






1 引言
在软件开发中,设计模式是一种被广泛应用的方法论,它们是在具有良好面向对象设计基础上的可重用解决方案,它可以提高代码的可重用性、可扩展性和可维护性。设计模式不仅可以让我们更快地开发出高质量的软件,而且还可以让我们更好地理解已有的代码,从而更好地进行重构和维护。
设计模式的起源可以追溯到上世纪80年代,它们最初是由四位著名的计算机科学家(Erich Gamma、Richard Helm、Ralph Johnson、John Vlissides)所提出的。这四位科学家在1994年发表了一本名为《设计模式:可复用面向对象软件的基础》的著作,其中提出了23个常用的设计模式,并将它们分为三种不同的类型:创建型模式、结构型模式和行为型模式。
使用设计模式需要遵循一些基本的设计原则,如开闭原则、里氏替换原则、单一职责原则、接口隔离原则和依赖倒置原则。这些原则可以帮助我们在设计软件时避免一些常见的错误,从而提高软件的质量和可维护性。
需要注意的是,设计模式并不是万能的,有时候它们会增加代码的复杂度并降低灵活性。因此,在使用设计模式时需要合理平衡设计的复杂度和灵活性,以确保软件系统的稳定和可维护性。
本文将介绍我学习过的9个常见设计模式,按照它们的类型分为创建型模式、结构型模式和行为型模式。每种模式都将详细讲解它的概念、实现方法和应用场景,同时还会比较不同模式之间的优缺点,帮助读者选择合适的模式。同时,本文也会强调设计模式的灵活性和实用性,并分享一些实际开发中的建议,帮助读者更好地理解和使用设计模式。
2 面向对象编程基础
面向对象编程(Object-oriented programming,OOP)是现代软件开发中广泛应用的一种编程范式,它的核心思想是将现实世界中的事物抽象成对象,并通过封装、继承和多态等机制来组织和处理这些对象。在面向对象的设计中,设计模式是一种重要的设计工具,它们可以帮助我们解决一些常见的软件设计问题,提高代码的可读性、可维护性和可扩展性。在学习设计模式之前,有必要先掌握面向对象编程的基础知识,包括封装、抽象、继承和多态等概念。这些概念是设计模式的基础,也是软件开发中不可或缺的一部分。
2.1 封装(Encapsulation)
封装(Encapsulation)是面向对象编程的一个基本特性,也是面向对象编程的三大特性之一(封装、继承、多态)。封装指的是将类的实现细节隐藏在类内部,对外只暴露有限的访问接口,授权外部仅能通过类提供的方式(或者叫函数)来访问内部信息或者数据。如果我们对类中属性的访问不做限制,那任何代码都可以访问、修改类中的属性,虽然这样看起来更加灵活,但从另一方面来说,过度灵活也意味着不可控,属性可以随意被修改,而且修改逻辑可能散落在代码中的各个角落,势必影响代码的可读性、可维护性。
在封装中,我们通过访问权限控制,即使用关键字(如Java语言中的private、public等),来限制类的属性和方法的访问范围,使得类的实现细节对外部不可见。对外只暴露有限的访问接口,暴露少许的几个必要的方法给调用者使用,调用者就不需要了解太多背后的业务细节,用错的概率就减少很多。
总结一下,封装的主要优点有:
-
提高安全性:通过将类的实现细节隐藏,可以防止外部非法访问和修改数据,保证数据的安全性。
-
提高灵活性:封装可以隔离类的实现细节和外部接口,使得类的实现细节可以更自由地变化,而不影响外部接口的使用。
-
提高可维护性:通过封装,可以将类的实现细节封装起来,使得修改类的实现细节时,不会影响外部接口的使用,从而提高代码的可维护性。
在实际编程中,我们应该合理运用封装,将类的实现细节隐藏起来,提高代码的安全性、灵活性和可维护性。
2.2 抽象(Abstraction)
抽象是面向对象编程的重要特性之一,它允许我们隐藏方法的具体实现,只暴露方法的功能接口给调用者。这样做的好处是调用者只需要知道方法提供了哪些功能,而不需要了解方法内部的实现细节,从而提高了代码的可维护性和可扩展性。
在面向对象编程中,我们通常使用接口类或抽象类来实现抽象特性。接口类是一个特殊的抽象类,它只定义了方法的接口,而没有实现任何具体的方法,因此它们只包含方法声明和常量定义。另一方面,抽象类不仅可以定义方法的接口,还可以定义具体的方法实现,但是它不能被直接实例化,只能被子类继承和实现。
接口类和抽象类的主要区别在于,接口类只能定义方法的接口,而抽象类可以定义方法的接口和具体实现,但它们都可以用来实现抽象这一特性。在使用接口类和抽象类时,我们需要根据具体的需求选择合适的机制。如果我们只需要定义方法的接口,那么使用接口类会更合适;如果我们需要定义具体的方法实现,并且需要继承和实例化,那么使用抽象类会更合适。
抽象特性的意义还在于它能够帮助我们实现代码的可维护性和可扩展性。在使用抽象特性的情况下,当我们需要修改代码的实现细节时,只需要修改具体实现的代码,而不需要修改调用者的代码,这样可以保证代码的稳定性和可维护性。同时,抽象特性也能够帮助我们实现代码的可扩展性,当我们需要增加新的功能时,只需要在已有的抽象层次上进行扩展,而不需要修改已有的代码,这样可以保证代码的灵活性和可扩展性。
总结一下,抽象的主要优点有:
● 提高代码的可读性:抽象可以使代码更加清晰简洁,降低代码的冗余性,从而提高代码的可读性,使得其他开发者更容易理解和维护代码。
● 提高代码的复用性:抽象可以使代码更加模块化,使得代码模块可以在不同的上下文中进行复用,从而提高代码的复用性,减少代码的重复编写。
● 支持多态性:抽象的实现方式可以支持多态性,使得不同的对象可以共享相同的接口和行为,从而增加了代码的灵活性和可扩展性。
总之,抽象是面向对象编程中非常重要的一个特性,它能够提高代码的可扩展性、可维护性、可读性、复用性和灵活性,使得我们能够更加高效地开发、维护和升级代码。
2.3 继承(Inheritance)
继承是面向对象编程中的一个重要概念,指的是一个类从另一个类中继承了属性和方法。被继承的类称为父类或超类,继承属性和方法的类称为子类或派生类。子类可以在不改变父类的情况下,增加自己的属性和方法,或者修改父类的方法实现,从而实现对父类的扩展或重写。
继承有以下几个优点:
-
代码复用:子类可以继承父类的属性和方法,从而避免了代码的重复编写,提高了代码的复用性。
-
扩展性:子类可以在父类的基础上进行扩展,增加自己的属性和方法,从而实现了对父类的扩展。
-
多态性:由于子类继承了父类的属性和方法,子类可以对父类的方法进行重写,从而实现多态性。
-
代码结构清晰:使用继承可以将类的结构分层,使得代码结构更加清晰。
但是,过度的继承也会带来一些问题:
-
父类和子类之间的耦合度过高,影响代码的可维护性。
-
子类继承了父类的所有属性和方法,有时会产生意想不到的副作用。
-
父类的变更可能会影响到所有的子类。
因此,在使用继承的时候,需要慎重考虑继承的深度和层级,以避免出现以上问题
2.4 多态(Polymorphism)
我们以动物为例子来说明多态。假设我们有一个Animal类,其中有一个方法叫做makeSound(),用于发出动物的声音。现在我们有两个子类Dog和Cat,它们都继承自Animal类,并且都实现了自己的makeSound()方法。在使用多态的情况下,我们可以通过Animal类型的变量,调用Dog和Cat的makeSound()方法,具体的实现取决于变量所引用的实际对象。让我们看看具体的代码实现:
public class Animal {
public void makeSound() {
System.out.println("The animal makes a sound");
}
}
public class Dog extends Animal {
@Override
public void makeSound() {
System.out.println("The dog barks");
}
}
public class Cat extends Animal {
@Override
public void makeSound() {
System.out.println("The cat meows");
}
}
public class Main {
public static void main(String[] args) {
Animal animal1 = new Dog();
Animal animal2 = new Cat();
animal1.makeSound(); // Output: The dog barks
animal2.makeSound(); // Output: The cat meows
}
}
在上面的代码中,我们定义了Animal类,以及继承自Animal类的Dog和Cat类。在Main类中,我们创建了一个Animal类型的变量animal1,它指向了一个Dog对象,另一个变量animal2则指向了一个Cat对象。在调用animal1 和animal2 的 makeSound() 方法时,实际上执行的是 Dog 和 Cat 的 makeSound() 方法,输出的结果分别是“The dog barks”和“The cat meows”。
总结一下,多态的优点有:
\1. 提高代码的可扩展性:
多态可以让我们在不修改原有代码的情况下,扩展新的类并覆盖原有类的行为。
