







对于gan网络的定义有很多参考文章,此处不再过多赘述,本文仅博主学习时对自己的知识体系补充,有一定的参考性。
- gan的优点:
- 相比于变分自动编码器(vae),gan没有引入任何决定性偏置,变分方法引入决定性偏置,因为他们优化对数似然的下界,而不是似然度本身,导致了vae生成的实例比gan更模糊
- 相比vae,gan没有变分下界,如果判别器训练的好,则生成器可以完美地学习到训练样本的分布。即gan是渐进一致的,但vae是有偏差的。
- gan应用到一些场景上,比如图片风格迁移,超分辨率,图像补全,去躁,避免了损失函数的困难,只要一个基准,就可以使用判别器,然后就可以交给对抗训练了
- gan的缺点:
- 训练gan需要到达纳什均衡,有时可以使用梯度下降法做到,有时不行,目前还未找到很好的可以达到纳什均衡的方法,所以训练gan相比vae是不稳定的。
- gan存在训练不稳定、梯度消失、模式崩溃的问题
- 模式崩溃的原因:一般出现在gan训练不稳定的时候,具体表现为生成出来的结果非常差,且加长训练时间也无法得到很好的改善。
- 具体原因:如果某一次g生成的样本不是很真实,,但d给出的评判概率很高,或g生成结果中的一些特征得到了d的认可,则g就会根据这个依据继续生成,然后g和d就一起自我欺骗下去。
- 模式崩溃的原因:一般出现在gan训练不稳定的时候,具体表现为生成出来的结果非常差,且加长训练时间也无法得到很好的改善。
- gan不选择sgd作为优化器的原因:
-
sgd容易振荡,易使gan训练不稳定
-
gan的目的是在高维非凸空间中找到纳什均衡点,gan的纳什均衡点是一个鞍点,但sgd只能找到局部极小值,因为sgd解决的是一个寻找最小值到的问题,gan是一个博弈问题。
-
-
训练gan的一些技巧:
-
输入规范化到(-1,1)之间,最后一层的激活函数使用tanh(双曲正切)(BEGAN除外)
-
如果有标签数据的话,尽量使用标签,也有人提出使用反转标签效果很好,另外使用标签平滑,单边标签平滑或者双边标签平滑
-
使用mini-batch norm, 如果不用batch norm 可以使用instance norm 或者weight norm
-
避免使用RELU和pooling层,减少稀疏梯度的可能性,可以使用leakrelu激活函数
-
优化器尽量选择ADAM,学习率不要设置太大,初始1e-4可以参考,另外可以随着训练进行不断缩小学习率,
-
给D的网络层增加高斯噪声,相当于是一种正则
-
不要early stopping:
-
一个常见的错误:当发现损失值不变时,或者生成的图像一直模糊时,通常会终止训练,调整模型。但GAN的训练通常非常耗时,有时多等一等会有意想不到的“收获”。
-
但当判别器的损失值快速接近0时,通常生成器很难学到任何东西了,就需要及时终止训练,修改网络、重新训练。
-
-
- gan的广泛应用:分类领域:将判别器替换为一个分类器,做多分类任务,生成器仍然做生成任务,辅助分类器训练。
- 补充知识:
- sgd算法(随机梯度下降算法):
- 从样本中随机抽取一组,训练后按梯度更新一次,然后再抽取一组,再更新,在样本量很大时,不用训练完所有样本就可以获得一个损失值在可接受范围之内的模型。
- “随机”是指每次迭代过程中,样本都会被随机打乱,可以有效减小样本之间造成的参数更新抵消问题
- 其步长选择比梯度下降法的步长小一点,因为梯度下降法使用的是准确梯度,其可以朝着全局最优解(当问题是凸问题时)进行较大幅度地迭代,但sgd不可,因为其使用的近似梯度,或对于全局来说其走的根本不是梯度下降的方向,并且步长小一些相比梯度下降法,也不容易陷入到局部最优解中。
- 分类:
- SGD:每次更新参数只使用一个样本,更新较慢
- Batch-SGD:每次更新使用所有样本,取参数更新均值,对参数进行一次性更新,更新较为粗糙
- Mini-Batch-SGD:每次参数更新使用一小批样本,样本的数量通常采用trial-and-error来确定,有效加快训练速度。
- 缺点:
- 准确度下降,因为即使目标函数为强凸函数,sgd也无法做到线性收敛
- 可能会收敛到局部最优,因为单样本不能代表全体样本的趋势
- 不利于并行实现。
- 鞍点的通俗理解:
- 想象马鞍,沿着马脊方向是稳定的(马脊上最低点,相当于极小值),但是左右偏差就容易掉下去,因此左右不是稳定的.马背上的最低点就是鞍点.
