







模型输入无标签文本(Text without annotation),通过消耗大量计算资源预训练(Pre-train)得到一个可以读懂文本的模型,在遇到有监督的任务是微调(Fine-tune)即可。
最具代表性是BERT,预训练模型现在命名基本上是源自于动画片《芝麻街》。

芝麻街人物
经典的预训练模型:
- ELMo:Embeddings from Language Models
- BERT:Bidirectional Encoder Representations from Transformers
- 华丽分割线,命名逐渐开始离谱
- ERNIE:Enhanced Representation through Knowledge Integration
- Grover:Generating aRticles by Only Viewing mEtadaya Records

一、pre-train model 是什么
(一)预训练概念
预训练模型的概念并不是由BERT时才出现。
预训练的任务一般是实现 词语token -> 词向量embedding vector, vector中包含token的语义,比如我们语文中常学习的近义词,语义相近,那么要求其词向量也应该近似。
(二)多语义多语境
存在的问题:同一个token就可以指代同一个vector。解决方法Word2vec、Glove...

但是语言有无穷尽的词语,咱们现在就一直在创造新词语,如 “雪糕刺客”、“栓Q”等等新兴词汇不断迭代更新,一个新的词汇就要增加一个向量,显然是不太OK的。
那么,研究者就想到可以将词语再分,英文可以拆分为字符(FastText),中文可以拆分为单个字,或者将一个中文字看作一张图片输入CNN等模型,可以让模型学习到字的构成。

但分解为单个character后面临的就是语义多意的问题,“养只狗”、“单身狗”其中的“狗”都是狗,但是我们知道,两个“狗”其实是不同的,然鹅他们又不能完全分开,毕竟都用了一个字,其实咱们是将考虑到其语义的。

考虑上下文后,就诞生了语境词向量(Contextualized Word Embedding),输入模型的是整个句子,模型会阅读上下文,而不是仅仅考虑单个token,考虑语境后得到一个词向量表示。【Encoder行为】
语境词向量的模型一般模型会由多层组成,层结构常使用LSTM、Self-attention layers或者一些Tree-based model(与文法相关)。但Tree-base Model经过检验效果不突出,在文法结构严谨(解决数学公式)时,效果突出。

李老师列举了“苹果”在10个句子中的向量表示,两两计算相似度,得到一个10*10的混淆矩阵。可以明显观察到,水果苹果和苹果公司两个苹果语义有所区别。

预训练模型训练参数逐渐增加,网络结构逐渐复杂,各个公司都争相发布“全球最大预训练模型”。

(三)穷人的BERT
预训练模型参数量大,在训练时会消耗大量计算资源,都是一些互联网公司在做,像我们这些“穷人”,没有那么大的GPU算力,就会搞一些丐版BERT。

举例:
- Distill BERT
- Tiny BERT
- Mobile BERT
- ALBERT(相比于原版BERT, 12层不同参数,ALBERT12层参数完全一致,效果甚至超过原版BERT一点点)
模型压缩技术:网络剪枝(Network Pruning)、知识蒸馏(Knowledge Distillation)、参数量化(Parameter Quantization)、架构设计(Architecture Design)

(四)架构设计(Architecture Design)
在该领域架构设计的目标,意在处理长文本语句。
典型代表,读者可以自行检索学习
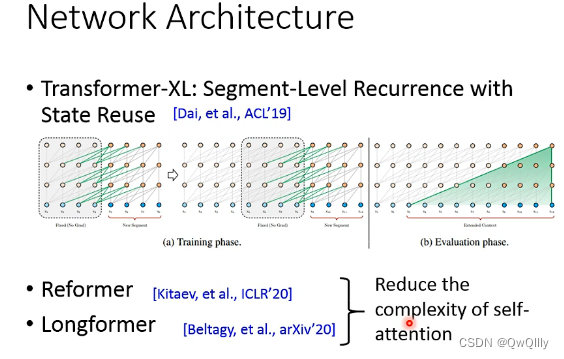
- Transformer-XL: Segment-Level Recurrence with State Reuse
- Reformer
[2001.04451] Reformer: The Efficient Transformer (arxiv.org)arxiv.org/abs/2001.04451
- Longformer
[2004.05150] Longformer: The Long-Document Transformer (arxiv.org)arxiv.org/abs/2004.05150
Reformer和Longformer意在降低Self-attention的复杂度。
二、怎么做 Fine-tune
预训练+微调范式是现在的主流形式,我们可以拿到大公司训练好的大模型,只需要根据自己的下游任务加一些Layer,就可以应用某一个具体的下游任务上。
预训练微调效果的实现,需要预训练模型针对该问题进行针对性设计。

