







性能指标
| 名词 | 描述 | 衡量标准 |
|---|---|---|
| QPS | Queries Per Second,每秒查询数。每秒能够响应的查询次数 | QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准,在因特网上,作为域名系统服务器的机器的性能经常用每秒查询率来衡量。每秒的响应请求数,也即是最大吞吐能力。 |
| TPS | Transactions Per Second 的缩写,每秒处理的事务数目 | 一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数,最终利用这些信息作出的评估分。 TPS 的过程包括:客户端请求服务端、服务端内部处理、服务端返回客户端。 |
| PV | (page view)即页面浏览量 | - 指一天内网站的浏览次数,它是衡量网站用户访问页面的数量。 - 特点: 用户每打开一个页面就记录一次,就算访问同一页面多次,就记录多次 |
| UV | 访问网站的用户 | - 指一天内访问某站点的人数,以cookie/客户端为依据 - 特点: 一天内,同一访问用户的多次访问只记录1次 |
| IP | (Internet Protocol)独立 IP 数 | - 指一天内使用不同IP地址的 - 用户访问网站的数量。 特点: 同一个IP无论访问多少网页,独立IP数均为1 |
| GMV | Gross Merchandise Volume 的简称 | 只要是订单,不管消费者是否付款、卖家是否发货、是否退货,都可放进 GMV |
| RPS | 代表吞吐率,即 Requests Per Second 的缩写 | 吞吐率是服务器并发处理能力的量化描述,单位是 reqs/s,指的是某个并发用户数下单位时间内处理的请求数。 某个并发用户数下单位时间内能处理的最大的请求数,称之为最大吞吐率。 |
| DUA | 日活 | 通常统计一日(统计日)之内,登录或使用了某个产品的用户数(去除重复登录的用户),这与流量统计工具里的访客(UV)概念相似。通常DAU会结合MAU(月活跃用户数量)一起使用,这两个指标一般用来衡量服务的用户粘性以及服务的衰退周期 注意:可以是启动UV、登录UV、发生了特定行为的UV |
根据 DAU 估算流量和容量的一般思路:
以 DAU = 1000w 为例:
| 指标 | 公式 | 描述 |
|---|---|---|
| PV | PV=DAU*10 | PV = 1000w*10 = 1亿 |
| 均值QPS | 访问量/时长 | 1亿/(246060) = 1160 |
| 峰值 QPS | 均值QPS*10 | 按照均值的10倍预估 = 11600,考虑到静态资源流量的放大效应,按照放大10倍计算,系统峰值 QPS = 116000 |
| 容量 | 峰值 QPS*2 | 考虑高可用、异地多活等策略,容量x2,QPS = 232000未来发展按照未来半年业务增长1.5倍计算,最终QPS=232000*1.5=348000 |
营销消息推送
