







一、classification 与 regression 的区别
通过以往学习已经知道:
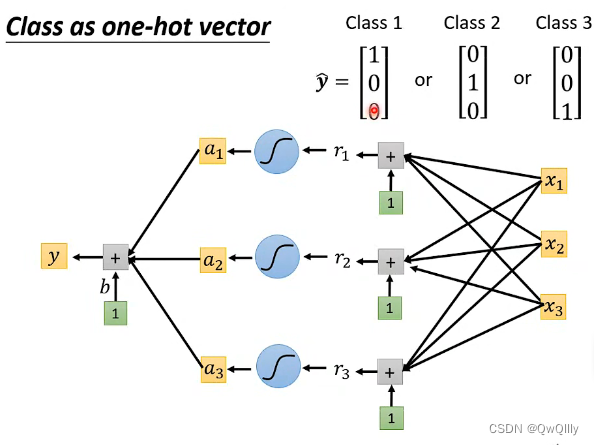
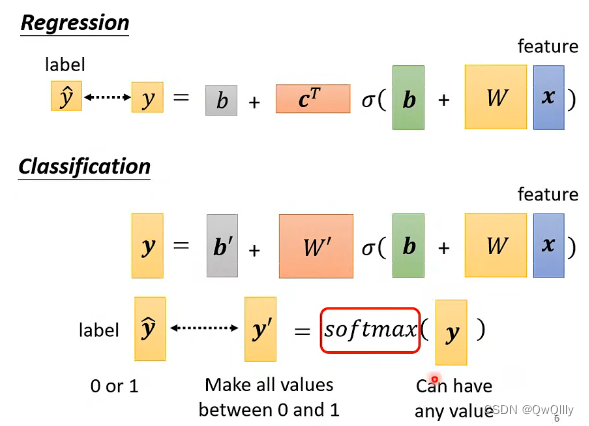
1. 在输出数量方面, R 只输出一个预测 y 值,而C 通过 one-hot vector(独热编码)表示不同的类别(一个向量中只有1 个 1 ,其余都为 0,1 在不同的位置代表不同类别);
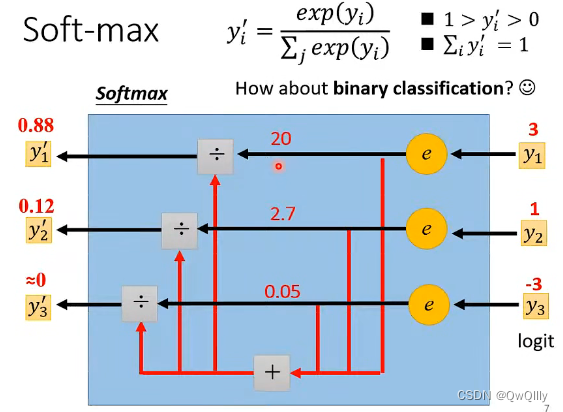
2. 在计算 Loss 时,R 直接拿预测输出数值 y 和 真实数值 计算接近度,而 C 将多个输出数值组成一个向量,向量经过 softmax(归一化,保证输出 y′ 在 0 与 1 之间,并且总和为1,可以理解为 预测输出是 yi 所代表类别的的概率值) 后形成新的向量,再拿新的向量去和不同类别计算接近度。
3. 计算loss的方法不同(新学习的)
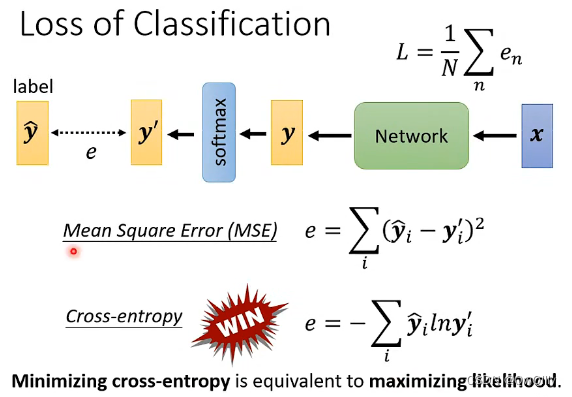
① 介绍: regression 采用 MSE 和 MAE 的方法计算 loss 函数;而 classification 采用 cross entropy(交叉熵)的方法计算 loss 函数,当 ŷ 跟 y' 一模一样的时候,为最小交叉熵(等价于 maximizing likelihood 最大似然估计)
② 交叉熵适用于 classification 的原因:交叉熵改变了 loss 函数,也就改变了 error surface,使得在大 loss 的地方也会有大的 gradient,而不像 MSE 在大 loss 处的 gradient 很小,不易梯度下降。所以交叉熵计算出来的loss函数更容易做梯度下降,不容易卡在 critical point
P.S. 在 pytorch 中,softmax 是嵌在 cross entropy 里面的,所以用了 cross entropy 就不用加 softmax 了,否则就有两层 softmax
二、softmax与sigmoid
此处要明白!softmax和sigmoid的区别和联系
Softmax函数和Sigmoid函数的区别与联系 - 知乎 (zhihu.com)
Sigmoid =多标签分类问题=多个正确答案=非独占输出(例如胸部X光检查、住院)。构建分类器,解决有多个正确答案的问题时,用Sigmoid函数分别处理各个原始输出值。
Softmax =多类别分类问题=只有一个正确答案=互斥输出(例如手写数字,鸢尾花)。构建分类器,解决只有唯一正确答案的问题时,用Softmax函数处理各个原始输出值。Softmax函数的分母综合了原始输出值的所有因素,这意味着,Softmax函数得到的不同概率之间相互关联。
Softmax函数是二分类函数Sigmoid在多分类上的推广,目的是将多分类的结果以概率的形式展现出来。
对于二分类问题来说,理论上,两者是没有任何区别的。由于我们现在用的Pytorch、TensorFlow等框架计算矩阵方式的问题,导致两者在反向传播的过程中还是有区别的。实验结果表明,两者还是存在差异的,对于不同的分类模型,可能Sigmoid函数效果好,也可能是Softmax函数效果。
三、损失函数
最小化交叉熵就是最大化对数似然函数
最小化交叉熵损失与极大似然 - 知乎 (zhihu.com)
下面给出极大似然估计与最小化交叉熵损失的转化过程,意在说明在伯努利分布下,极大似然估计与最小化交叉熵损失其实是同一回事。
下面同样给出极大似然估计与最小化广义伯努利分布的交叉熵损失函数的转化过程,意在说明在广义伯努利分布下,极大似然估计与最小化交叉熵损失也是同一回事。
实例说明
此时简单举例说明分类问题要用交叉熵:更改loss function后,不会被困住了。
交叉熵形式使优化问题变得简单
MSE左上角的梯度变化非常平缓,接近于0,被困住。

分类问题要用交叉熵!!!!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









