






4.2 train_vgg.py 中各函数模块详解(train_vgg.ipynb)
设置环境变量和导入所需的库
os.environ[‘NLS_LANG’] = ‘SIMPLIFIED CHINESE_CHINA.UTF8’:设置环境变量,指定编码格式为UTF-8。
BASE_DIR = os.path.dirname(os.getcwd()):获取当前工作目录的上级目录。
import语句用于导入所需的库和模块,包括numpy、torch、torchvision等。
import os
os.environ['NLS_LANG'] = 'SIMPLIFIED CHINESE_CHINA.UTF8'
BASE_DIR = os.path.dirname(os.getcwd())
import sys
sys.path.append(BASE_DIR)
import numpy as np
import torch.nn as nn
import torch
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torch.optim as optim
from matplotlib import pyplot as plt
import torchvision.models as models
from tools.my_dataset import CatDogDataset
from tools.common_tools import get_vgg16
from datetime import datetime
BASE_DIR = os.path.dirname(os.getcwd())
print(BASE_DIR)
运行结果:
e:\Deep_learning_work\B_VGG
定义一些变量和路径
device = torch.device(“cuda” if torch.cuda.is_available() else “cpu”):根据是否有可用的CUDA设备,选择使用GPU还是CPU作为计算设备。
now_time = datetime.now():获取当前时间。
time_str = datetime.strftime(now_time, ‘%m-%d_%H-%M’):将当前时间格式化为字符串。
log_dir = os.path.join(BASE_DIR, “…”, “results”, time_str):设置日志目录路径。
data_dir = os.path.join(BASE_DIR, “B_VGG”, “data”, “train”):设置数据集目录路径。
path_state_dict = os.path.join(BASE_DIR, “B_VGG”, “data”, “vgg16-397923af.pth”):设置预训练模型的路径。
其他一些用于训练的超参数和配置。
# config
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
# log dir
now_time = datetime.now()
time_str = datetime.strftime(now_time, '%m-%d_%H-%M')
log_dir = os.path.join(BASE_DIR, "..", "results", time_str)
if not os.path.exists(log_dir):
os.makedirs(log_dir)
num_classes = 2
MAX_EPOCH = 1
BATCH_SIZE = 16
LR = 0.001
log_interval = 1
val_interval = 1
classes = 2
start_epoch = -1
lr_decay_step = 1
运行结果:(有cuda的则输出cuda,没有的则输出cpu)
cuda
数据集
定义了两个数据预处理的transform:
train_transform用于训练集数据的预处理,包括图像的大小调整、裁剪、翻转、转换为张量和归一化。
valid_transform用于验证集数据的预处理,包括图像的大小调整、裁剪、转换为张量和归一化。
使用CatDogDataset类构建训练集和验证集的数据集实例,并使用DataLoader类构建训练集和验证集的数据加载器。
示例图片:

def transform_invert(img_, transform_train):
"""
将data 进行反transfrom操作
:param img_: tensor
:param transform_train: torchvision.transforms
:return: PIL image
"""
if 'Normalize' in str(transform_train):
norm_transform = list(filter(lambda x: isinstance(x, transforms.Normalize), transform_train.transforms))
mean = torch.tensor(norm_transform[0].mean, dtype=img_.dtype, device=img_.device)
std = torch.tensor(norm_transform[0].std, dtype=img_.dtype, device=img_.device)
img_.mul_(std[:, None, None]).add_(mean[:, None, None])
img_ = img_.transpose(0, 2).transpose(0, 1) # C*H*W --> H*W*C
if 'ToTensor' in str(transform_train):
img_ = np.array(img_) * 255
if img_.shape[2] == 3:
img_ = Image.fromarray(img_.astype('uint8')).convert('RGB')
elif img_.shape[2] == 1:
img_ = Image.fromarray(img_.astype('uint8').squeeze())
else:
raise Exception("Invalid img shape, expected 1 or 3 in axis 2, but got {}!".format(img_.shape[2]) )
return img_
class CatDogDataset(Dataset):
def __init__(self, data_dir, mode="train", split_n=0.9, rng_seed=620, transform=None):
"""
猫狗分类任务的Dataset
:param data_dir: str, 数据集所在路径
:param transform: torch.transform,数据预处理
