







Interspeech2021:语音前端
Target Speaker Separation
当前在做的方向:
时域/频域的pipeline
先验信息的利用
损失函数的设计
网络架构的训练
- Auxiliary loss function for target speech extraction and recognition
with weak supervision based on speaker characteristics
①使用新定义的损失函数对目标说话任提取的任务进行重新训练,将损失函数划分成两部分:
其一,是说话人一致性损失
其二,是混合语音一致性损失
②弱监督学习
- Universal Speaker Extraction in the Presence and Absence of Target Speakers for Speech of One and Two Talkers
①考虑到了在TSE工作中可能会存在目标说话人信息不存在的情况,将【至多两个人说话】的情景划分成四个子类:2T-PT,1T-PT,2T-AT,1T-AT;
②训练上沿用了SpEX+的结构
③重新定义了一个损失函数,对上述提到的四种情况都可以进行联合优化:
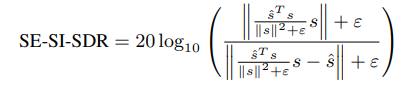
Source Separation,Dereverberation and Echo Cancellation
- Real-Time Speaker Counting in a Cocktail Party Scenario Using Attention-Guided Convolutional Neural Network
①背景:鸡尾酒会中的语音分离问题往往假设说话人数量已知,但这在很多现实场景中并不成立;
现有的说话人计数框架经历了——
通过判断调制频谱的特定模式;
无监督学习:使用聚类方法
监督学习方法:使用卷积层提取特征
但是上述方法存在一定时延,不能保证系统应用的实时性
②问题描述:
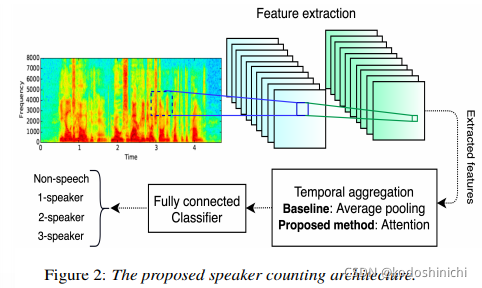
speaker-counting系统的架构通常为下述架构:
- 从语音中提取与说话人数量相关的高层次特征;
- 将frame-level的特征向量总结压缩成基于utterance的特征向量;
- 在特征空间中对说话人数目进行分类
③网络架构:
- 使用二维卷积提取高层次的特征
- 通过attention机制在temporal aggregation block中对特征向量按时间帧进行压缩
- 使用FC对压缩后的特征向量进行分类
④计算逻辑:

2.Should We Always Separate?: Switching Between Enhanced and Observed Signals for Overlapping Speech Recognition
