







Skeleton-based Action Recognition via Spatial and Temporal Transformer Networks
ABSTRACT
骨架数据对光照变化、身体尺度、动态摄像机视图和复杂的背景具有鲁棒性。时空图卷积网络 (ST-GCN) 被证明在学习非欧几里得数据(例如骨架图)上的空间和时间依赖性方面是有效的。
未解决问题: 3D 骨架底层潜在信息的有效编码,尤其是在从关节运动模式及其相关性中提取有效信息时。
本文提出了一种新颖的时空 Transformer 网络 (ST-TR),它使用 Transformer 自注意力算子对关节之间的依赖关系进行建模。在 ST-TR 模型中,空间自注意力模块 (SSA) 用于理解不同身体部位之间的帧内交互,并使用时间自注意力模块 (TSA) 来模拟帧间相关性。
1.Introduction
尽管ST- GCN模型在骨架数据上表现得非常好,但它仍有一些结构上的局限性。
首先,代表人体的图的拓扑结构对于所有层和所有动作都是固定的,这可能会不利于提取丰富的骨架运动时间序列特征(特别是图形有方向且信息只能沿着预定义的路径流动的情况)。
其次,空间卷积和时间卷积都是从标准的二维卷积开始实现的,受卷积核大小的限制,它只能在局部邻域内运行。
最后,现有研究鲜有考虑人体骨骼中没有直接连接的身体关节之间的相关性,比如在拍手这个动作中,左手和右手其实是相关的。
基于此,本研究采用一个优化后的Transformer自注意力运算来解决以上问题,如图1所示:
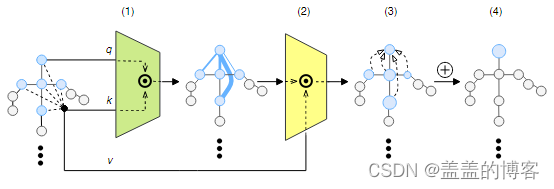
图1 对骨骼关节的自注意力
图1中(1)对每个身体关节,计算查询 q、键 k 和值向量 v;(2)计算关节查询与所有其他节点键之间的点积,表示每对节点之间的关联强度;(3)每个节点按其与当前节点的相关性 w.r.t 进行缩放;(4)将加权节点相加,得到新的特征。
2.Related Works
在这项工作中使用 ST-GCN 作为基线模型;具体来说,使用 Transformer 自注意力算子在空间和时间上替换常规图卷积。通过在图中的节点上应用自注意力,包括帧内和帧间,我们有效地对骨架序列的空间和时间依赖性进行建模。
3.Background
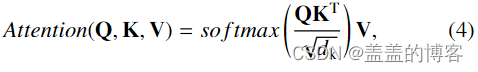
4. Spatial Temporal Transformer Network
4.1. Motivation
原始 Transformer self-attention 背后的想法是允许编码句子中单词之间的短程和长程相关性。本文觉得同样的方法也可以应用于基于骨架的动作识别,因为节点之间的相关性在空间和时间维度上都是至关重要的。本文将包含骨架的关节视为词袋,并利用 Transformer self-attention 提取编码周围关节之间关系的节点嵌入,就像 NLP 中短语中的单词一样。