2021/5-2022/2 必要商城营销消息推送平台(必要科技) 迭代/优化/维护/重构
开发环境:jdk8、Linux、docker、Mysql、zk、apollo、es、k8s
后端技术:SpringBoot、dubbo、mybatis、es、RocketMQ、spi、elastic-job、Pebble、redis、FastDFS
项目描述:营销主要表现于营销活动促使用户购买和营销消息推送提高用户回访复购能力。营销消息推送关注跟谁推、推什么、推到哪儿、怎么推,由营销任务中心、必要通知、客户关系服务、用户活动中心、变量服务和营销控制台以及各涉及营销相关的服务等组成。
| 系统 | 描述 |
|---|---|
| 客户关系(crb) | 后台管理系统,供运营人员创建配置营销任务,功能主要包括必要通知(业务/场景/时机、渠道模板、业务模板、变量管理等)、营销任务管理、营销工具管理(短链生成、营销策略、营销活动、用户群、用户行为优先级)、规则配置管理(互斥、优先级、免打扰等)、用户及权限管理。 |
| 营销任务中心(mmc) | 主要执行营销消息推送任务,通过后台可配置营销策略、用户群、推送时间、业务模板、渠道等绑定关系生成营销活动,通过定时扫描生成完成营销消息推送工作。功能主要包括营销任务、用户群拉取、营销策略、全量push等。 |
| 必要通知(bns) | 根据携带的策略信息为用户推送消息。基于推送策略引擎决定全局策略、行为过滤、渠道选择、三方处理;基于消息组装引擎生成文案;基于消息限制引擎决定消息如何处理,基于分布式锁保证给用户推送的幂等性; |
| 用户活动中心(uca) | 同步用户行为数据到ES用于用户行为数据搜索。基于责任链模式生成用户行为时机链路,基于spi处理链路,实现用户行为匹配引擎,为用户绑定不同的营销推送策略,进而达到千人前面的推送效果,如行为偏好、福利触达、商品推荐、推荐好友等相关业务下场景时机策略。 |
| 变量服务(vbc) | 营销消息的一些动态信息在各业务系统,基于spi对接各服务,根据时机编码实现对目标服务的调用,用于获取文案中的站位信息。 |
| 必要公益(pis) | 主要用于地震预警,位于必要商城app我的菜单下,用户开启预警开关后,定时采集用户地理位置信息,地震局基于netty将探测到的地震预警信息推送到pis,进而推送给震源附近的用户。功能主要包括地震资讯列表、地震资讯详情、预警开关、白名单、以及演习预警。 |
责任描述:
1.业务学习,日常维护,定位线上问题,给出解决方案并落地
2.迭代开发,优化代码,增加代码可读性和扩展性
3.日常监控,分析监控现象原因,给出可优化方案
4.业务熟悉后,基于现有问题和核心业务指定重构方案并落地
5.主要从业务架构、中间件(reids和ES)、异步编程、线程池模型、JVM调优进行优化
成 果:系统性能、稳定性显著提升,代码可读性、业务边界清晰化
优化点
优化的目的:解决发现问题,不影响正常功能的前提提升性能和代码可读性
主要从业务架构、中间件优化(reids和ES)、异步编程、线程池模型、JVM调优
| 优化点 | 问题 | 优化措施 |
|---|---|---|
