







在文本挖掘领域,少不了对PDF文件进行处理的,其中有不少PDF里面可能是单纯的图片,这个时候就需要采用OCR技术进行图像文字识别。今天发布一版将图片PDF转为WORD文字的教程,首先需要安装并且配置好Tesseract OCR工具。下面展开详细教程。
(一)Tesseract OCR工具安装
1、首先下载安装包
安装包下载地址:https://digi.bib.uni-mannheim.de/tesseract/
安装包版本为:tesseract-ocr-w64-setup-5.3.4.20240503.exe
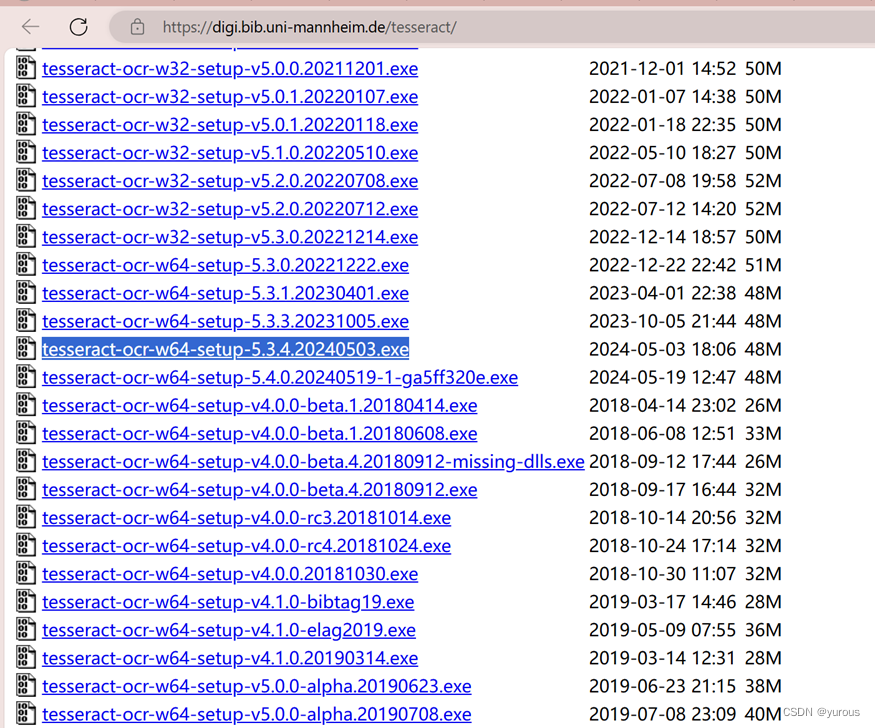
下载下来后就是一个.exe可执行文件(就不需要github上下载二进制文件然后进行一系列操作啦)

2、双击.exe可执行文件进行本地安装
一步步选择就行啦
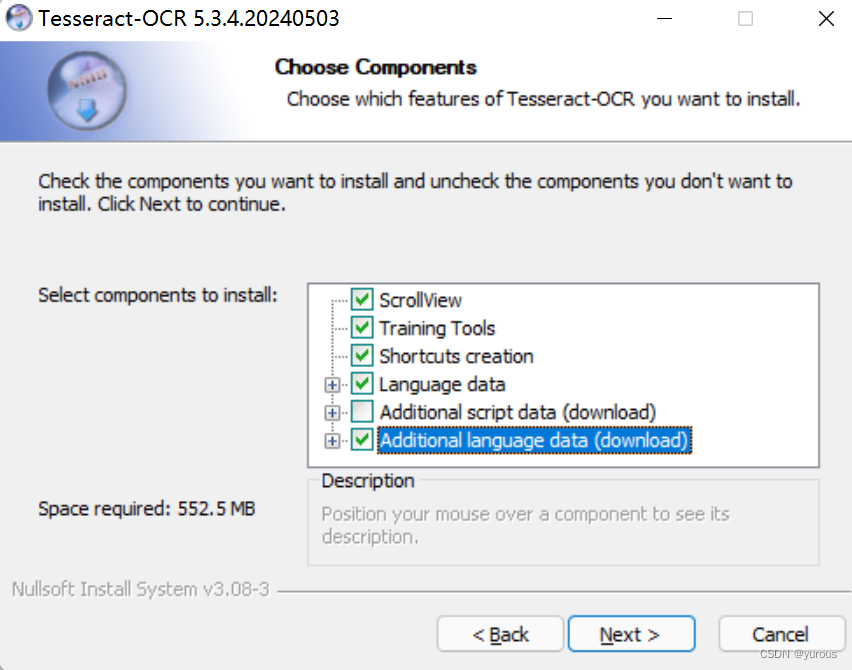
(可以看到上图我把语言包选择了,选择这个选项能够把目前OCR所有能识别的语言都下载好,搭了梯子会稍微快一些,没有搭梯子建议不勾选,然后采用这个参考链接里的方法单独下载语言包https://www.jianshu.com/p/f7cb0b3f337a)