"""
self.mode = mode
self.data_dir = data_dir
self.rng_seed = rng_seed
self.split_n = split_n
self.data_info = self._get_img_info() # data_info存储所有图片路径和标签,在DataLoader中通过index读取样本
self.transform = transform
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB') # 0~255
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label
def __len__(self):
if len(self.data_info) == 0:
raise Exception("\ndata_dir:{} is a empty dir! Please checkout your path to images!".format(self.data_dir))
return len(self.data_info)
def _get_img_info(self):
img_names = os.listdir(self.data_dir)
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names)) # 获取所有图片文件名
random.seed(self.rng_seed) # 保证每次随机的顺序一致,避免训练集与测试集有交叉
random.shuffle(img_names)
img_labels = [0 if n.startswith('cat') else 1 for n in img_names] # 根据文件名获取标签
split_idx = int(len(img_labels) * self.split_n) # 25000* 0.9 = 22500 # 选择划分点
# split_idx = int(100 * self.split_n)
if self.mode == "train":
img_set = img_names[:split_idx] # 数据集90%训练
label_set = img_labels[:split_idx]
elif self.mode == "valid":
img_set = img_names[split_idx:]
label_set = img_labels[split_idx:]
else:
raise Exception("self.mode 无法识别,仅支持(train, valid)")
path_img_set = [os.path.join(self.data_dir, n) for n in img_set] # 拼接路径
data_info = [(n, l) for n, l in zip(path_img_set, label_set)] # 制作样本对
return data_info
norm_mean = [0.485, 0.456, 0.406] # imagenet 训练集中统计得来
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((256)), # (256, 256) 区别
transforms.CenterCrop(256),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
normalizes = transforms.Normalize(norm_mean, norm_std)
valid_transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.TenCrop(224, vertical_flip=False),
transforms.Lambda(lambda crops: torch.stack([normalizes(transforms.ToTensor()(crop)) for crop in crops])),
])
# dataset
data_dir = os.path.join(BASE_DIR, "data", "train")
train_data = CatDogDataset(data_dir=data_dir, mode="train", transform=train_transform)
valid_data = CatDogDataset(data_dir=data_dir, mode="valid", transform=valid_transform)
print(train_data.__len__())
print(valid_data.__len__())
# fake dataset
fake_dir = os.path.join(BASE_DIR, "data", "test_dataset")
train_data = CatDogDataset(data_dir=fake_dir, mode="train", transform=train_transform)
valid_data = CatDogDataset(data_dir=fake_dir, mode="valid", transform=valid_transform)
print(train_data.__len__())
print(valid_data.__len__())
img_tensor, label = train_data.__getitem__(0)
img_rgb = transform_invert(img_tensor, train_transform)
print(img_tensor, label)
print(img_rgb)
plt.imshow(img_rgb)
运行结果:
22500
2500
18
2
tensor([[[0.9098, 0.9137, 0.9137, ..., 0.5961, 0.5961, 0.5882],
[0.9137, 0.9137, 0.9137, ..., 0.5490, 0.5647, 0.5373],
[0.9137, 0.9137, 0.9137, ..., 0.4196, 0.4353, 0.4549],
...,
[0.8627, 0.8667, 0.8667, ..., 0.7216, 0.6314, 0.4863],
[0.8627, 0.8667, 0.8667, ..., 0.7020, 0.5843, 0.4588],
[0.8588, 0.8627, 0.8667, ..., 0.7098, 0.5843, 0.4588]],
[[0.9176, 0.9216, 0.9216, ..., 0.6039, 0.6039, 0.5961],