| Redis | zset数量大检索 大key删除 | 导致主从切换问题(大用户群删除+用户群检索) 1、zset替换 2、大key拆分 |
| ES | 历史索引规划问题 | 重新索引规划 单索引->按天生成索引->按周生成索引->按月生成索引 |
| for循环查询数据 | 批量检索 | |
| JVM | JVM频繁内存阈值报警 | JVM频繁内存阈值报警,监控发现频繁yonggc 1、跳转新生代和老年的比例 2、任务接触主动触发一次fullgc |
| 线程池模型 | 串行处理用户 | 串行处理用户->批量处理->输出中间状态数据 |
| 核心业务优化 | 行为链路串行处理 | 行为链路处理优化->预处理方案 + 批量处理方案 |
业务模型优化
业务概述
- 目的给用户推消息
- 每个用户都有时机链路
- 时机链路按照优先级排列
- 不用时机都有一个实现
- 按照链路顺序,满足的第一个推送,不满足或推送失败则推送下一个时机节点
限制与目标–性能要提升6倍以上
- 当前3h推送250w用户
- 目标1h推送500h用户
优化前模型
自己处理出来的模型,才进公司没有
 优化点:
优化点:
- 时间链路处理比较耗时,子线程串行处理,可优化为批处理或预处理
- 数据准备和数据处理串行,可预处理
线程池优化

预处理线程池:数据预处理(批量)
执行引擎线程池:到执行执行无需再执行耗时的操作
数据预处理

数据准备线程池抽离在营销活动任务之前就将公共数据准备好执行引擎线程池在营销任务时间开始执行,直接拿准备好的数据执行合理利用不同时间的CPU资源,压力分摊到空闲时间
时机链路相同特性的用户放在一起批处理,具体落地实现营销消息推送优化 密码:pXuo
优化后模型

消息推送引擎=推送策略引擎+消息组装引擎+推送限制引擎+延时队列
- 推送策略引擎:全局策略、行为过滤、三方策略、渠道策略
- 消息组装引擎:根据不同策略携带的时机可获取与其绑定的业务模板、变量站位符等进而获取消息相关信息,基于模板引擎技术,生成消息文案
- 推送限制引擎:限制载体主要分为用户、营销活动、消息、时间
- 延时队列:决定什么时候推送出去
- 消息渠道处理引擎:策略模式集成不同渠道,将消息推送到不同渠道
用户行为匹配引擎设计
用户行为匹配引擎设计=行为树+用户行为匹配过滤器+行为扩展点+行为树链路转化器
用户行为确定:即是某个业务场景时机下确定的行为
行为数据分为静态离线数据和实时数据,其中行为偏好为静态数据(前一天的离线数据)
行为匹配引擎由时机链路组成,通过用户群携带的用户标签确定业务场景时机树(顺序根据行为优先级而定),经过过滤器确定时机链路,通过spi最后组装信息发送策略
用户行为匹配过滤器
- 从udc获取用户最后一次发送的时机,判断是否给用户发送过不活跃消息
- 未发送过不活跃消息:无需过滤
- 发送过不活跃消息:需过滤,根据从ES查询用户单击过的消息确定(用户点击消息时机集合,时间正序)(优化:倒序判断)
- 未点击过(集合空):
- 点击过:获取最后点击时机码(点击消息集合中匹配到的行为树最后时机)
- 时机码存在:时间链路舍弃,由该时机组成单时机链
- 否则,过滤用户最后一次发送的时机
必要通知(bns)消息规则引擎

批量数据提交
