







通用的引导型神经网络生成式摘要框架
会议:NAAC CCF-B区

Abstract
讲述了神经网络模型在生成摘要方面是可行的,但是有些时候会产生不可靠的结果,产生事实性的错误,而且难以控制生成的内容。(可以用unfaithful来描述)为了解决这些问题,之前的研究就尝试提供不同类型的指导来控制输出并增加忠实度,但是现在仍然不知道这些策略之间比较的结果。
faithfulness:内容摘要和原文内容的一致性
作者提出了作者提出了一种框架GSum(Generate and extensible guided Summarization framework),这个框架能够高效的接受不同的外部引导作为输入,并且对不同类型的引导做了实验
Introduce
介绍了两种文本摘要的技术
- 抽取式:抽取式方法从输入文档中识别最合适的单词或句子,并将它们连接起来形成摘要
- 生成式:生成式方法则自由地生成摘要,并能够产生新的单词和句子,比抽取式摘要更加灵活,其更有可能产生流畅和连贯的摘要。然而,抽象摘要的无约束性质也可能导致问题。
生成式摘要可能产生的问题:
- 可能产生不忠实(unfaithful)的摘要,产生事实性的错误和不真实的内容
- 难以控制生成的内容
Gsum和之前研究的不同点创新点
描述了一些之前用于指导神经网络摘要模型的方法
Kikuchi et al. (2016) :规定摘要的长度
Li et al.(2018):为模型提供了关键词,以防止模型丢失关键信息
Cao et al.(2018):提出了从训练集中检索和引用相关摘要的模型
虽然这些方法已经证明了总结质量和可控性的改进,但每种方法都专注于一种特定类型的指导-仍然不清楚哪种更好,以及它们是否相互补充。
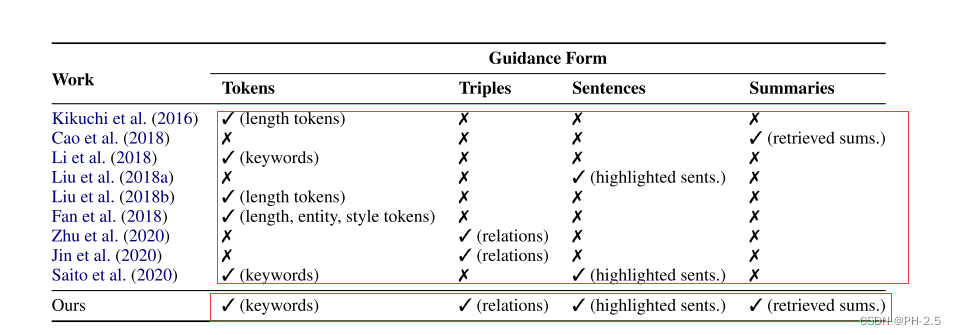
上图列出了不同方法引导神经网络摘要模型的比较,可以发现在本文之前的研究中,并没有将这些不同形式的引导相结合,但是Gsum框架将它们结合在一起
- sequence:原文中的重要句子
- tokens :标记(长度,主题,关键字)
- Triples:从原文中找出一系列的关系,形成三元组(subject,relation,object)
- Summaries:从训练集检索到的相似的摘要
架构
像现在文本摘要生成的大多数模型一样,如同(BART 和BERT)基于编码器-解码器的架构,使用上下文化的预训练语言模型来实现
研究的四个引导信号
(1)源文档中突出显示的句子
(2)关键字
(3)(主语、关系、宾语)形式的显著关系三元组
(4)检索到的摘要
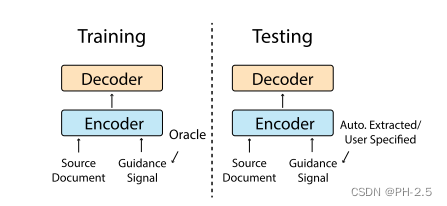
测试期间:为模型提供自动提取或用户指定的指导,以约束模型输出
在训练时,为了鼓励模型密切关注指导,我们建议使用oracle来选择信息丰富的指导信号
Oracle指的是一个用于训练的指导信号选择器
Background and Related Work
引导可以被定义为一种信号 g,它在源文档 x 之外被输入到模型中
Methods
model structure
采用Transformer 模型作为骨干框架,用BERT或BART进行实例化,它们可以被
分离成编码器和解码器组件。
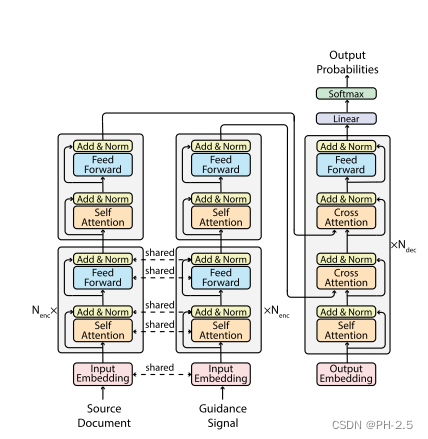
Encoder
Gsum的Encoder分为两部分,一部分对原文进行编码,另一部分对指导信息进行编码,一共有 Nenc+1 层。其中,前Nenc 层,两部分是共享参数的,最后一层是分开的。
1)这样可以减少计算量和内存需求;