[0.9216, 0.9216, 0.9216, ..., 0.5451, 0.5569, 0.5333],
[0.9216, 0.9216, 0.9216, ..., 0.4078, 0.4235, 0.4431],
...,
[0.8392, 0.8431, 0.8431, ..., 0.6824, 0.6000, 0.4510],
[0.8392, 0.8431, 0.8431, ..., 0.6627, 0.5529, 0.4235],
[0.8353, 0.8392, 0.8431, ..., 0.6745, 0.5529, 0.4235]],
[[0.8667, 0.8706, 0.8706, ..., 0.5294, 0.5294, 0.5216],
[0.8706, 0.8706, 0.8706, ..., 0.4824, 0.4980, 0.4706],
[0.8706, 0.8706, 0.8706, ..., 0.3529, 0.3686, 0.3882],
...,
[0.7765, 0.7804, 0.7804, ..., 0.6235, 0.5490, 0.4275],
[0.7765, 0.7804, 0.7804, ..., 0.6039, 0.5059, 0.3961],
[0.7725, 0.7765, 0.7804, ..., 0.6157, 0.5098, 0.3961]]]) 1
<PIL.Image.Image image mode=RGB size=224x224 at 0x14495B12BE0>
<matplotlib.image.AxesImage at 0x1449575ed30>
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True) # 20 128
valid_loader = DataLoader(dataset=valid_data, batch_size=4) # 2 4
print(BATCH_SIZE)
print(len(train_loader))
print(len(valid_loader))
运行结果:
16
2
1
构建VGG模型
使用get_vgg16函数加载预训练的VGG-16模型。
修改VGG-16模型的最后一层全连接层,将输出类别数改为2(猫和狗)。
将模型移动到设备(GPU或CPU)上。
import torchvision.models as models
def get_vgg16(path_state_dict, device, vis_model=False):
"""
创建模型,加载参数
:param path_state_dict:
:return:
"""
model = models.vgg16()
pretrained_state_dict = torch.load(path_state_dict)
model.load_state_dict(pretrained_state_dict)
model.eval()
if vis_model:
from torchsummary import summary
summary(model, input_size=(3, 224, 224), device="cpu")
model.to(device)
return model
# ============================ step 2/5 模型 ============================
path_state_dict = os.path.join(BASE_DIR, "data", "vgg16-397923af.pth")
vgg16_model = get_vgg16(path_state_dict, device, False)
num_ftrs = vgg16_model.classifier._modules["6"].in_features
vgg16_model.classifier._modules["6"] = nn.Linear(num_ftrs, num_classes)
print(num_classes)
print(num_ftrs)
vgg16_model.to(device)
print(vgg16_model)
运行结果:
2
4096
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
...
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=2, bias=True)
)
)
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
vgg16_model.features[0] # vgg16网络第一层
运行结果:
Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
vgg16_model.features[0].weight.shape # 64个3*3*3的卷积核
运行结果:
torch.Size([64, 3, 3, 3])
损失函数和优化器
使用交叉熵损失函数nn.CrossEntropyLoss()。
选择优化器,这里根据flag的值来选择不同的优化器:
当flag=1时,冻结卷积层,只更新全连接层的参数。
当flag=0时,更新所有参数。
设置学习率衰减策略,使用torch.optim.lr_scheduler.StepLR函数。
# ============================ step 3/5 损失函数 ============================
criterion = nn.CrossEntropyLoss()
# ============================ step 4/5 优化器 ============================
# 冻结卷积层
flag = 0
# flag = 1
if flag:
fc_params_id = list(map(id, vgg16_model.classifier.parameters())) # 返回的是parameters的 内存地址
base_params = filter(lambda p: id(p) not in fc_params_id, alexnet_model.parameters())
optimizer = optim.SGD([
{'params': base_params, 'lr': LR * 0.1}, # 0
{'params': vgg16_model.classifier.parameters(), 'lr': LR}], momentum=0.9)
else:
optimizer = optim.SGD(vgg16_model.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=lr_decay_step, gamma=0.1) # 设置学习率下降策略
# scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(patience=5)
print(optimizer)
print(scheduler)
运行结果:
SGD (
Parameter Group 0
dampening: 0
differentiable: False
foreach: None
initial_lr: 0.001
lr: 0.001
maximize: False
momentum: 0.9
nesterov: False
weight_decay: 0
)
<torch.optim.lr_scheduler.StepLR object at 0x00000144956ED2B0>
迭代训练
迭代训练多个epoch。
在每个epoch中,迭代训练数据集。
对于每个迭代:
将输入和标签移动到设备上。
前向传播计算输出。
计算损失并进行反向传播。
更新权重。
统计分类情况和打印训练信息。
更新学习率。
在每个epoch结束后,进行模型的验证:
在验证集上计算损失和准确率。
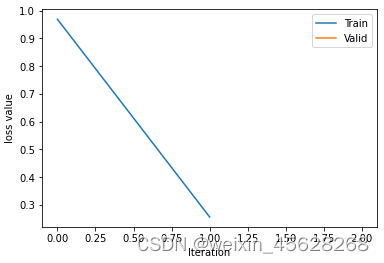
绘制训练和验证曲线图。
# ============================ step 5/5 训练 ============================
train_curve = list()
valid_curve = list()
for epoch in range(start_epoch + 1, MAX_EPOCH):
loss_mean = 0.
correct = 0.
total = 0.
vgg16_model.train()
for i, data in enumerate(train_loader):
# forward
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
outputs = vgg16_model(inputs)
# backward
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
# update weights
optimizer.step()
# 统计分类情况
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).squeeze().cpu().sum().numpy()
# 打印训练信息
loss_mean += loss.item()
train_curve.append(loss.item())
if (i+1) % log_interval == 0:
loss_mean = loss_mean / log_interval
print("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%} lr:{}".format(
epoch, MAX_EPOCH, i+1, len(train_loader), loss_mean, correct / total, scheduler.get_last_lr()))
loss_mean = 0.
scheduler.step() # 更新学习率
# validate the model
if (epoch+1) % val_interval == 0:
correct_val = 0.
total_val = 0.
loss_val = 0.
vgg16_model.eval()
with torch.no_grad():
for j, data in enumerate(valid_loader):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
bs, ncrops, c, h, w = inputs.size()
outputs = vgg16_model(inputs.view(-1, c, h, w))
outputs_avg = outputs.view(bs, ncrops, -1).mean(1)
loss = criterion(outputs_avg, labels)
_, predicted = torch.max(outputs_avg.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).squeeze().cpu().sum().numpy()
loss_val += loss.item()
loss_val_mean = loss_val/len(valid_loader)
valid_curve.append(loss_val_mean)
print("Valid:\t Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, j+1, len(valid_loader), loss_val_mean, correct_val / total_val))
vgg16_model.train()
train_x = range(len(train_curve))
train_y = train_curve
train_iters = len(train_loader)
valid_x = np.arange(1, len(valid_curve)+1) * train_iters*val_interval # 由于valid中记录的是epochloss,需要对记录点进行转换到iterations
valid_y = valid_curve
plt.plot(train_x, train_y, label='Train')
plt.plot(valid_x, valid_y, label='Valid')
plt.legend(loc='upper right')
plt.ylabel('loss value')
plt.xlabel('Iteration')
plt.savefig(os.path.join(log_dir, "loss_curve.png"))
# plt.show()
运行结果:
Training:Epoch[000/001] Iteration[001/002] Loss: 0.9694 Acc:25.00% lr:[0.001]
Training:Epoch[000/001] Iteration[002/002] Loss: 0.2565 Acc:33.33% lr:[0.001]
Valid: Epoch[000/001] Iteration[001/001] Loss: 0.4573 Acc:100.00%















 3567
3567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