优化前1w一个批次提交,为什么?没有依据
单次批处理的数据大小应从 5MB~15MB 逐渐增加,当性能没有提升时,把这个数据量作为最大值。
BulkProcessor 提供了批量写策略:
此processer的含义为如果消息数量到达1000 或者消息大小到大5M 或者时间达到5s 任意条件满足,客户端就会把当前的数据提交到服务端处理。效率很高
这个数量应该设置多少,可以根据计算下元素大小评估下
查询优化(改为批量)
用户行为匹配引擎中,从es查询了单个用户点击行为,
测试环境:模拟100G用户行为数据,测试查询200w用户,测试如下两个模型:

性能差距在30倍以上,改为批量查询后,设计两种改动方式:
- 行为匹配引擎中耦合了该查询,改成批量用户行为匹配引擎(详细看设计优化)
- 解耦,将该方法抽离出行为匹配引擎,提前预热数据到redis
JVM调优(mmc营销中心)
营销消息推动系统调优原则:在最大吞吐量优先的情况下,降低停顿时间
优化背景:mmc站点jvm内存使用到达80%或90%的阈值,频繁邮件报警
线上JVM情况

根据启动参数-Xms6144m -Xmx6144m,堆空间初始化分配6144m,最大分配6144m=6G
默认:新生代:老年代=1:2 = 2G:4G
监控情况

- Young Gc后内存清理1.8G左右
- fullGc后内内存清理1.8G左右
- 每次营销推送任务周期进入老年代对象1.7G左右
| 现象 | 措施 |
|---|---|
| Young Gc很频繁 | 调大新生代比例 |
| full gc频率V-WS-105-96比较频繁 | 该机器内存资源过少,可增加机器内存资源,调节参数-Xms6144m -Xmx6144m,堆空间初始化分配6144m,最大分配6144m=6G |
| 每台机器最低堆内存差距比较大 | 这两点可能产生原因是数据倾斜,每台机器处理的数据量存在差异 结论:经过分析存在任务分配不均的情况,如有的任务只在某个节点执行或分部不均很 |
| 每台机器最高堆内存差距比较大 | |
| 第4-5次任务频繁报警,第6次fullgc 那么fullgc频率 15-18天左右 | 每次任务执行完成,显示调用System.gc()触发FullGC,保证任务执行期间不会FullGC |
优化方案
结论:mmc调大新生代,每个任务周期结束可System.gc()触发FullGC
显示调用System.gc()触发FullGC:
每次任务执行完成,显示调用System.gc()触发FullGC,保证任务执行期间不会FullGC
调整新生代和老年代比例,增大新生代比例(首选):
线上采用java8默认的配置,新生代:老年代=1:2。增大新生代比例,会降低YongGc频率,增大FullGC频率,如何调节?目标任务执行期间不FullGC,尝试将比例一点一点调节大,监控观察。将老年代调小需要注意一个问题,就是程序产生的最大对象问题,不然会导出内存溢出问题。
垃圾回收器修改为G1:
营销消息推送的目的是尽快的将消息推送出去,并无用户主动交互,吞吐量和停顿时间选择吞吐量优先,那么必然需要降低内存回收的执行频率,但是这样会导致GC需要更长的暂停时间来执行内存回收。但是除了营销任务消息推送,存在其他何种与用户交互的场景,如登录验证码,由于消息推送站点在bns,故而bns采用C1,mmc还是采用Po+Ps
