







- 根据说话人(麦克风)的数目,通常将语音分离任务分为单通道(Singlechannel)语音分离和麦克风阵列(Multi-channel)的语音分离。
- 对于时频域的语音分离需要将时域的语音信号进行短时傅里叶变换(STFT),将时域信号转换为时频域信号。需要进行 STFT的原因:
- 对于时频域的信号特征更容易提取,更容易去做一些语音特征提取的操作,例如 MFCC等。
- 对于经过 STFT 的时频域信号很容易的通过逆傅里叶变换(iSTFT)恢复为时域信号。
- 频域本质是把信号分解到每个子带空间上,每个空间里面性质稳定,你可以理解为频率恒定。
- 因此,一开始大家在做语音分离任务是都是在时频域上进行的。而对于时域的语音分离只需要做的就是搭建一个 encoder-decoder 的端到端的模型即可。
- 说话者无关即模型可以应用都所有说话人的语音分离
- 对于语音分离任务,数据集一般使用的是华尔街日报数据集(Wall Street Journal dataset, WSJ0)。
- 目前对于数据集的混合以及划分数据集的方法均采用 Deep Clustering 的 matlab 脚本混合(https://www.merl.com/demos/deepclustering/create-speaker-mixtures.zip)。
- 该数据集分为三个文件夹,si_tr_s,si_dt_05 和 si_et_05。
- 训练数据集使用 si_tr_s 中获取
- 验证集和测试集均在 si_dt_05 和 si_et_05 中获取。
- 在 Deep Clustering 方法之后所有的语音分离任务都是在开放演讲者集合(open speaker set)中训练,因此不会训练验证集和测试集的数据。
- 纯语音分离任务的相关工作 :
- 深度聚类(更多可以看笔记(1))
- 帧级别和句子级别的标签不变训练(PIT&uPIT)
- 估计单一声音的频谱图,是通过 mask 点乘混合频谱
图:使用深度学习模型估计一组掩码(mask),使用 softmax 操作可以轻松满足此约束。 - 深度吸引子网络则是通过学习聚类中心来对不同的 speaker 生成不同的 mask。这样就可以得到一种可学习的聚类中心
- TasNet:
- 在时域上对音频进行分离,克服了短时傅里叶变换将时域信号转换为频域信号的精度问题。
- 使用编码器-解码器框架:
- 在时域中直接对信号建模,并对非负编码器输出执行语音分离。这种方法省去了频率分解步骤,并将分离问题减少到估计编码器输出上的语音掩模,然后由解码器对其进行合成。TasNet 优于当前最新的因果和非因果语音(因果分离就是不考虑信号的将来特征,例如 RNN,LSTM,GRU。而非因果分离则是考虑信号的将来特征,例如,BILSTM,BIGRU,TCN)分离算法,降低了语音分离的计算成本,并显着降低了输出所需的最小延迟。
- 省去了 time-domain 转frequency-domain 步骤,并将分离问题减少到 decoder 合成音频。该方法其实就是用卷积来替换 stft 方法,因为 stft 其实也是卷积操作。因果操作的性能不如非因果操作的的性能,这个是因为非因果操作可以考虑到将来的特征信息。
- 训练阶段的目标函数是使尺度不变的信噪比(SI-SNR)最大化,该信噪比通常被用作替代标准信噪比的信源分离评估指标。从这篇文章开始所有的时域方法的损失函数均为该评价指标。
- Conv-TasNet:与 TasNet 的区别就是将分离网络有循环神经网络(RNN,LSTM,GRU)变为时间卷积网络 TCN。这样可用通过 GPU 的并行加速大大缩减训练和测试时间。此外通过实验证明, Conv-TasNet 在因果实现和非因果实现中均大大提高了以前的 LSTM-TasNet 的分离精度。
