









引言
-
分区表实际上就是对应一个HDFS文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过WHERE子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
-
Hive中支持的分区类型有两种:
- 静态分区
- 动态分区
-
静态分区和动态分区的主要区别在于静态分区需要手动指定,而动态分区是基于查询参数的位置去推断分区的名称,从而建立分区。总的来说就是,静态分区的列是在编译时通过用户传递来决定的;动态分区只有在SQL执行时才能确定
-
注意:分区字段绝对不能出现在数据库表已有的字段中!
1、静态分区
1.1 静态分区——单分区
1、创建静态分区表t1,分区字段为部门
create table t1(
id int,
name string,
likes array<string>,
adress map<string,string>
)
partitioned by (department string)
-- 字段分割符
row format delimited fields terminated by ','
-- MAP 和 ARRAY 的分隔符(数据分割符号)
collection items terminated by '_'
-- 键值分隔符
map keys terminated by ':'
-- 行分隔符
lines terminated by '\n';
- 查看表信息
desc t1;

2、加载数据
- 下面数据为部门1的数据,存储在department.txt
001,Ace,study,Guangdong:SZ,
002,Jack,reading-movie,Guangdong:GG-Guangdong:DG,
003,Maria,basketball-Computer games-Swimming,Guangdong:SZ-Guangdong:DG,
004,Jimmy,reading-sing,Guangdong:SZ-Guangdong:HZ-Guangdong:DG,
005,Tom,dance-movie,Guangdong:FS-Guangdong:DG
- 加载数据到表t1,并查看表
load data local inpath '/hive_data/department.txt' into table t1 partition(department='dep-1');
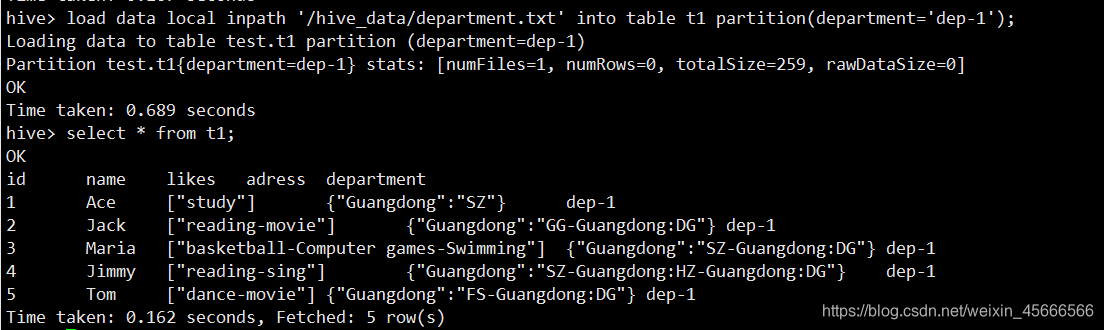
那么数据是存储在哪里呢?