2)我们推测源文档和制导信号之间的差异应该是高层次的,
对于Encoder中的每一层,可以写成下面这样的公式:
x = LN(x + SELFATTN(x)),
x = LN(x + FEEDFORWARD(x)),
Decoder
对于Decoder部分,相比原始的Transformer框架,增加了一层Cross Attention,用于计算指导信息的Attention,其余的和经典Transformer模型是一样的。
与标准的Transformer 不同,解码器必须同时关注源文档和引导信号,而不是只关注一个输入
解码器由相同的Ndec 层组成,每一层包含四个块。自注意块结束后,解码器首先关注制导信号并生成相应的表示,由此制导信号通知解码器应关注源文档的哪一部分。然后,解码器将根据指南感知的表示来处理整个源文档。
完整的讲,每一层Decoder需要进行四个步骤:
y = LN(y + SELFATTN(y)),
y = LN(y + CROSSATTN(y, g)),
y = LN(y + CROSSATTN(y, x)),
y = LN(y + FEEDFORWARD(y)).
Choices of Guidance Signals
测试时:
- Manal Definition。手工打造,只在test阶段比较现实,用户可以设计自己喜欢的signal
- Automatic Prediction。通过其他模型来根据原文本生成相应的signal
训练时:
- Automatic Prediction。通过其他模型来根据原文本生成相应的signal
- Oracle Extraction,我们使用 x和 y,来推断一个值g,它在生成y时最有可能是有用的。
Guided Signal包含以下四种:
Highlighted Sentence:
- 对于oracle extraction,作者使用贪婪搜索算法,查找源文档与参考摘要中具有最高的ROUGE分数的一组句子,并处理这些句子作为我们的指导 g。
- 对于automatic prediction,作者使用其他预训练模型进行预测。
Keyword:
- 对于oralce extraction 整个句子可能会包含一些不必要的信息,因此得到使用上述说的贪心搜索算法得到这些关键句子之后,作者再用TextRank提取出一些候选关键字,再过滤不在目标摘要中出现的关键字.
- 对于automatic prediction,作者依然是使用其他的预训练模型进行预测。
Relation
- 对于oracle提取,我们首先使用Stanford OpenIE从源文档中提取关系三元组。与我们如何选择突出显示的句子类似,我们贪婪地选择一组与参考文档具有最高 ROUGE 分数的关系,然后将其展平并视为指导。
- 对于自动预测,我们使用另一个神经模型(类似的 BertAbs)来预测目标侧的关系三元组。
Retrieved Summary - 对于oracle提取,我们直接检索五个数据点 {(x1,y1)…(x5,y5)} 来自训练数据,其摘要 yi 与目标摘要 y 最相似。
- 对于自动预测,我们检索五个数据点,其源文档 xi 与每个输入源文档 x 最相似的摘要
ROUGE度量标准
ROUGE是一组用于评估自动摘要质量的度量标准,通过比较生成的摘要与一个或多个参考摘要之间的重叠程度来进行评估。
ROUGE-1衡量生成的摘要与参考摘要之间的单个词的重叠,
ROUGE-2衡量二元组的重叠,
ROUGE-L衡量生成的摘要与参考摘要之间的最长公共子序列。
Experiments