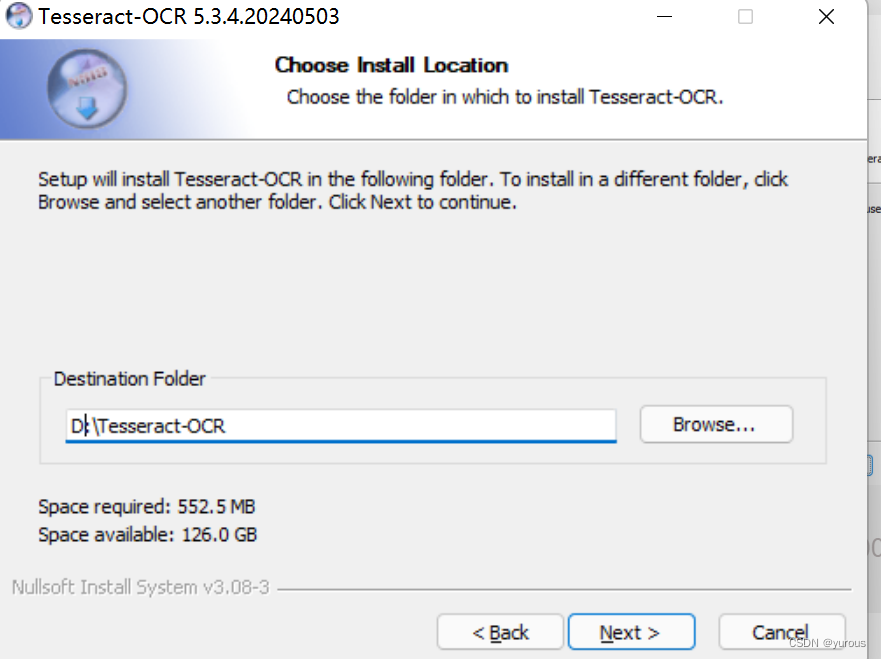
(选择好目标文件夹之后就是缓慢的安装过程啦)
3、配置系统环境
设置-高级系统设置-环境变量-PATH
在PATH里面新建刚才下载的目标文件夹的路径,我的是D盘
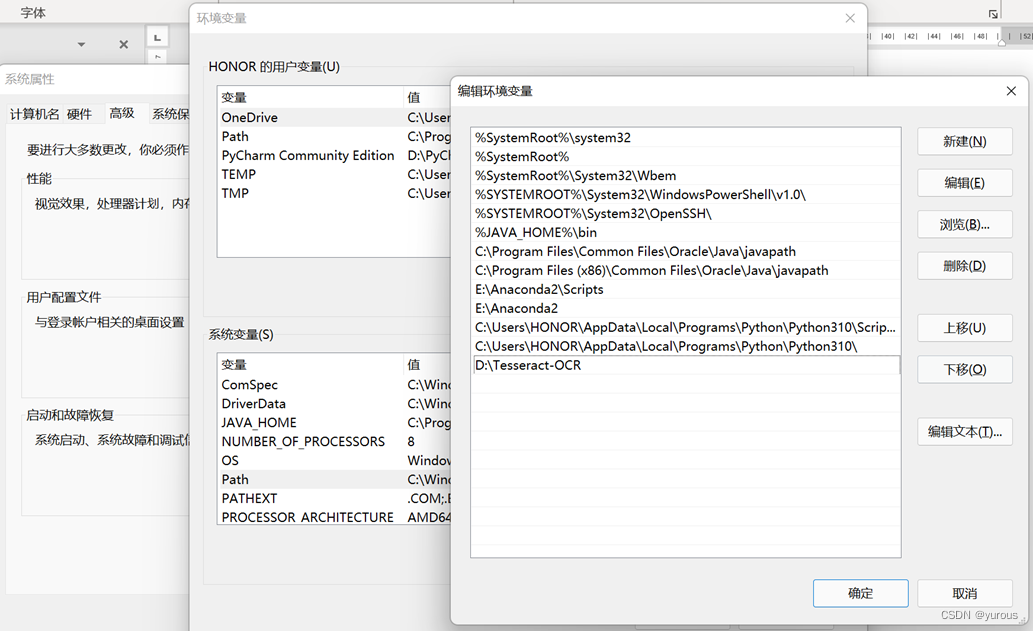
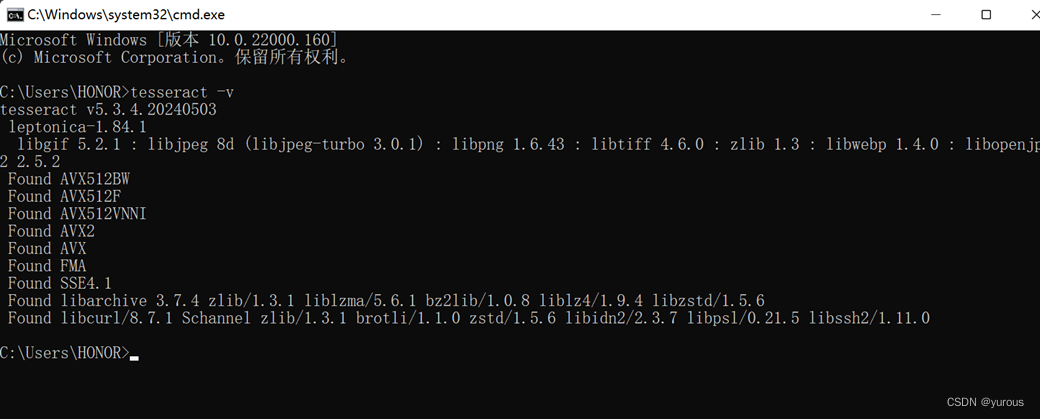
4、验证是否下载并配置成功
win+R输入cmd,在命令行中输入
tesseract -v
出现下图的结果就说明成功啦
可以再输入下面指令看看语言包
tesseract --list-langs
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1073
1073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











