







正则表达式的定义
正则表达式是使用单个字符串来描述、匹配一系列符合某 个句法规则的字符串,简单来说,是一种匹字符串的方法,通过一些特殊符号,实现快速查找、删除、替换某个特定字符串。
正则表达式是由普通字符与元字符组成的文字模式。模式用于描述在搜索文本时要匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。其中普通字符包括大小写字母、数字、标点符号及- -些其他符号,元字符则是指那些在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式。
基础正则表达式
扩展正则表达式
sed工具使用方法
ayk工具使用方法
一:基础正则表达式
1)查找特定字符
#grep -n ‘the’ httpd.txt 从文件中查询带the的位置
“-n”表示显示行号、“-i”表示不区分大小写。命令执行后,符合匹配标准的字符,字体颜色会变为红色

2)利用中括号“ [ ] ”来查找集合字符
(1)#grep -n ‘sh[io]rt’ test.txt
可同时查找到“shirt”与“short”这两个字符串。“[ ]”中无论有几个字符,都仅代表一个字符,“[io]”表示匹配“i”或者“o”。
(2)#grep -n ‘oo’ httpd.txt
若要查找包含重复单个字符“oo”时,只需要执行以上命令即可。

(3)#grep -n ‘[^w]oo’ httpd.txt
若查找“oo”前面不是“w”的字符串,只需要通过集合字符的反向选择“[^]”来实现该目的

(4)#grep –n‘[^a-z]oo’ httpd.txt
查找“oo”前面不是小写字母的行,其中“a-z”表示小写字母,大写字母则通过“A-Z”表示。

(5)#grep -n ‘[0-9]’ httpd.txt
查找包含数字的行

3) 查找行首“^”与行尾字符“$”
(1)#grep -n ‘^the’ httpd.txt
查询以“the”字符串为行首的行

(2)#grep -n ‘^ [a-z]’ httpd.txt
查询以小写字母开头的行可以通过"^ [a-z]" 规则来过滤

(3)#grep -n ‘^ [A-Z]’ httpd.txt
查询大写字母开头的行则使用“^ [A-Z]”规则

(4)#grep -n ‘^ [^a-zA-Z]’ httpd.txt
查询不以字母开头的行则使用“[a-zA-Z]”规则。

“ ^ ”符号在“[ ]”符号内表示反向选择,在“[ ]”符号外则代表定位行首。
(5)#grep -n ‘\ .$’ httpd.txt
查询以小数点(.)结尾的行 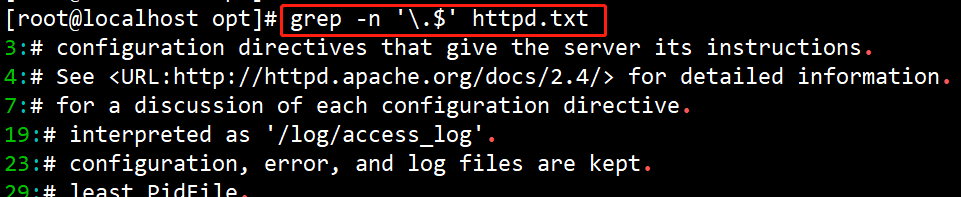
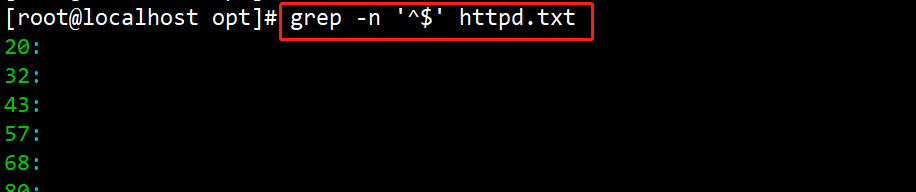
(6)#grep –n‘^$’ httpd.txt
查询空白行
4)查找意一个字符“.”与重复字符“*”
(1)#grep -n ‘w…d’ httpd.txt
查询以w开头d结尾,中间两位任意匹配任意字符,的行
(2)#grep -n ‘ooo*’ httpd.txt
查询含至少两个 o 以上的行

(3)#grep -n ‘woo*d’ httpd.txt
查询以 w 开头 d 结尾,中间含至少一个 o 的行

(4)#grep -n ‘w.*d’ httpd.txt
查询以 w 开头 d 结尾,中间的字符可有可无 的行

(5)#grep -n ‘[0-9][0-9] *’ httpd.txt
查询任意数字所在行

5)查找连续字符范围“{ }”
若查找三到五个 o 的连续字符,需用限定范围的字符“{ }”。因“{ }”在 Shell 中具有特殊意义,所以在使用“{ }”字符时,需要利用转义字符“\”,将“{}”字符转换成普通字符。
(1)#grep -n ‘o\ {3\ }’ httpd.txt
查询三个 o 的字符。

