







Knn算法:邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是机器学习分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。属于监督学习,有类别标记,他没有明显的前期训练过程,在程序运行之后,把数据加载到内存后,不需要进行训练就可以分类。
使用kNN算法的手写识别系统
1.收集数据:提供文本文件
2.准备数据:编写函数img2vector(),将图像格式转换为分类器使用的向量格式。
3.分析数据:在Python命令提示符中检查数据,确保它符合要求。
4.测试算法:编写函数使用提供的部分数据集作为测试样本,测试样本与非测试样本的区别在于测试样本是已经完成分类的数据,如果预测分类与实际类别不同,则标记为一个错误。
5.使用算法:使用已编写好的算法来对测试样本进行测试
将图像转换为txt文件。已知图像为28*28的像素范围,利用getpixel提取图片中的像素值大小。在打印成txt文件,这边要注意的是这边读取的是整个文件夹。
 图 1数据集整理
图 1数据集整理
3.2命名的整理
为了更好的对已有的数据集进行分类,我们将正确值与图片转换后的txt进行一一对应。
 图 2 标签分离
图 2 标签分离
注意:这边我们将列表的0序号占用掉。
将txt的命名修改成 标签_图片的形式,帮助knn进行分类。
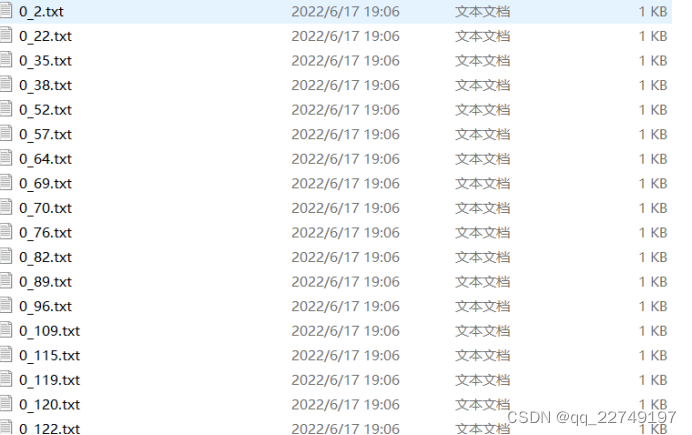
图 3 txt命名
3.3KNN模型的建立:
实现思路:①将测试数据转换成只有一列的0-1矩阵形式 将所有(L个)训练数据也都用上方法转换成只有一列的0-1矩阵形式。②把L个单列数据存入新矩阵A中——矩阵A每一列存储一个字的所有信息。③用测试数据与矩阵A中的每一列求距离,求得的L个距离存入距离数组中。④从距离数组中取出最小的K个距离所对应的训练集的索引拥有最多索引的值就是预测值。
所以先定义一个读取数据的转换数据的函数。将图像信息转成28*28的格式。

图 4 读跟转换函数
在定义一个距离计算,相似度比较函数,来得出最高的索引值。用来确定测试样本的属性。
 图 5 相似度计算
图 5 相似度计算
最后编写识别函数:

图 6识别函数
注意:图中定义模型列表,用来保存knn训练时产生的数组。采取的训练好后,将待测的值依次放入,进而求最接近的数,其概率就是最匹配的索引值。
将待训练的5000的样本集进行转换为txt文件。

图 7 待测样本转入
通过观察,可以发现本次实验所给的样本为乱序状态,无法对其用训练集的方式读取,所以这边采用了try ····except 的方式,用来跳过错误的文件名。
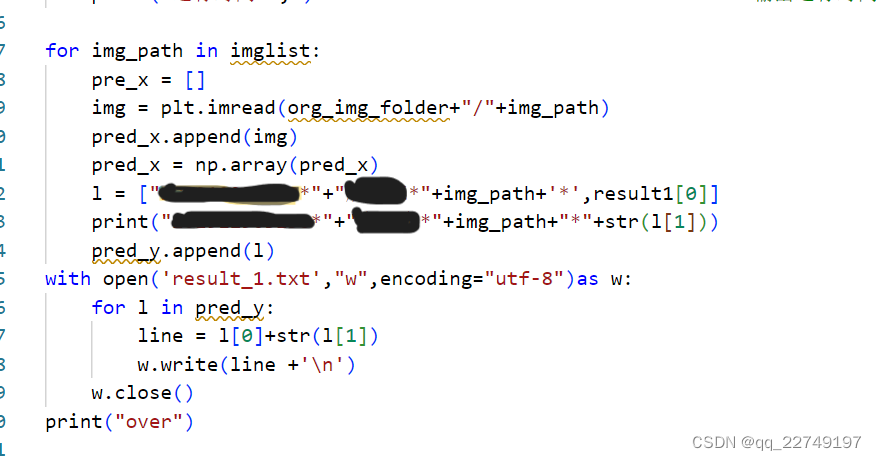
图 8输出结果
利用已存入结果的结果列表result1,将对应的结果输出,输出是注意要将原图像的图形名一同输出,考虑到我们在测试的时候读写图片的顺序也是按顺序读写,所以这里输出的时候,我们在定义一个列表,用来存储名称。
图 9 结果
1、本次实验主要使用了kNN算法,由于采用的是图片转txt后在对应数组,在数据集达到60000时,运行时间巨长,而且在面对5000个数据集时,因为采用的是1对60000数组的形式,导致配对的数据更加长。这个也是此次程序的设计漏洞所在,但是其准确性确实高。
2、本次实验最难的部分,其实并不是算法的设计,我更认为是完成这些设计的边缘代码。比如如何使用 os 库,如何去遍历文件夹内的图片,以及非顺序性读取文件的处理。总体来说,本次课设不仅让我们学习了knn算法的原理,还巩固了我们其他方面的能力。
3、面对测试时间太长这个问题,经过更改数组变化,利用opencv库进行修改,大幅度提高了测试速度。















 1058
1058











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









