







⼆叉树、BFS、堆、Top K、⼆叉搜索树、模拟、图算法
一、二叉树
二叉树的前序中序后序
二叉树节点定义
为了方便演示,我们先定义一个二叉树节点类。
class TreeNode:
def __init__(self, val=0, left=None, right=None):
self.val = val
self.left = left
self.right = right前序遍历
前序遍历的顺序是先访问根节点,再遍历左子树,最后遍历右子树。可以用递归实现前序遍历,也可以用栈来实现。
递归
def preorderTraversal(root: TreeNode) -> List[int]:
res = []
def dfs(node):
if not node:
return
res.append(node.val)
# 先左后右
dfs(node.left)
dfs(node.right)
dfs(root)
return res栈
def preorderTraversal(root: TreeNode) -> List[int]:
if not root:
return []
res = []
stack = [root]
while stack:
node = stack.pop()
res.append(node.val)
if node.right:
stack.append(node.right)
if node.left:
stack.append(node.left)
return res
中序遍历
中序遍历的顺序是先遍历左子树,再访问根节点,最后遍历右子树。同样可以用递归或者栈来实现。
递归
def inorderTraversal(root: TreeNode) -> List[int]:
res = []
def dfs(node):
if not node:
return
# 先左 再访问 最后右
dfs(node.left)
res.append(node.val)
dfs(node.right)
dfs(root)
return res
栈
def inorderTraversal(root: TreeNode) -> List[int]:
if not root:
return []
res = []
stack = []
while stack or root:
while root:
stack.append(root)
root = root.left
node = stack.pop()
res.append(node.val)
root = node.right
return res
后序遍历
后序遍历的顺序是先遍历左子树,再遍历右子树,最后访问根节点。同样可以用递归或者栈来实现。
递归
def postorderTraversal(root: TreeNode) -> List[int]:
res = []
def dfs(node):
if not node:
return
dfs(node.left)
dfs(node.right)
res.append(node.val)
dfs(root)
return res
栈
def postorderTraversal(root: TreeNode) -> List[int]:
if not root:
return []
res = []
stack = [root]
while stack:
node = stack.pop()
res.append(node.val)
if node.left:
stack.append(node.left)
if node.right:
stack.append(node.right)
return res[::-1]
需要注意的是,栈实现后序遍历的时候,先遍历右子树再遍历左子树,然后将结果反转即可。
异型遍历
102. 二叉树的层序遍历
给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。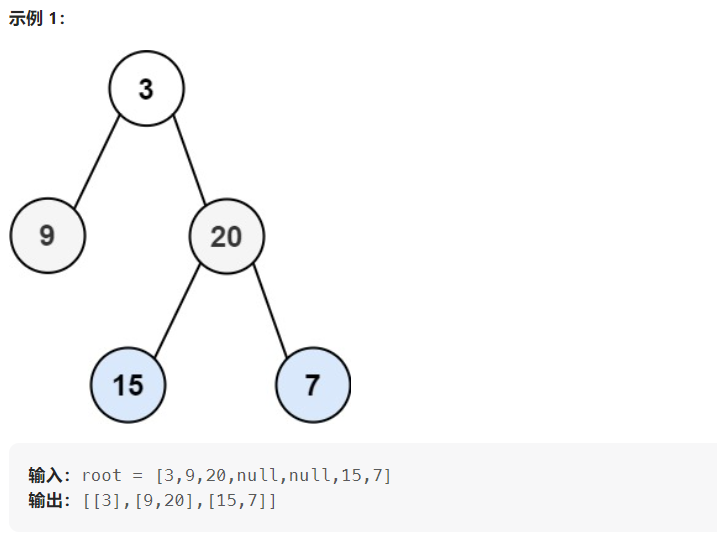
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def levelOrder(self, root: Optional[TreeNode]) -> List[List[int]]:
if root is None:
return []
ans = []
