






GSum: A General Framework for Guided Neural AbstractiveSummarization
Abstract
abstractive summarization模型灵活,可以生成连贯的摘要,但是有时unfaithful并且很难去控制。尽管之前的工作尝试提供不同类型的guidance来控制输出并增加faithfulness,目前仍不清楚这些策略之间如何互相对比。本文我们提出了一个通用可扩展的摘要框架:GSum,它可以采用不同类型的外部guidance作为输入,我们采用几种不同变体实施了实验。经验结果证明了模型有效,当使用关键句作为guidance时,模型在4个流行的摘要数据集上达到了sota的rouge指标。除此之外,我们展现了我们的模型可以生成更faithful的摘要,并展示了不同类型的guidance如何生成质量上不同的摘要,从而为模型提供了一定程度的可控性。
Introduction
文本摘要技术可以分为extractive methods(Nallapati et al., 2017; Narayan et al., 2018b; Zhou et al., 2018)和abstractive methods(Rush et al., 2015; Chopra et al., 2016; Nallapati et al., 2016; Paulus et al., 2018),前者在输入文档中识别最合适的词或句子,然后拼接成摘要,后者自由的生成摘要,并可以生成新的词和句子。后者比前者更灵活,因此能生成连贯的摘要。但是,后者unconstrained的特性会导致一些问题。首先,它可能导致unfaithful摘要(Kry ́sci ́nski et al., 2019),包括factual errors以及hallucinated(幻觉)content。第二,难以控制摘要内容:很难去提前选择原始文档中可以被模型触及的方面。为了解决这些问题,我们为guided abstractive summarization提出了方法:该方法提供各种类型的guidance signals,一方面约束摘要,使得输出内容与原文档偏离变小;另一方面通过提供user-specified输入允许可控性。
对于guided abstractive summarization,过去有一些工作。例如,Kikuchi等人(2016)规定了摘要的长度,Li等人(2018)提供了带有关键字的模型,以防止模型丢失关键信息,Cao等人(2018)提出了从训练集中检索和引用相关摘要的模型。虽然这些方法在总结质量和可控性方面都有改进,但每种方法都侧重于一种特定类型的指导——尚不清楚哪种方法更好,以及它们是否相互补充。
在本文中,我们提出了一个通用可扩展的guided summarization框架,它可以采用不同类型的外部guidance作为输入。与最近大多数摘要模型类似,我们的模型基于encoder-decoders,用上下文预训练语言模型初始化,包括Bert,Bart。以这作为一个强大的起点,我们进行了修改,允许模型在生成输出时同时关注源文档和guidance signals。如图1所示,我们可以在测试期间为模型提供自动提取的或user-specified guidance,以约束模型的输出。在训练时,为了鼓励模型密切关注guidance,我们建议使用oracle来选择informative guidance signals——一个简单的修改,但被证明对于有效学习guided summarization模型是必不可少的。利用这个框架,我们研究了四种类型的guidance signals:(1)在源文档中突出显示的句子,(2)关键字,(3)以(主题、关系、对象)形式出现的显著关系元组,以及(4)检索到的摘要。
我们在6个流行的摘要benchmarks上评估我们的方法。我们最好的模型,使用关键的句子作为guidance,可以在6个数据集中的4个上实现sota性能。此外,我们对不同的guidance signals进行了深入分析,并证明了它们是相互补充的,有可能将它们的输出聚合在一起,获得进一步的改进。对结果的分析还表明,我们的引导模型可以生成更准确的摘要和更新颖的单词。最后,我们证明了我们可以通过提供user-specified guidance signals去控制输出,不同的signals可以导致不同的生成质量。

Background and Related Work
Neural abstractive summarization
abstractive summarization通常接受源文档x,它由多个句子
X
1
,
X
2
,
.
.
.