作者测试的时候一共使用了6个数据集,分别是:Reddit、Xsum、CNN/DM、WikiHow、New York Times(NYT)、PubMed。
Performance of Different Guidance Signals
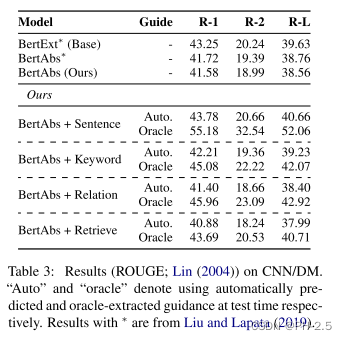
其中,表格中的“Auto”表示的是在测试时使用自动抽取的指导信息,而“Oracle”表示在测试时也使用Oracle提取的信息。
可以发现,使用关键句作为指导信息的作用是最大的,使用三元组关系和相似摘要的方法没有任何提升(甚至出现了“负优化”)。作者认为其中的原因是可能是因为在测试期间很难预测这些信号。
同时,作者发现如果测试的时候也使用Oracle提取的指导信息,模型的效果会有很大的提升。这说明了:
- 模型具有很大的潜力,如果指导信息给得好,那么模型可以达到很好的效果;
- 模型和我们的预期相似,确实在依赖指导信号进行学习。
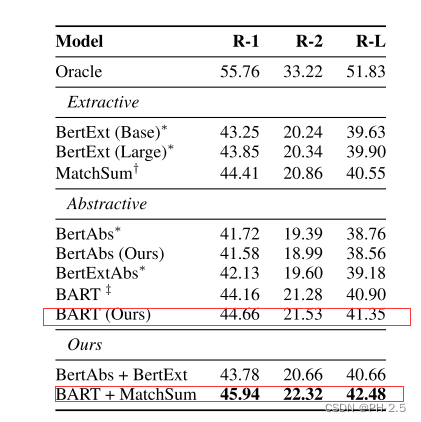
Comparisons with State of the Art
作者将这个框架用于BART模型之上,训练时候使用oracle extraction 并且测试时使用MatchSum去生成指导信息(关键句),发现这种做法对原模型有很大程度的提升。
Performance on Other Datasets
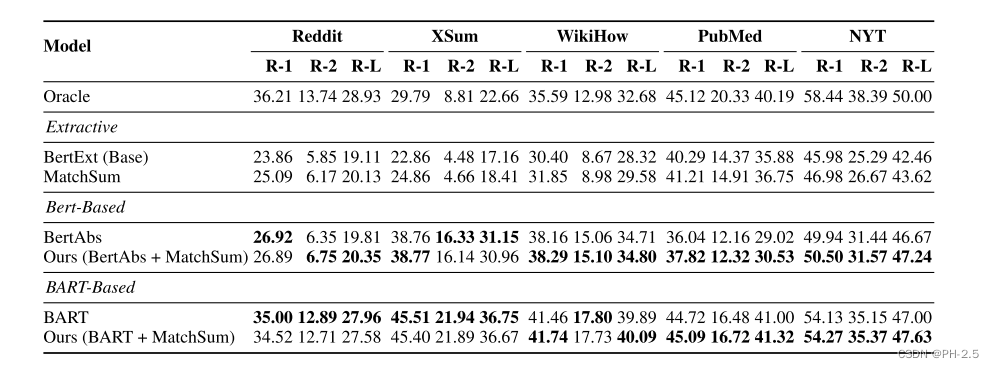
对于Reddit和XSum等抽象性数据集,本文模型无法实现性能提升。在PubMed和NYT这类抽取式摘要数据集,可以有一定程度的提升。
Analysis
虽然我们有时会提供从源文档中提取的信息作为指导信号,但目前尚不清楚模型是否会过度拟合,导致在生成摘要时只是简单地复述了这些信息,而没有进行更多的创造性处理。
为了衡量这一点,我们计算输出摘要中的新n-gram的数量即没有出现在源文档中的n-gram。
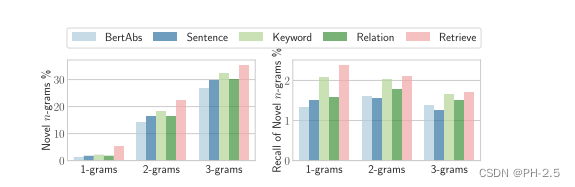
n-grams
n-grams是文本处理和自然语言处理领域中常用的概念,它是一种用于分析文本的方法。具体来说,n-grams是文本中连续的n个单词或字符的序列。这里的“n”表示一个整数,可以是1、2、3等,分别对应于单个单词、两个连续单词(称为bigrams)、三个连续单词(称为trigrams)等。
例如,对于句子 “I love natural language processing”,以下是一些不同n的n-grams示例:
- 1-grams(单个单词):[“I”, “love”, “natural”, “language”, “processing”]
- 2-grams(bigrams,两个连续单词):[“I love”, “love natural”, “natural language”, “language processing”]
- 3-grams(trigrams,三个连续单词):[“I love natural”, “love natural language”, “natural language processing”]
n-grams的使用有助于分析文本的结构和语言特征,例如在自然语言处理任务中,它们可以用于文本分类、语言建模、机器翻译等应用。在上述引文中,作者提到“novel n-grams”,意思是在生成摘要时,模型是否能够产生在源文档中没有出现过的新的n-grams序列,从而表现出一定的创造性。
Complementarity of Different Guidance Signals.
