









KNN 与 KMeans 的区别
我们首先要明确,KNN 与 KMeans 是完全不同的算法,也许有初学者(像我这样的)会感觉两者很像,甚至不知道有什么区别。但是,这两者是有本质区别的!
1、 KMeans 是一种无监督算法,而 KNN 是一种有监督的算法。
2、 KMeans 是先用所有样本训练出一个模型,然后给出预测样本点,根据模型给出预测。而 KNN 则并不预先用已知样本训练模型,而是在用户给出一个所要预测的样本点时,从所有训练样本中搜索出 K 个与预测样本“最近邻”的样本点,并根据给定的预测规则(如多数投票原则),来判定预测样本所属哪个类别。
3、KMeans 是一种聚类算法,而 KNN 是一种分类算法。
4、KMeans 中 K 的含义:K 是一个人工给定的数字,假设数据可以分为 K 个簇,需要一些先验知识。KNN 中的 K :找出所要预测的样本附近最近的 K 个数据点,是人工指定的,当然也可以进行交叉验证来确定最佳参数,不需要先验知识。
KNN 算法的几个关键点
如何进行距离度量:
在机器学习中,常用的距离度量方式有:欧氏距离(L2),曼哈顿距离(L1),余弦距离 以及 切比雪夫距离。 在 KNN 中常用欧式距离。
K值如何进行选择:
K值过小:抗噪能力差,容易产生过拟合。
K值过大:分类误差会增大,容易产生欠拟合。
我们一般用交叉验证来确定最佳K值。
最终的分类决策规则:
通常为多数表决规则。
代码:
先来两张矩阵运算的照片:

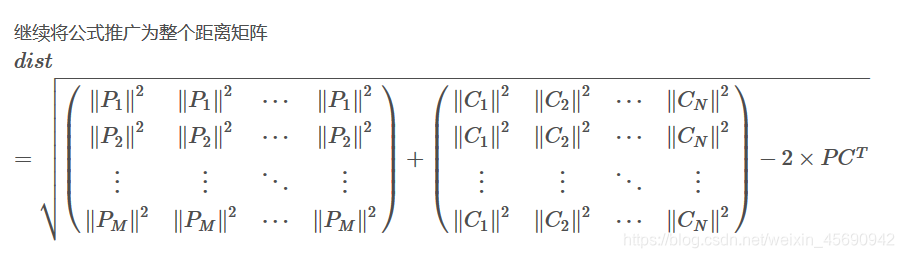
# -*- coding: utf-8 -*-
"""
Created on Sun Jun 28 20:37:52 2020
@author: Lenovo
"""
import numpy as np
from collections import Counter
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.utils import shuffle
plt.rcParams['figure.figsize'] = (10.0, 8.0)
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
iris=datasets.load_iris()
X, y = shuffle(iris.data, iris.target, random_state=13)
X = X.astype(np.float32)
# 训练集与测试集的简单划分
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=42)
y_train=y_train.reshape(-1,1)
y_test=y_test.reshape(-1,1)
print('X_train=', X_train.shape)
print('X_test=', X_test.shape)
print('y_train=', y_train.shape)
print('y_test=', y_test.shape)
def compute_distances(X):
#这个compute函数是计算预测矩阵与样本矩阵的距离的,因为涉及矩阵运算,如果写for循环太费时费力
#所以采用这种矩阵运算的方式,X^2+Y^2-2XY
num_test = X.shape[0]
num_train = X_train.shape[0]
dists = np.zeros((num_test, num_train))
M = np.dot(X, X_train.T)
te = np.square(X).sum(axis=1)
tr = np.square(X_train).sum(axis=1)
# 这个 np.matrix(te).T 和 te.reshape(-1,1) 应该是一样的
# 用这两个哪个形式都会报一个警报:
# RuntimeWarning: invalid value encountered in sqrt
# 不过不影响结果和程序的正常运行
dists = np.sqrt(-2 * M + tr + te.reshape(-1,1))
return dists
dists = compute_distances(X_test)
print(dists.shape)
def predict_labels(y_train, dists, k=1):
num_test = dists.shape[0]
y_pred = np.zeros(num_test)
for i in range(num_test):
closest_y = []
# 注意 argsort 函数的用法
# np.argsort 默认是按照从小到大的顺序排列
labels = y_train[np.argsort(dists[i, :])].flatten()
closest_y = labels[0:k]
# Counter就是一个计数器类
c = Counter(closest_y)
# Counter.most_common(n) 返回一个 topn 的列表
# 举个小例子
'''
>>> c = Counter('abracadabra')
>>> c.most_common()
[('a', 5), ('r', 2), ('b', 2), ('c', 1), ('d', 1)]
>>> c.most_common(3)
[('a', 5), ('r', 2), ('b', 2)]
'''
y_pred[i] = c.most_common(1)[0][0] #这样就得到了出现最多的那个标签
return y_pred
y_test_pred = predict_labels(y_train,dists, k=1)
y_test_pred = y_test_pred.reshape((-1, 1))
num_correct = np.sum(y_test_pred == y_test)
accuracy = float(num_correct) / X_test.shape[0]
print('Got %d / %d correct => accuracy: %f' % (num_correct, X_test.shape[0], accuracy))
#下面是进行 五折交叉验证
num_folds = 5
k_choices = [1, 3, 5, 8, 10, 12, 15, 20, 30, 50]
X_train_folds = []
y_train_folds = []
X_train_folds = np.array_split(X_train, num_folds)
y_train_folds = np.array_split(y_train, num_folds)
k_to_accuracies = {}
for k in k_choices:
for fold in range(num_folds):
# 对传入的训练集单独划出一个验证集作为测试集
validation_X_test = X_train_folds[fold]
validation_y_test = y_train_folds[fold]
temp_X_train = np.concatenate(X_train_folds[:fold] + X_train_folds[fold + 1:])
temp_y_train = np.concatenate(y_train_folds[:fold] + y_train_folds[fold + 1:])
# 计算距离
temp_dists = compute_distances(validation_X_test)
temp_y_test_pred = predict_labels(y_train,temp_dists, k=k)
temp_y_test_pred = temp_y_test_pred.reshape((-1, 1))
# 查看分类准确率
num_correct = np.sum(temp_y_test_pred == validation_y_test)
num_test = validation_X_test.shape[0]
accuracy = float(num_correct) / num_test
k_to_accuracies[k] = k_to_accuracies.get(k,[]) + [accuracy]
# 打印不同 k 值不同折数下的分类准确率
for k in sorted(k_to_accuracies):
for accuracy in k_to_accuracies[k]:
print('k = %d, accuracy = %f' % (k, accuracy))
for k in k_choices:
accuracies = k_to_accuracies[k]
plt.scatter([k] * len(accuracies), accuracies)
accuracies_mean = np.array([np.mean(v) for k,v in sorted(k_to_accuracies.items())])
accuracies_std = np.array([np.std(v) for k,v in sorted(k_to_accuracies.items())])
plt.errorbar(k_choices, accuracies_mean, yerr=accuracies_std)
plt.title('Cross-validation on k')
plt.xlabel('k')
plt.ylabel('Cross-validation accuracy')
plt.show()
best_k = k_choices[np.argmax(accuracies_mean)]
print('最佳k值为',best_k)
class KNearestNeighbor(object):
def __init__(self):
pass
def train(self, X, y):
self.X_train = X
self.y_train = y
def compute_distances(self, X):
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
M = np.dot(X, self.X_train.T)
te = np.square(X).sum(axis=1)
tr = np.square(self.X_train).sum(axis=1)
dists = np.sqrt(-2 * M + tr + te.reshape(-1,1))
return dists
def predict_labels(self, dists, k=1):
num_test = dists.shape[0]
y_pred = np.zeros(num_test)
for i in range(num_test):
closest_y = []
labels = self.y_train[np.argsort(dists[i, :])].flatten()
closest_y = labels[0:k]
c = Counter(closest_y)
y_pred[i] = c.most_common(1)[0][0]
return y_pred
def cross_validation(self, X_train, y_train):
num_folds = 5
k_choices = [1, 3, 5, 8, 10, 12, 15, 20, 50, 100]
X_train_folds = []
y_train_folds = []
X_train_folds = np.array_split(X_train, num_folds)
y_train_folds = np.array_split(y_train, num_folds)
k_to_accuracies = {}
for k in k_choices:
for fold in range(num_folds):
validation_X_test = X_train_folds[fold]
validation_y_test = y_train_folds[fold]
temp_X_train = np.concatenate(X_train_folds[:fold] + X_train_folds[fold + 1:])
temp_y_train = np.concatenate(y_train_folds[:fold] + y_train_folds[fold + 1:])
self.train(temp_X_train, temp_y_train )
temp_dists = self.compute_distances(validation_X_test)
temp_y_test_pred = self.predict_labels(temp_dists, k=k)
temp_y_test_pred = temp_y_test_pred.reshape((-1, 1)) #Checking accuracies
num_correct = np.sum(temp_y_test_pred == validation_y_test)
num_test = validation_X_test.shape[0]
accuracy = float(num_correct) / num_test
k_to_accuracies[k] = k_to_accuracies.get(k,[]) + [accuracy] # Print out the computed accuracies
for k in sorted(k_to_accuracies):
for accuracy in k_to_accuracies[k]:
print('k = %d, accuracy = %f' % (k, accuracy))
accuracies_mean = np.array([np.mean(v) for k,v in sorted(k_to_accuracies.items())])
best_k = k_choices[np.argmax(accuracies_mean)]
print('最佳k值为{}'.format(best_k))
return best_k
def create_train_test(self):
X, y = shuffle(iris.data, iris.target, random_state=13)
X = X.astype(np.float32)
y = y.reshape((-1,1))
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=42)
return X_train, y_train, X_test, y_test
if __name__ == '__main__':
knn_classifier = KNearestNeighbor()
X_train, y_train, X_test, y_test = knn_classifier.create_train_test()
best_k = knn_classifier.cross_validation(X_train, y_train)
dists = knn_classifier.compute_distances(X_test)
y_test_pred = knn_classifier.predict_labels(dists, k=best_k)
y_test_pred = y_test_pred.reshape((-1, 1))
num_correct = np.sum(y_test_pred == y_test)
accuracy = float(num_correct) / X_test.shape[0]
print('Got %d / %d correct => accuracy: %f' % (num_correct, X_test.shape[0], accuracy))
参考文献与说明:
本博客转载自公众号“机器学习实验室”的文章“数学推导+纯Python实现机器学习算法3:k近邻”
链接:https://mp.weixin.qq.com/s/XmUAYs-l5PqiTpXVVG2_WQ
如若侵权,请联系删除。














 1102
1102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









