






1 分层强化学习简介
分层强化算是强化学习领域比较流行的研究方向。当环境较为复杂或者任务较为困难时,智能体的状态和动作空间过大,会导致强化学习难以取得理想的效果。应对这种状况,分层强化学习应运而生,主要解决稀疏reward以及状态动作空间过大导致难以训练的问题。
人类在解决一个复杂问题时,往往会将其分解为若干个容易解决的子问题,分而治之,分层的思想正是来源于此。目前分层的解决手段大体分两种,一种是基于目标的(goal-reach),主要做法是选取一定的goal,使agent向着这些goal训练,可以预见这种方法的难点就是如何选取合适的goal;另一种方式是多级控制(multi-level control),做法是抽象出不同级别的控制层,上层控制下层。
分层强化学习解决的是强化学习中的稀疏奖励(sparse reward)问题:当环境奖励过于稀疏时,智能体可能长期都没有办法获得具有正奖励的样本,给值函数和策略的学习带来了困难。通过分层把策略分为不同层级的子策略,每个子策略在学习的过程中会得到来自上一层级传递来的奖励,这样可以大大提升 样本的利用效率。
目前的分层强化学习主要可以分为两大类,第一类是基于 option 的,第二类是基于 goal 的。拿做菜举例,为了做完一道菜,我们需要选择洗菜、切菜、炒菜,这里洗菜、切菜、炒菜均属于option,而把才洗干净、切细、炒熟则属于goal目标,可以看出两者是紧密联系的。总体来说,几乎所有的分层强化学习都是,上层控制器在较长的时间跨度里选择option/goal,下层控制器在较短的时间跨度里根据option/goal选择action。分层之所以能够提升样本效率,是因为上层控制器给下层控制器提供goal/option的同时还会根据下层控制器的策略好坏反馈一个对应的 内在奖励(intrinsic reward),这就保证了即便在外部奖励为0的情况下,下层控制器依然能够获得奖励,从而一定程度上缓解了奖励稀疏的问题。
2 分层强化学习算法
2.1 封建等级式学习 Feudal Learning
feudal learning受中世纪欧洲封建制度的启发。其主要思路是:将整个要解决的问题分为多个层级,上层调用下层来解决任务,下层执行上层的命令(也就是reward设计其实是根据上层的需求实现的)。
封建学习主要的特征有两个:
奖赏隐藏(reward hiding):每层只知道本层的奖赏,而每层的目标(由上层指定)就编码到reward函数中;【每层只要满足该层的奖励最大化,不用满足上面层级的奖励最大化(因为也不知道)】
信息隐层:每层只关注其应该关注到的信息,而不是真实的环境信息(全局信息)。【底下干活的人无需知道大领导给小领导安排的事儿】
图 1 封建学习解决导航问题
2.2 基于选项(option)的强化学习
2.2.1 option和action的关系和区别
option是时序扩展的action,或把option看成是对action的一种时序抽象。
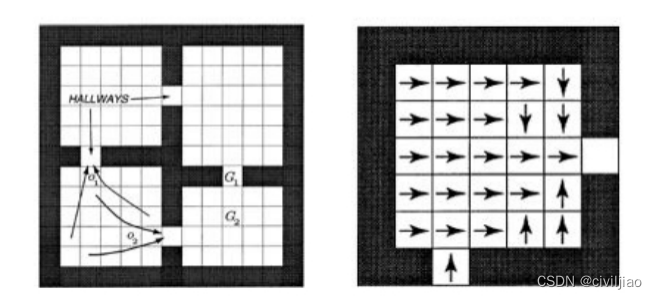
图 2 Option和action
左图是一个格子世界,共有四个房间,每个房间之间通过一个过道连接,假设智能体当前处于左上方的房间内,其目标是到达G1处。