cur = [root]
while cur:
vals = []
nxt = []
for node in cur:
vals.append(node.val)
if node.left: nxt.append(node.left)
if node.right: nxt.append(node.right)
cur = nxt
ans.append(vals)
return ans优化,使用队列,保证当前cur中只保存待取的节点,那么每次访问完后就剔除队列即可。左出右进(先进先出)
class Solution:
def levelOrder(self, root: Optional[TreeNode]) -> List[List[int]]:
if root is None:
return []
ans = []
q = deque([root])
while q:
vals = []
for _ in range(len(q)):
node = q.popleft()
vals.append(node.val)
if node.left: q.append(node.left)
if node.right: q.append(node.right)
ans.append(vals)
return ans先保存根节点,然后先提取根节点的值,然后只要左右不为空就加到nxt中,待cur中的节点访问完毕后,把新的nxt赋值给cur,继续循环。
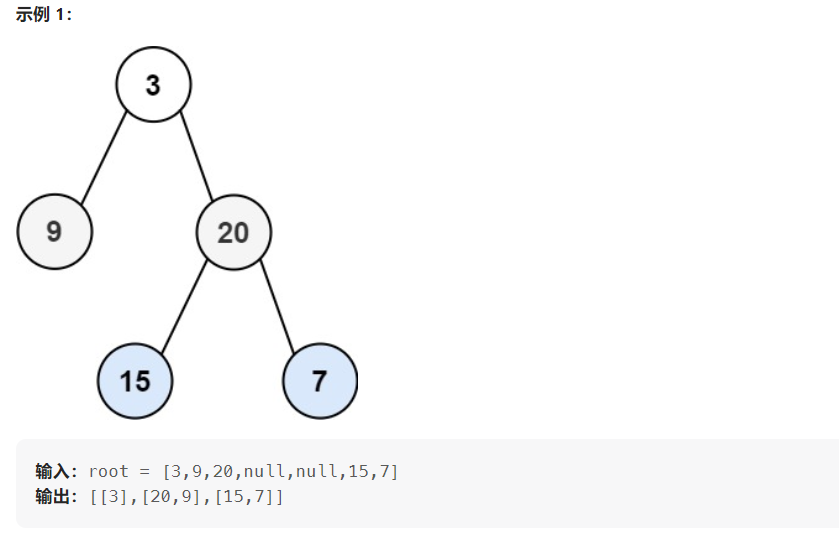
103. 二叉树的锯齿形层序遍历
给你二叉树的根节点 root ,返回其节点值的 锯齿形层序遍历 。(即先从左往右,再从右往左进行下一层遍历,以此类推,层与层之间交替进行)。
class Solution:
def zigzagLevelOrder(self, root: Optional[TreeNode]) -> List[List[int]]:
if root is None:
return []
ans = []
cur = [root]
even = False
while cur:
nxt = []
vals = []
for node in cur:
vals.append(node.val)
if node.left: nxt.append(node.left)
if node.right: nxt.append(node.right)
cur = nxt
# 奇数层不变,偶数层翻转
ans.append(vals[::-1] if even else vals)
even = not even
return ans105. 从前序与中序遍历序列构造二叉树
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。
class Solution:
def buildTree(self, preorder: List[int], inorder: List[int]) -> TreeNode:
if not preorder or not inorder: # 递归终止条件
return
root = TreeNode(preorder[0]) # 先序为“根左右”,所以根据preorder可以确定root
idx = inorder.index(preorder[0]) # 中序为“左根右”,根据root可以划分出左右子树
# 下面递归对root的左右子树求解即可
root.left = self.buildTree(preorder[1:1 + idx], inorder[:idx])
root.right = self.buildTree(preorder[1 + idx:], inorder[idx + 1:])
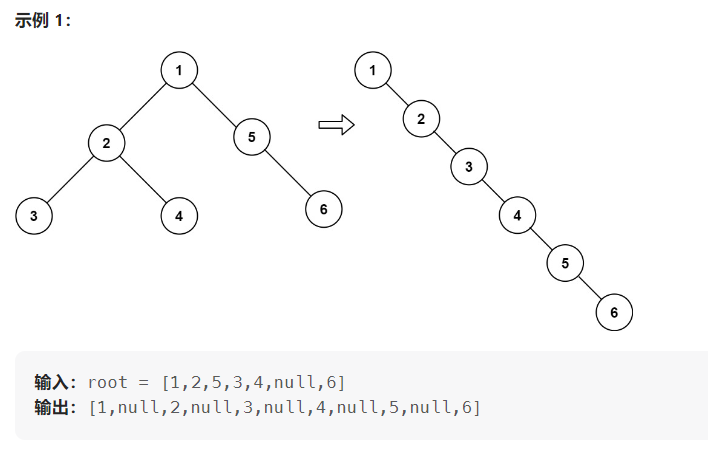
return root114.二叉树展开为链表
给你二叉树的根结点 root ,请你将它展开为一个单链表:
- 展开后的单链表应该同样使用
TreeNode,其中right子指针指向链表中下一个结点,而左子指针始终为null。
展开后的单链表应该与二叉树 先序遍历 顺序相同。
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def flatten(self, root):
while root:
if root.left: #左子树存在的话才进行操作