虽然一些引导信号实现比其他更差的性能,但如果它们的输出是多样的并且它们彼此互补,则仍然可以聚合它们的输出并获得更好的性能。
我们尝试为每个测试数据点选择四个引导信号的最佳输出,并研究是否可以聚合它们的最佳输出并获得更好的性能。
具体来说,对于每个测试输入,我们执行预言机实验,计算四个引导信号的每个输出的 ROUGE 分数,并选择最好的一个。
此外,通过将它们的最佳输出聚合在一起,我们可以获得 48.30/45.15 的 ROUGE-1/L 点,这明显优于任何单一引导模型。
结论:因此,我们可以有把握地得出结论,每种类型的引导信号都有其自身的优点,一个有前途的方向是利用诸如 Hong 等人的系统组合方法。
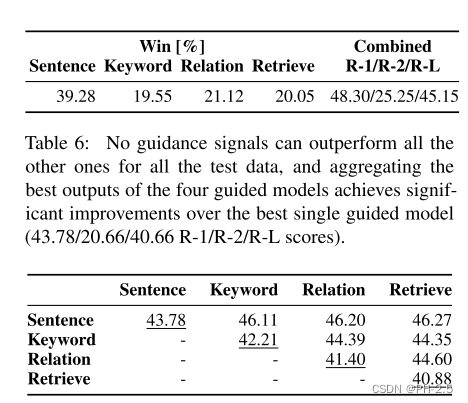
上述两个表,表6说明了,没有一种指导信号能完全的优于其他指导信号
此外,本文试图以成对的方式聚合这些指导信号,
表7说明每个指导信号在某种程度上是相互补充的。(表7的数值代表ROUGE-1这个衡量指标的值)
Necessity of Using Oracles During Training.
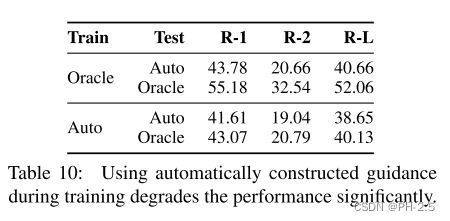
我们使用预言机在训练期间选择引导信号。在这一部分中,我们研究是否可以在训练期间为模型提供自动构建的指导。表 10 显示这种方法将导致性能显着下降。
Conclusion
我们提出了一个引导神经摘要的通用框架,使用它我们研究了四种类型的引导信号并在各种流行的数据集上实现了最先进的性能。我们展示了四种引导信号的互补性,并发现我们的模型可以生成更多新颖的单词和更忠实的摘要。我们还表明,我们可以通过提供用户指定的引导信号来控制输出。鉴于我们框架的通用性,这为未来的几个研究方向开辟了可能性,包括1)开发在不同引导信号下集成模型的策略; 2) 结合复杂的技术,例如复制或覆盖源文档、指导信号或两者; 3)尝试其他类型的引导信号,例如显着的基本话语单元。
Conclusion
本文提出了一个引导神经摘要的通用框架,研究了四种类型的引导信号并在各种流行的数据集上实现了最先进的性能。
我们展示了四种引导信号的互补性,模型可以生成更多新颖的单词还有与原文一致性更高的摘要。
我们还表明,我们可以通过提供用户指定的引导信号来控制输出。鉴于我们框架的通用性,这为未来的几个研究方向开辟了可能性,包括
- 制定在不同制导信号下集成模型的策略
- 结合复杂的技术,例如复制或覆盖源文档、指导信号或两者;
- 尝试其他类型的引导信号,例如显着的基本话语单元。
复制机制允许模型直接从输入文本中复制单词或短语到摘要中,而覆盖机制则防止模型生成重复的单词或短语。
我提出的问题
为什么在图3 测试中使用oracle提取引导信号方式的预测结果比使用自动生成引导信号方式的预测结果好很多但是文章却推荐使用自动生成引导信号的方式,还有为什么oracle 提取会比 自动生成信号更优?
作者比较了在训练过程中使用"oracle extraction"和自动预测来生成引导信号时GSum模型的性能差异。他们发现,使用"oracle extraction"可以显著提高性能,相比之下,使用自动预测性能较差。
然而,作者也指出,使用"oracle extraction"可能会成本高、耗时,因为它需要访问参考摘要或其他外部信息。相比之下,自动预测可以快速且容易实现,因为它只需要输入文本。因此,作者建议在测试过程中使用自动预测,因为这更符合实际系统的条件,实际系统通常也会接收到自动预测。
总之,虽然"oracle extraction"在训练过程中可以提高性能,但在所有情况下可能并不切实际或可行。自动预测是一种更方便且可扩展的方法,仍然可以产生高质量的结果。
















 750
750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