①提出背景
语音增强在某些情况下会对语音造成诸如processing artifacts的副作用,对后端的ASR任务造成影响(有无语音段的overlap时均存在);
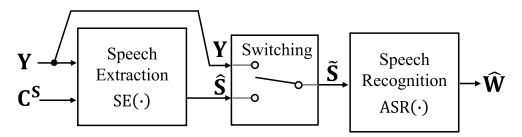
②基本思想
基于估计得到的SIR或SNR实现一个简单的切换算法,输出的有时是直接的obeserved speech,有时是enhanced speech。
③技术发展
前端的工作并不能完全帮助到后端语音任务提高性能,这一问题近年来一直受到重视:
- 对前端工作进行改善:其一是针对有overlapping的片段进行混合语音和增强后的语音的switch,本文是针对有无overlapping的片段均进行此操作;
- 对后端工作进行改善:其一是对后端的ASR等任务模型使用经过前端处理后的语料重新训练;其二是将前后端进行联合训练。
④机制模式
针对(混合语音,目标人特征向量)二元组对SIR和SNR进行估计,利用估计得到的SIR和SNR在本篇文章中设计了一个rule-based的switching机制,然后设定阈值,对mixture或者enhanced speech进行选择。

- Multi-Stream Gated and Pyramidal Temporal Convolutional Neural Networks for Audio-Visual Speech Separation in Multi-Talker Environments
①目的:在多说话人环境下的时域的audio-visual的语音分离模型;
②创新:
a.引入multi-stream gated TCN的audio-visual分离架构——便于更好地对特征表示进行建模、选择和整合。
b. 使用pyramidal convolution对TCN进行提升,不同的kernel_size便于提取multi-scale的特征表示。
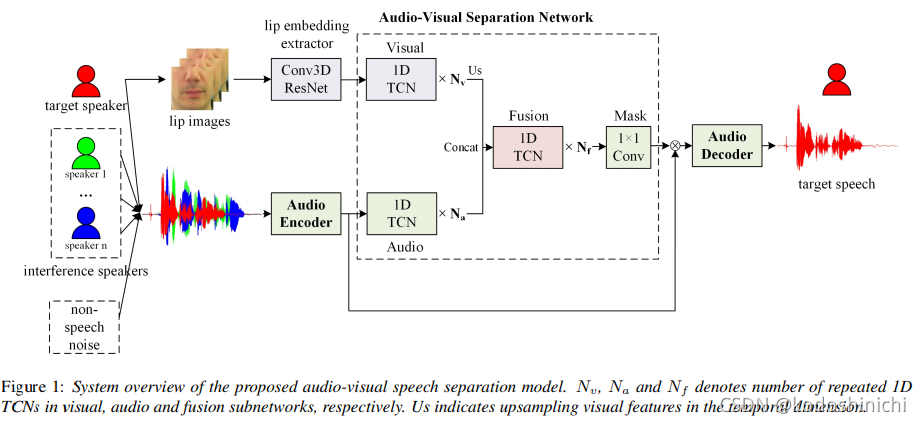
③架构
【visual representation】
face image pixels:很难学到audio-visual的相关性
face recognition embedding:更多关注的是面部的相似度,而不是audio-visual交互的本质
lip embedding:直接从lipreading task的任务中提取出来的
【audio encoder/decoder】
1D的卷积操作和解卷积操作
【audio-visual separation network】
其内部含有[visual subnetwork]、[audio subnetwork]、[fusion subnetwork]和[mask subnetwork]这些子网络,均由1D的TCN block组成的。