假设我们有一个基类Animal,现在我们想添加一些新的动物,比如Bird和Fish。我们只需要继承Animal类并覆盖makeSound()方法即可,而不需要修改Animal类的代码。这样,我们可以轻松地扩展代码,而不用担心影响已有代码的运行。
-
提高代码的可维护性:
多态可以让我们在不修改原有代码的情况下,修改已有类的行为。
假设我们有一个基类Shape,现在我们想修改Rectangle类的行为,比如增加一个新的属性或方法。我们只需要修改Rectangle类的代码即可,而不用修改Shape类的代码。这样,我们可以轻松地修改代码,而不用担心影响其他代码的运行。
-
提高代码的可读性:
多态可以让代码更具有可读性,因为在代码执行时,实际调用的方法是在运行时动态确定的。
假设我们有一个基类Animal,我们可以使用多态来调用子类的方法。例如,我们可以将一个Dog对象赋值给一个Animal变量,然后调用makeSound()方法。实际上,会调用Dog类的makeSound()方法。这样代码更具有可读性,因为在代码执行时,实际调用的方法是在运行时动态确定的,而不是在编译时确定的。
3 设计原则
当进行软件设计时,我们应该遵循一些基本的设计原则,以确保我们的代码具有高可维护性、可扩展性和可重用性。以下是几个重要的设计原则:
3.1 单一职责原则(Single Responsibility Principle, SRP)
一个类或一个方法应该只负责一项职责,即只有一个引起它变化的原因,这样可以降低代码复杂度,提高可读性和可测试性。如果一个类承担了多个职责,那么当其中一个职责发生变化时,可能会影响其他职责的实现,从而导致代码的脆弱性和不稳定性。
举个例子,一个汽车类应该只负责汽车的基本操作和信息显示,不应该承担其他业务逻辑,如保险、销售等。
3.2 开闭原则(Open-Closed Principle, OCP)
一个软件实体(如类、模块、函数等)应该对扩展开放,对修改关闭。也就是说,我们应该通过扩展来实现软件功能的增加,而不是通过修改现有代码来实现,这样可以提高软件地稳定性和可复用性。
举个例子,一个负责计算订单金额的类,如果需要支持新的优惠方式,比如打折、满减等,我们可以通过添加新的计算规则来实现,而不是修改原有的计算代码。
3.3 里氏替换原则(Liskov Substitution Principle, LSP)
子类应该能够完全替换父类并且不会破坏程序的正确性。也就是说,在任何使用父类对象的地方,都应该能够使用子类对象来无缝代替,而不会引起任何错误或异常,这样可以保证继承关系的合理性和多态的正确性。
举个例子,假设有一个 Animal 类和一个 Dog 类,Dog 类继承自 Animal 类。如果我们有一个函数接收一个 Animal 类型的参数,那么我们也可以传递一个 Dog 类型的参数,因为 Dog 类型可以完全替换 Animal 类型而不会引起任何错误或异常。
3.4 接口隔离原则(Interface Segregation Principle, ISP)
客户端不应该依赖它不需要的接口。也就是说,我们应该将接口细分为更小的粒度,以确保客户端只需要依赖于它需要的接口,这样可以降低接口的复杂度,提高接口的可用性和灵活性。
举个例子,一个电子产品接口应该被细分为音频接口、视频接口、数据接口等,客户端可以根据需要只依赖于它所需的接口。
3.5 依赖倒置原则(Dependency Inversion Principle, DIP)
高层模块不应该依赖低层模块,二者都应该依赖其抽象。抽象不应该依赖于具体实现细节,具体实现细节应该依赖于抽象,即要针对接口编程,而不是针对实现编程,这样可以降低模块之间的耦合度,提高模块的可替换性和可扩展性。
举个例子,一个程序需要读取不同类型的文件,可以定义一个抽象的FileReader接口,不同的文件类型可以实现这个接口,并在高层模块中调用这个接口,而不需要直接依赖于具体的文件读取实现。这样,当需要添加新的文件读取类型时,只需要实现这个接口即可,不会对程序的其他部分产生影响。
3.6 迪米特法则(Law of Demeter)
它规定了一个对象应当对其他对象有尽可能少的了解,也就是一个对象不应该知道太多关于其他对象的信息。该原则可以帮助我们减少系统中各个对象之间的耦合度,从而使系统更加易于维护和扩展。
举个例子,一个购物车应该只需要和商品打交道,而不需要直接和用户、库存、支付等对象打交道。通过引入中介对象如订单,购物车只需要与订单对象打交道,订单对象负责与用户、库存、支付等对象进行交互,购物车只需要关注商品的添加、删除、修改等操作即可。这样,当需要修改用户、库存、支付等对象时,购物车的实现不需要做出任何修改,只需要修改订单对象即可。
4 设计原则与设计模式的关系
在设计模式中,常常会使用设计原则作为指导原则来帮助我们设计出符合标准的、易于维护和扩展的代码。让我们来看看一些常见的设计模式是如何运用这些设计原则的:
-
工厂方法模式(Factory Method Pattern):该模式使用工厂方法来处理对象的创建,将对象的创建和使用分离。这个模式中的关键是抽象工厂类和抽象产品类的定义,以及具体工厂类和具体产品类的实现。它使用了开闭原则和依赖倒置原则,通过抽象工厂类来屏蔽对象创建的具体实现,从而提高了系统的灵活性和可扩展性。
-
单例模式(Singleton Pattern):该模式保证一个类只有一个实例,并且提供一个全局访问点。这个模式使用了单一职责原则、开闭原则和迪米特法则,通过将对象的创建和使用分离,保证了系统的可扩展性和可维护性,同时提供了一个全局的访问点来方便系统的访问和管理。
-
适配器模式(Adapter Pattern):该模式用于将一个类的接口转换成客户希望的另外一个接口,使得原本不兼容的类可以合作无间。这个模式使用了依赖倒置原则、接口隔离原则和单一职责原则,通过将客户端和被适配者分离开来,实现了系统的松耦合,同时通过抽象适配器来屏蔽具体实现,提高了系统的灵活性和可扩展性。
-
装饰器模式(Decorator Pattern):该模式动态地给一个对象添加一些额外的职责,就增加功能来说,它比生成子类更为灵活。这个模式使用了开闭原则和依赖倒置原则,通过使用抽象装饰器和具体装饰器来动态地添加功能,实现了系统的可扩展性和可维护性。
-
观察者模式(Observer Pattern):该模式定义了对象之间的一种一对多的依赖关系,当一个对象的状态发生改变时,它的所有依赖者都会收到通知并自动更新。这个模式使用了开闭原则和依赖倒置原则,通过抽象观察者和具体观察者来分离出观察者和被观察者之间的耦合关系,提高系统的可扩展性和可维护性。
5 常见设计模式及应用
5.1 创建型模式
创建型模式是一类设计模式,它们关注如何创建对象,以及如何将对象进行组合形成更复杂的对象。创建型模式在系统设计中具有很大的作用,可以使得系统更加灵活、扩展性更好,同时也能提高系统的可维护性和可读性。常见的创建型模式有单例模式、工厂模式、抽象工厂模式、建造者模式和原型模式
5.1.1 单例模式
单例设计模式(Singleton Design Pattern)理解起来非常简单。一个类只允许创建一个对象(或者实例),那这个类就是一个单例类,这种设计模式就叫作单例设计模式,简称单例模式。
5.1.1.1 为什么要使用单例
我通过两个案例来讲解为什么要使用这种设计模式,以及它能解决哪些问题。
例子一:配置文件读取
我们来看一个实际的应用场景,假设我们要编写一个程序,这个程序需要读取配置文件,然后在程序中使用这些配置信息。那我们应该如何实现呢?
一种做法是,每次需要配置信息时,都读取一遍配置文件,然后使用这些配置信息。这样做法的问题是,每次都需要打开文件、读取文件,非常耗时,并且还会占用过多的资源,容易导致程序崩溃。
另一种做法是,只在程序启动时读取一次配置文件,然后把配置信息保存在内存中,以后需要使用这些配置信息时,直接从内存中获取即可。这种做法的问题是,如果在程序中创建了多个实例,每个实例都会读取一次配置文件,导致资源的浪费。
那怎么办呢?这时候,单例模式就派上用场了。我们可以将配置文件的读取过程封装在一个单例类中,然后在程序启动时创建一个实例,并将这个实例保存在内存中。以后需要使用配置信息时,直接通过这个单例实例获取即可,这样既能保证读取配置信息的效率,又不会浪费过多的资源。
例子二:数据库连接池
再来看一个实际的应用场景,假设我们正在编写一个Web应用程序,这个程序需要连接数据库,然后执行一些SQL查询操作。那我们应该如何实现呢?
一种做法是,每次需要数据库连接时,都打开一次数据库连接,执行完操作后再关闭数据库连接。这样做法的问题是,每次打开和关闭数据库连接都需要一定的时间和资源,导致程序效率低下,而且还容易导致数据库连接过多,导致程序崩溃。
另一种做法是,使用数据库连接池。在程序启动时,先创建一些数据库连接,并将这些连接保存在内存中。以后需要连接数据库时,从内存中获取一个连接,然后执行完操作后再将连接放回池中,这样既能保证程序的效率,又能避免连接过多导致程序崩溃。
那怎么实现数据库连接池呢?这时候,单例模式又可以派上用场了。我们可以将数据库连接池封装在一个单例类中,然后在程序启动时创建一个实例,并将这个实例保存在内存中。以后需要使用数据库连接时,直接通过这个单例实例获取即可,这样既能保证程序的效率,又能避免连接过多导致程序崩溃。
综上所述,单例模式的主要作用就是,确保一个类只有一个实例。
5.1.1.2 如何实现一个单例?