堆优化(调节后续观察的优化方式,参考):
Java整个堆大小设置,Xmx 和 Xms设置为老年代存活对象的3-4倍,即FullGC之后的老年代内存占用的3-4倍。
方法区(永久代PermSize和MaxPermSize或元空间MetaspaceSize和MaxMetaspaceSize)设置为老年代存活对象的1.2-1.5倍
年轻代Xmn的设置为老年代存活对象的1-1.5倍:
老年代的内存大小设置为老年代存活对象的2-3倍
Bns之JIT优化:
一次营销任务(核心任务不活跃用户召回)就要跟百万/千万的用户发送消息,一个批次500也要调用bns批量发送方法2000至20000次以上,由于server模式下JIT编译执行10000次才触发,导致有时用到有时用不到,而任务周期3天一次又过半衰弱周期,周而复始。
通过-XX:ComplieThreshold设置阈值,调小如100。考虑其他系统的调用频率,基本都是都是根用户交互相关,考虑日活不过20W,首页QPS估计在8.12(跟用户交互,首页QPS算个极值考虑),计算是触发JIT编译阈值??卡在阈值计算了,考虑到其他系统调用的不是批量方法,不影响。
Redis优化
| Redis版本 | 部署架构 | 内存 | 缓存淘汰策略 |
|---|---|---|---|
| 3.2.3 | 一主一从三个哨兵 | 16G | allkey-lru |
redis参数:
问题及方案
营销任务zset深度分页导致redis主从切换
营销任务执行时,会从redis中zset获取分页用户信息,而zset中用户信息数据量在500w以上,zset底层用的跳跃表时间复杂度O(logN)。由于redis是单线程,从zset获取分页用户数据超时,哨兵节点任务master宕机,进行主从切换
| 解决方案 | 优点 | 缺点 |
|---|---|---|
| 加长心跳检查时间 | 短期内没时间优化的备用方案 | 没解决根本问题,心跳时间修改为多少没发很好评估 |
| zset修改为list | 数据分片时间复杂度O(1) 查询 | 查询时间复杂度O(n) |
| zset修改为list+布隆过滤器 | 数据分片时间复杂度O(1) 查询 | 不适合查询用户具体信息,查询具体信息可使用源头数据(zset的用户数据从BI拉取缓存的) |
| 查询是否存在时间复杂度O(1) | ||
| 拆分zset(拆分用户群) | 改动小,短期内解决问题 | 加大系统熵,没解决用户增长的根本问题,用户量增加后,拆分后用户群依然大 |
短期方案选择:拆分zset(拆分用户群)
长期方案选择:zset修改为list+布隆过滤器
大key删除导致主从切换
| 解决方案 | 优点 | 缺点 |
|---|---|---|
| 加长心跳检查时间 | 短期内没时间优化的备用方案 | 没解决根本问题,心跳时间修改为多少没发很好评估 |
| redis版本升级到4之后 | 不用改动代码 | 公司部署架构没办法做到平滑技术组件升级,只能另外部署一套,部署和数据迁移成本高 |