与仅比较相邻节点的标准图卷积相反,本文丢弃任何预定义的骨架结构,让 Transformer selfattention 自动发现与预测当前动作相关的联合关系。 生成的操作类似于图卷积,但其中内核值是根据发现的关节关系动态预测的。同样的想法也应用于序列级别,通过分析动作期间每个关节如何变化并构建跨越不同帧的远程关系,类似于如何在 NLP 中构建短语之间的关系。生成的算子能够获得在空间和时间维度上扩展的动态表示。
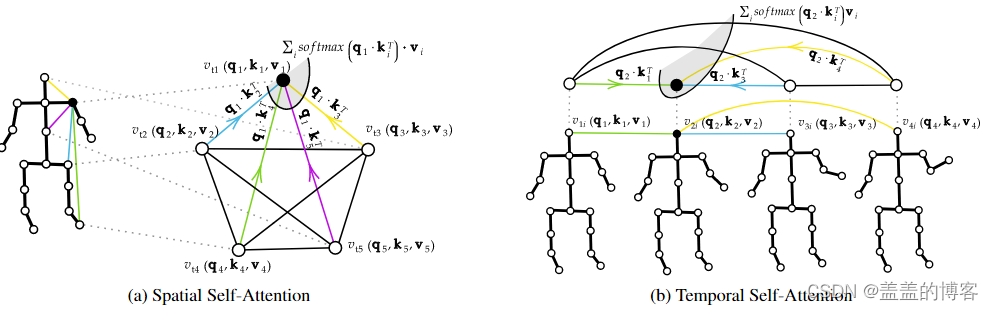
图2 : 空间自我注意(SSA)和时间自我注意(TSA)。
自注意力通过对每对节点计算一个权重来对每对节点进行操作,该权重代表它们相关性的强度。然后使用这些权重对每个身体关节 vti 的贡献进行评分,与节点与所有其他节点的相关性成比例。请注意,在 SSA (a) 上,为简单起见,该过程仅由一组五个节点来说明,而在实践中它对所有节点进行操作。
4.2. Spatial Self-Attention (SSA)
空间自注意力模块在每一帧内应用自注意力来提取嵌入身体部位之间关系的低级特征。这是通过独立计算每个单帧中每对关节之间的相关性来实现的,如图 2a 所示。应用了一个针对所有节点的可学习的多头注意力注意机制,所有动作的相关结构并不是固定的,而是针对每个样本自适应地变化。 SSA 的操作类似于全连接图上的图卷积,但是内核值(即 αt ij 分数)是基于骨架姿势动态预测的。
对于骨架中时间t, 节点vti;首先将查询向量qt i∈Rdq、关键字向量kt i∈Rdk和值向量vt i∈Rdv应用于参数为Wq∈RCin×dq、Wk∈RCin×dk、Wv∈RCin×dv的节点特征nt i∈RCin计算,在所有节点之间共享。然后,对于每一对身体节点(vti, vt j),应用查询键点积得到权重:
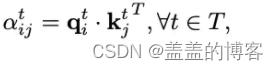
表示两个节点之间的相关强度。得到的分数 αt ij 用于对每个关节值 vtj 进行加权,并计算加权和以获得节点 vti 的新嵌入 zt i,如下所示:
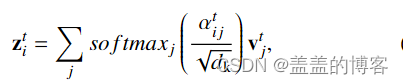
其中 zt i ∈ RCout(输出通道的数量为 Cout)构成了节点 vti 的新嵌入。
4.3. Temporal Self-Attention (TSA)
使用时间自注意力 (TSA) 模块,每个关节的动力学沿所有帧单独研究,即每个单个关节都被视为独立的,通过比较同一身体关节沿时间维度的嵌入的变化来计算帧之间的相关性(见图 2b)。该公式与 SSA 的等式 (5) 中报告的公式对称:
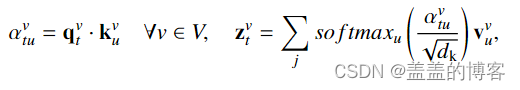
其中 vti, vui 表示两个不同时刻 u 中的相同关节 v,αi tu ∈ R 是相关分数,qi t ∈ Rdq 是查询与 vti 相关联,ki u ∈ Rdk 和 vi u ∈ Rdv 是与联合 vui 相关的键和值(所有这些都使用 SSA 中的可训练线性变换计算),zi t ∈ RCout 是生成的节点嵌入。请注意,本节中使用的符号与第 4.2 节中使用的符号相反;下标表示时间,上标表示关节。
多头注意力的应用与 SSA 中一样。 网络通过及时提取节点之间的帧间关系,可以学习将帧相互关联(例如,第一帧中的节点与最后一帧中的节点),捕获原本无法因为标准卷积受内核大小限制的其他方法捕获的判别特征 。
4.4. Two-Stream Spatial Temporal Transformer Network
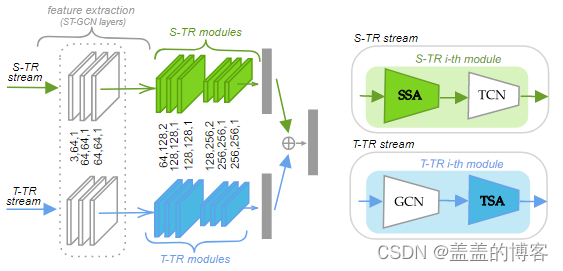
图3 两个 2s-ST-TR 架构的图示。
在每个流中,前三层通过标准 ST-GCN层提取低级特征。在每个连续的层上,在S-TR流上,SSA用于提取空间信息,然后在时间维度(TCN)上进行2D卷积,而在T-TR流上,TSA用于提取时间信息,而空间特征由标准图卷积(GCN)提取。
为了结合SSA和TSA模块,使用了一种名为ST-TR的双流架构,这两个流区分了所提出的自我注意机制的应用方式:SSA 在空间流(命名为 S-TR)上运行,而 TSA 在时间流(命名为 T-TR)上运行。在这两个流上,节点特征首先由三层残差网络提取,其中每一层都通过图卷积 (GCN) 处理空间维度上的输入,并通过标准的 2D 卷积 (TCN) 在时间维度上,如 ST-GCN那样。然后将 SSA 和 TSA 应用于 S-TR 和后续层中的 T-TR 流,分别替换 GCN 和 TCN 特征提取模块(图 3)。S-TR流和T-TR流是端到端训练的及其相应的特征提取层。子网络输出最终通过求和它们的softmax输出分数融合在一起,得到最终的预测。
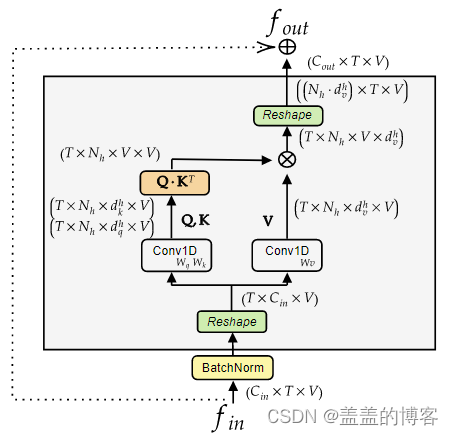
图4 SSA模块的说明(TSA的实现是相同的,唯一的区别是维度V对应于T,反之亦然)。
输入fin通过在批处理维度中移动 T 来重塑,以便自注意力分别在每个时间帧上运行。SSA 实现为矩阵乘法,其中 Q、K 和 V 分别是查询、键和值矩阵,⊗ 表示矩阵乘法。
空间变压器流(S-TR) 在空间流中,通过 SSA 模块在骨架级别应用自注意力,该模块专注于关节之间的空间关系,然后将其输出传递给时间维度上具有内核 Kt 的 2D 卷积模块(TCN):