要实现一个单例,我们需要关注的点主要是这几个:
-
构造函数需要是private访问权限的,这样才能避免外部通过new创建实例;
-
考虑对象创建时的线程安全问题;
-
考虑是否支持延迟加载;
-
考虑getInstance()性能是否高(是否加锁)。
几种常见的单例实现方式:
5.1.1.2.1 饿汉式
饿汉式是一种常见的单例实现方式,其特点是在类加载的时候就创建实例,并在整个应用生命周期中保持唯一实例。这种方式的优点是实现简单,线程安全,且可以保证在任何时候都可以获得到实例。但是也有一个缺点,即无法实现延迟加载,如果实例的初始化需要占用大量资源,会造成资源浪费。
以下是一个简单的饿汉式实现代码:
public class IdGenerator {
private AtomicLong id = new AtomicLong(0);
private static final IdGenerator instance = new IdGenerator();
private IdGenerator() {}
public static IdGenerator getInstance() {
return instance;
}
public long getId() {
return id.incrementAndGet();
}
}
在这个实现中,我们将IdGenerator的构造方法设置为private,确保外部无法直接创建实例。同时,我们在类中定义了一个私有的静态变量instance,并在类加载时直接初始化。由于类加载是线程安全的,因此这种实现方式可以保证线程安全性。
在调用getInstance()方法时,我们直接返回预先创建好的静态实例即可。由于实例在类加载时就已经创建好了,因此可以保证在任何时候都可以获得到实例。
这种实现方式虽然不支持延迟加载,但是在实例初始化需要占用大量资源的情况下,可以避免在运行时出现性能问题,因此仍然是一种常见的单例实现方式。
5.1.1.2.2 懒汉式
懒汉式相比于饿汉式,实例的创建是在需要时才进行的,支持延迟加载,不会浪费系统资源。不过,在多线程环境下,需要考虑线程安全问题,避免多个线程同时创建实例,导致实例不唯一。
以下是一个线程安全的懒汉式单例实现:
public class IdGenerator {
private AtomicLong id = new AtomicLong(0);
private static IdGenerator instance;
private IdGenerator() {}
public static synchronized IdGenerator getInstance() {
if (instance == null) {
instance = new IdGenerator();
}
return instance;
}
public long getId() {
return id.incrementAndGet();
}
}
在getInstance()方法中,使用synchronized关键字对方法进行加锁,保证在多线程环境下只有一个线程可以进入方法创建实例,其他线程需要等待锁的释放。这种实现方式虽然线程安全,但由于加锁会影响getInstance()的性能,因此在高并发环境下可能会存在性能问题。
5.1.1.2.3 双重检测锁实现
双重检测锁(Double Checked Lock,简称DCL)实现方式是一种既支持延迟加载、又支持高并发的单例实现方式。具体的代码实现如下所示:
public class IdGenerator {
private static volatile IdGenerator instance;
private IdGenerator() {}
public static IdGenerator getInstance() {
if (instance == null) {
synchronized(IdGenerator.class) {
if (instance == null) {
instance = new IdGenerator();
}
}
}
return instance;
}
}
在这个实现方式中,我们仍然使用一个私有构造函数来保证不能通过构造函数来创建对象实例。在类加载时,静态变量instance并没有被初始化,只有在第一次调用getInstance()方法时,虚拟机才会加载并初始化静态变量。同时,由于这个静态变量是volatile类型的,所以它保证了多线程之间的可见性。在静态变量被初始化之后,我们就可以通过一个全局访问点(方法)来获取这个单例对象了。
在获取单例对象的时候,我们进行了两次判空操作。第一次是为了避免不必要的同步,第二次是在同步块内部进行判空,确保了在实例对象被创建后,同步块内部的代码不会被再次执行。同时,由于锁的粒度只有到类的粒度,所以这种实现方式会带来比较好的性能。
5.1.1.2.4 静态内部类
利用Java的类加载机制来实现线程安全的延迟加载。具体实现方法是,将单例对象放到一个静态内部类中,在调用getInstance()方法时才加载该内部类,并创建单例对象。由于静态内部类只会被加载一次,因此这种方法可以保证线程安全,也能够实现延迟加载。
具体的代码实现如下所示:
public class IdGenerator {
private IdGenerator() {}
private static class SingletonHolder {
private static final IdGenerator instance = new IdGenerator();
}
public static IdGenerator getInstance() {
return SingletonHolder.instance;
}
public long getId() {
// 生成唯一ID的方法
}
}
这种实现方法相对于双重检测来说,更加简单,代码也更加清晰易懂。但是,instance的唯一性、创建过程的线程安全性,都由JVM来保证,所以有些开发者可能不太容易理解。同时,这种实现方法也不支持传参。如果需要在创建单例对象时传递参数,就无法使用这种实现方法了。
5.1.1.2.4 枚举
基于枚举类型的单例实现是一种最简单的实现方式,这种实现方式通过Java枚举类型本身的特性,保证了实例创建的线程安全性和实例的唯一性。具体的代码如下所示:
public enum IdGenerator {
INSTANCE;
public long getId() {
return ...;
}
}
在这个实现中,INSTANCE是一个枚举常量,它在JVM中是唯一的。当我们第一次调用IdGenerator.INSTANCE.getId()方法时,Java会加载并初始化IdGenerator类,此时,INSTANCE常量会被初始化为一个实例。我们可以通过枚举类型的特性,保证INSTANCE在整个应用中是唯一的,并且这个实例的创建是线程安全的。由于枚举类型在Java中是天然的单例模式,所以我们不需要再手动实现单例模式,这样可以避免手动实现单例模式带来的线程安全性问题和代码复杂度。
5.1.1.3 单例存在哪些问题
单例模式存在以下几个问题:
-
破坏封装性:单例模式要求单例类必须具有全局唯一性,这就要求单例类的构造函数必须是私有的,不能被外部访问。为了在其他类中使用单例类的实例,我们只能通过单例类提供的静态方法getInstance()来获取单例实例。这就暴露了类的实现细节,破坏了类的封装性。
-
难以扩展:由于单例类的构造函数是私有的,因此无法通过继承来扩展单例类的行为。而且,如果需要扩展单例类的行为,必须修改单例类的源代码,这样就违背了开闭原则。
-
对象生命周期过长:单例对象一般在整个应用程序的生命周期内都存在,如果单例对象持有大量的资源,会导致这些资源在应用程序生命周期中一直得不到释放,从而导致内存泄漏和系统性能下降。
-
难以进行单元测试:由于单例类的实例不能通过构造函数创建,也不能通过其他方式销毁,所以在进行单元测试时,很难对单例类进行测试。
-
可能引起性能问题:虽然单例模式在一定程度上可以避免对象的重复创建,但是在高并发环境下,getInstance()方法可能成为瓶颈,导致性能下降。特别是在使用懒加载的单例模式中,需要进行加锁操作,进一步降低了性能。
5.1.1.4 单例的替代解决方案
除了单例模式外,工厂模式和IOC容器也可以实现全局唯一性,在编写代码时我们也可以通过自己的控制来保证不会创建两个类对象(这就类似Java中内存对象的释放由JVM来负责,而C++中由程序员自己负责,道理是一样的)。在实际开发中,我们应该根据实际情况和需求来选择最合适的方式来保证类对象的全局唯一性。
5.1.1.5 如何理解单例模式中的唯一性
单例模式中的唯一性指的是,在一个进程中只能存在一个实例对象。换句话说,无论在什么地方、什么时间,只要是在同一个进程中,获取到的单例对象都是同一个。
这种唯一性保证了单例对象的一致性和可控性,可以避免在多处创建相同对象而导致的资源浪费和状态不一致的问题。同时,由于单例对象只有一个,所以它也能够作为一个全局的数据中心,提供数据共享和通信的功能。
需要注意的是,单例模式中的唯一性只是在同一个进程内部的保证,不同进程之间的单例对象是相互独立的,也就是说不同进程中的单例对象并不是同一个实例。这是由于不同进程拥有独立的地址空间,无法共享同一个对象实例。
5.1.1.6 如何实现线程唯一的单例
线程唯一的单例指的是在一个线程内,只有一个对象实例,每个线程都有自己独立的对象实例,不同线程之间的对象实例可以不同。而进程唯一的单例指的是在一个进程内,只有一个对象实例,不同进程之间的对象实例可以不同。
线程唯一的单例可以使用Java中的ThreadLocal类来实现。ThreadLocal类可以为每个线程创建一个独立的对象实例,保证了在同一个线程内,只有一个对象实例,不同线程之间的对象实例可以不同。具体来说,通过定义一个ThreadLocal变量,可以将每个线程独立的对象实例存储到线程局部变量中,从而实现线程唯一的单例。
这里提供一个简单的示例代码,用于说明如何使用ThreadLocal类实现线程唯一的单例:
public class Singleton {
private static final ThreadLocal<Singleton> threadLocalInstance = ThreadLocal.withInitial(Singleton::new);
private Singleton() {}
public static Singleton getInstance() {
return threadLocalInstance.get();
}
}
在这个示例代码中,定义了一个私有构造函数和一个公有的静态方法getInstance,用于获取单例对象。在getInstance方法中,通过threadLocalInstance.get()方法获取当前线程对应的Singleton对象。由于每个线程都有自己独立的线程局部变量,因此每个线程都会创建自己独立的Singleton实例,从而实现了“线程唯一”的单例。
再来一个复杂一点的例子,这个例子是一个线程池,每个线程都有一个独立的单例对象。如果多个线程在同一个线程池中运行,它们仍然共享同一个单例对象,但是在不同线程池中运行的线程会有不同的单例对象。
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class MyThreadPool {
private static final ThreadLocal<MySingleton> THREAD_LOCAL = ThreadLocal.withInitial(() -> new MySingleton());
private static final ExecutorService EXECUTOR_SERVICE = Executors.newFixedThreadPool(3);
private MyThreadPool() {
// 初始化代码
}
public static void execute(Runnable task) {
EXECUTOR_SERVICE.submit(() -> {
MySingleton instance = THREAD_LOCAL.get();
// 使用instance处理任务
task.run();
// 清理ThreadLocal
THREAD_LOCAL.remove();
});
}
public static void shutdown() throws InterruptedException {
EXECUTOR_SERVICE.shutdown();
EXECUTOR_SERVICE.awaitTermination(10, TimeUnit.SECONDS);
}
}
在这个示例代码中,我们使用了一个固定大小的线程池来处理任务。在execute方法中,我们通过ThreadLocal来获取当前线程的单例对象,并在任务处理完毕后清理ThreadLocal。在shutdown方法中,我们关闭线程池并等待所有任务完成。
5.1.2 工厂模式
工厂模式是一种创建型设计模式,它用工厂方法代替直接使用new操作符来创建对象,从而实现了对对象创建过程的封装和解耦。工厂模式有三种常见的变体,分别是简单工厂模式、厂方法模式、抽象工厂模式。
5.1.2.1 简单工厂模式(Simple Factory Pattern)
一个工厂类根据传入的参数决定创建出哪一种产品类的实例。
简单工厂模式包含 3 个角色(要素):
-
Factory:即工厂类, 简单工厂模式的核心部分,负责实现创建所有产品的内部逻辑;工厂类可以被外界直接调用,创建所需对象
-
Product:抽象类产品, 它是工厂类所创建的所有对象的父类,封装了各种产品对象的公有方法,它的引入将提高系统的灵活性,使得在工厂类中只需定义一个通用的工厂方法,因为所有创建的具体产品对象都是其子类对象
-
ConcreteProduct:具体产品, 它是简单工厂模式的创建目标,所有被创建的对象都充当这个角色的某个具体类的实例。它要实现抽象产品中声明的抽象方法
UML 类图
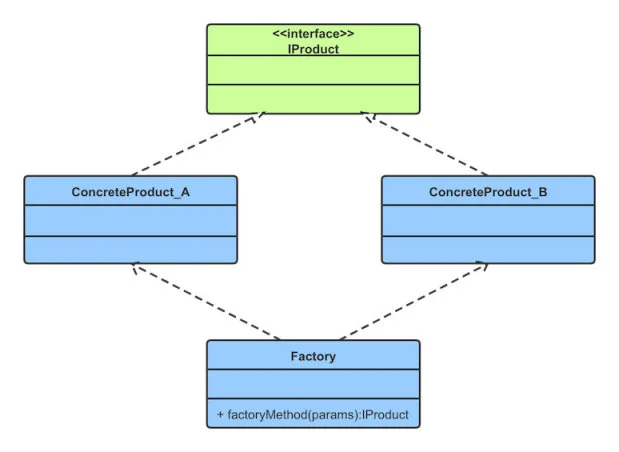
img
5.1.2.1.1 使用简单工厂模式
以下是一个示例,演示如何使用简单工厂模式创建图形对象。
首先,我们定义一个图形接口Shape,其中包含一个绘制方法draw:
public interface Shape {
void draw();
}
然后,我们定义具体的图形类,例如Rectangle、Circle和Triangle,它们都实现了Shape接口,并分别实现了draw方法:
public class Rectangle implements Shape {
@Override
public void draw() {
System.out.println("Draw a rectangle.");
}
}
public class Circle implements Shape {
@Override
public void draw() {
System.out.println("Draw a circle.");
}
}
public class Triangle implements Shape {
@Override
public void draw() {
System.out.println("Draw a triangle.");
}
}
接下来,我们定义一个简单工厂类ShapeFactory,用于创建图形对象。它包含一个静态方法getShape,根据传入的参数来返回相应的图形对象:
public class ShapeFactory {
public static Shape getShape(String shapeType) {
if (shapeType == null) {
return null;
}
if (shapeType.equalsIgnoreCase("rectangle")) {
return new Rectangle();
} else if (shapeType.equalsIgnoreCase("circle")) {
return new Circle();
} else if (shapeType.equalsIgnoreCase("triangle")) {
return new Triangle();
}
return null;
}
}
最后,我们可以在客户端代码中使用ShapeFactory来创建具体的图形对象,如下所示:
public class Client {
public static void main(String[] args) {
Shape rectangle = ShapeFactory.getShape("rectangle");
rectangle.draw();
Shape circle = ShapeFactory.getShape("circle");
circle.draw();
Shape triangle = ShapeFactory.getShape("triangle");
triangle.draw();
}
}
运行上述代码,输出如下:
Draw a rectangle.