| 渐进式删除 | 不用过多修改代码 | 不能解决zset深度分页导致主从切换问题 |
| 拆分用户群(大zset拆成小zset) | 改动量适中,也能解决zset深度分页问题 | 加大系统熵,没解决用户增长的根本问题,用户量增加后,拆分后用户群依然大 |
短期方案选择:拆分zset(拆分用户群)
长期方案选择:zset修改为list+布隆过滤器
存储数据结构优化分析
用户群存储数据结构优化
| 对比 | 数据结构 | 时间复杂度 | 空间复杂度 | 数据量 |
|---|---|---|---|---|
| 原来结构 | Zset | O(logn) | O(N)(跳表额外空间消耗) | 百万/千万级别 |
| 1、用户群预热,从Mogodb分批拉取放入zset,会频繁更新索引,性能消耗 2、使用时采用zrangebyscore进行数据分片,时间复杂度O(log(N)+M),导致慢查询,从而redis主从切换。M为偏移量,实际分片500一批,N/500,最后时间复杂度log(N)+M的N/500次方,会导致主从切换 | ||||
| 优化结构 | list | O(N) | O(N) | 百万/千万级别 |
| 1、list的pop时间复杂度O(1),解决Zset数据分片的消耗,和大key删除造成的redis主从切换问题 |
用户推送幂等存储结构优化
不活跃用户消息推送场景,需保证推送幂等,允许部分用户没有推送到
什么样的场景必须精确推送?与用户紧密相关的信息,如用户修改了密码,需要精确推动给用户
| 幂等对比 | 数据量 | 存储数据 | 1kw数据占用内存 |
|---|---|---|---|
| 分布式保证 | 百万/千万级别 | key:任务id+用户id(10位) value:用户id(六字符) | 100m左右内存 |
| 布隆过滤器 | 百万/千万级别 | bit位 | 9m |
1、布隆过滤器与任务id绑定,设置过期时间(1天),误判率0.01,需要950w位(9m左右)
2、每天拉取用户群预热新的布隆(删除原来,创建新的)
3、数据量临界值95w左右,95w下分布式锁方案占用内存小,且精确;95w以上,布隆过滤器内存使用小
地理位置信息存储优化
必要公益(Pis)为地震源附近(根据震级和烈度,计算最大震中距)用户发送提示消息。
| 对比 | 一致性问题 | 性能问题 |
|---|---|---|
| es存储经纬度 (优化前) | 用户开启GPS后,必要商城会定时上传用户位置,保存在ES中。用户关闭GPS,不应该想用户推送地震报警信息。可能发生问题,地震发生在用户最后一次上传地理位置的地方,但是用户此时关闭了GPS,确收到了预警信息。 | 根据震级和烈度,计算最大震中距 |
| redis中的geo (优化后) | ttl过期时间解决 | reids GEORADIUS 以给定的经纬度为中心, 返回与中心的距离不超过给定最大距离的所有位置元素 |
ES优化(uca用户中心)
es集群情况
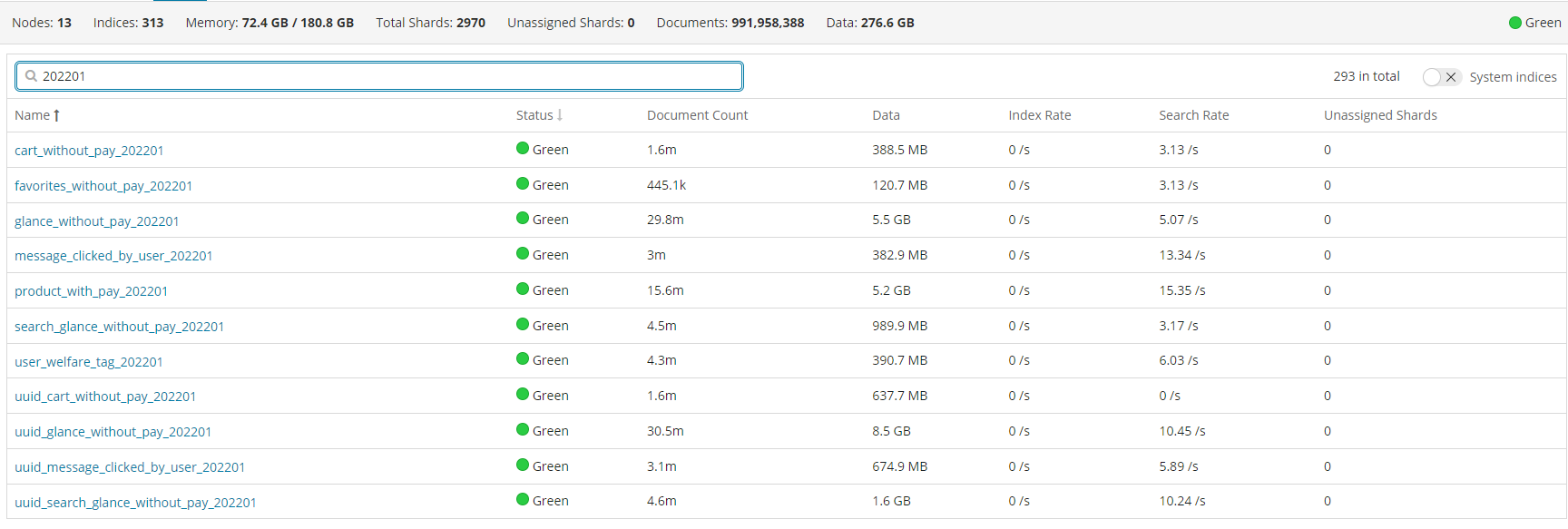