X
∣
X
∣
X_1, X_2, ... X_{|X|}
X1,X2,...X∣X∣组成,把它们输入encoder生成表征,并传递给decoder,decoder每次输出一个目标词y。训练中,模型参数
θ
\theta
θ更新以最大化训练语料库中输出的条件似然:
arg
max
θ
∑
<
x
i
,
y
i
>
∈
<
X
,
Y
>
log
p
(
y
i
∣
x
i
;
θ
)
\arg \max\limits_{\theta} \sum\limits_{<x^i,y^i> \in <\mathscr{X}, \mathscr{Y}>}\log p(y^i|x^i;\theta)
argθmax<xi,yi>∈<X,Y>∑logp(yi∣xi;θ)
过去工作已经提出了一些技术来改进模型结构。例如,copy模型(Gu et al., 2016; See et al., 2017; Gehrmann et al., 2018) 允许将单词直接从输入复制到输出,coverage模型阻止模型生成重复的单词(See et al.,2017)。
Guidance
guidance可以被定义为除了源文档x外额外输入模型的一系列信号g:
arg
max
θ
∑
<
x
i
,
y
i
,
g
i
>
∈
<
X
,
Y
,
G
>
log
p
(
y
i
∣
x
i
,
g
i
;
θ
)
\arg \max\limits_{\theta} \sum\limits_{<x^i, y^i, g^i> \in <\mathscr{X,Y,G}>}\log p(y^i|x^i,g^i;\theta)
argθmax<xi,yi,gi>∈<X,Y,G>∑logp(yi∣xi,gi;θ)
在这个整体框架中,输入g的信息类型以及将这些信息合并到模型中的方法可能会有所不同。虽然有关于非神经网络guidance模型的早期尝试(Owczarzak和Dang, 2010;Genest和Lapalme, 2012),这里我们专注于神经网络模型并在表1中总结了最近的工作。
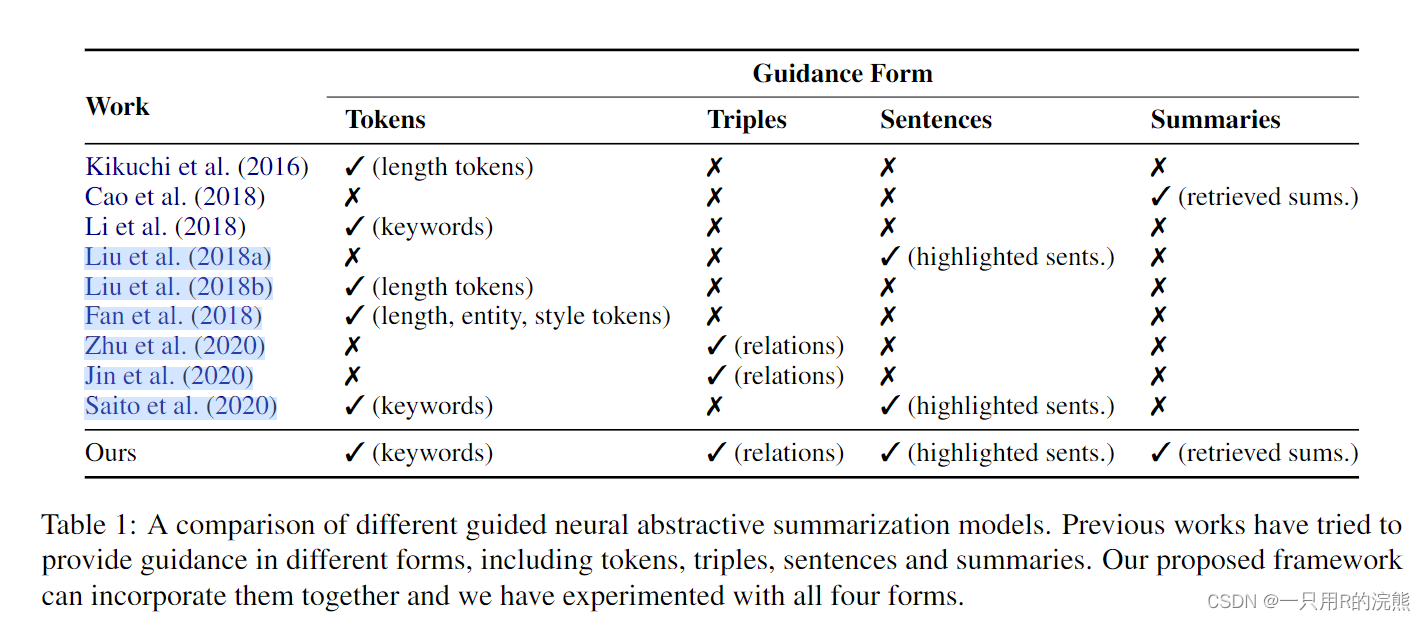
例如,Li等人(2018)首先生成一组关键词,然后通过注意力机制将其纳入生成过程。Cao等人(2018)提出搜索训练语料库,召回样本点
<
x
j
,
y
j
>
<x^j, y^j>
<xj,yj>,其中
x
j
x^j
xj与当前输入
x
x
x最相关,将
y
j
y^j
yj作为候选模板引导摘要生成。Jin等人(2020)和Zhu等人(2020)从源文档中提取(主体、关系、对象)形式的关系三元组,并用图神经网络表示。然后,解码器通过attend提取的关系以生成可靠的摘要。Saito等人(2020)的一项工作建议使用显著性模型提取关键字或突出句子,并将它们输入给摘要模型。
也有一些工作通过显示的向模型输入所需的特征来控制摘要长度(Kikuchi等人2016;Liu等人2018b)和风格(Fan等人2018)。此外,Liu等人(2018a)和Chen and Bansal(2018)采用了两阶段范式,一阶段先用一个pretrained extractor去提取原文档的一个子集
{
x
i
1
,
.