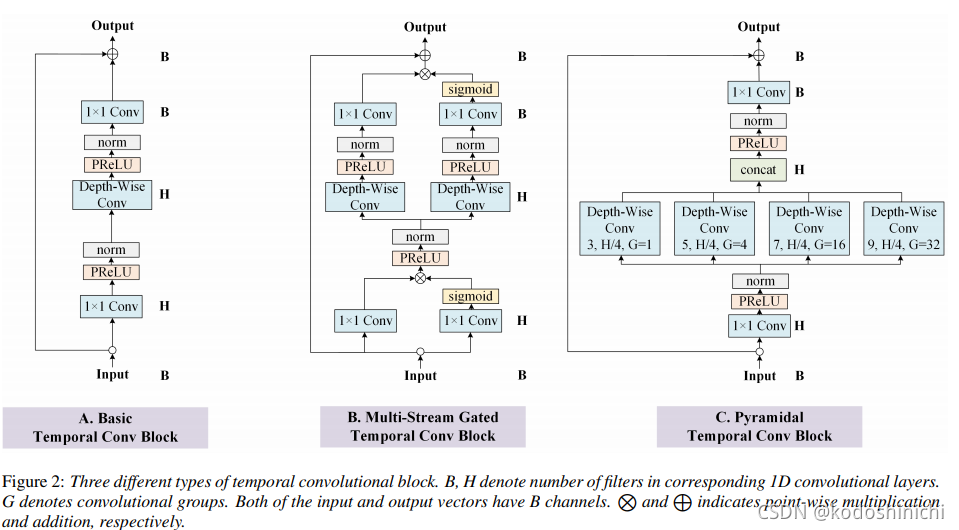
- TeCANet: Temporal-Contextual Attention Network for Environment-Aware Speech Dereverberation
①背景
语音去混响任务对上下文帧之间的相关性有更大的依赖:
在一个混响比较大的环境中,帧之间的关联会更紧密,这个时候需要一个较长的上下文用来捕捉足够的上下文信息;
在一个混响比较若的环境中,帧之间的关联不会很紧密,这个时候如果采用较长的上下文反而可能会引入多余的数据量。
②Idea
√ 采用基于注意力的方法,能够通过感知环境混响程度来适应性地调整上下文长度获得合适的上下文信息;
√ 获得注意力权重的方法:基于不同频带RIRs效应的影响,我们采用两类方法,其一是FTA(FullBand based Temporal Attention),另外一个是STA(SubBand based Temporal Attention)
- Personalized PercepNet:Real-Time,Low-Complexity Target Voice Separation and Enhancement
①目标与计划:目标说话人增强
√ 训练一个perceptually motivated embedding network对于给定的说话人产生特征表示
√ 提出的PercepNet使用目标说话人的embedding作为额外的信息来挑选出并增强特定说话人的语音信号,同时对其他说话人语音进行抑制。
②算法框架
特征空间:基于感知的波段的潜在表示
- 通过等效矩形带宽 (ERB) 标度进行空间映射,得到32个三角光谱带,;
- 每个频带都使用两维特征进行描述:频带幅度和pitch coherence
- 再加入4个通用的特征(其中包含基因周期)——故特征空间一共68维
感知驱动的基音滤波(pitch-filter)
- 目的是从谱包络中重建纯净语音中的谐波性质和分量;
- 使用基于基音频率的梳状滤波
- 比起STFT的操作会拥有更精细的频域分辨率
- 梳妆滤波的效果由每个频带的相关参数独立控制
RNN模型
- 用于估计每个频带(band)的比率掩码
- 这个mask被用于含噪信号,作为信号增益(gain),来拟合目标纯净语音的谱包络
- 除了增益外,我们的模型还输出每个频段的估计基因滤波器强度和帧级语音活动
检测器 (VAD) 输出。
③模型与数据流
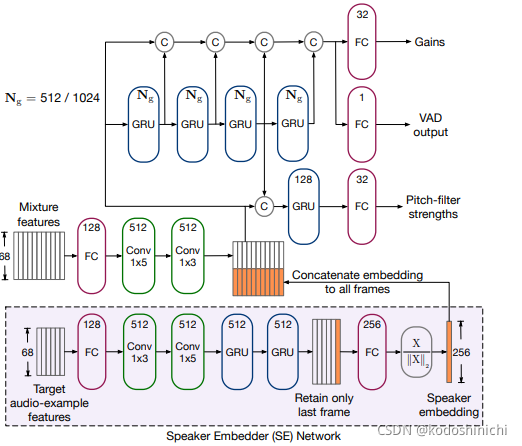
④Info&Tips
i.本架构并不需求过于高分辨率的特征描述,因为我们直接把基因周期等特征包含在特征集中,而不用再从频谱图中隐式地提取。
ii.LPCNet vocoder架构已经证明可以只依赖18个band的高质量的特征表示(内含pitch和voicing的信息),来还原出纯净语音。
Source Separation