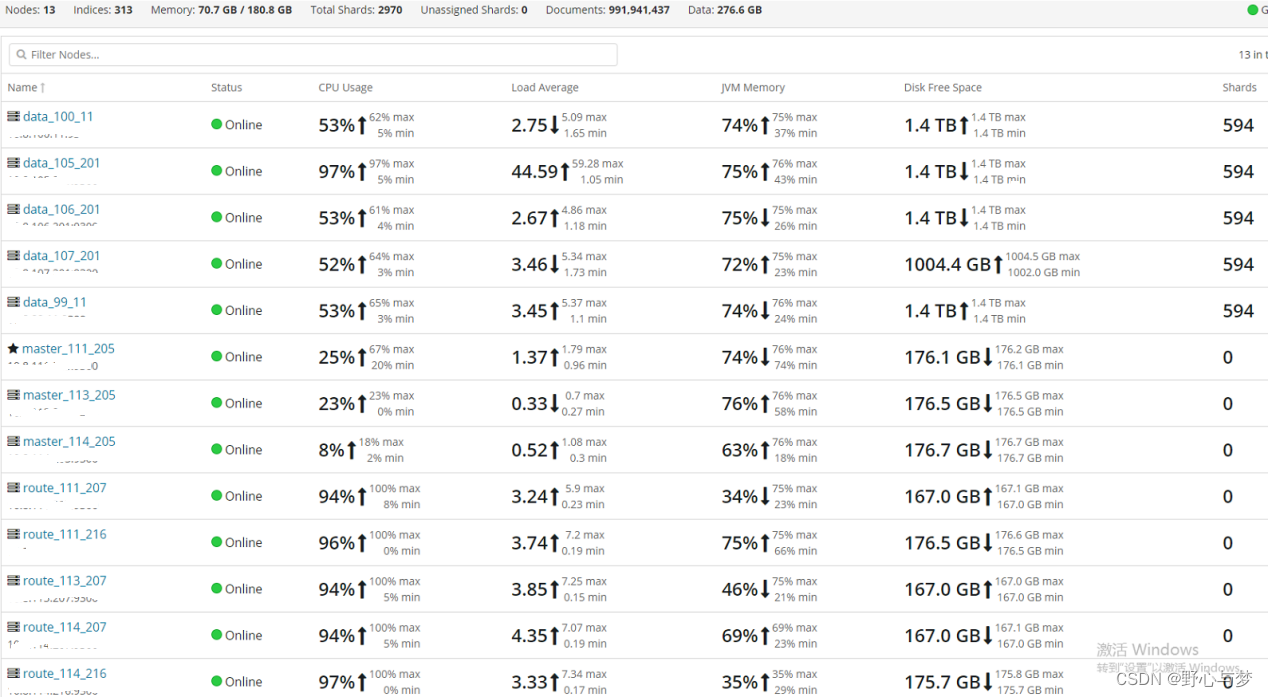



索引优化分析
历史规划性能分析: 查询时间范围2个月
| 索引规划 | 索引个数 | 索引大小 | 总推送速度 | 单个索引推送 |
|---|---|---|---|---|
| 1个索引 | 1个索引 | 200Gb/索引 | 200w/h | 200w/h |
| 按天生成索引 | 60个索引 | 50mb/索引 | 60w/h | 1w/h |
| 按月生成索引 (规划) | 2-3索引 | 3-4.5g /索引 | 保守估计 193-195.4 w/h | |
| 影响因素 = 索引数量 + 索引大小 不考虑索引数大小,索引数量影响情况:(200-60)/60 = 2.33 w/h |
影响比重计算分析:
假设查询两个月数据,从1个索引多按月60个索引,根据ES工作机制索引影响
- 不考虑索引大小的情况:时间复杂度加大60倍,性能下降60倍应该为200/60=3.33 w/h
- 但是此时推动速度为60w/h:60w/h>3.33 w/h,说明索引变小后对查询效率是有优化的,比重计算:60/3.3=18
- 那么影响因素比重 =索引数量:索引大小 = 60:18 = 10:3
优化规划性能分析计算
| 对比分析 | 以1个索引参考 | 以按天索引参考 |
|---|---|---|
| 索引数量影响 | 下降:(2-3)* 2.3w/h = 4.66-7 w/h | 提升:(57-58)* 2.3w/h =** 132.81-135.14 w/h** |
| 索引大小影响 | 提升:(200-(3到4.5))*0.6 = 117.3-118.2 w/h | 下降:(3-4.5)*0.6 = 1.8 - 2.7 w/h |
| 总体提升 | 200-(4.66-7)+(117.3-118.2)=310.3 -313.54 w/h | 60-(1.8 - 2.7)+(132.81-135.14)=190.11 -193.34 w/h |
综合推送速度估计:190.11 w/h - 313.54 w/h
由于静态考虑,保守估计上下载波动一半:95w/h-450w/h
segment 优化
那么有哪些途径减少data node上的segment memory占用呢? 总结起来有三种方法:
| 方案 | 描述 | 落地实施 |
|---|---|---|
| 删除不用的索引 | 每个月初删除往前数第三个月的月数据索引 | |
| 关闭索引 | 文件仍然存在于磁盘,只是释放掉内存,需要的时候可以重新打开 | 关闭三个增量索引中不使用的索引(索引大),kibana监控飙到了没分钟近10w 注意:跟运营确定没用后关闭 |
| 定期对不再更新的索引做optimize | 这Optimze的实质是对segment file强制做合并,可以节省大量的segment memory | segment 归并优化,在每天拉取消息中心用户行为数据后执行 |















 2044
2044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