.
.
,
x
i
n
}
\{x_{i1}, ... , x_{in}\}
{xi1,...,xin}作为关键句子,然后在第二阶段把他们输入模型的encoder,并丢弃其他的文本。
Method
图2展现了模型的主要框架。我们把原文档和各种类型的guidance signals输入模型。具体来说,我们对guidance signals进行了实验,包括突出显示的句子、关键词、关系和检索的摘要,当然该框架是通用的,也可以扩展到其他类型的guidance。
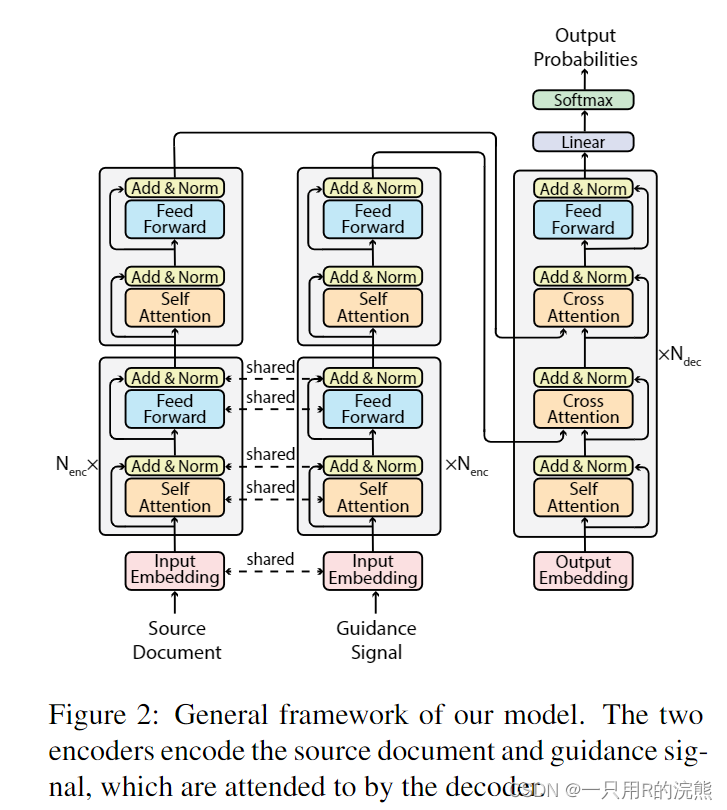
Model Architecture
We adopt the Transformer model (Vaswani et al., 2017) as our backbone architecture, instantiated with BERT or BART, which can be separated into the encoder and decoder components.