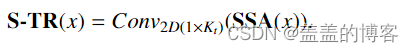
在原始 Transformer 之后,输入通过批量归一化层,进行预归一化,并使用跳过连接,将输入与 SSA 模块的输出相加。
时间 Transformer 流 (T-TR) :相反,时间流侧重于发现帧间时间关系。与 S-TR 流类似,在每个 T-TR 层内,标准的图卷积子模块后面是提出的时间自注意力模块:
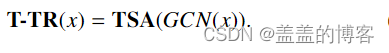
TSA 对所有时间维度(例如,所有左脚或所有右手)链接相同关节的图进行操作。
4.5. SSA和TSA的实现
如图 4 所示,给定一个形状输入张量 (Cin, T, V),其中 Cin 是输入特征的数量,T 是帧数,V 是节点数,矩阵 XV ∈ RT ×Cin ×V 通过重新排列输入得到。这里 T 维在批次维度内移动,有效地沿时间维度实现参数共享,并分别在每一帧上应用变换:
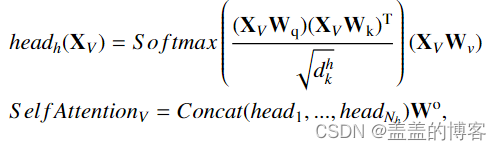
仅在矩阵的形状上有所不同,变为 Q ∈ RV×Nh×dh q ×T , K ∈ RV×Nh ×dh k ×T 和 V ∈ RV×Nh×dh v ×T。
5. Model Evaluation
5.2. Model Complexity
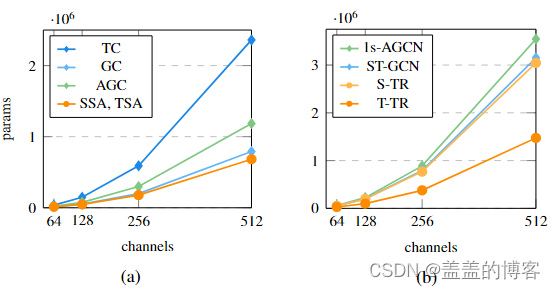
图5 (a) Cin = Cout通道的图卷积(GC)、自适应卷积(AGC)、空间自我注意(SSA)模块以及时间卷积(TC)和时间自我注意(TSA)模块之间的参数差异;(b) ST-GCN、1s-AGCN和我们的新S-TR和T-TR之间的参数比较。
如图5(a)中,一层标准卷积与我们的变压器机制,设置Cin = Cout通道。这导致 TSA 和 SSA 的参数数量相同,因为内部执行的卷积具有相同的内核维度,查询键点积和 logit 值乘积都是无参数的。
可以看出,SSA 比 GC 引入的参数更少,尤其是在处理大量通道时。
自适应模块 (AGC) 比SSA的参数更多。
在时间维度上,TC比T S A 的参数更多。ST-GCN中的时间卷积被实现为具有滤波器 1 × F 的 2D 卷积,其中 F 是沿时间维度考虑的帧的数量,通常设置为 9,沿 T = 300 帧跨步。因此,除了更好的性能之外,用自注意力机制替换它会导致复杂性大大降低。
在图 5b 还比较了整个流架构,即 ST-GCN 和 1s-AGCN 与所提出的 S-TR 和 T-TR 流在参数方面。正如预期的那样,通过将时间卷积替换为TSA来实现参数减少的最大改进,即在T-TR比ST-GCN参数更少。在空间维度上,参数的差异不像时间维度那么明显。