Draw a circle.
Draw a triangle.
以上就是一个简单工厂模式的示例。使用简单工厂模式,我们可以将图形对象的创建过程封装在ShapeFactory中,使得客户端代码只需要关心要创建哪种类型的图形对象,而无需关心具体的创建细节。这样可以提高代码的可维护性和扩展性。
5.1.2.1.2 简单工厂模式总结
简单工厂模式的优点是:
-
简化了对象的创建过程,客户端不需要了解具体的创建细节,只需要向工厂类传递一个参数即可获取所需的对象。
-
工厂类集中了所有对象的创建过程,方便维护和管理。
简单工厂模式的缺点是:
-
工厂类包含了所有产品对象的创建逻辑,一旦工厂类出现问题,所有产品对象的创建都将受到影响。
-
由于工厂类需要根据客户端传入的参数来判断要创建的产品对象,如果客户端传入了错误的参数,将无法创建正确的产品对象。
总的来说,简单工厂模式适用于产品对象较少的情况,当系统中的具体产品类不断增多时候,可能会出现要求工厂类根据不同条件创建不同实例的需求.这种对条件的判断和对具体产品类型的判断交错在一起,很难避免模块功能的蔓延,对系统的维护和扩展非常不利。
5.1.2.2 工厂方法模式(Factory Method Pattern)
定义一个用于创建对象的接口,让子类决定实例化哪一个类。工厂方法使一个类的实例化延迟到其子类。
工厂方法模式包含 4 个角色(要素):
-
Product:抽象产品,定义工厂方法所创建的对象的接口,也就是实际需要使用的对象的接口
-
ConcreteProduct:具体产品,具体的 Product 接口的实现对象
-
Factory:工厂接口,也可以叫 Creator(创建器),申明工厂方法,通常返回一个 Product 类型的实例对象
-
ConcreteFactory:工厂实现,或者叫 ConcreteCreator(创建器对象),覆盖 Factory 定义的工厂方法,返回具体的 Product 实例
UML 类图
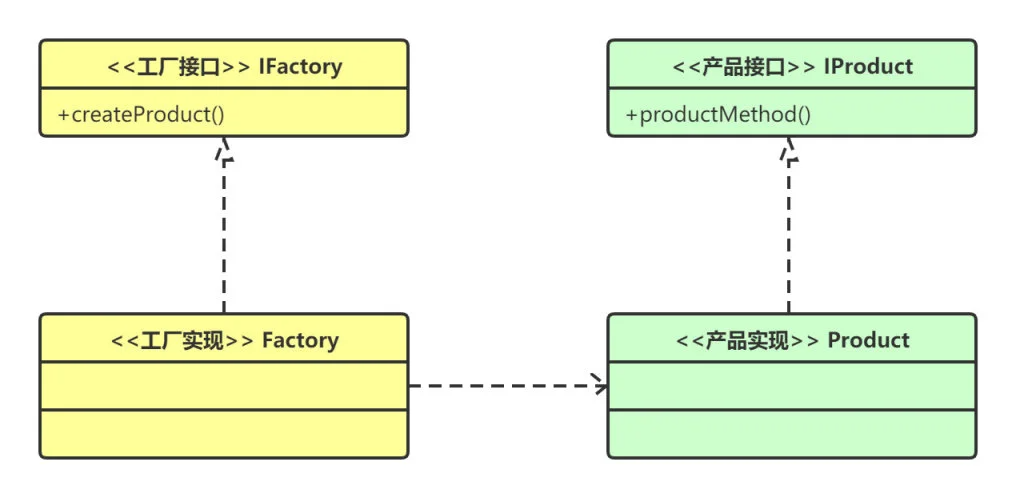
img
5.1.2.2.1 使用工厂方法模式
下面是一个使用工厂方法模式的例子:
假设有一个图形接口 Shape,它有一个 draw() 方法用于绘制该图形。现在有三种具体图形:圆形、矩形和三角形。每个具体图形都需要实现 Shape 接口并实现 draw() 方法。
使用工厂方法模式,可以定义一个 ShapeFactory 接口,该接口有一个 createShape() 方法,该方法返回一个 Shape 对象。然后,可以为每种具体图形创建一个 ShapeFactory 的实现类,用于创建该图形的实例。
下面是示例代码:
// Shape 接口
public interface Shape {
void draw();
}
// Circle 具体图形
public class Circle implements Shape {
@Override
public void draw() {
System.out.println("Drawing a Circle");
}
}
// Rectangle 具体图形
public class Rectangle implements Shape {
@Override
public void draw() {
System.out.println("Drawing a Rectangle");
}
}
// Triangle 具体图形
public class Triangle implements Shape {
@Override
public void draw() {
System.out.println("Drawing a Triangle");
}
}
// ShapeFactory 接口
public interface ShapeFactory {
Shape createShape();
}
// CircleFactory 具体工厂
public class CircleFactory implements ShapeFactory {
@Override
public Shape createShape() {
return new Circle();
}
}
// RectangleFactory 具体工厂
public class RectangleFactory implements ShapeFactory {
@Override
public Shape createShape() {
return new Rectangle();
}
}
// TriangleFactory 具体工厂
public class TriangleFactory implements ShapeFactory {
@Override
public Shape createShape() {
return new Triangle();
}
}
// 使用工厂方法模式创建图形对象
public class Client {
public static void main(String[] args) {
ShapeFactory factory = new CircleFactory();
Shape shape = factory.createShape();
shape.draw();
factory = new RectangleFactory();
shape = factory.createShape();
shape.draw();
factory = new TriangleFactory();
shape = factory.createShape();
shape.draw();
}
}
在这个例子中,我们定义了一个 Shape 接口和三个具体的图形类。然后,我们定义了一个 ShapeFactory 接口和三个具体的工厂类,用于创建对应的图形对象。最后,在 Client 类中,我们可以使用具体的工厂类来创建相应的图形对象,并调用它的 draw() 方法。由于每个图形类都实现了 Shape 接口,因此我们可以统一地调用它们的 draw() 方法,而不需要关心它们的具体类型。
是不是感觉更复杂了,那怎么来解决这个问题呢?我们可以为工厂类再创建一个简单工厂,也就是工厂的工厂,用来创建工厂类对象。 具体实现如下所示:
public class ShapeFactoryFactory {
private static final Map<String, ShapeFactory> factoryMap = new HashMap<>();
static {
factoryMap.put("circle", new CircleFactory());
factoryMap.put("square", new SquareFactory());
factoryMap.put("rectangle", new RectangleFactory());
}
public static ShapeFactory getFactory(String type) {
return factoryMap.get(type.toLowerCase());
}
}
然后,在 Client 类中,我们可以通过调用工厂的工厂来获取对应的工厂对象,具体实现如下所示:
public class Client {
public static void main(String[] args) {
ShapeFactory circleFactory = ShapeFactoryFactory.getFactory("circle");
Shape circle = circleFactory.createShape();
circle.draw();
ShapeFactory squareFactory = ShapeFactoryFactory.getFactory("square");
Shape square = squareFactory.createShape();
square.draw();
ShapeFactory rectangleFactory = ShapeFactoryFactory.getFactory("rectangle");
Shape rectangle = rectangleFactory.createShape();
rectangle.draw();
}
}
这样做的好处是,可以避免每次创建新的工厂类对象,减少对象的创建和销毁,提高程序的性能。同时,通过将工厂类作为参数传入工厂的工厂中,也可以更加灵活地配置和管理工厂类对象。
5.1.2.2.2 工厂方法模式适用场景
工厂方法模式和简单工厂模式虽然都是通过工厂来创建对象,他们之间最大的不同是——工厂方法模式在设计上完全完全符合“开闭原则”。
在以下情况下可以使用工厂方法模式:
-
一个类不知道它所需要的对象的类:在工厂方法模式中,客户端不需要知道具体产品类的类名,只需要知道所对应的工厂即可,具体的产品对象由具体工厂类创建;客户端需要知道创建具体产品的工厂类。
-
一个类通过其子类来指定创建哪个对象:在工厂方法模式中,对于抽象工厂类只需要提供一个创建产品的接口,而由其子类来确定具体要创建的对象,利用面向对象的多态性和里氏代换原则,在程序运行时,子类对象将覆盖父类对象,从而使得系统更容易扩展。
-
将创建对象的任务委托给多个工厂子类中的某一个,客户端在使用时可以无须关心是哪一个工厂子类创建产品子类,需要时再动态指定,可将具体工厂类的类名存储在配置文件或数据库中。
5.1.2.2.3 工厂方法模式总结
工厂方法模式是简单工厂模式的进一步抽象。
由于使用了面向对象的多态性,工厂方法模式保持了简单工厂模式的优点,而且克服了它的缺点。
在工厂方法模式中,核心的工厂类不再负责所有产品的创建,而是将具体创建工作交给子类去做。这个核心类仅仅负责给出具体工厂必须实现的接口,而不负责产品类被实例化这种细节,这使得工厂方法模式可以允许系统在不修改工厂角色的情况下引进新产品。
优点:
-
一个调用者想创建一个对象,只要知道其名称就可以了。
-
扩展性高,如果想增加一个产品,只要扩展一个工厂类就可以。
-
屏蔽产品的具体实现,调用者只关心产品的接口。
缺点:
每次增加一个产品时,都需要增加一个具体类和对象实现工厂,使得系统中类的个数成倍增加,在一定程度上增加了系统的复杂度,同时也增加了系统具体类的依赖。这并不是什么好事。
5.1.3 建造者模式
将一个复杂对象的构建与其表示分离,使得同样的构建过程可以创建不同的表示
建造者模式包含 4 个角色(要素):
Director:指挥者,用于构造使用Builder接口的对象。 Builder:抽象建造者,定义产品对象的各个部件的抽象接口。 ConcreteBuilder:具体建造者,实现Builder的接口用于构造和装配该产品的各个部件。 Product:产品角色。
UML 类图
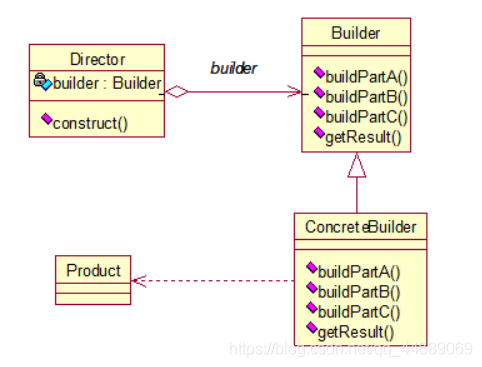
img
5.1.3.1 建造模式的适用场景和使用
上面的介绍可能不是很好理解,我们直接通过一个实际案例来进一步了解建造者模式的适用场景和使用。
假设有这样一道设计面试题:设计一个连接池类 ConnectionPool,用于管理数据库连接,该类应该包含以下几个成员变量,现在请你编写这个 ConnectionPool 类的实现代码。
| 变量名 | 描述 | 是否必填 | 默认值 |
|---|---|---|---|
| name | 连接池的名称,用于标识不同的连接池实例。 | 是 | 无 |
| max_connections | 连接池中允许的最大连接数。 | 否 | 10 |
| min_connections | 连接池中允许的最小连接数。 | 否 | 1 |
| connection_timeout | 从连接池中获取连接到连接实际可用的最长等待时间,单位为秒。 | 否 | 30 |
| idle_timeout | 连接池中空闲连接的最大存活时间,超过这个时间的连接将被回收,单位为秒。 | 否 | 300 |
根据需求最容易想到的实现思路应该如下代码所示。这个类包含了一个默认构造方法和一个包含所有可配置项的构造方法。在第二个构造方法中,我们使用了和 ResourcePoolConfig 类类似的参数校验逻辑,确保传入的值符合要求。对于没有传入的参数,我们使用了默认值。
public class ConnectionPool {
private static final int DEFAULT_MAX_CONNECTIONS = 10;
private static final int DEFAULT_MIN_CONNECTIONS = 1;
private static final int DEFAULT_CONNECTION_TIMEOUT = 30;
private static final int DEFAULT_IDLE_TIMEOUT = 300;
private String name;
private int maxConnections = DEFAULT_MAX_CONNECTIONS;
private int minConnections = DEFAULT_MIN_CONNECTIONS;
private int connectionTimeout = DEFAULT_CONNECTION_TIMEOUT;
private int idleTimeout = DEFAULT_IDLE_TIMEOUT;
public ConnectionPool(String name) {
if (StringUtils.isBlank(name)) {