我们采取了Transformer模型(Vaswani等人,2017)作为我们的骨干结构,以Bert或Bart初始化,可以分为encoder和decoder部分。
Encoder
我们的模型有两个encoder,分别对原文档和guidance signal做encoding。
与Transformer模型类似,每一个encoder都有
N
e
n
c
+
1
N_{enc}+1
Nenc+1层,其中每层都包含一个self-attention block和feed-forword block:
x
=
L
N
(
x
+
S
e
l
f
A
t
t
n
(
x
)
)
x = LN(x+SelfAttn(x))
x=LN(x+SelfAttn(x))
x
=
L
N
(
x
+
F
e
e
d
F
o
r
w
a
r
d
(
x
)
)
x = LN(x+FeedForward(x))
x=LN(x+FeedForward(x))
这里LN表示layer normalization。注意原文档和guidance signal在encoding中并没有互相交互。
两个encoders在底部的
N
e
n
c
N_{enc}
Nenc层和embedding层share参数,因为:
- 可以减少计算和内存需求
- 我们推测原文档和guidance signals之间的差异是high-level的,这种差异会被encoders的顶层捕获。
Decoder
与标准的Transformer decoder不同,我们的decoder attend to原文档和guidance signal,而不是只attend一个输入。
具体来说,我们的decoder由
N
d
e
c
N_{dec}
Ndec相同的层组成,每一层包含4个blocks。在self-attention block之后,decoder会首先attend to guidance signals并生成对应的表征,从而guidance signal会告知decoder原文档中应该被关注的内容。然后,decoder会attend to 原文档,基于guidance-aware表征。最后,输出的表征会被输入feed-forward block:
y
=
L
N
(
y
+
S
e
l
f
A
t
t
n
(
y
)
)
y = LN(y+SelfAttn(y))
y=LN(y+SelfAttn(y))
y
=
L
N
(
y
+
C
r
o
s
s
A
t
t
n
(
y
,
g
)
)
y=LN(y+CrossAttn(y,g))
y=LN(y+CrossAttn(y,g))
y
=
L
N
(
y
+
C
r
o
s
s
A
t
t
n
(
y
,
x
)
)
y=LN(y+CrossAttn(y,x))
y=LN(y+CrossAttn(y,x))
y
=
L
N
(
y
+
F
e
e
d
F
o
r
w
a
r
d
(
y
)
)
y=LN(y+FeedForward(y))
y=LN(y+FeedForward(y))
理想情况下,第二个cross attention block允许模型填充输入guidance signal的细节,比如通过搜索共同引用链来查找实体的名称。
Choices of Guidance Signals
在深入研究我们所使用的guidance signal类型的细节之前,我们首先要注意训练模型时一个重要细节。在test阶段,有两种指定guidance signal的方法:
- 人工指定:感兴趣的用户手动指定signal
- 自动预测:使用自动化系统从输入中推断出guidance signal
我们在实验中阐述两种方法的结果。
在训练阶段,获取人工guidance的成本往往很高,因此我们关注两种生成他们的方式:
- 自动预测:同上文
- oracle extraction:使用x和y来推导一个在生成y时最可能有用的值g
理论上,自动预测具有与系统的训练和测试条件相匹配的优势,该系统在测试时也将接收自动预测的结果。然而,正如我们将在实验中展示的那样,使用oracle guidance有一个很大的优势,即生成信息高度丰富的guidance signals,从而鼓励模型在测试时更加关注这些信号。考虑到这一点,我们描述了我们实验的四种guidance signal,以及它们的自动和oracle提取方法。
Highlighted Sentences
抽取式方法的成功表明了我们可以从原文档中提取句子的子集
{
x
i
1
,
.
.
.
,
x
i
n
}
\{x_{i_1}, ..., x_{i_n}\}
{xi1,...,xin}并把它们拼接在一起组成摘要。受此启发,我们使用抽取模型显式地告诉我们的模型源句子中的关键子集。
我们基于greedy search算法(Nallapati等人,2017;Liu and Lapata,2019)做oracle extraction,以发现与reference(细节见Appendix)有最高ROUGE得分的句子子集,并把它们作为guidance g。在test阶段,我们使用pretrained extractive 摘要模型(BertExt(Liu and Lapata,2019)或者Match-Sum(Zhong等人,2020))来进行自动抽取。
Keywords
如果我们选择完整的句子,它们可能包含摘要中没有出现的不重要信息,这会分散模型对输入中期望部分的关注。因此,我们也尝试用一系列原文档中的关键词
{
w
1
,
.
.
.