- End-to-End Speech Separation Using Orthogonal Representation in Complex and Real Time-Frequency Domain
①概述
【complex-valued case】
- 端到端复数域模型——结合DCN和Conv-TasNet
- 混合的编码-解码结构——使用到了STFT变换和可学的复数层
- 论述了时频变换中特征正交的重要性,提出MSO(Multi-segement orthogonality)架构
【real-valued case】
- 引入STDCT变换得到正交的特征表示,用以在实数的TF-Domain中进行分离
②DC-Conv-TasNet
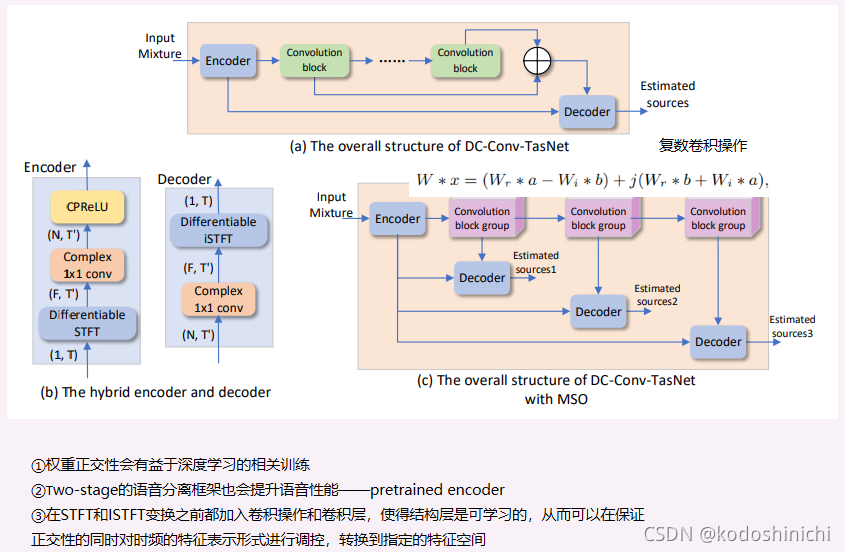
2. Continuous Speech Separation Using Speaker Inventory for Long Recording
①概述
- 该篇论文专注于同时有两个说话人的场景,最终输出有两个信号通道
- SSUSI:speech separation using speaker inventory
使用目标说话人的语音特征信息和额外说话人信号池作为辅助信息来联合分离目标说话人的语音信号;- 现状:现实生活中并不总能有pre-enrolled的过程;且真实的多人说话场景中也会包含很多non-overlapped的片段,可以用于提取鲁棒的单一说话人特征;
- Idea:在long recording的情景下使用SSUSI模型,并提出一种self-informed,clustering-based的inventory-forming机制;旨在直接从输入的混合信号中得到目标说话人特征池的数据。
②Speaker-independent separation
【informed speech extraction】
- 使用目标说话人的额外的信息
- SpeakerBeam——使用序列总结网络针对说话人的utterance生成embedding
- VoiceFilter——将混合频谱特征和目标说话人的d-vector特征信息在每一帧拼接起来
- 优势:避开了permutation和fixed speaker number的问题
- 限制:计算代价与说话人数目呈正比;说话人bias信息的好坏影响目标说话人的提取效果
【SSUSI】
- 使用一个额外的候选说话人语料池同时分离所有说话人
- 不足:需要额外的信息;受到bias影响很大;使用的数据集不能真实还原现实场景
③SSUSI using pre-enrolled utterance

④Continuous SSUSI using self-informed mechanism for inventory construction
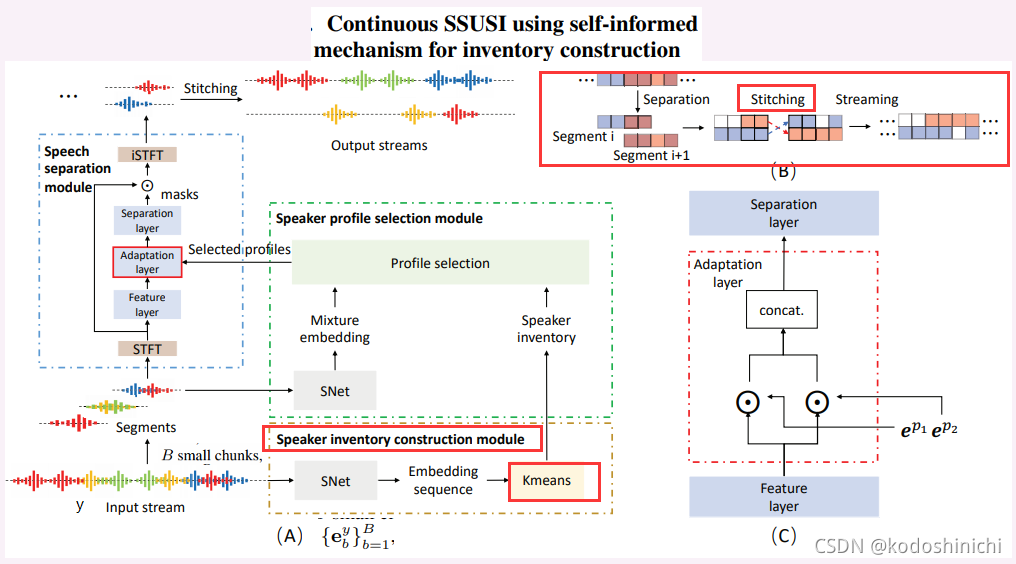