5.4. Results
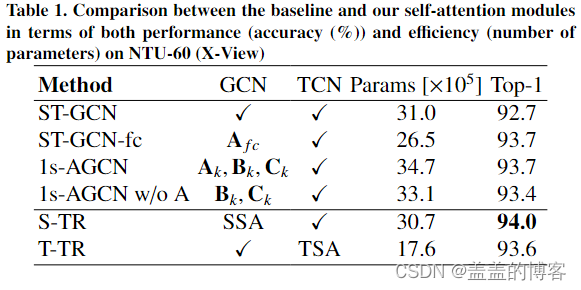
为了验证SSA和TSA模块的有效性,将S-TR和T-TR流分别与ST-GCN 基线和其他修改其基本GCN模块的模型作比较,表明自我注意可以用于代替图卷积,提高网络性能,同时减少参数的数量。
同样,关于TSA,T-TR与采用标准卷积的ST-GCN基线的比较,通过在时间维度上使用自我注意,模型明显较轻,准确率提高。

首先通过仅使用联合信息组成的输入数据来分析 S-TR 流、T-TR 流及其组合的性能。S-TR 流在 X-View 和 X-Sub 上都比 T-TR 流实现了稍好的性能,这可能是因为 STR 中的 SSA 仅在 25 个关节上运行,而在时间维度上,相关性的数量与大量帧成正比。
当添加骨骼信息作为输入时,所有先前的配置都会得到改善。表明了我们方法的灵活性,能够适应不同的输入类型和网络配置。
其中 GCN 模块被时间流上的 AGCN 自适应模块替换。可以看出,这些配置 (T-TR-agcn) 在 X-Sub 和 X-View 上都比标准 GCN 取得了更好的结果。
5.5. Effect of Applying Self-Attention since Feature Extraction
本文设计的流,从高级特征开始操作,而不是直接从坐标开始。
表2b中,SSA (TSA) 从第一层替换 S-TR (T-TR) 流上的 GCN (TCN)。表 2b(命名为 S-TR-alllayers)中报告的配置的性能比表 2a 中相应的配置差,同时仍然优于基线 ST-GCN(见表 3)。
5.6. Effect of Augmenting Convolution with Self-Attention
本文研究了将所提出的 Transformer 机制作为增强过程应用于原始 ST-GCN 模块的效果。在此配置中,GCN (TCN) 产生的 0.75 × Cout 特征,并将它们连接到 SSA (TSA) 的剩余 0.25 × Cout 特征。
为了弥补注意力通道的减少,使用了广泛的注意力,即每个头部分配了一半的注意力通道,然后在合并头部时将它们重新组合。结果如表 2b 所示(称为 ST-TR-augmented)。图卷积是受益于 SSA 注意力(S-TR-augmented,94.5%)最多的卷积,与表 2a 中的 S-TR 94% 进行比较。然而,分配给自注意力的输出特征数量较少可以防止时间卷积改进 T-TR 流。
5.7. Effect of combining SSA and TSA in a single stream
我们在单个流架构中组合 SSA 和 TSA 时测试了模型的效率(见表 2b,称为 S-TR-1s)。参数更少,比 ST-GCN 基线高出 0.6%。