(一)Input & Output
这里总结了NLP Tasks的常见输入输出。

- Input:
- one sentence: 直接丢进去。
- multiple sentences: Sentence1 SEP Sentence2, 句子分割。
- Ouput:
- one class: 加一个 CLS,或者直接将所有Embedding表示接下游任务分类
- class for each token
- copy from input: 可以解决阅读理解问题,QA。
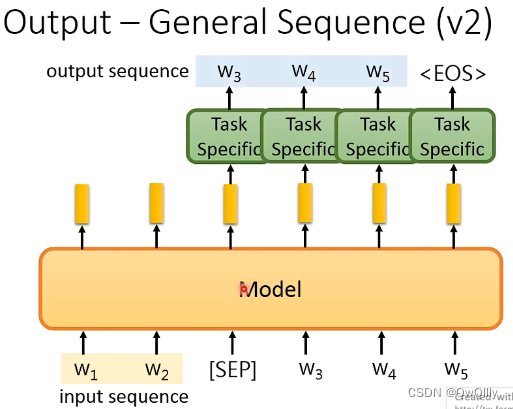
- General Sequence: 用到Seq2Seq Model
- v1:将预训练模型看作Encoder,将下游任务模型看作Decoder。
- v2:给出一个特别符号 SEP,得到字符再输入到预训练模型,让预训练模型encoder-decoder。







(二)How to fine-tune
如何微调也有两种,一种是冻结预训练模型,只微调下游任务对应的Task-specific部分;另一种是连同预训练模型,将整体网络结构进行参数微调(预训练模型参数不是随机初始化,可以有效避免过拟合)。

Adaptor
考虑到模型巨大,微调代价太大,且消耗存储大。引入Apt,只微调Pre-train Model中的一部分Apt。这样只需要存储Apt和Task specific. 此处举一个例子。



现在很多预训练模型中都是使用了Transformer的结构,研究者在Transformer结构中插入Adaptor层,通过训练微调Adaptor,而不去修改其他已经训练好的参数。



三、Why Pre-train Models?
研究者提出了GLUE指标,用来衡量机器与人在不同语言任务上的表现,随着深度学习的发展,预训练模型的迭代更新,现在预训练模型使得模型效果已经同人类水平相差无几。

四、Why Fine-tune?
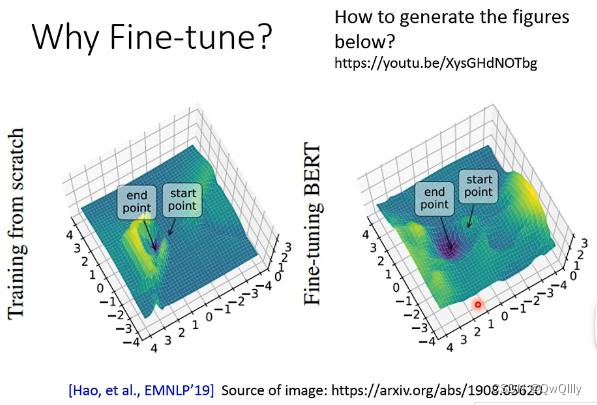
EMNLP19年刊发的一篇文章做了分析,在网络模型上fine-tune与否,Training Loss变化是不同的。
在有Fine-tune的情况下,Training Loss可以很好的实现收敛,而从头训练则会出现较大的波动。

同时考虑泛化能力,因为基于预训练模型将Training Loss降低到很低,有没有可能是过拟合导致的。海拔图可以表示,如果海拔图中,变化越陡峭,模型泛化能力越差,变化越平稳,模型泛化能力越强。















 1399
1399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