w
n
}
\{w_1,...w_n\}
{w1,...wn}作为输入。
对于oracle extraction,首先使用上面提到的greedy search算法选择输入句子的子集,然后使用TextRank(Mihalcea and Tarau,2004)从这些句子中提取keywords。我们也剔除了不在目标摘要中的keywords。对于自动预测,我们使用另一种神经网络模型(BertAbs(Liu and Lapata,2019))去预测目标摘要中的keywords。
Relations
Relations通常以关系三元组的形式表示,每个三元组包含一个主语、一个关系和一个宾语。例如,”Barack Obama was born in Hawaii“对应一个三元组(Barack Obama,was born in,Hawaii)。
对于oracle extraction,我们首先使用Stanford OpenIE (Angeli等人,2015)从原文档中提取关系三元组。与我们选择高亮句子的方式类似,我们随后greedily选择一组与reference的ROUGE分数最高的关系,然后将其flatten并作为guidance。对于自动预测,我们使用另一个神经模型(类似的,BertAbs)来预测目标侧的关系三元组。
Retrived Summaries
直觉上,对于输入文档,其相似文档的gold摘要可为引导式摘要生成提供参考。因此,我们也尝试从训练集
<
X
,
Y
>
<\mathscr{X,Y}>
<X,Y>中检索相关摘要。
对于oracle extraction,我们使用Elastic Search直接从训练集中检索五个数据点
{
<
x
1
,
y
1
>
,
.
.
.
,
<
x
5
,
y
5
>
}
\{<x_1,y_1>,...,<x_5,y_5>\}
{<x1,y1>,...,<x5,y5>},这些数据点的
y
i
y_i
yi与目标摘要
y
y
y最相似。对于test阶段的自动预测,我们检索5个数据点,它们的原文档
x
i
x_i
xi与每个输入原文档
x
x
x最相似。
Experiments
Datasets
我们在6个数据集上进行实验(统计数据见表2)
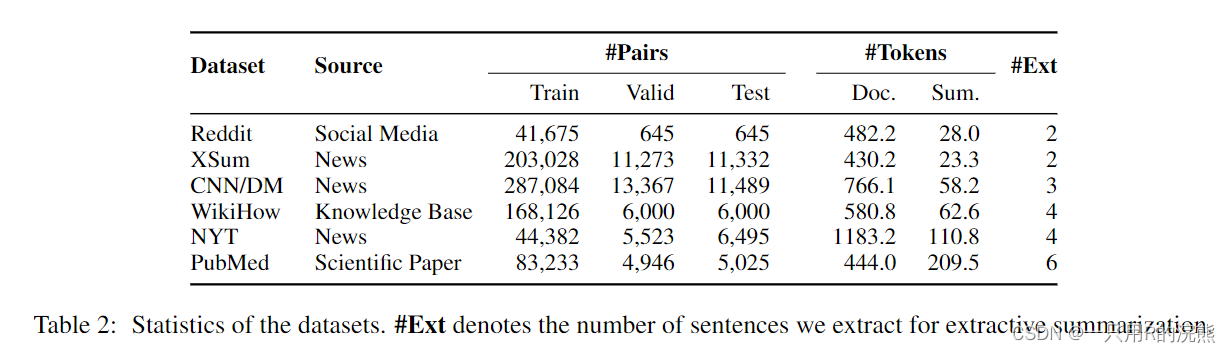
- Reddit(Kim等人,2019)是一个highly abstractive数据集,我们使用它的TIFU-long版本。
- XSum(Narayan等人,2018a)是一个abstractive数据集,包含BBC线上文章的一句话摘要。
- CNN/DM(Hermann等人,2015;Nallapati等人,2016)是一个广泛使用的摘要数据集,包含新闻文章和相关的高亮作为摘要。我们使用它的non-anonymized版本。
- WikiHow(Koupaee and Wang,2018)是从在线知识库提取的数据集,具有high level abstraction。
- New York Times(NYT)(Sandhaus,2008)是一个包含新闻文章和摘要的数据集。我们按照(Kedzie等人,2018)的做法split数据集。
- PubMed(Cohan等人,2018)是从科学论文中收集的extractive数据集。
Baselines
我们的baselines包含下面的模型:
