






强化学习极简入门:通俗理解MDP、DP MC TC和Q学习、策略梯度、PPO
一文通透优化算法:从梯度下降、SGD到牛顿法、共轭梯度(23修订版)_共轭梯度下降法-CSDN博客
梯度下降算法:


SGD:

小批量梯度下降
换言之,对于每更新一次θ,传统梯度下降算法 遍历整个数据集m个样本,SGD则每更新一次θ 遍历1个样本,而小批量梯度下降每更新一次θ 遍历b个数据样本,b取值范围通常介于2~100之间。
强化学习
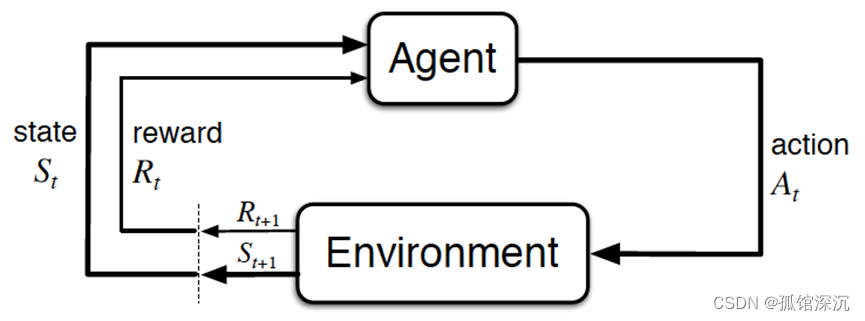
总的而言,Agent依据策略决策从而执行动作action,然后通过感知环境Environment从而获取环境的状态state,进而,最后得到奖励reward(以便下次再到相同状态时能采取更优的动作),然后再继续按此流程“依据策略执行动作-感知状态--得到奖励”循环进行。
最优模型 = arg minE { [损失函数(标签,模型(特征)] }
最优策略 = arg maxE { [奖励函数(状态,动作)] }
进一步,RL为得到最优策略从而获取最大化奖励,有
基于值函数的方法,通过求解一个状态或者状态下某个动作的估值为手段,从而寻找最佳的价值函数,找到价值函数后,再提取最佳策略
比如Q-learning、DQN等,适合离散的环境下,比如围棋和某些游戏领域
基于策略的方法,一般先进行策略评估,即对当前已经搜索到的策略函数进行估值,得到估值后,进行策略改进,不断重复这两步直至策略收敛。
RL其实是一个马尔可夫决策过程(Markov decision process,MDP),而为说清楚MDP,得先从随机过程、马尔可夫过程(Markov process,简称MP)开始讲起。

在马尔可夫过程(MP)的基础上加入奖励函数R和折扣因子γ,就可以得到马尔可夫奖励过程(MRP)。

价值函数:


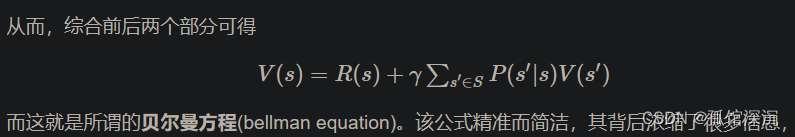

![]()
上述例子的状态比较少所以计算量不大,但当状态一多,则贝尔曼方程的计算量还是比较大的,而求解较大规模的马尔可夫奖励过程中的价值函数时,可以用的方法包括:动态规划、蒙特卡洛方法、时序差分(temporal difference,简称TD)方法。后面挨个介绍这三种方法。

策略函数:

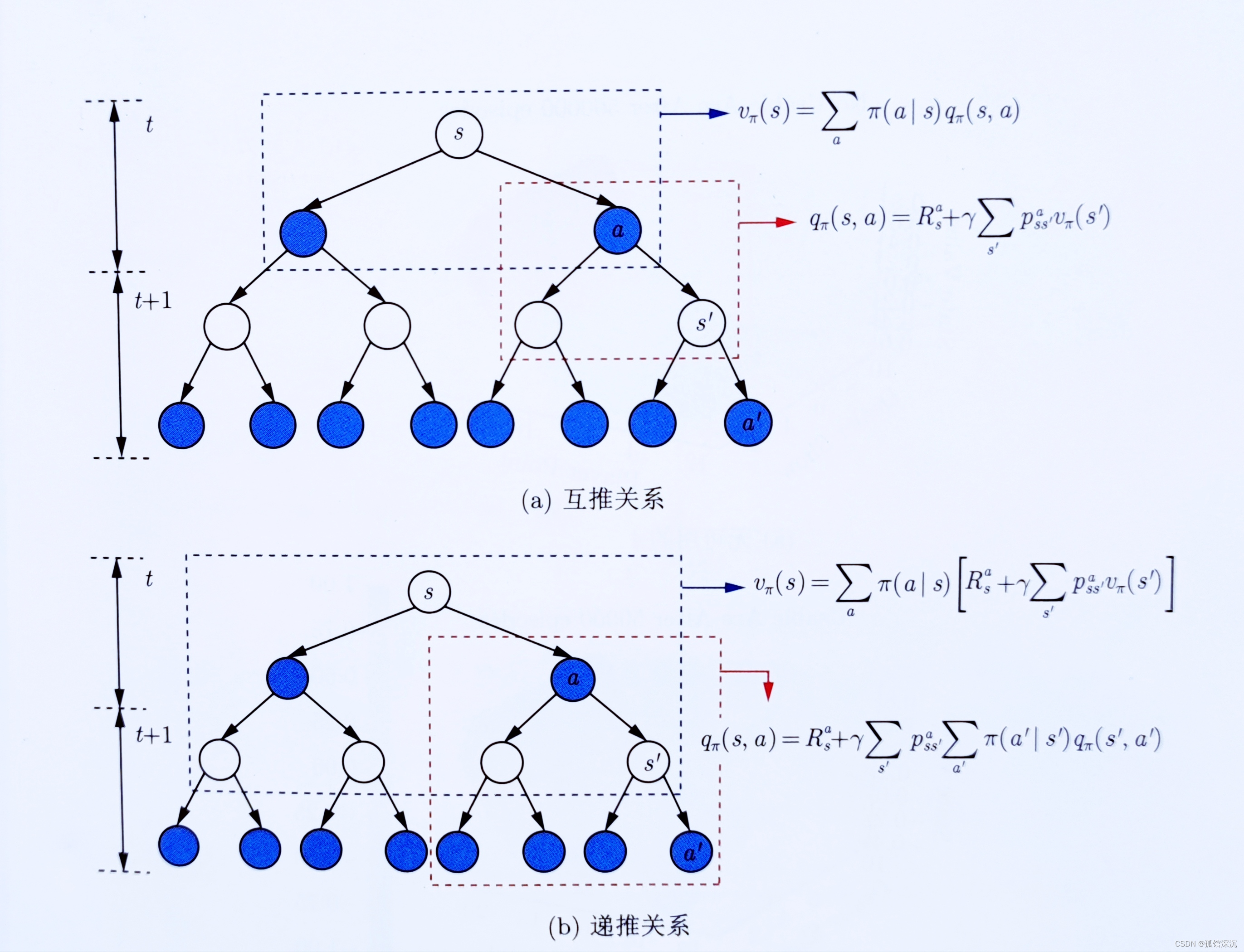
V和Q函数:

V和Q函数的关系:
1、Q到V
![]()
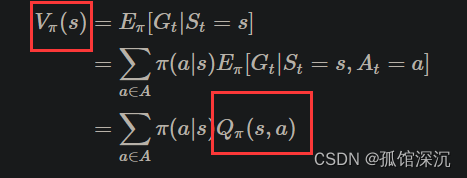
2、V到Q
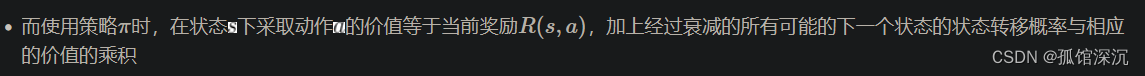
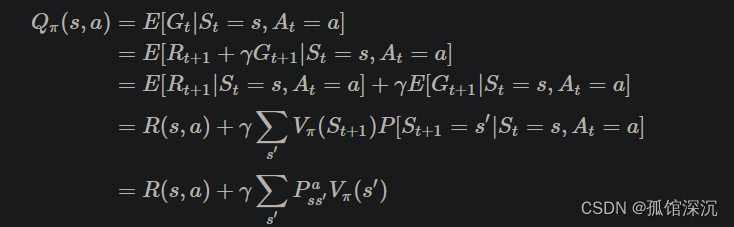
总:

RL和动态规划DP:
![]()

综合,可得:
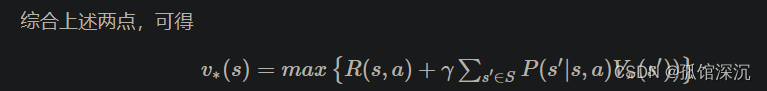

DP求解最优策略的算法流程:

RL和蒙特卡洛法

RL和时序差分法
总之,TD结合了DP和MC,与DP一致的点时与MC不一致,与DP不一致的点时恰又与MC一致
没细看这块。

RL分类——基于模型 与 不基于模型(Value-base/Policy-based)
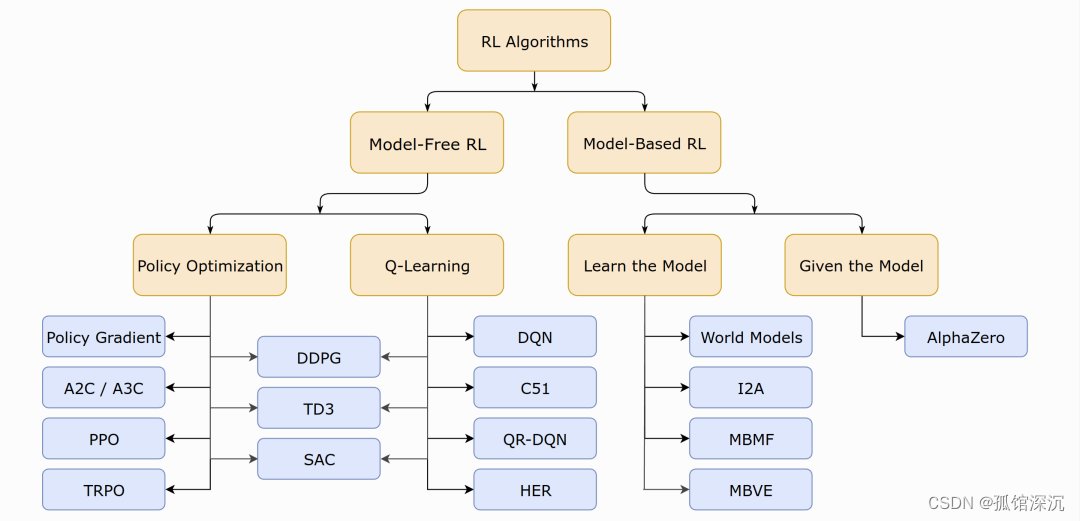
无模型的强化学习:
①基于价值的强化学习(Value-based RL)。最经典的便是off-policy模式的Q-learning和on-policy模式的SARSA
②基于策略的强化学习(Policy-based RL)。其对策略进行进行建模π(s,a)并优化,一般得到的是随机性策略。
















 310
310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