- hive默认表存放路径一般都是在你工作目录的/user/hive/warehouse/库名.db/下创建一个目录,按表名做文件夹分开。
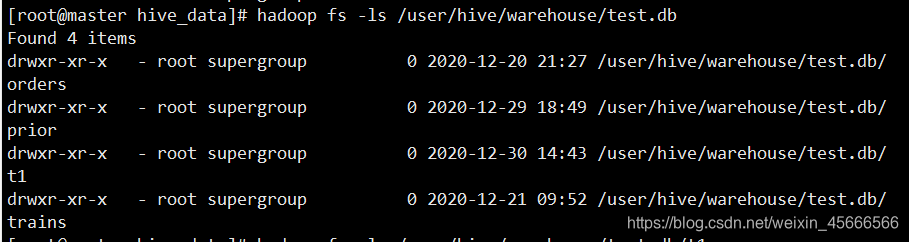
- 可在终端里面通过命令
hadoop fs -ls /user/hive/warehouse/test.db进行查看
- 也可以通过dfs端口进行查看

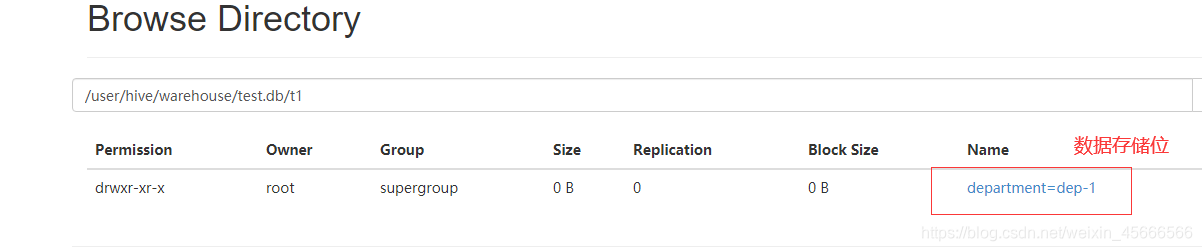
3、查看分区信息
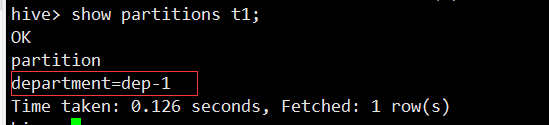
show partitions t1;
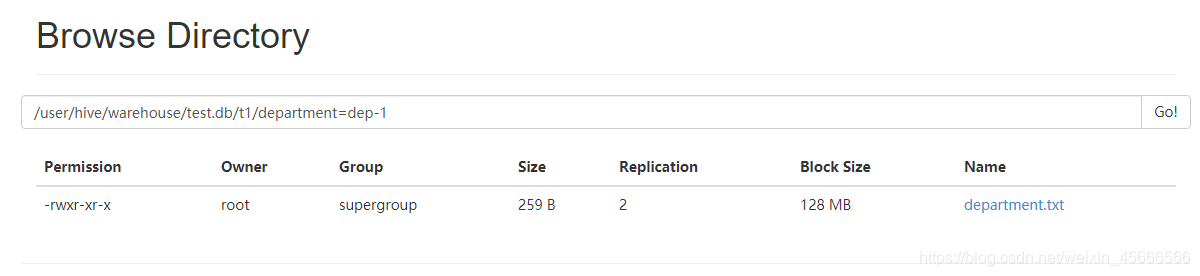
- 查看web页面
-
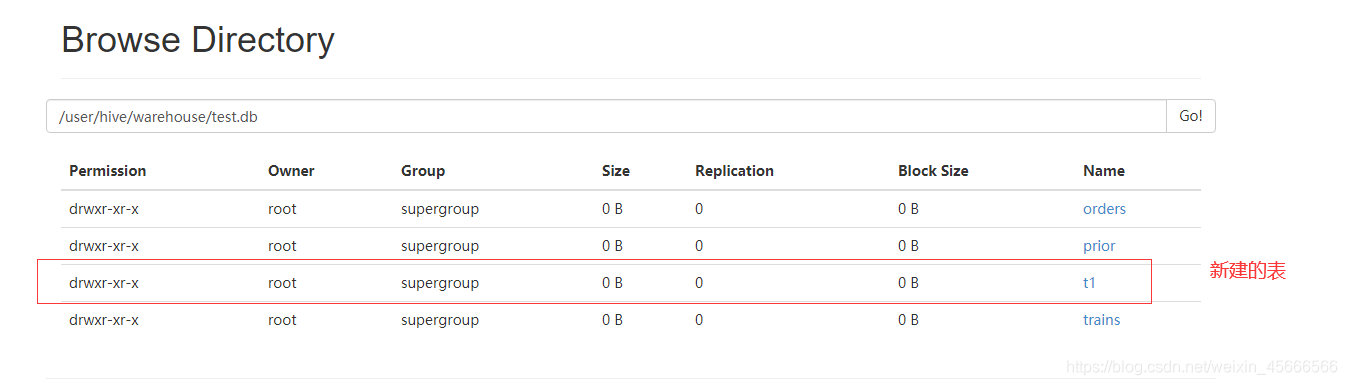
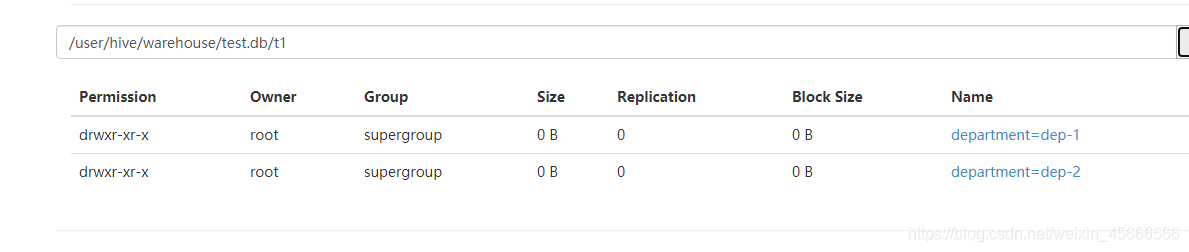
如上图所示,在新建分区表的时候,系统会在hive数据仓库默认路径/user/hive/warehouse/库名.db/下创建一个目录(表名),然后在该目录下再创建子目录department=dep-1(分区名),最后在分区名下存放实际的数据文件(load加载进表的文件department.txt)
-
如上,一个静态分区——单分区表就建成了。
4、我们再导入数据到新的第二分区
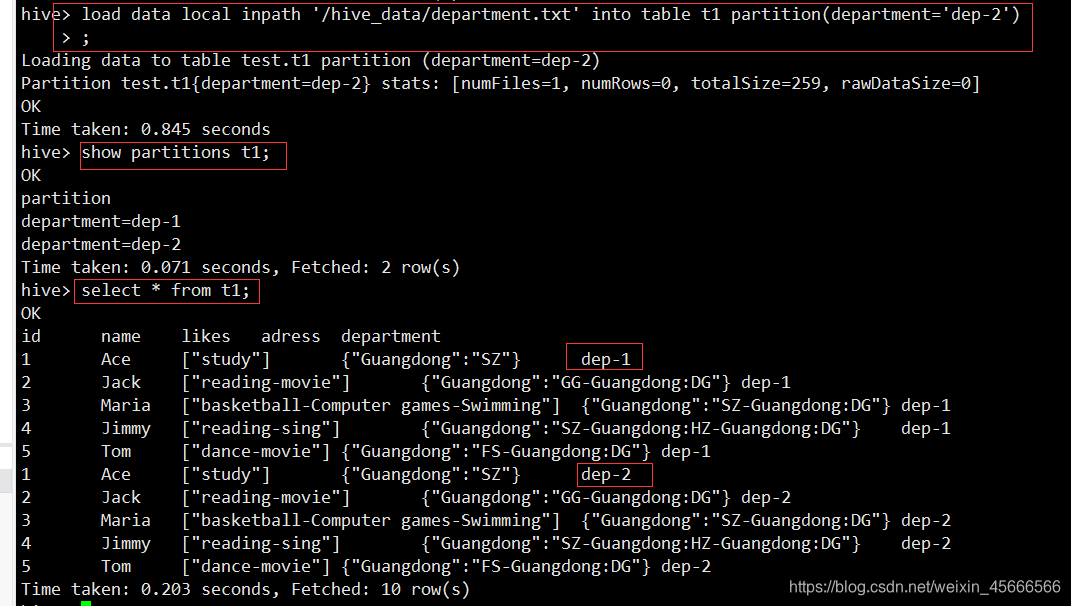