sub_left = root.left
while sub_left.right: #左子树的右子树找到最深
sub_left = sub_left.right
sub_left.right = root.right #将root的右子树挂到左子树的右子树的最深
root.right = root.left #将root的左子树挂到右子树
root.left = None #将root左子树清空
root = root.right #继续下一个节点的操作
222.完全二叉树的节点个数
给你一棵 完全二叉树 的根节点 root ,求出该树的节点个数。
完全二叉树 的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层,则该层包含 1~ 2h 个节点。
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def countNodes(self, root: Optional[TreeNode]) -> int:
if root is None:
return 0
ans = 0
cur = [root]
while cur:
vals = []
nxt = []
for node in cur:
ans+=1
if node.left: nxt.append(node.left)
if node.right: nxt.append(node.right)
cur = nxt
ans+=len(vals)
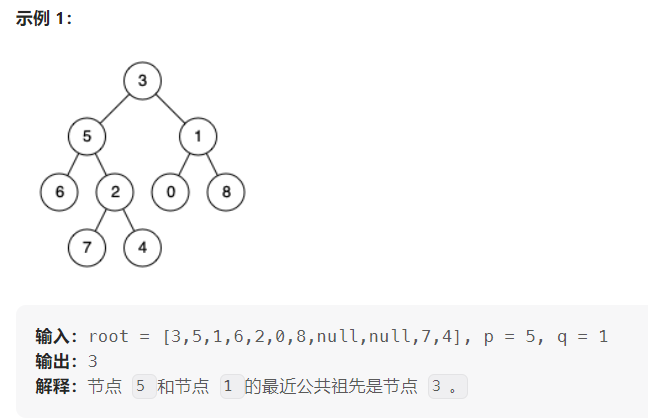
return ans236.二叉树的最近公共祖先
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def lowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode':
if root in (None, p, q):
return root
left = self.lowestCommonAncestor(root.left, p, q)
right = self.lowestCommonAncestor(root.right, p, q)
if left and right:
return root
return left if left else right二叉搜索树
二叉搜索树的中序遍历(左根右)结果是一个单调递增的有序序列,我们反序进行中序遍历(右根左),即可以得到一个单调递减的有序序列。
二叉搜索树的最小绝对差
给你一个二叉搜索树的根节点 root ,返回 树中任意两不同节点值之间的最小差值 。
差值是一个正数,其数值等于两值之差的绝对值。
class Solution:
def getMinimumDifference(self, root: TreeNode) -> int:
st = []
p = root
pre = -float('inf')
min_val = float('inf')
while p is not None or st:
while p is not None:
st.append(p)
p = p.left
p = st.pop()
cur = p.val
if cur - pre < min_val:
min_val = cur - pre
pre = cur
p = p.right
return min_val二叉搜索树的最近公共祖先
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
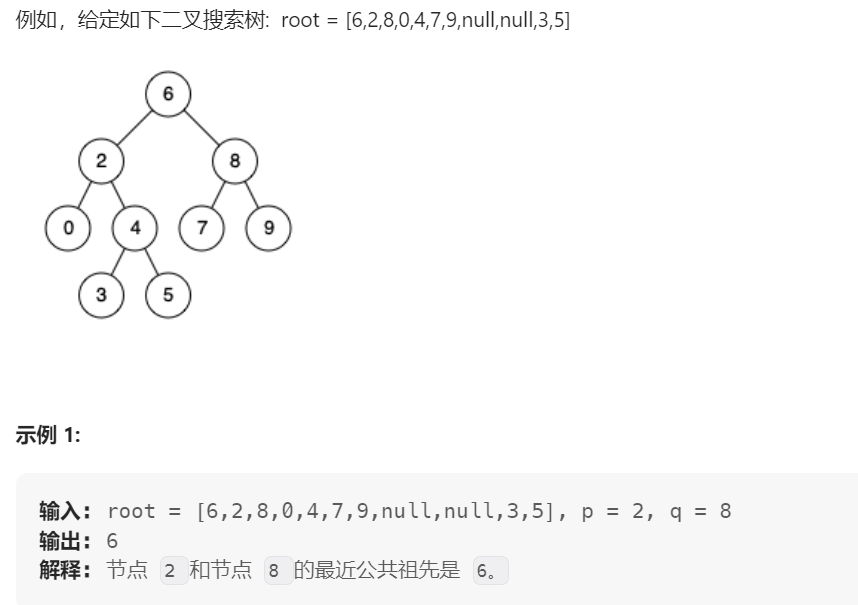
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def lowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode':
x = root.val
if p.val < x and q.val < x:
return self.lowestCommonAncestor(root.left, p, q)
if p.val > x and q.val > x:
return self.lowestCommonAncestor(root.right, p, q)
return root把二叉搜索树转换为累加树
