






布隆过滤器是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列映射函数。布隆过滤器可以用来检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般算法要好得多,缺点是有一定的误识别率和删除困难。
如果要判断一个元素是不是在一个集合中,一般想到的是将所有的元素保存起来,然后通过比较确定。链表,树等数据结构都是这种思路。但随着集合中元素的增加,我们需要的存储空间越来越大,检索速度越来越慢。
散列表(又称哈希表)可以通过一个Hash函数讲一个元素映射成一个位阵列中的一个点。这样一来,我们只需要看这个点是否为1就可知道该元素在集合中是否存在。这时布隆过滤器的基本思想。
算法:
- 首先需要n个hash函数,每个函数可以把key散列为1个整数。
- 初始化时,需要一个长度为k比特的数组,每个比特位初始化为0.
- 某个key加入集合时,用n个hash函数计算出n个散列值,并把数组中对应的比特位设为1.
- 判断某个key是否在集合中,用n个hash函数计算出n个散列值,并查询数组中对应的比特位,如果所有的比特位都是1,则认为key在该集合中。
布隆过滤器数据结构
布隆过滤器是由一个固定大小的二进制向量或位图和一系列映射函数组成的。
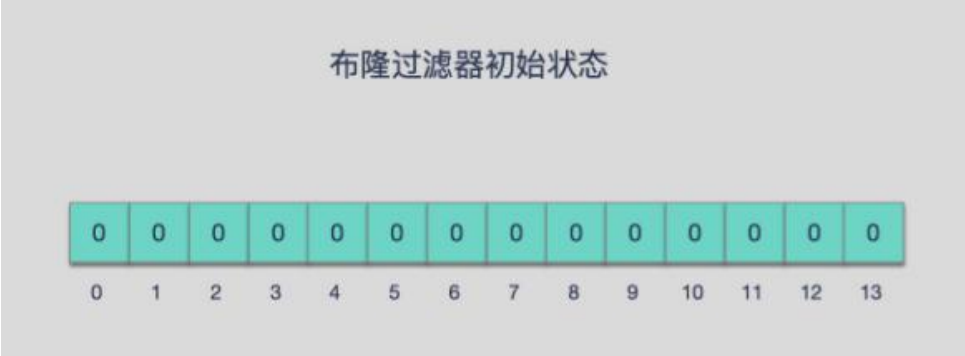
在初始状态时,对于长度为m的位数组,它的所在为都设为0,如图:
当有元素被加入集合中时,通过n个哈希数将这个变量映射成位图中的n个点,把它们设为1。
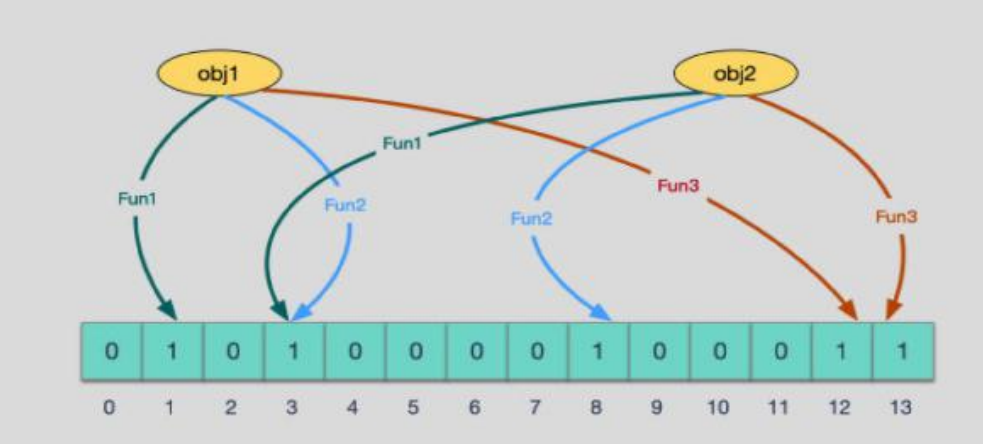
查询某个变量的时候,我们只需看这些点是否都是1,会可以大概率知道集合中有没有它了。
- 如果这些点有任何一个0,则该变量一定不存在。
- 如果都是1,则该变量很可能存在
为什么说可能存在?因为映射函数本身就是散列函数,散列函数是会有碰撞的。
优点: 不需要存储key,节省空间。
缺点:
- 算法判断key在集合中时,有一定概率误识别。
- 无法删除















 1349
1349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