- 查看web页面:
5、删除第二分区
alter table t1 drop if exists partition(department='dep-2');
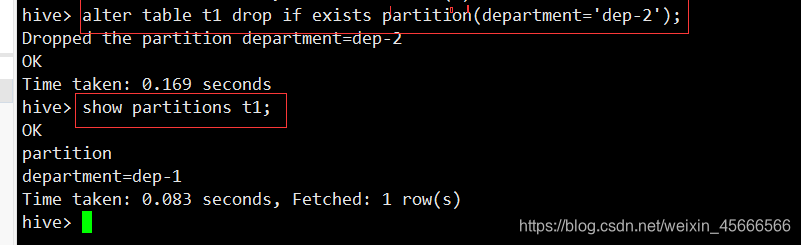
1.2 静态分区——多分区
1、创建多分区表t2,分区字段为部门,性别
create table t2(
id int,
name string,
likes array<string>,
adress map<string,string>
)
partitioned by (department string comment '部门',sex string comment '性别')
-- 字段分割符
row format delimited fields terminated by ','
-- MAP 和 ARRAY 的分隔符(数据分割符号)
collection items terminated by '_'
-- 键值分隔符
map keys terminated by ':'
-- 行分隔符
lines terminated by '\n';
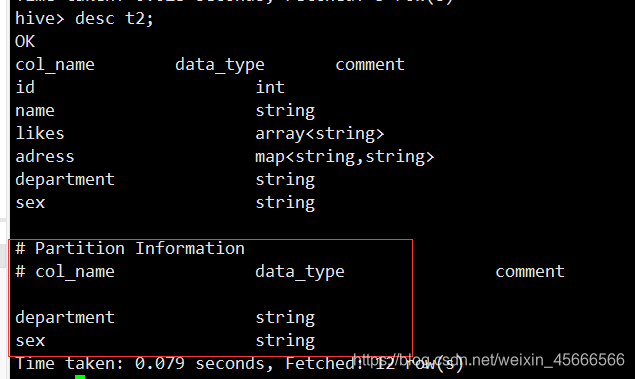
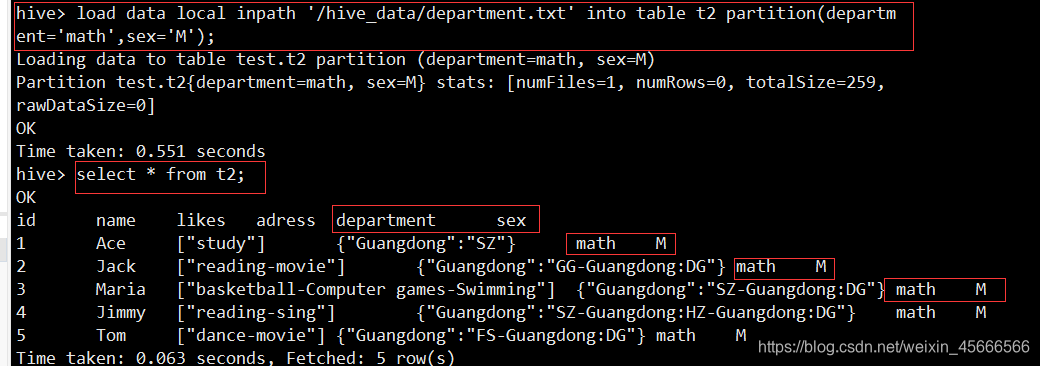
2、将上面测试数据加载到表中
load data local inpath '/hive_data/department.txt' into table t2 partition(department='math',sex='M');