给出二叉 搜索 树的根节点,该树的节点值各不相同,请你将其转换为累加树(Greater Sum Tree),使每个节点 node 的新值等于原树中大于或等于 node.val 的值之和。
提醒一下,二叉搜索树满足下列约束条件:
- 节点的左子树仅包含键 小于 节点键的节点。
- 节点的右子树仅包含键 大于 节点键的节点。
- 左右子树也必须是二叉搜索树。
class Solution:
def convertBST(self, root: TreeNode) -> TreeNode:
def dfs(root):
nonlocal s
if root is None:
return
dfs(root.right)
s += root.val
root.val = s
dfs(root.left)
s = 0
dfs(root)
return root二、Top K
347.前 K 个高频元素
给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。
class Solution:
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
dic = collections.Counter(nums)
res = []
while k > 0:
tmp = 0
for num in dic:
if dic[num] > tmp:
tmp = dic[num]
cur = num
dic[cur] = -1
res.append(cur)
k -= 1
return res思路一:直接排序
class Solution:
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
count = collections.Counter(nums)
return [item[0] for item in count.most_common(k)]思路二:堆排序一
- 记录每个数字出现的次数
- 把数字和对应出现次数放入堆中
- 返回堆的前k大元素
class Solution:
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
count = collections.Counter(nums)
heap = [(val, key) for key, val in count.items()]
return [item[1] for item in heapq.nlargest(k, heap)]692.前K个高频单词
给定一个单词列表 words 和一个整数 k ,返回前 k 个出现次数最多的单词。
返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率, 按字典顺序 排序。
class Solution:
def topKFrequent(self, words: List[str], k: int) -> List[str]:
hash = collections.Counter(words)
res = sorted(hash, key=lambda word:(-hash[word], word))
return res[:k]
关于 sorted 排序的多种情况
- 词频正序, 字母正序 sorted(hash, key=lambda word:(hash[word], word))
- 词频倒序, 字母倒序 (reverse=True 即将sorted方法修改为倒序排列) sorted(hash, key=lambda word:(hash[word], word), reverse=True)
- 词频倒序, 字母正序(本题要求) sorted(hash, key=lambda word:(-hash[word], word))
- 词频正序, 字母倒序 sorted(hash, key=lambda word:(-hash[word], word), reverse=True)
703.数据流中的第 K 大元素
设计一个找到数据流中第 k 大元素的类(class)。注意是排序后的第 k 大元素,不是第 k 个不同的元素。
请实现 KthLargest 类:
KthLargest(int k, int[] nums)使用整数k和整数流nums初始化对象。int add(int val)将val插入数据流nums后,返回当前数据流中第k大的元素。