因为从每个segment输出的结果都只含有一个说话人,所以为了能够把各个分段拼接在一起,需要去衡量相邻segemnt之间重叠区域的相似性,以此来决定把哪两个输出片段进行拼接。
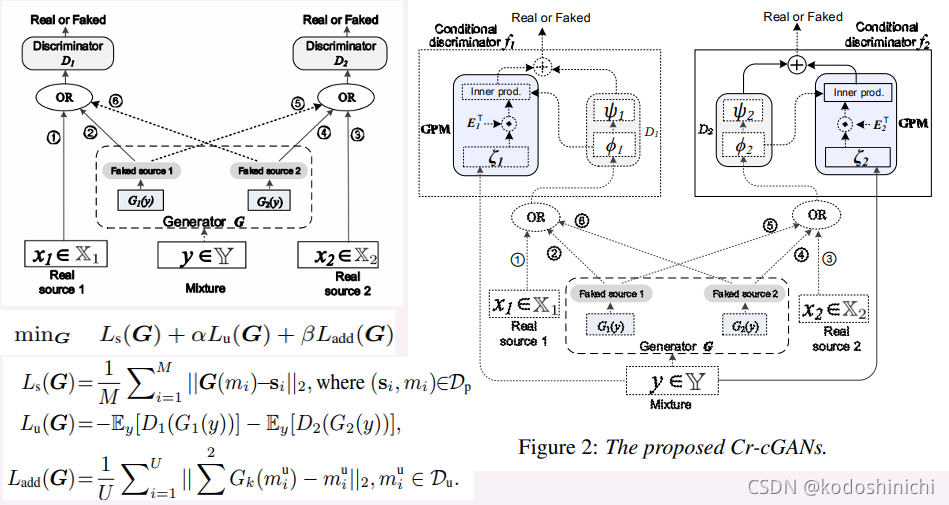
- Crossfire Conditional Generative Adversarial Networks for Singing Voice Extraction
【生成对抗网络】
- 可以很好地对数据的分布进行建模
- 可以有效使用大量的无标签数据
- 现有的基于GAN的SVE架构没有显式的方法去消除不同信源之间的相互影响
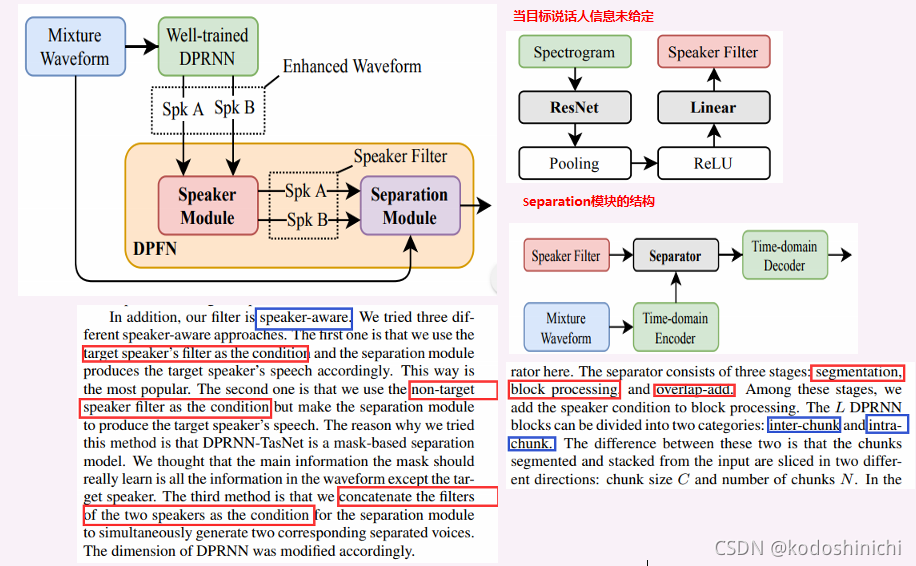
4. Dual-Path Filter Network: Speaker-Aware Modeling for Speech Separation
①概述
- DPFN(Dual-path filter network)旨在于对语音分离进行后处理以提升性能;
- 模型由speaker module和separation module构成——前者识别目标说话人的身份特征,后者结合目标说话人的信息进行语音分离;
- 该模型基于DPRNN-TasNet结构来构成,并且考虑到了permutation的问题
②DPRNN
【Encoder】
将输入的混合信号转换成相关的特征表示形式
【Separator】
根据给定的混合信号的特征表示,得到各个源的掩码
【Decoder】
根据掩码计算后的各个源的信号还原重建出语音信号
【特点】
- 将encoder输出的数据按照有无交叠进行划分,并把他们组成一个三维张量
- 双通道的BiLSTM会将这个三维的张量映射成关于某一说话人的三维的mask
- 将mask和原始的混合张量进行点乘操作,并基于“overlap-add”操作还原得到序列输出
- 双通道的LSTM在两种维度上进行工作——chunk size和chunk numbers,分别用于针对chunk内部的信息和chunk之间的信息
- DPRNN这个结构可以看到当前时间帧附近和很远的相关信息,这也是该模型性能有很大提升的原因。
③SCCM
【speaker inference】
- 基于一个self-attention的Transformer结构,使用STFT变换后的频谱图作为输入
- 计划输出目标说话人标签和相关特征向量
【speech extractor】
- 将speaker embedding和频谱特征基于每一帧进行对齐拼接
- 使用和Conv-TasNet相似的结构进行语音提取的工作
④DPFN















 744
744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