- BertExt(Liu and Lapata,2019)是一个extractive模型,参数用Bert(Devlin等人,2019)初始化。
- BertAbs(Liu and Lapata,2019)是一个abstractive模型,encoder使用Bert初始化,并用和decoder不同的优化器。
- MatchSum(Zhong等人,2020)是一个extractive模型,它rerank BertExt产出的候选摘要,在多个摘要数据集上达到sota。
- BART(Lewis等人,2020)是一个sota abstractive模型,使用denoising自编码目标函数做预训练。
Implementation Details
我们的模型基于BertAbs和BART,并按照它们的超参数设置训练摘要。对于基于BertAbs的莫i选哪个,有13个encoding层,两个encoder的最上面一层单独训练。对于基于Bart的模型,有24个encoding层,两个encoder的最上面一层单独训练。decoder的第一个cross-attention block随机初始化,第二个用预训练参数初始化。BertAbs被用来在test阶段预测relations和keywords的guidance signals。除非特殊说明,我们在training阶段使用oracle extractions。
Main Result
我们首先使用BertAbs在CNN/DM数据集上对比不同的guidance signals,然后使用BertAbs和BART在其他五个数据集上评估最优的guidance。
Performance of Different Guidance Signals
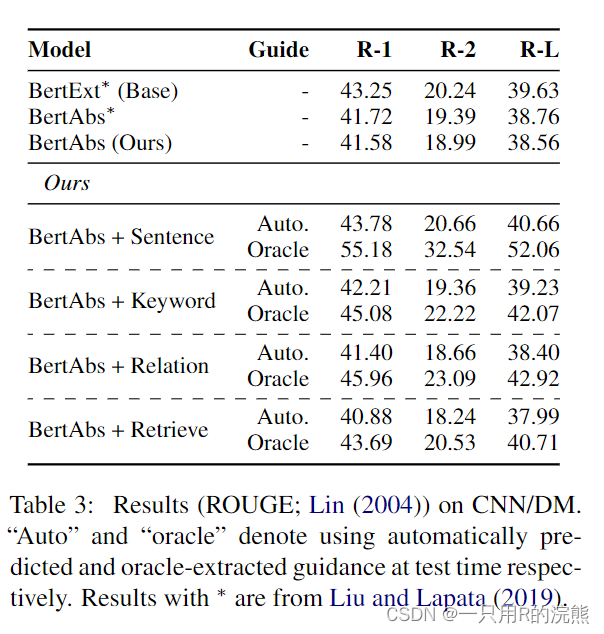
如表3所示,如果我们用自动预测signals输入模型,无论是用高亮句子或keywords都可以超出abstractive摘要模型baseline很大的幅度。特别的,将高亮句子作为guidance可以在ROUGE-L指标上超出最好的baseline 1个点。使用relations或者retrieved摘要作为guidance不能提升效果,这可能是因为在test阶段很难预测这些signals。
如果我们使用oracle去选择guidance signals,所有类型的guidance都可以显著提升模型表现,其中最好模型的ROUGE-1达到了55.18。这些结果表明:
- 给定更好的guidance预测模型,模型表现有进一步提升的潜力。
- 模型确实学会了依赖guidance signals。
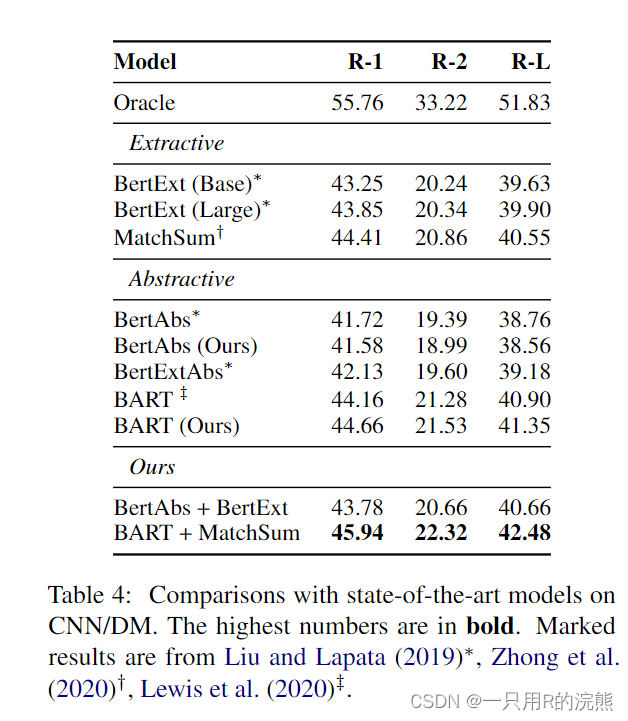
Comparisons with State of the Art
然后,我们尝试在sota模型基础上构建模型,因为高亮句在CNN/DM数据集上达到了最好的表现,因此使用它作为guidance。首先,我们基于BART搭建模型,并在训练中使用oracle extracted高亮句作为guidance。然后在test阶段,我们使用MatchSum预测guidance。从表4中可以看出我们的模型与sota模型相比,在ROUGE-1/L指标上提升了一个点,这表明了我们提出的模型的性能。
Performance on Other Datasets.
未完-待续

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