class KthLargest(object):
def __init__(self, k, nums):
"""
:type k: int
:type nums: List[int]
"""
self.k = k
self.que = nums
heapq.heapify(self.que)
def add(self, val):
"""
:type val: int
:rtype: int
"""
heapq.heappush(self.que, val)
while len(self.que) > self.k:
heapq.heappop(self.que)
return self.que[0]
三、DFS和BFS
1. 注意⽐较DFS和BFS的异同。相同之处:这两种算法都属于在树形结构或者图的搜索算法,能够访问所有的节点/位置不同之处:DFS像侦察兵⼀样⼀直优先往深处搜索;BFS像军队⼀样铺展开来搜索DFS通常需要借助⽤递归实现,本质上是⽤到了编译栈;BFS通常需要借助队列来辅助实现BFS有层的概念(level),有时候也称为波纹法,通常可以⽤来搜寻最短路径对于⼆叉树⽽⾔,DFS有先序、中序、后序三种遍历⽅式,但对于图⽽⾔通常没有这种分类;BFS在⼆叉树中也称为层序遍历。
743. 网络延迟时间
有 n 个网络节点,标记为 1 到 n。
给你一个列表 times,表示信号经过 有向 边的传递时间。 times[i] = (ui, vi, wi),其中 ui 是源节点,vi 是目标节点, wi 是一个信号从源节点传递到目标节点的时间。
现在,从某个节点 K 发出一个信号。需要多久才能使所有节点都收到信号?如果不能使所有节点收到信号,返回 -1 。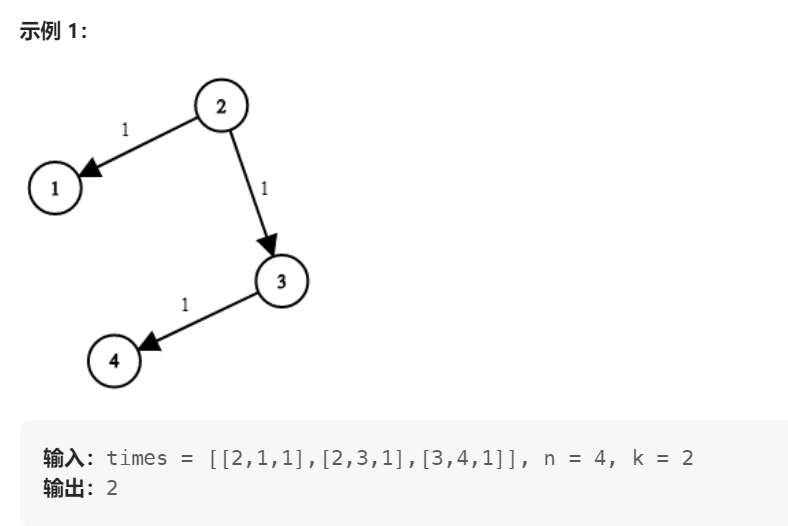
207. 课程表
你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。
在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] = [ai, bi] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。
- 例如,先修课程对
[0, 1]表示:想要学习课程0,你需要先完成课程1。
请你判断是否可能完成所有课程的学习?如果可以,返回 true ;否则,返回 false 。
本题可约化为: 课程安排图是否是有向无环图(DAG)。即课程间规定了前置条件,但不能构成任何环路,否则课程前置条件将不成立。
思路是通过拓扑排序 判断此课程安排图是否是 有向无环图(DAG) 。 拓扑排序原理: 对DAG 的顶点进行排序,使得对每一条有向边 (u,v)(u, v)(u,v),均有 u(在排序记录中)比 v 先现。亦可理解为对某点 vvv 而言,只有当 vvv 的所有源点均出现了,vvv 才能出现。
通过课程前置条件列表 prerequisites 可以得到课程安排图的 邻接表 adjacency,以降低算法时间复杂度,以下两种方法都会用到邻接表。
class Solution:
def canFinish(self, numCourses: int, prerequisites: List[List[int]]) -> bool:
def dfs(i, adjacency, flags):
if flags[i] == -1: return True
if flags[i] == 1: return False
flags[i] = 1
for j in adjacency[i]:
if not dfs(j, adjacency, flags): return False
flags[i] = -1
return True
adjacency = [[] for _ in range(numCourses)]
flags = [0 for _ in range(numCourses)]
for cur, pre in prerequisites:
adjacency[pre].append(cur)
for i in range(numCourses):
if not dfs(i, adjacency, flags): return False
return True














 2205
2205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