3、查看分区信息
show partitions t2;
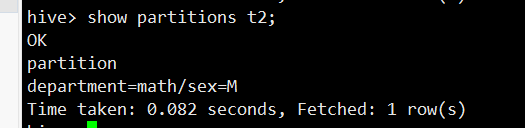
注意:多分区时,分区字段都要加,否则会报错

2、动态分区
- 在往hive分区表中插入数据时,如果需要创建的分区很多,比如要以表中某个字段进行分区存储,则需要复制粘贴修改很多HQL去执行,如此一来效率很低。
- 在关系型数据库中,对分区表Insert数据时候,数据自动会根据分区字段的值,将数据插入到相应的分区中,因为hive是批处理系统,所以Hive提供了一个动态分区功能,其可以基于查询参数的位置去推断分区的名称,从而建立分区。
2.1 动态分区——单分区
略
2.2 动态分区——多分区
1、创建原表t3,加载原数据到表t3
- 原数据
1,Ace,20,M,study,Guangdong:SZ,
2,Jack,22,M,reading-movie,Guangdong:GG-Guangdong:DG,
3,Maria,20,F,basketball-Computer games-Swimming,Guangdong:SZ-Guangdong:DG,
4,Jimmy,23,M,reading-sing,Guangdong:SZ-Guangdong:HZ-Guangdong:DG,
5,Tom,25,F,dance-movie,Guangdong:FS-Guangdong:DG