throw new IllegalArgumentException("name should not be empty.");
}
this.name = name;
}
public ConnectionPool(String name, Integer maxConnections, Integer minConnections, Integer connectionTimeout, Integer idleTimeout) {
if (StringUtils.isBlank(name)) {
throw new IllegalArgumentException("name should not be empty.");
}
this.name = name;
if (maxConnections != null) {
if (maxConnections <= 0) {
throw new IllegalArgumentException("maxConnections should be positive.");
}
this.maxConnections = maxConnections;
}
if (minConnections != null) {
if (minConnections < 0) {
throw new IllegalArgumentException("minConnections should not be negative.");
}
this.minConnections = minConnections;
}
if (connectionTimeout != null) {
if (connectionTimeout < 0) {
throw new IllegalArgumentException("connectionTimeout should not be negative.");
}
this.connectionTimeout = connectionTimeout;
}
if (idleTimeout != null) {
if (idleTimeout < 0) {
throw new IllegalArgumentException("idleTimeout should not be negative.");
}
this.idleTimeout = idleTimeout;
}
}
// 省略get、set方法
}
现在,ConnectionPool 只有4个可配置项,对应到构造函数中也只有4个参数,参数个数不多。但如果可配置项主键增多,变成了10个,20个甚至更多,那么继续沿用现在的设计思路,构造函数的参数列表会变得很长,代码在可读性和易用性上都会变差。在使用构造函数的时候,我们就容易搞错各参数的顺序,传递进错误的参数值,导致非常隐蔽的bug。
这个时候可能有同学会说,我不用构造函数,自己用set()函数来给成员变量赋值,以替代冗长的构造函数。我写了一个示例代码,如下所示。没有了冗长的函数调用和参数列表,代码在可读性和易用性上提高了很多。
// ConnectionPool
ConnectionPool config = new ConnectionPool("ProgrammerAlan");
config.setIdleTimeout(1000);
至此,我们仍然没有用到建造者模式,通过构造函数设置必填项,通过set()方法设置可选配置项,就能实现我们的设计需求。
但如果我们把问题的难度再加大点,比如,还需要解决下面这三个问题,那现在的设计思路就不能满足了。
-
如果必填项通过set()方法设置,就无法保证它们已经被正确设置,因为其他对象方法可能在这些必填项被正确设置之前被调用。
-
如果配置项之间存在依赖关系或者约束条件,那么我们需要考虑如何处理这些逻辑。例如,如果用户设置了maxConnections、minConnections和connectionTimeout中的一个,就必须显式地设置另外两个;或者minConnections必须小于等于maxConnections。如果我们继续使用现有的设计思路,那么这些逻辑就无法在类中进行处理。
-
如果我们希望ConnectionPool类对象是不可变的,也就是说,对象在创建后不能再修改其内部属性的值,那么我们就不能暴露set()方法。
为了解决这些问题,建造者模式就派上用场了。
我们可以通过以下方式来解决配置项必填、约束和依赖关系校验的问题,同时保证对象不可变:
-
把ConnectionPool的构造函数权限改为private,这样只能通过Builder来创建ConnectionPool类对象。
-
在Builder类中设置必填项,以及通过set()方法设置其他配置项,但不直接创建ConnectionPool类对象。
-
在Builder类中增加校验逻辑,对所有必填项、约束和依赖关系进行集中校验。
-
只有在校验通过后,才在Builder类中调用ConnectionPool的私有构造函数创建对象,然后返回创建的ConnectionPool对象。
-
ConnectionPool类不提供任何set()方法,因此创建出来的对象是不可变的,不能修改其属性值。
这样,我们就能够保证ConnectionPool对象的正确性和不可变性,并且能够通过Builder类来解决配置项必填、约束和依赖关系校验的问题。
以下是一个简单的 ConnectionPool 类的代码实现,使用了建造者模式,确保对象的不可变性,并提供了校验逻辑:
public class ConnectionPool {
private final String url;
private final String username;
private final String password;
private final int maxTotal;
private final int maxIdle;
private final int minIdle;
private final List<Connection> connectionPool;
private ConnectionPool(Builder builder) {
this.url = builder.url;
this.username = builder.username;
this.password = builder.password;
this.maxTotal = builder.maxTotal;
this.maxIdle = builder.maxIdle;
this.minIdle = builder.minIdle;
this.connectionPool = new ArrayList<>(maxTotal);
for (int i = 0; i < minIdle; i++) {
connectionPool.add(createConnection());
}
}
public Connection getConnection() {
Connection connection = null;
synchronized (connectionPool) {
if (!connectionPool.isEmpty()) {
connection = connectionPool.remove(connectionPool.size() - 1);
}
}
if (connection == null) {
connection = createConnection();
}
return connection;
}
public void releaseConnection(Connection connection) {
if (connection != null) {
synchronized (connectionPool) {
if (connectionPool.size() < maxIdle) {
connectionPool.add(connection);
} else {
try {
connection.close();
} catch (SQLException e) {
// log error
}
}
}
}
}
private Connection createConnection() {
Connection connection = null;
try {
connection = DriverManager.getConnection(url, username, password);
} catch (SQLException e) {
// log error
}
return connection;
}
public static class Builder {
private final String url;
private final String username;
private final String password;
private static final int DEFAULT_MAX_TOTAL = 8;
private static final int DEFAULT_MAX_IDLE = 8;
private static final int DEFAULT_MIN_IDLE = 0;
private int maxTotal = DEFAULT_MAX_TOTAL;
private int maxIdle = DEFAULT_MAX_IDLE;
private int minIdle = DEFAULT_MIN_IDLE;
public Builder(String url, String username, String password) {
this.url = url;
this.username = username;
this.password = password;
return this;
}
public ConnectionPool build() {
if (maxIdle > maxTotal) {
throw new IllegalArgumentException("maxIdle cannot be greater than maxTotal");
}
if (minIdle > maxTotal || minIdle > maxIdle) {
throw new IllegalArgumentException("minIdle cannot be greater than maxTotal or maxIdle");
}
return new ConnectionPool(this);
}
public Builder setMaxTotal(int maxTotal) {
if (maxTotal <= 0) {
throw new IllegalArgumentException("maxTotal must be positive");
}
this.maxTotal = maxTotal;
return this;
}
public Builder setMaxIdle(int maxIdle) {
if (maxIdle < 0) {
throw new IllegalArgumentException("maxIdle cannot be negative");
}
this.maxIdle = maxIdle;
return this;
}
public Builder setMinIdle(int minIdle) {
if (minIdle < 0) {
throw new IllegalArgumentException("minIdle cannot be negative");
}
this.minIdle = minIdle;
return this;
}
}
}
使用方式示例:
// 创建ConnectionPool对象,设置连接池参数
ConnectionPool pool = new ConnectionPool.Builder()
.setName("myConnectionPool")
.setMaxTotal(10)
.setMaxIdle(5)
.setMinIdle(2)
.setUrl("jdbc:mysql://localhost:3306/mydatabase")
.setUsername("myuser")
.setPassword("mypassword")
.build();
// 从连接池中获取一个连接
Connection conn = pool.getConnection();
// 使用连接进行数据库操作
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM mytable");
// 关闭连接和连接池
rs.close();
stmt.close();
conn.close();
pool.close();
5.1.3.2 建造者模式总结
建造者模式的优点有:
-
将对象的构建过程与表示分离,可以更好地控制对象的构建流程。
-
建造者模式可以更好地处理对象构建过程中的变化,比如需要修改构建过程、添加新的构建方式等。
-
建造者模式可以帮助我们创建不可变对象,提高系统的安全性和稳定性。
-
可以使用链式调用的方式,更加直观和易于使用。
建造者模式的缺点有:
-
建造者模式会增加代码量,需要定义Builder类和Product类,从而增加了代码的复杂度。
-
建造者模式需要较为严格的类层次结构,对于需要构建的类需要进行比较详细的设计和规划。
-
对于一些简单对象,建造者模式可能会显得过于繁琐。