- 在微分方程中,沿着某一方向是稳定的,另一条方向是不稳定的奇点,叫做鞍点.
- 在泛函中,既不是极大值点也不是极小值点的临界点,叫做鞍点.
- 反转标签:设置Generated=True, Real=False,在训练样本的标签上加入随机噪声,也能提升模型效果。对于进入判别器中5%的数据,随机地翻转其标签,即真实数据标记成假的,生成的数据标记为真的。
- 标签平滑:训练判别器时,0或者1的标签,称为hard label,这种标签可能会使得判别器的损失值迅速跌落至0。所以使用soft label,对于标签为0的样本,其标签设置为(0,0.1)内的随机数;对于标签为1的样本,其标签设置为(0.9,1)内的随机数。这个操作在训练生成器的时候不需要做。
- mini-batch norm:
- 进行使数据分布的均值为0、方差为1的正规化
- 如图:
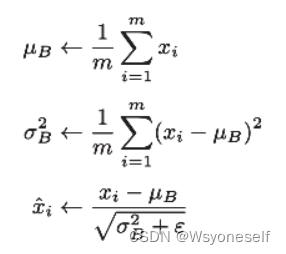
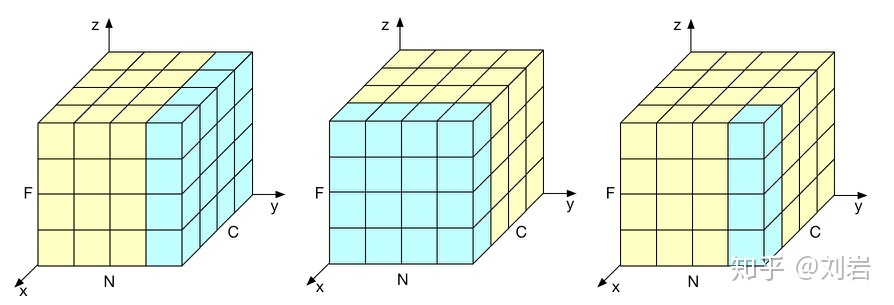
- instance norm:参考:模型优化之Instance Normalization - 知乎 (zhihu.com)
- BN计算归一化统计量时考虑了一个批量中所有数据,从而造成了每个样本独特细节的丢失。
- LN这类需要考虑一个样本所有通道的算法来说可能忽略了不同通道的差异
- IN:计算归一化统计量时考虑单个样本,单个通道的所有元素。
- 三者对比如图:IN(右)和BN(中)以及LN(左)
- weight norm:WN的重参数表示:对权重w \bm{w}w用参数向量v和标量g进行表示,则新参数表示为:
 其中v是k维向量,g是标量,∥ v ∥为v 欧式范数。w 则被重参数为v 和g两个参数。通过上述重参数表示,我们可以发现∥w∥=g,与参数v独立,而权重w 的方向也变更为v /∥ v ∥。重参数将权重向量w 用了两个独立的参数表示其幅度和方向。在利用SGD优化算法时,重参数可以加速网络的收敛速度。
其中v是k维向量,g是标量,∥ v ∥为v 欧式范数。w 则被重参数为v 和g两个参数。通过上述重参数表示,我们可以发现∥w∥=g,与参数v独立,而权重w 的方向也变更为v /∥ v ∥。重参数将权重向量w 用了两个独立的参数表示其幅度和方向。在利用SGD优化算法时,重参数可以加速网络的收敛速度。 - leakrelu激活函数:
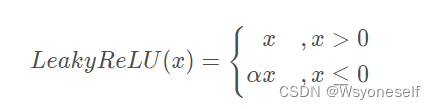
- sgd算法(随机梯度下降算法):


















 2647
2647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