(2)#grep -n ‘wo\ {3,5\ }d’ httpd.txt
查询以 w 开头以 d 结尾,中间包含 3~5 个 o 的字符串。

(3)#grep -n ‘wo\ {4, \ }d’ test.txt
查询以 w 开头以 d 结尾,中间包含 4个以上 o 的字符串。

二:扩展正则表达式
| 元字符 | 作用与示例 |
|---|---|
| + | 作用:重复一个或者一个以上的前一个字符。 |
| ? | 作用:零个或者一个的前一个字符。 |
| | | 作用:使用或者(or)的方式找出多个字符。 |
| ( ) | 作用:查找“组”字符串。 |
| ( )+ | 作用:辨别多个重复的组。 |
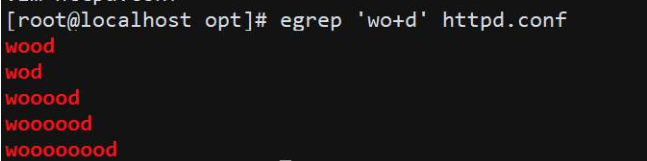
1)#egrep ‘wo+d’ http.conf
查询含一个或多个以上的o字符的行
2) #egrep ‘wo?d’ httpd.conf
查询含零个o或一个o的行

3)#egrep ‘of| is|on’ test.txt
查询含"of"或"if"或者"on"字符串。可加-n ,显示行号。

4) #egrep -n ‘t(a|e)st’ httpd.txt
查询含"tast"或者"test"字符串的行
“tast”与“test”因为这两个单词的“t”与“st”是重复的,所以将“a”与“e”列于“()”符号当中,并以“|”分隔,

5)#egrep -n ‘A(xyz)+C’ httpd.conf
查询开头的"A"结尾是"C",中间有一个以上的 "xyz"字符串的行

三:sed 工具
| 参数 | 作用 |
|---|---|
| -e或–expression= | 表示用指定的脚本文件来处理输入的文本文件 |
| -f或–file= | 表示用指定的脚本文件来处理输入的文本文件 |
| -n、–quiet或silent | 表示仅显示处理后的结果 |
| -i | 直接编辑文本文件 |
| -h或–help | 显示帮助 |
| s | 替换,替换指定字符 |
| d | 删除,删除选定的行 |
| p | 打印,如果同时指定行,表示打印指定行;如果不指定行,则表示打印所有内容;如果有非打印字符,则以 ASCII 码输出。其通常与“-n”选项一起使用 |
| y | 字符转换 |
| a | 增加,在当前行下面增加一行指定内容 |
| c | 替换,将选定行替换为指定内容 |
| i | 插入,在选定行上面插入一行指定内容 |
1)输出符合条件文本
(1)#sed -n ‘p’ httpd.txt
输出所有内容,等同于 cat httpd.txt

(2)#sed -n ‘6p’ httpd.txt
输出第6行
(3)#sed -n ‘4,7p’ httpd.txt
输出4~7行

(4)#sed -n ‘p;n’ httpd.txt
输出所有奇数行, n表示读入下一行资料

(5)#sed -n ‘n;p’ httpd.txt
输出所有偶数行, n表示读入下一行资料

(6)#sed -n ‘1,5{n;p}’ httpd.txt
输出第 1~5 行之间的奇数行(第 1、3、5 行)

(7)# sed -n ‘10,${n;p}’ httpd.txt
输出第 10 行至文件尾之间的偶数行。
读取的第 1 行是文件的第 10 行,
读取的第 2 行是文件的第 11 行,依此类推,所以输出的偶数行是文件的第 11 行、13 行直至文件结尾,其中包括空行。

(8)#sed -n ‘/the/p’ httpd.txt
输出包含the 的行

(9)#sed -n ‘4,/the/p’ httpd.txt
输出从第 4 行至第一个包含 the 的行

(10)#sed -n ‘/the/=’ httpd.txt
输出包含the 的行所在的行号,等号(=)用来输出行号

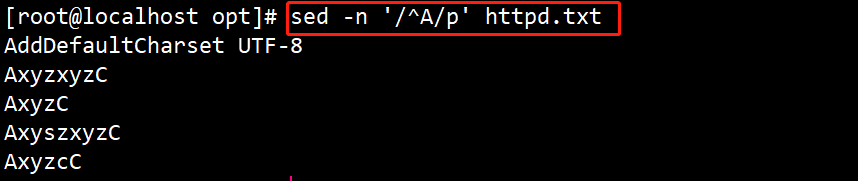
(11)#sed -n ‘/^A/p’ httpd.txt
输出以A 开头的行
(12)#sed -n ‘/<The>/p’ httpd.txt
输出包含单词The 的行, \ < 、\ >代表单词边界















 3378
3378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