在实际应用中,建造者模式常常用于创建复杂的对象,比如一些框架或者API中的配置对象、请求对象等。建造者模式可以帮助我们更好地组织代码和控制流程,从而提高代码的可维护性和可读性。
5.2 结构型模式
结构型模式主要涉及如何组合各种对象以便获得更好、更灵活的结构。虽然面向对象的继承机制提供了最基本的子类扩展父类的功能,但结构型模式不仅仅简单地使用继承,而更多地通过组合与运行期的动态组合来实现更灵活的功能。
5.2.1 代理模式(Proxy Pattern)
给某一个对象提供一个代理,并由代理对象控制对原对象的引用。代理模式的英文叫做 Proxy 或 Surrogate,它是一种对象结构型模式。
代理模式有三个关键要素,它们分别是:
-
主题(Subject):定义“操作/活动/任务”的接口类。
-
真实主题(RealSubject):真正完成“操作/活动/任务”的具体类。
-
代理主题(ProxySubject):代替真实主题完成“操作/活动/任务”的代理类。
UML类图

img
5.2.1.1 浅析静态代理模式
静态代理在编译时就将接口、实现类、代理类这些都变成了一个个实际的 class 文件。也就是说我们对目标对象的每个方法的增强都是手动完成的,需要对每个目标类都单独写一个代理类,接口一旦新增加方法,目标对象和代理对象都要进行修改非常不灵活。
静态代理实现步骤:
-
定义一个接口及其实现类;
-
创建一个代理类同样实现这个接口
-
将目标对象注入进代理类,然后在代理类的对应方法调用目标类中的对应方法。这样的话,我们就可以通过代理类屏蔽对目标对象的访问,并且可以在目标方法执行前后做一些自己想做的事情。
代码示例:
// 定义接口
public interface HelloService {
void sayHello();
}
// 实现类
public class HelloServiceImpl implements HelloService {
public void sayHello() {
System.out.println("Hello World");
}
}
// 代理类
public class HelloServiceProxy implements HelloService {
private HelloService target;
public HelloServiceProxy(HelloService target) {
this.target = target;
}
@Override
public void sayHello() {
// 在目标方法执行前做一些自己想做的事情
System.out.println("Before sayHello");
// 调用目标对象的方法
target.sayHello();
// 在目标方法执行后做一些自己想做的事情
System.out.println("After sayHello");
}
}
// 客户端代码
public class Client {
public static void main(String[] args) {
// 创建目标对象
HelloService target = new HelloServiceImpl();
// 创建代理对象,并将目标对象传入代理对象的构造函数中
HelloService proxy = new HelloServiceProxy(target);
// 调用代理对象的方法
proxy.sayHello();
}
}
5.2.1.2 浅析动态代理模式
动态代理是在运行时动态生成类字节码,并加载到 JVM 中的。相比于静态代理来说,动态代理更加灵活,我们不需要针对每个目标类都单独创建一个代理类。
5.2.1.2.1 JDK动态代理
5.2.1.2.1.1 使用步骤
-
定义一个接口及其实现类;
-
自定义 InvocationHandler 并重写invoke方法,在 invoke 方法中我们会调用原生方法(被代理类的方法)并自定义一些处理逻辑;
-
通过 Proxy.newProxyInstance(ClassLoader loader,Class<?>[] interfaces,InvocationHandler h) 方法创建代理对象;
5.2.1.2.1.2 代码示例
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
// UserService 接口
interface UserService {
void addUser(String userId, String userName);
void deleteUser(String userId);
}
// UserService 接口的实现类
class UserServiceImpl implements UserService {
@Override
public void addUser(String userId, String userName) {
System.out.println("添加用户成功,用户ID为" + userId + ",用户名为" + userName);
}
@Override
public void deleteUser(String userId) {
System.out.println("删除用户成功,用户ID为" + userId);
}
}
// DebugInvocationHandler 类,实现 InvocationHandler 接口
class DebugInvocationHandler implements InvocationHandler {
private Object target; // 目标对象
// 构造方法,传入目标对象
public DebugInvocationHandler(Object target) {
this.target = target;
}
// 代理方法
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("调用方法:" + method.getName()); // 方法调用前的逻辑
Object result = method.invoke(target, args); // 调用目标方法
System.out.println("方法调用结束"); // 方法调用后的逻辑
return result; // 返回方法调用结果
}
}
//获取代理对象的工厂类
class JdkProxyFactory {
public static Object getProxy(Object target) {
return Proxy.newProxyInstance(
target.getClass().getClassLoader(), // 目标类的类加载
target.getClass().getInterfaces(), // 代理需要实现的接口,可指定多个
new DebugInvocationHandler(target) // 代理对象对应的自定义 InvocationHandler
);
}
}
// 主程序
public class DynamicProxyDemo {
public static void main(String[] args) {
UserService userService = (UserService)JdkProxyFactory.getProxy(new UserServiceImpl());
userService("001", "张三"); // 调用代理对象的方法
}
}
/**
代码执行后,在控制台输出如下内容:
调用方法:addUser
添加用户成功,用户ID为001,用户名为张三
方法调用结束
*/
5.2.1.2.2 CGLIB 动态代理
CGLIB是一个强大的高性能的动态代理框架,可以通过生成目标类的子类来实现代理,不需要目标类实现任何接口。它允许我们在运行时对字节码进行修改和动态生成。CGLIB 通过继承方式实现代理。
5.2.1.2.2.1 使用步骤
-
定义一个类;
-
自定义 MethodInterceptor 并重写 intercept 方法,intercept 用于拦截增强被代理类的方法,和 JDK 动态代理中的 invoke 方法类似;
-
通过 Enhancer 类的 create()创建代理类;
5.2.1.2.2.2 代码示例
<dependency>
<groupId>cglib</groupId>
<artifactId>cglib</artifactId>
<version>3.3.0</version>
</dependency>
public class UserService {
public void addUser(String userId, String userName) {
System.out.println("添加用户成功,用户ID为" + userId + ",用户名为" + userName);
}
}
/**
* 自定义MethodInterceptor
*/
public class DebugMethodInterceptor implements MethodInterceptor {
/**
* @param o 被代理的对象(需要增强的对象)
* @param method 被拦截的方法(需要增强的方法)
* @param args 方法入参
* @param methodProxy 用于调用原始方法
*/
@Override
public Object intercept(Object o, Method method, Object[] args, MethodProxy methodProxy) throws Throwable {
//调用方法之前,我们可以添加自己的操作
System.out.println("before method " + method.getName());
Object object = methodProxy.invokeSuper(o, args);
//调用方法之后,我们同样可以添加自己的操作
System.out.println("after method " + method.getName());
return object;
}
}
//获取动态代理
public class CglibProxyFactory {
public static Object getProxy(Class<?> clazz) {
// 创建动态代理增强类
Enhancer enhancer = new Enhancer();
// 设置类加载器
enhancer.setClassLoader(clazz.getClassLoader());
// 设置被代理类
enhancer.setSuperclass(clazz);
// 设置方法拦截器
enhancer.setCallback(new DebugMethodInterceptor());
// 创建代理类
return enhancer.create();
}
}
//实际使用
UserService userService = (UserService) CglibProxyFactory.getProxy(UserService.class);
userService("001", "张三");
5.2.1.3 JDK 动态代理和 CGLIB 动态代理对比
-
JDK 动态代理只能代理实现了接口的类或者直接代理接口,而 CGLIB 可以代理未实现任何接口的类。 另外, CGLIB 动态代理是通过生成一个被代理类的子类来拦截被代理类的方法调用,因此不能代理声明为 final 类型的类和方法。
-
就二者的效率来说,大部分情况都是 JDK 动态代理更优秀,随着 JDK 版本的升级,这个优势更加明显。
5.2.1.4 代理模式的应用场景
-
业务系统的非功能性需求开发 :
代理模式可以将一些与业务无关的附加功能,如监控、统计、鉴权、限流、事务、幂等、日志等与业务功能解耦,放到代理类中统一处理,让程序员只需要关注业务方面的开发。在Java语言和Spring开发框架中,这部分工作可以在Spring AOP切面中完成。
-
代理模式在RPC中的应用:
RPC框架也可以看作一种代理模式,通过远程代理将网络通信、数据编解码等细节隐藏起来,让客户端在使用RPC服务的时候,无需了解跟服务器交互的细节。除此之外,RPC服务的开发者也只需要开发业务逻辑,不需要关注跟客户端的交互细节。
-
代理模式在缓存中的应用:
代理模式也可以应用在接口请求的缓存功能中,通过动态代理,在应用启动的时候从配置文件中加载需要支持缓存的接口,以及相应的缓存策略(比如过期时间)等。当请求到来的时候,在AOP切面中拦截请求,如果请求中带有支持缓存的字段,便从缓存(内存缓存或者Redis缓存等)中获取数据直接返回。这样可以减少接口数量,方便缓存接口的集中管理和配置。
5.2.2 适配器模式
将一个类的接口变成客户端所期望的另一种接口,从而使原本因接口不匹配而无法一起工作的两个类能够在一起工作。
适配器模式中主要三个角色,在设计适配器模式时要找到并区分这些角色:
-
目标(Target): 即你期望的目标接口,要转换成的接口。
-
源对象(Adaptee): 即要被转换的角色,要把谁转换成目标角色。
-
适配器(Adapter): 适配器模式的核心角色,负责把源对象转换和包装成目标对象。
UML类图
适配器模式的类图如下:
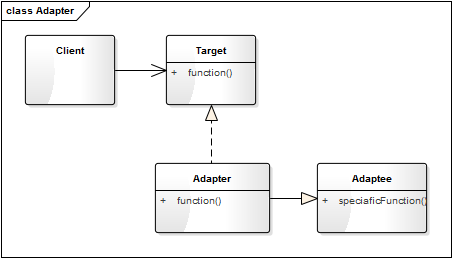
img
Target 是一个接口类,是提供给用户调用的接口抽象。
Adaptee 是你要进行适配的对象类.
