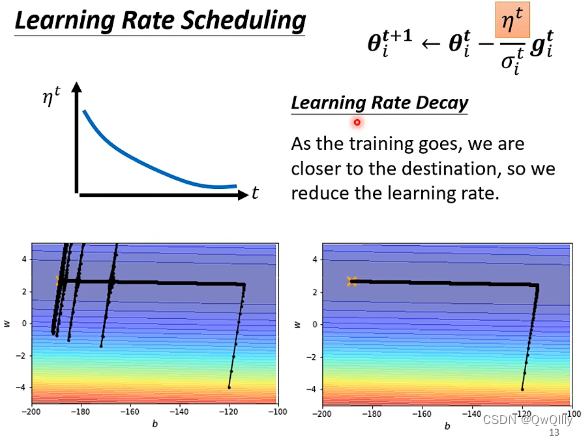
此时,该例子变成了这样,琢磨之后就知道很合理了,最后可以到目标。
为什么有向上下的一跃?Y轴方向累积了很多小的Σ,累积到一定地步后,下一step变得很大就喷出去了,走到大梯度的地方又迈着小步子回来了(左右山谷有摩擦力震荡着下来了)

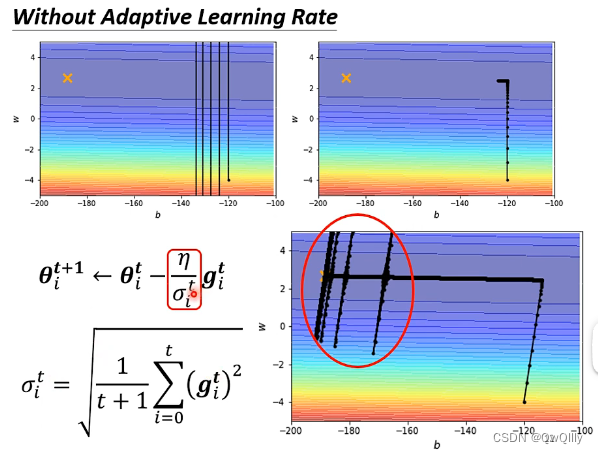
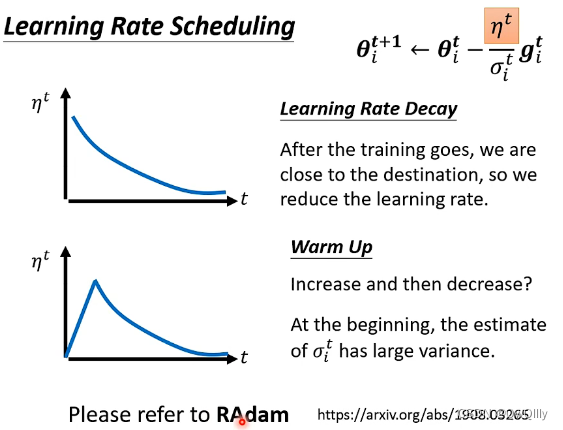
解决方法:Learning Rate Scheduling ⇒ 让 LearningRate 与 “训练时间” 有关
Learning Rate Decay
加入decay,随着时间的增大,学习率在变小

Warm Up
(预热)
为什么要先变大呢?刚开始Σ的统计量有很大误差(小学习率探索,先收集统计数据),只有足够多的统计后才会变准确。

实例论文支撑的warm up

三、总结

















 1432
1432











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