6. Comparison with State-Of-The-Art Results
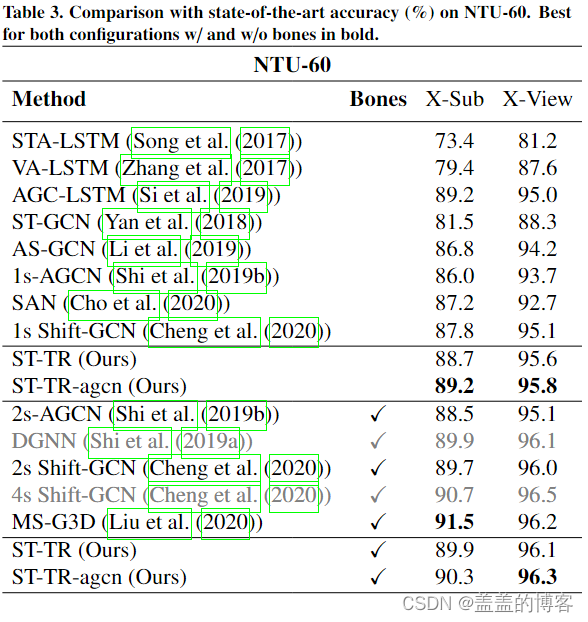
当仅使用联合信息时,所提出的 ST-TR 优于使用相同类型信息的所有最先进模型。当使用骨骼信息时,所提出的基于变压器的架构在 X-Sub 和 X-Set 上都优于 2s-AGCN ,并且我们使用 AGCN 主干 (ST-TR-agcn) 的最佳配置与最先进的架构相当。尽管 4s Shift-GCN 使用额外的输入数据并结合了两个额外的流,但 ST-TR-agcn 仍然取得了相当的结果,但设计更简单。
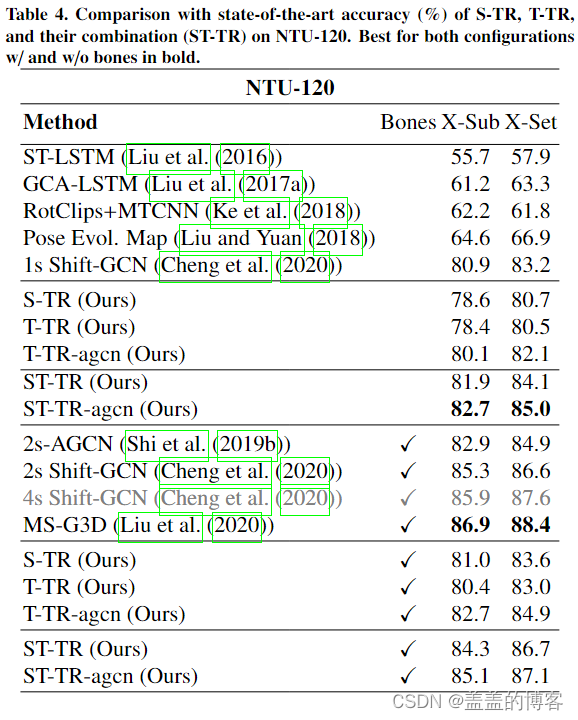
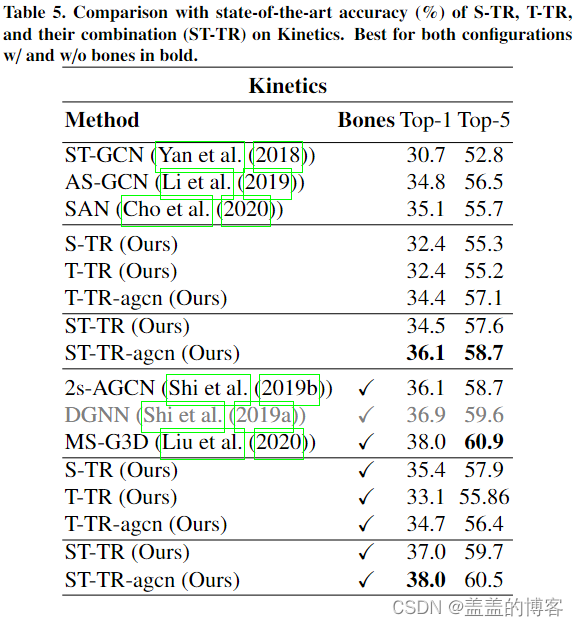
在 NTU-120(表 4)上,仅基于关节的模型优于使用相同信息的所有最先进的方法。在添加骨骼时,ST-TR 和 ST-TR-agcn 都优于 2s-AGCN 。此外,ST-TR-agcn 的结果与 X-Sub 上的 2s Shift-GCN 相当,但它们在 XSet 上有所改进。我们的网络的性能仅略低于 MS-G3D,这迄今为止代表了一个非常基于骨架的动作识别的强大基线。考虑到 MS-G3D 具有多尺度图卷积的多路径设计,ST-TR 获得的性能是显著的,因为后者基于更简单的主干。最后,在 Kinetics(表 5)上,我们仅使用关节的模型比 ST-GCN 基线高出 5%,并且所有以前的方法仅使用关节信息。当添加骨骼信息时,它优于 2s-AGCN 和 DGNN,并取得了与最近最先进的方法 MS-G3D 相当的结果。
8. Conclusions
本文提出了一种新的方法,在骨架活动识别中引入Transformer自我注意作为图卷积的替代方案。通过对NTU-60、NTU-120和Kinetics的广泛实验,证明了空间自我注意模块(SSA)可以取代图卷积,从而实现更灵活和动态的表示。类似地,时间自注意力模块 (TSA) 克服了标准卷积的严格局部性,从而能够提取动作之间的长期依赖关系。此外,我们最终的时空 Transformer 网络 (ST-TR) 在所有数据集 上实现了最先进的性能,使用相同的输入联合信息和流设置的方法,并在添加骨骼信息时与最先进的方法相当。由于仅涉及自注意力模块的配置被证明是次优的,因此未来可能的工作是搜索一个统一的 Transformer 架构,能够在各种任务中替换图卷积。

















 4450
4450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