Adapter 是一个适配器,是对 Adaptee 的适配,它将 Adaptee 的对象转换(或说包装)成符合 Target 接口的对象.
5.2.2.1 类适配器
类适配器使用继承来实现接口转换。适配器继承自已有的类,并实现新的接口。通过这种方式,适配器可以重用已有类的代码,并且可以在不修改已有类的情况下,增加新的功能。
代码示例:
// 类适配器: 基于继承
public interface ITarget {
void f1();
void f2();
void fc();
}
public class Adaptee {
public void fa() { //... }
public void fb() { //... }
public void fc() { //... }
}
public class Adaptor extends Adaptee implements ITarget {
public void f1() {
super.fa();
}
public void f2() {
//...重新实现f2()...
}
// 这里fc()不需要实现,直接继承自Adaptee,这是跟对象适配器最大的不同点
}
5.2.2.2 对象适配器
对象适配器使用组合来实现接口转换。适配器包含一个已有类的对象,并实现新的接口。通过这种方式,适配器可以重用已有类的代码,并且可以在不修改已有类的情况下,增加新的功能。
// 对象适配器:基于组合
public interface ITarget {
void f1();
void f2();
void fc();
}
public class Adaptee {
public void fa() { //... }
public void fb() { //... }
public void fc() { //... }
}
public class Adaptor implements ITarget {
private Adaptee adaptee;
public Adaptor(Adaptee adaptee) {
this.adaptee = adaptee;
}
public void f1() {
adaptee.fa(); //委托给Adaptee
}
public void f2() {
//...重新实现f2()...
}
public void fc() {
adaptee.fc();
}
}
5.2.2.3 实际场景选哪一种
-
如果Adaptee接口并不多,那两种实现方式都可以。
-
如果Adaptee接口很多,而且Adaptee和ITarget接口定义大部分都相同,那我们推荐使用类适配器,因为Adaptor复用父类Adaptee的接口,比起对象适配器的实现方式,Adaptor的代码量要少一些。
-
如果Adaptee接口很多,而且Adaptee和ITarget接口定义大部分都不相同,那我们推荐使用对象适配器,因为组合结构相对于继承更加灵活。
5.2.3 适用场景
5.2.3.1 统一多个类的接口设计
某个功能的实现依赖多个外部系统(或者说类)。通过适配器模式,将它们的接口适配为统一的接口定义,然后我们就可以使用多态的特性来复用代码逻辑。具体我还是举个例子来解释一下。
使用适配器前
// 定义 A 敏感词过滤系统提供的接口
public class ASensitiveWordsFilter {
// 过滤文本中的色情词汇
public String filterSexyWords(String text) {
// ...
}
// 过滤文本中的政治敏感词汇
public String filterPoliticalWords(String text) {
// ...
}
}
// 定义 B 敏感词过滤系统提供的接口
public class BSensitiveWordsFilter {
// 过滤文本中的敏感词汇
public String filter(String text) {
// ...
}
}
// 定义 C 敏感词过滤系统提供的接口
public class CSensitiveWordsFilter {
// 过滤文本中的敏感词汇,并用指定的掩码替换
public String filter(String text, String mask) {
// ...
}
}
// 未使用适配器模式的代码:不方便扩展和维护
public class RiskManagement {
// 依赖 A、B、C 三个敏感词过滤系统的具体实现
private ASensitiveWordsFilter aFilter = new ASensitiveWordsFilter();
private BSensitiveWordsFilter bFilter = new BSensitiveWordsFilter();
private CSensitiveWordsFilter cFilter = new CSensitiveWordsFilter();
// 过滤文本中的敏感词汇
public String filterSensitiveWords(String text) {
// 首先使用 A 敏感词过滤系统过滤文本中的色情词汇和政治敏感词汇
String maskedText = aFilter.filterSexyWords(text);
maskedText = aFilter.filterPoliticalWords(maskedText);
// 然后使用 B 敏感词过滤系统过滤文本中的敏感词汇
maskedText = bFilter.filter(maskedText);
// 最后使用 C 敏感词过滤系统过滤文本中的敏感词汇,并用指定的掩码替换
maskedText = cFilter.filter(maskedText, "***");
return maskedText;
}
}
使用适配器后
// 使用适配器模式进行改造后的代码:方便扩展和维护,符合开闭原则
// 定义敏感词过滤器接口
public interface ISensitiveWordsFilter {
// 过滤文本中的敏感词汇
String filter(String text);
}
// 将 A 敏感词过滤系统适配到 ISensitiveWordsFilter 接口上
public class ASensitiveWordsFilterAdaptor implements ISensitiveWordsFilter {
// 持有 A 敏感词过滤系统的实例
private ASensitiveWordsFilter aFilter;
// 实现 ISensitiveWordsFilter 接口中的 filter 方法
@Override
public String filter(String text) {
// 调用 A 敏感词过滤系统提供的方法进行过滤
String maskedText = aFilter.filterSexyWords(text);
maskedText = aFilter.filterPoliticalWords(maskedText);
return maskedText;
}
}
// 将 B 敏感词过滤系统适配到 ISensitiveWordsFilter 接口上
public class BSensitiveWordsFilterAdaptor implements ISensitiveWordsFilter {
// 持有 B 敏感词过滤系统的实例
private BSensitiveWordsFilter bFilter;
// 实现 ISensitiveWordsFilter 接口中的 filter 方法
@Override
public String filter(String text) {
// 调用 B 敏感词过滤系统提供的方法进行过滤
String maskedText = bFilter.filter(text);
return maskedText;
}
}
// 将 C 敏感词过滤系统适配到 ISensitiveWordsFilter 接口上
public class CSensitiveWordsFilterAdaptor implements ISensitiveWordsFilter {
// 持有 C 敏感词过滤系统的实例
private CSensitiveWordsFilter cFilter;
// 实现 ISensitiveWordsFilter 接口中的 filter 方法
@Override
public String filter(String text) {
// 调用 C 敏感词过滤系统提供的方法进行过滤
String maskedText = cFilter.filter(text, "***");
return maskedText;
}
}
// RiskManagement 类使用适配器模式中的 ISensitiveWordsFilter 接口进行过滤
public class RiskManagement {
// 维护 ISensitiveWordsFilter 接口的实现列表
private List<ISensitiveWordsFilter> filters = new ArrayList<>();
// 添加 ISensitiveWordsFilter 接口的实现
public void addSensitiveWordsFilter(ISensitiveWordsFilter filter) {
filters.add(filter);
}
// 使用 ISensitiveWordsFilter 接口的实现列表对文本进行过滤
public String filterSensitiveWords(String text) {
String maskedText = text;
for (ISensitiveWordsFilter filter : filters) {
maskedText = filter.filter(maskedText);
}
return maskedText;
}
}
5.2.3.2 替换依赖的外部系统
当我们把项目中依赖的一个外部系统替换为另一个外部系统的时候,利用适配器模式,可以减少对代码的改动。具体的代码示例如下所示:
// 外部系统A
public interface IA {
//...
void fa();
}
public class A implements IA {
//...
public void fa() { //... }
}
// 在我们的项目中,外部系统A的使用示例
public class Demo {
private IA a;
public Demo(IA a) {
this.a = a;
}
//...
}
Demo d = new Demo(new A());
// 将外部系统A替换成外部系统B
public class BAdaptor implemnts IA {
private B b;
public BAdaptor(B b) {
this.b= b;
}
public void fa() {
//...
b.fb();
}
}
// 借助BAdaptor,Demo的代码中,调用IA接口的地方都无需改动,
// 只需要将BAdaptor如下注入到Demo即可。
Demo d = new Demo(new BAdaptor(new B()));
5.3 行为型模式
行为型模式是一种设计模式,用于处理对象之间的通信和协作。这些模式涉及到对象之间的交互和职责分配,以实现某种行为。这些模式可以帮助程序员减少代码重复,提高代码的可重用性和可维护性。
5.3.1 观察者模式
观察者模式(Observer Design Pattern)也被称为发布订阅模式(Publish-Subscribe Design Pattern)。
在对象之间定义一个一对多的依赖,当一个对象状态改变的时候,所有依赖的对象都会自动收到通知。
5.3.1.1 使用观察者模式
观察者模式是一个比较抽象的模式,根据不同的应用场景和需求,有完全不同的实现方式.
下面举一个比较经典的例子:
public interface Subject {
// 注册观察者
void registerObserver(Observer observer);
// 移除观察者
void removeObserver(Observer observer);
// 通知观察者
void notifyObservers(Message message);
}
public interface Observer {
// 更新消息
void update(Message message);
}
public class ConcreteSubject implements Subject {
private List<Observer> observers = new ArrayList<Observer>();
@Override
public void registerObserver(Observer observer) {
observers.add(observer);
}
@Override
public void removeObserver(Observer observer) {
observers.remove(observer);
}
@Override
public void notifyObservers(Message message) {
for (Observer observer : observers) {
observer.update(message);
}
}
}
public class ConcreteObserverOne implements Observer {
@Override
public void update(Message message) {
//TODO: 获取消息通知,执行自己的逻辑...
System.out.println("ConcreteObserverOne is notified.");
}
}
public class ConcreteObserverTwo implements Observer {
@Override
public void update(Message message) {
//TODO: 获取消息通知,执行自己的逻辑...