- 创建表t3
create table t3(
id int,
name string,
age int,
gender string,
likes array<string>,
adress map<string,string>
)
-- 字段分割符
row format delimited fields terminated by ','
-- MAP 和 ARRAY 的分隔符(数据分割符号)
collection items terminated by '_'
-- 键值分隔符
map keys terminated by ':'
-- 行分隔符
lines terminated by '\n';
- 加载数据
load data local inpath '/hive_data/department.txt' into table t3;
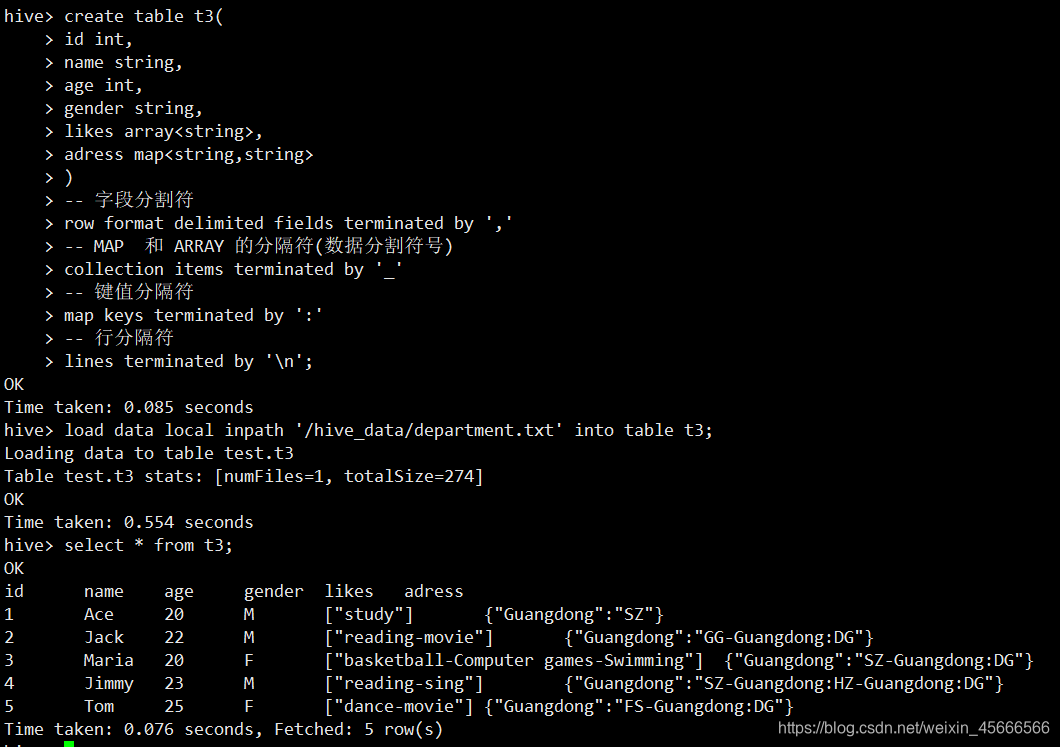
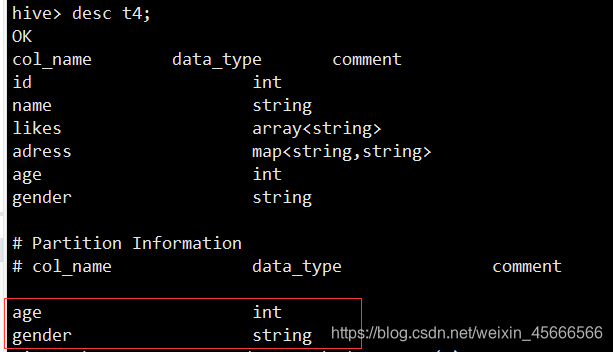
2、创建动态分区表t4
- 注意动态分区表字段中不能有分区字段
- 由于我们要以age,gender进行多分区,因此我们在创动态分区表中,字段可以是除了age,gender之外原数据任意字段
create table t4(
id int,
name string,
likes array<string>,
adress map<string,string>
)