- Dual-Path-RNN:
- 该方法在深层模型中优化 RNN 使其可以对极长的语音序列建模。DPRNN 将较长的音频输入分成较小的块,并迭代应用块内和块间操作,其中输入长度(chunk size)可以与每个操作中原始音频长度的平方根成比例。
- 该方法的双路径的 pipeline 是首先将语音切分,然后组合成 3D 的特征快,学习块内特征和块间特征来分离语音。块内 RNN 首先独立处理本地块(将长语音序列分为 chunk number),然后块间 RNN 聚合来自所有块的信息做 utterancelevel 的处理。
- 视听模型的语音分离任务:
- 由于其视觉信息的输入,将不会出现纯语音分离任务的的难题(标签置换问题:即分离之后给结果分配说话人身份标签混乱和困难的问题)。这是由于输入的视觉信息是存在标签的,与输出的标签数目是相同的。此外,视觉的特征信息用于将音频“聚焦”到场景中所需的说话者上,并改善语音分离质量。
- 输入:视频部分给定一个包含多个演讲者的视频片段,我们使用现成的面部检测器 mtcnn 在每个帧中查找面部 75 张。再使用 FaceNet 将人脸图像提取为一个 Face embedding。
- 使用 CNN 的方法得到的结果往往要比使用 RNN,LSTM,GRU 的方法要更精确,原因:
- CNN 方法首先可以大大的缩小训练和测试时间,可以更好的利用 GPU。
- 由于 TCN 方法和 ResNet 方法的发展,CNN 网络也可以朝向更深层次发展
- 通过 Dilated Conv 操作可以使 CNN 也能获得序列的上下文语义,使 CNN 模型更能适合 RNN 网络的操作。
- 因此 ConvTasNet 可以得到更好的结果。所以在设计 AV-model 的时候,语音部分参考了 Conv-Tasnet 的 Encoder 和 Separation 结构,而在视觉部分参考了端到端的 AudioVisual 语音识别的视觉信息部分。
- 语音分离流程图:
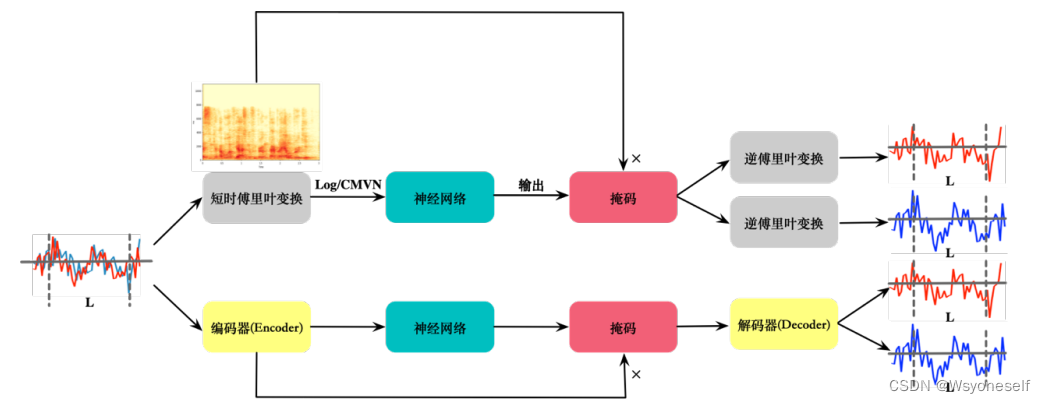
更多模型细节可参考:语音分离的总结 (cslikai.cn)
#--------------------3.31 补充----------------------------------------------------------------------------------------------
关于“create-speaker-mixtures怎么生成数据集”:
- 如果熟悉使用matlab的朋友,可以选择参考这个仓库(create_future/LSTM_PIT_Speech_Separation (gitee.com)),应该运行“ create-speaker-mixtures-V1”或“create-speaker-mixtures-V2”下的文件皆可(作者说两个版本没有差别),但由于我对matlab不熟悉,所以没有实践检验,但根据star数,应该可行
- 如果1不成立或者没成功,可以参考一个python脚本实现的仓库(语音分离speech separation数据准备,开源_speech seperation_RoadmanG的博客-CSDN博客,从这个博客进入仓库),亲测可用,立马上手的那种















 130
130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









