







概念与架构
推荐系统概念:
推荐系统主要用于信息过载&用户需求不明确,对用户进行项目推荐。
推荐与Web项目的区别:
Web项目:处理高并发实现高可用,提供稳定的服务(信息流)
推荐:追求指标增长,留存率,GMV(商品交易总额)等
推荐与搜索的区别:
搜索:马太效应、用户主动、需求明确、个性化弱且快速满足;
推荐:长尾效应、用户被动、需求模糊、个性化强且持续服务;
推荐系统的要素:
- UI、UE(前端)
- 数据(Lambda架构)
- 业务知识
- 算法
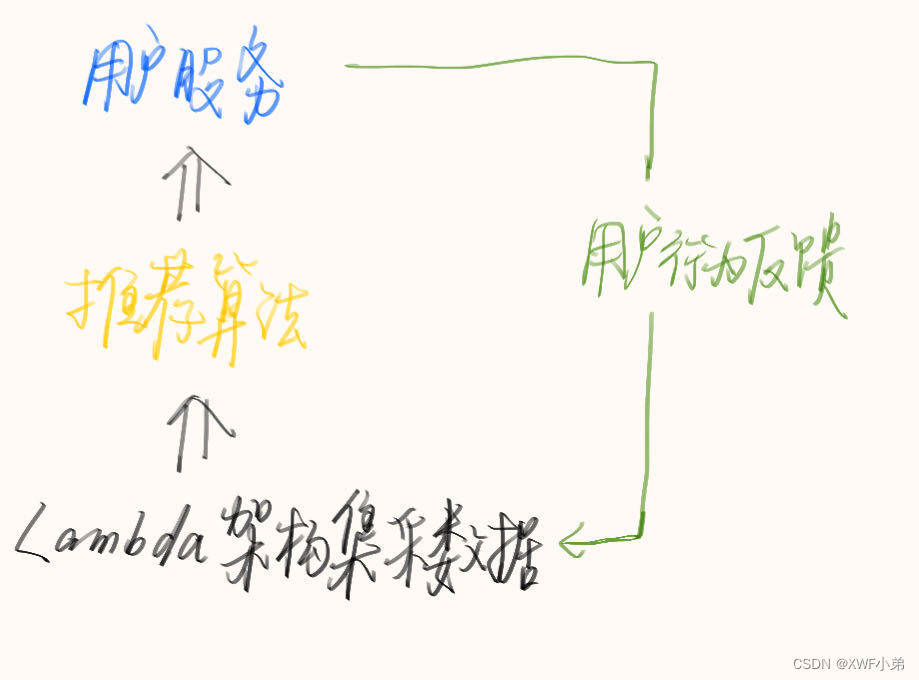
前端部分和业务知识不是重点内容(略)
Lambda架构(数据部分)
Twitter提出来的应该提供 实时数据 和 离线预先计算 的数据环境混合平台
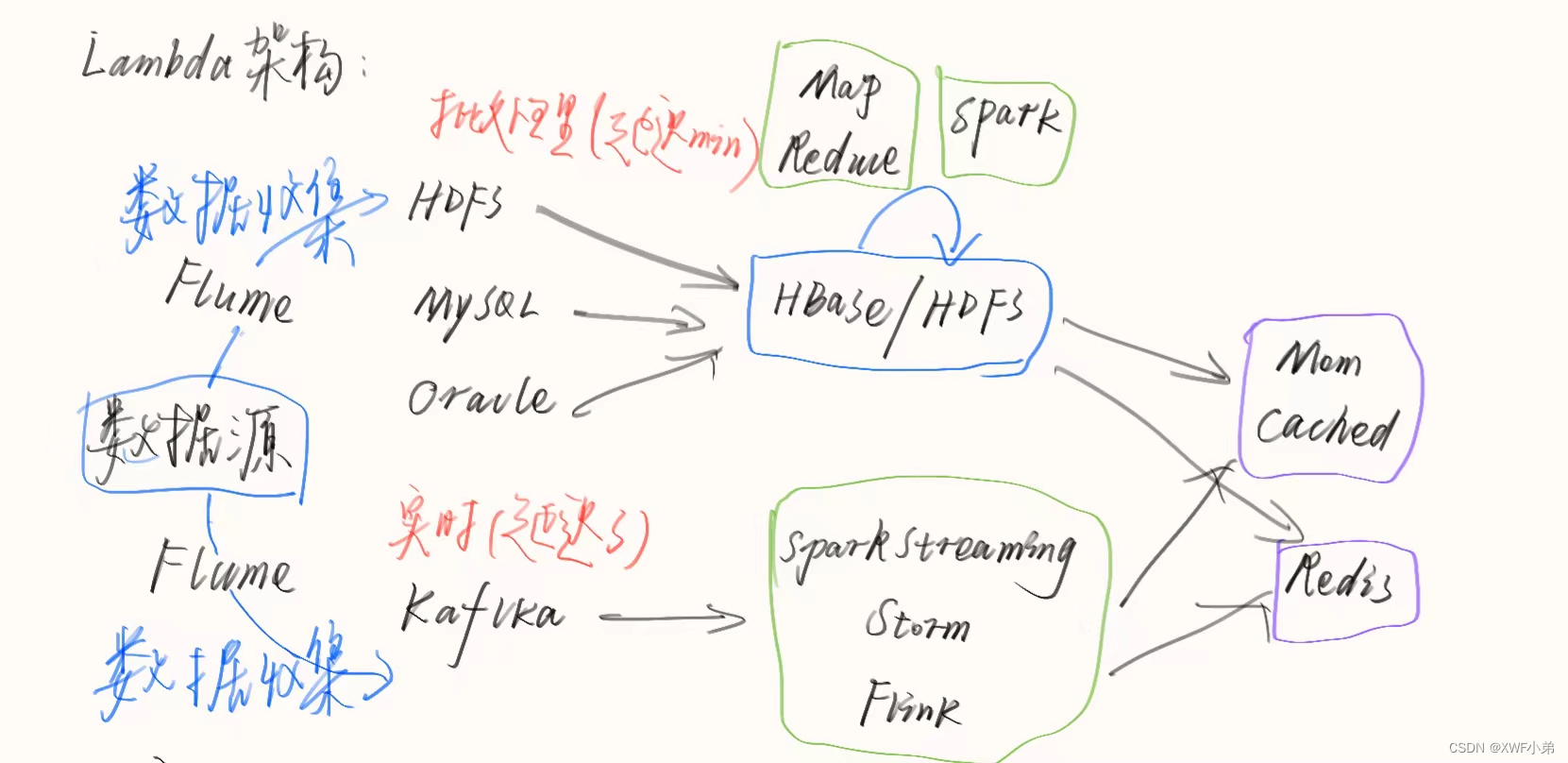
分为上下两个部分:
离线批处理(延迟达min级):
Flume是一个分布的、可靠的、高可用的海量日志聚合的系统,可用于日志数据收集,日志数据处理,日志数据传输(数据日志采集收集)
***Haddop(HDFS)***提供了高可靠性、高扩展性和高吞吐率的数据存储服务(分布式存储框架)
Haddop(MapReduce)& spark 由于计算过程需要反复操作磁盘,适用于离线计算,批计算,大规模的数据量计算(分布式计算框架)
Haddop(HBase) 和 HDFS 类似, 核心区别,在于分布适用于不同的应用负载类型,分别适用于随机访问低延迟与数据分析场景;
实时处理层(延迟达s级):
kafka是一个可持久的分布式消息队列,自带存储,提供push和pull两种存储数据功能(数据日志缓存)
spark streaming & Storm&Flink实时流处理计算框架(三种框架各有优缺实时性也有所不同)
算法部分
算法基本分为以下的四类:
①基于机器学习与协同过滤的推荐(详见UsersCF等)
②基于矩阵分解的推荐(详见MF)
③基于深度学习的推荐(详见深度学习推荐系统)
④基于图模型的推荐(详见cs224w 图机器学习与图神经网络)
推荐系统架构(总体架构)
一般是从海量item选出部分item(召回),再候选item中进行排序,再结合最后的推送策略进行重排,最后推送排名的前N个item















 230
230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