partitioned by (age int,gender string)
-- 字段分割符
row format delimited fields terminated by ','
-- MAP 和 ARRAY 的分隔符(数据分割符号)
collection items terminated by '_'
-- 键值分隔符
map keys terminated by ':'
-- 行分隔符
lines terminated by '\n';
3、打开动态分区模式,并且设置分区模式为非严格模式
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;

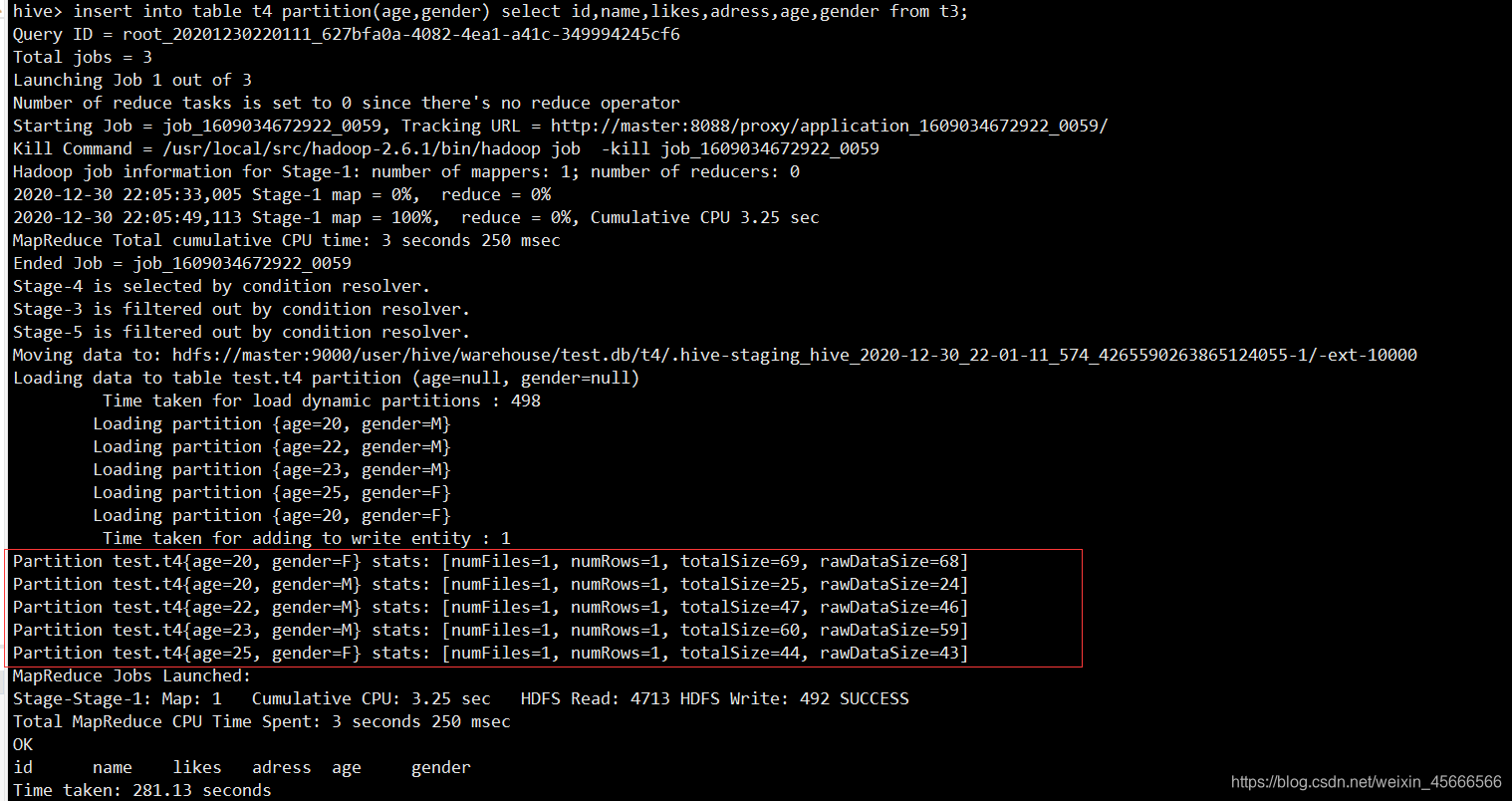
4、加载数据到t4
- 注意从原数据表t1提取字段时,分区字段必须放在后面
- 因为我们在动态分区表时,系统默认将分区字段放在后两列。
insert into table t4 partition(age,gender) select id,name,likes,adress,age,gender from t3;
5、查看分区信息
show partitions t4;
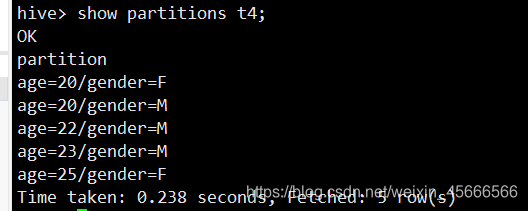
3、静态+动态分区
- 部分字段静态分区,部分动态分区
- 多个分区字段时,会实现半自动分区
- 注意:静态分区字段要在动态的前面
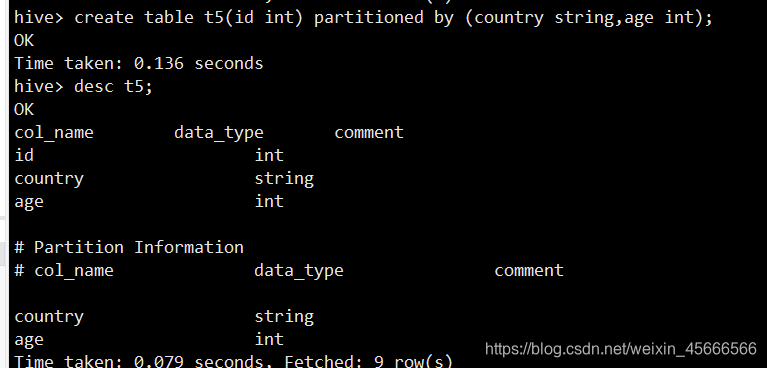
1、创建一个只有一个字段,具有两个分区字段的分区表t5
- country分区为静态,age为动态分区,以查询的age字段为分区名
3、打开动态分区模式,并且设置分区模式为非严格模式
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
4、加载数据
- contry为静态分区字段,需要指定字段名为什么
insert overwrite table t5 partition(country='china',age) select id,age from t3;
5、查看分区信息
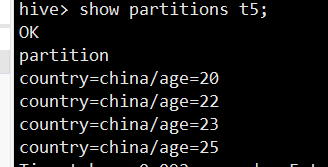
4、动态分区优化
\quad \quad 动态分区的一些参数设置,有时候会优化你的分区。
- 在所有执行MR的节点上,最大可以创建多少个动态分区
- 该参数是根据具体的业务场景决定的。比如源数据中包含了一年的数据,若按day进行分区,那么该参数就需要设置成大于365,如果使用默认值100,那么就会报错
hive.exec.max.dynamic.partitions=1000
- 整个MR Job中,最大可以创建多少个HDFS文件
hive.exec.max.created.files=100000

















 663
663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