那么从宏观的层面看, 它有两种选择,分别是先进入右上方房间和先进入左下方房间,这两种宏观的选择就是所谓的option;
其次,当选择了某一种方案(option) 后,例如选择了先进入右上方房间,那么如何从当前的格子位置抵达当前房间与右上方房间相连的过道格子,在这个过程中所需采取的每一步 动作即是action,例如我们可以通过一些路径规划方法找到像右图一样的某种最短路径走法。
【option框架下的策略层次就是首先由顶层策略选择option,再由option选择action。】
整体的框架可以看成两个层次组成:
(1) 底层是一个选择action的次级策略:
- 半马尔可夫决策过程 semi-markov decision process SMDP
- 运行到终止
- 输出动作
- 进行环境观测
(2) 顶层是用于选择 option 的高级策略(policy-over-option):
- 进行环境观测
- 输出子策略
- 运行到终止
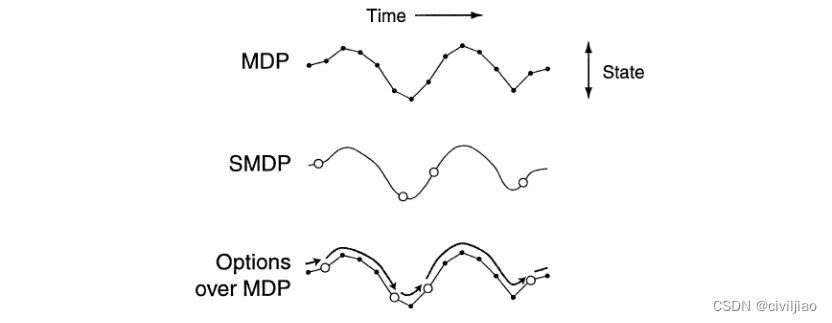
2.2.2 半马尔可夫决策过程
马尔可夫决策过程中,选择一个动作后,agent会立刻根据状态转移方程P跳转到下一个状态,而 在半马尔可夫决策过程中,当前状态到下一个状态的步数是一个随机变量 τ, 即在某个状态s下选择一个动作a后,经过 τ 步才会以一个概率转移到下一个状态s′(多次和环境发生交互之后,状态才会改变【在之后可以知道,这一系列action我们可以看成一个option】)。
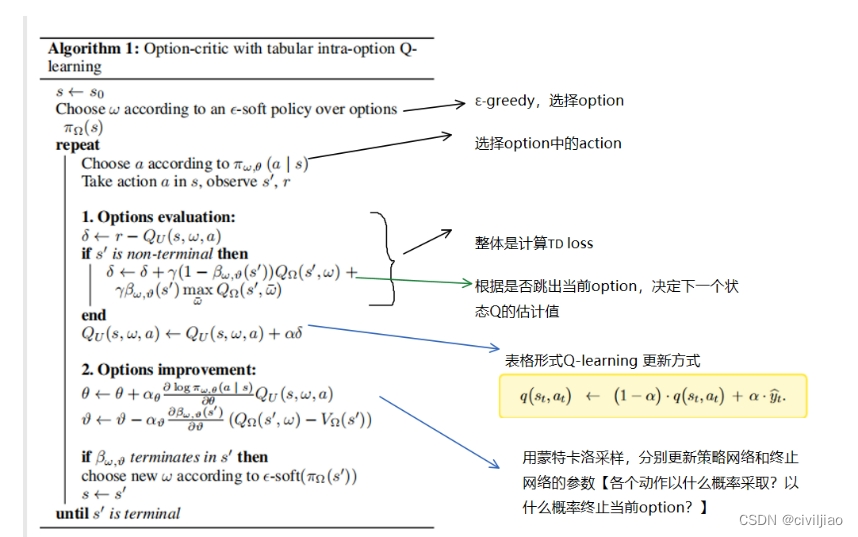
2.2.3 算法流程
2.3 基于MaxQ值函数分解的分层强化学习
2.3.1 介绍
首先将一个马尔可夫决策过程M分解成多个子任务{M0, M1, …, Mn},M0为根子任务,解决了M0就意味着解决了原问题M。
对于每一个子任务Mi,都有一个终止断言(termination predicate) Ti和一个动作集合Ai。这个动作集合中的元素既可以是其他的子任务,也可以是一个MDP中的action。
一个子任务的目标是转移到一个状态,可以满足终止断言,使得此子任务完成并终止。
我们需要学到一个高层次的策略π={π0, …, πn},其中πi为子任务Mi的策略。(换言之,我们此时每一步的action,可以是原来MDP的一个action,也可以是解决一个子问题的一连串action)。
令Q(i, s, j)为子任务i在状态s执行动作j之后按照某个策略执行直到达到终止状态的期望累计奖赏,可以表示为
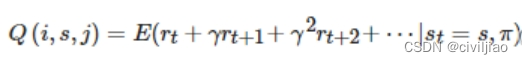
假设在子任务i中,我们一共执行了τ步,才满足终止断言,那么我们可以将Q函数改写成:
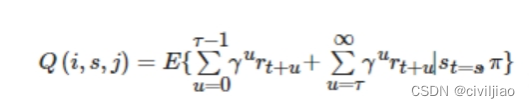
右边的第1项实际上是V(j s)【在子任务中,状态s执行动作j的累计奖励】
后一项我们称之为完成函数completion function,C(i, s, j)。记后续父任务的总期望奖励。
MaxQ问题的瓶颈也是很明显的:就是子任务需要人为去划分 。
2.3.2 举例
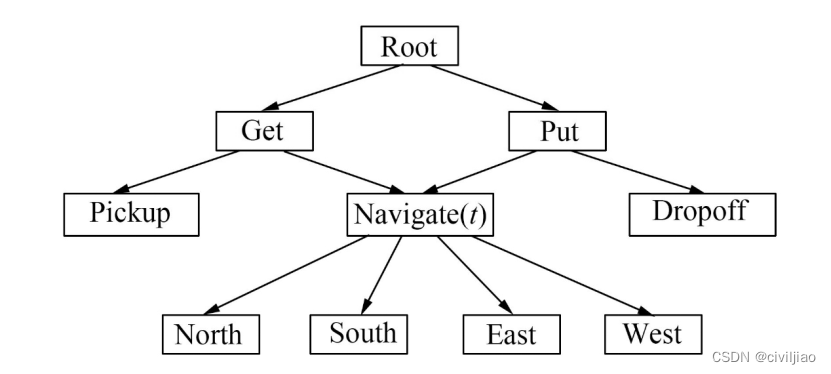