System.out.println("ConcreteObserverTwo is notified.");
}
}
public class Demo {
public static void main(String[] args) {
ConcreteSubject subject = new ConcreteSubject();
subject.registerObserver(new ConcreteObserverOne());
subject.registerObserver(new ConcreteObserverTwo());
subject.notifyObservers(new Message());
}
}
该代码实现了观察者模式(Observer Pattern),其中:
-
Subject 接口定义了注册、移除和通知观察者的方法;
-
Observer 接口定义了更新消息的方法;
-
ConcreteSubject 类实现了 Subject 接口,并维护了一个观察者列表,可以将观察者注册、移除和通知;
-
ConcreteObserverOne 和 ConcreteObserverTwo 类实现了 Observer 接口,定义了具体的更新消息的逻辑;
-
Demo 类演示了如何使用观察者模式,首先创建一个具体的主题(ConcreteSubject)对象,然后向其中注册两个观察者(ConcreteObserverOne 和 ConcreteObserverTwo),最后通过 notifyObservers 方法通知观察者更新消息。
观察者模式可以用来解决对象之间的多对一依赖关系,当一个对象发生改变时,所有依赖于它的对象都会收到通知并自动更新。
5.3.2 模板模式
模板模式(Template Pattern),定义一个操作中算法的骨架,而将一些步骤延迟到子类中,模板方法使得子类可以不改变算法的结构,只是重定义该算法的某些特定步骤。这种类型的设计模式属于行为型模式。
5.3.2.1 使用模板模式
public abstract class GuessingGame {
// 这是一个模板方法,它定义了这个猜数字游戏的整个流程。
public final void play() {
// 1. 首先,我们要求用户输入一个数字。
int number = getNumber();
// 2. 接下来,我们将调用checkNumber()方法来检查用户是否猜对了数字。
while (!checkNumber(number)) {
// 3. 如果用户没有猜对数字,我们会告诉他们他们需要猜一个更高或更低的数字。
if (number < getAnswer()) {
System.out.println("请猜一个更高的数字。");
} else {
System.out.println("请猜一个更低的数字。");
}
// 4. 然后,我们要求用户再次输入一个数字。
number = getNumber();
}
// 5. 最后,我们告诉用户他们猜对了数字。
System.out.println("恭喜你猜对了!");
}
// 这是一个抽象方法,由子类实现,用于获取用户输入的数字。
protected abstract int getNumber();
// 这也是一个抽象方法,由子类实现,用于检查用户是否猜对了数字。
protected abstract boolean checkNumber(int number);
// 这是一个抽象方法,由子类实现,用于获取正确的答案。
protected abstract int getAnswer();
}
public class NumberGame extends GuessingGame {
// 这是一个私有变量,它存储了正确的答案。
private int answer;
// 这是NumberGame类的构造函数,它用于生成一个随机数字作为答案。
public NumberGame() {
answer = (int) (Math.random() * 100);
}
// 这是getNumber()方法的实现,它要求用户输入一个数字,并将其返回。
@Override
protected int getNumber() {
System.out.println("请猜一个数字:");
Scanner scanner = new Scanner(System.in);
return scanner.nextInt();
}
// 这是checkNumber()方法的实现,它检查用户猜测的数字是否等于正确的答案。
@Override
protected boolean checkNumber(int number) {
return number == answer;
}
// 这是getAnswer()方法的实现,它返回正确的答案。
@Override
protected int getAnswer() {
return answer;
}
}
public class Main {
public static void main(String[] args) {
// 创建一个NumberGame对象并调用它的play()方法。
NumberGame game = new NumberGame();
game.play();
}
}
GuessingGame是抽象类,NumberGame是它的一个子类,实现了父类中定义的三个抽象方法。在main()方法中,我们创建一个NumberGame对象并调用它的play()方法来启动游戏。这个设计模式的关键在于将公共的游戏流程定义在父类中,并将具体的实现留给子类完成,这样可以减少代码的重复,提高代码的可维护性和可扩展性。
5.3.3 策略模式
定义一族算法类,将每个算法分别封装起来,让它们可以互相替换。策略模式可以使算法的变化独立于使用它们的客户端(这里的客户端代指使用算法的代码)。
策略模式中主要三个角色,在设计策略模式时要找到并区分这些角色:
-
上下文环境(Context): 起着承上启下的封装作用,屏蔽上层应用对策略(算法)的直接访问,封装可能存在的变化。
-
策略的抽象(Strategy): 策略(算法)的抽象类,定义统一的接口,规定每一个子类必须实现的方法。
-
具体的策略: 策略的具体实现者,可以有多个不同的(算法或规则)实现
5.3.3.1 策略模式的使用
/**
* 策略的抽象
*/
public interface Strategy {
void algorithmInterface();
}
/**
* 具体的策略A
*/
public class ConcreteStrategyA implements Strategy {
@Override
public void algorithmInterface() {
//具体的算法...
}
}
/**
* 具体的策略B
*/
public class ConcreteStrategyB implements Strategy {
@Override
public void algorithmInterface() {
//具体的算法...
}
}
/**
* 上下文环境
*/
public class Context {
private Strategy strategy;
public Context(Strategy strategy) {
this.strategy = strategy;
}
public void setStrategy(Strategy strategy) {
this.strategy = strategy;
}
public void executeAlgorithm() {
strategy.algorithmInterface();
}
}
/**
* 策略的创建
*/
public class StrategyFactory {
public static Strategy createStrategy(String type) {
if (type.equals("A")) {
return new ConcreteStrategyA();
} else if (type.equals("B")) {
return new ConcreteStrategyB();
} else {
return null;
}
}
}
/**
* 策略的使用,运行时动态
*/
public class Main {
public static void main(String[] args) {
Context context = new Context(StrategyFactory.createStrategy("A"));
context.executeAlgorithm();
context.setStrategy(StrategyFactory.createStrategy("B"));
context.executeAlgorithm();
}
}
这是一个策略模式的实现,其中:
-
Strategy 接口定义了策略的抽象行为。
-
ConcreteStrategyA 和 ConcreteStrategyB 类分别实现了不同的具体策略。
-
Context 类包含了一个 Strategy 成员变量,它的 executeAlgorithm 方法将调用当前策略的 algorithmInterface 方法。
-
StrategyFactory 类包含了一个静态方法 createStrategy,用于根据传入的类型创建对应的具体策略对象。
-
Main 类演示了如何使用策略模式,它首先创建了一个使用 ConcreteStrategyA 策略的 Context 对象,并执行它的算法。然后,它将 Context 的策略更改为 ConcreteStrategyB,再次执行算法。
上面的代码还可以进行优化,因为这里每个策略都是无状态的,我们没必要在每次使用的时候,都重新创建一个新的对象。所以,我们可以使用工厂模式对对象的创建进行封装。按照这个思路,我们对代码进行重构。
/**
* 策略的抽象
*/
public interface Strategy {
void algorithmInterface();
}
/**
* 具体的策略A
*/
public class ConcreteStrategyA implements Strategy {
@Override
public void algorithmInterface() {
//具体的算法...
}
}
/**
* 具体的策略B
*/
public class ConcreteStrategyB implements Strategy {
@Override
public void algorithmInterface() {
//具体的算法...
}
}
/**
* 上下文环境
*/
public class Context {
private Strategy strategy;
public Context(Strategy strategy) {
this.strategy = strategy;
}
public void setStrategy(Strategy strategy) {
this.strategy = strategy;
}
public void executeAlgorithm() {
strategy.algorithmInterface();
}
}
/**
* 策略工厂
*/
public class StrategyFactory {
private static final Map<String, Strategy> strategies = new HashMap<>();
static {
strategies.put("A", new ConcreteStrategyA());
strategies.put("B", new ConcreteStrategyB());
}
public static Strategy getStrategy(String type) {
return strategies.get(type);
}
}
/**
* 策略的使用,运行时动态
*/
public class Main {
public static void main(String[] args) {
Context context = new Context(StrategyFactory.getStrategy("A"));
context.executeAlgorithm();
context.setStrategy(StrategyFactory.getStrategy("B"));
context.executeAlgorithm();
}
}
现在我们将具体策略的创建封装在了 StrategyFactory 类中,它使用一个静态 Map 来存储具体策略对象。在需要创建具体策略对象时,我们只需调用 getStrategy 方法并传入对应的类型即可。
在 Main 类中,我们使用 StrategyFactory.getStrategy 方法来获取具体策略对象。我们首先创建一个使用 ConcreteStrategyA 策略的 Context 对象,并执行它的算法。然后,我们将 Context 的策略更改为 ConcreteStrategyB,再次执行算法。
这种重构的好处是,在需要使用不同的具体策略时,我们可以直接调用工厂类的方法获取对象,而不必知道具体策略的实现。此外,由于具体策略对象是在工厂类初始化时创建的,所以我们可以避免在每次使用时都创建新的对象,从而提高了程序的性能。
5.3.4 职责链模式
将请求的发送和接收解耦,让多个接收对象都有机会处理这个请求。将这些接收对象串成一条链,并沿着这条链传递这个请求,直到链上的某个接收对象能够处理它为止。
5.3.4.1 职责链模式使用
public abstract class Handler {
// 后继者处理者
protected Handler successor = null;
public void setSuccessor(Handler successor) {
this.successor = successor;
}
// 处理方法,定义了处理的步骤和流程
public void handle() {
boolean handled = doHandle();
if (!handled && successor != null) {
successor.handle();
}
}
// 抽象方法,由具体子类实现
protected abstract boolean doHandle();
}
public class HandlerA extends Handler {
@Override
protected boolean doHandle() {
//... 进行处理逻辑
return false; // 如果无法处理,返回false
}
}
public class HandlerB extends Handler {
@Override
protected boolean doHandle() {
//... 进行处理逻辑
return false; // 如果无法处理,返回false
}
}
public class HandlerChain {
// 链表头部和尾部
private Handler head = null;
private Handler tail = null;
// 添加处理者
public void addHandler(Handler handler) {
handler.setSuccessor(null);
if (head == null) {
// 如果链表为空,设置头部和尾部为新增处理者
head = handler;
tail = handler;
return;
}
// 将新增处理者接在链表尾部
tail.setSuccessor(handler);
tail = handler;
}
// 处理请求
public void handle() {
if (head != null) {
head.handle();
}
}
}
// 使用举例
public class Application {
public static void main(String[] args) {
HandlerChain chain = new HandlerChain();
chain.addHandler(new HandlerA());
chain.addHandler(new HandlerB());
chain.handle();
}
}
6 结语
相对于MySQL优化、高并发等知识来说,设计模式更为抽象不易掌握。
但它能提高我们对复杂代码的设计和开发能力,帮助我们写出更优雅、易于维护的代码。
同时,也可以帮助我们在阅读优秀框架源码时,更好地参透作者的设计思路、设计初衷。
因此,我认为是值得花时间和心思去学习实践的,尽管要花费很多精力并且短期内得不到很大的收益。
7 作者简介
鑫茂,深圳,Java开发工程师。
希望通过文章,结识更多同道中人。
公众号:ProgrammerAlan















 2317
2317











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