出租车问题是指一个出租车agent需要到特定位置接一位乘客并且把他送到特定的位置让其下车。一共有6个动作,分别是上车(pick up)、下车(drop off),以及向东南西北四个方向开车的动作。
这里使用MaxQ方法,将原问题分解成了get和put两个子任务。(root任务,他的策略只是什么时候应该get,什么时候应该put,至于get和put里面是怎么搞的,root不管)。
这两个子任务又进行分解,get分解成一个基本动作pick up和一个子任务navigate,而put也分解成了一个基本动作drop off和一个子任务navigate。子任务navigate(t)表示t时刻应该开车的方向。(同样地,get子任务的策略只是什么时候pickup,什么时候navigate;put子任务的策略只是什么时候pickup,什么时候navigate)。
对于这个强化学习问题,agent首先选择get,然后get子问题navigate,直到到达乘客所在地,然后get选择pick up动作,乘客上车。之后agent选择put子任务,put子任务选择navigate,直到到达乘客目的地,之后put子任务选择drop off动作,乘客下车,任务完成。
3 分层强化学习的工业界应用
目前工业界解决大规模控制场景的解决范式也是分层,为了训练快速,调出理想的效果,更多的是应用分层的思路。通过把大规模问题,拆分成子问题,这里的拆分就利用到了专家的经验。而大规模问题的顶层决策,我们这里叫做指挥层,可以通过向量机(专家系统)或者强化学习去做决策;另外,子问题的决策,我们也可以通过向量机(专家系统)或者强化学习去做决策。这样,把问题拆解开来之后,决策的action的维度会大大降低,另外输出的态势(observation)也会相应减少。甚至真正在应用场景中,为了训练的方便,会固定子任务和指挥层两者中一个神经网络的参数,只去训练另外一个参数模型。
一篇关于空战的论文,讲述的是"人工智能(AI)正在成为国防工业的一个重要组成部分,最近美国DARPA的AlphaDogfight试验(ADT)证明了这一点。ADT试图审查能够在模拟空对空战斗中驾驶F-16的人工智能算法可行性。作为ADT的参与者,洛克希德-马丁公司(LM)的方法将分层结构与最大熵强化学习(RL)相结合,通过奖励塑造整合专家知识,并支持策略模块化。该方法在ADT的最后比赛中取得了第二名的好成绩(共有8名竞争者),并在比赛中击败了美国空军(USAF)F-16武器教官课程的一名毕业生。"里面的分层思路,也可以代表一种实际业界如何利用分层强化学习的方式。
4 参考文献:
原文链接:https://blog.csdn.net/deeprl/article/details/110153164
原文链接:强化学习笔记:分层强化学习-CSDN博客
原文链接:【干货总结】分层强化学习(HRL)全面总结-CSDN博客(这篇文章讲述具体的多种分层RL算法)
原文链接:https://zhuanlan.zhihu.com/p/571707927

















 888
888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









