







目录
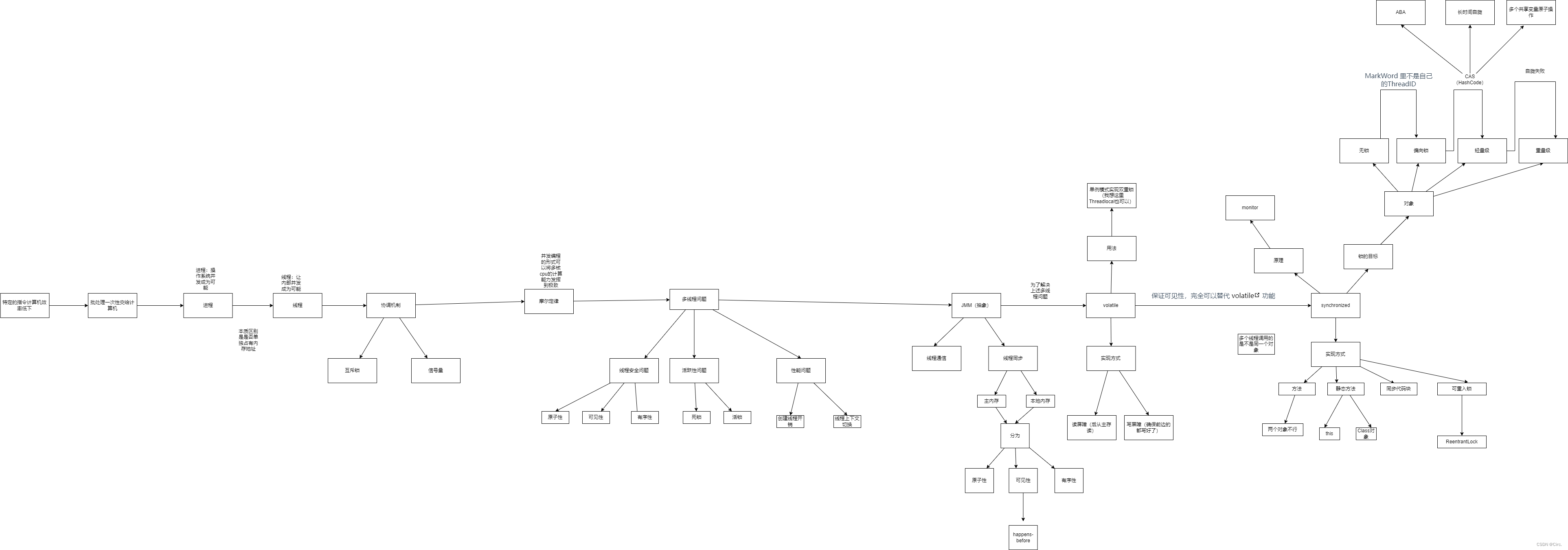
背景
到底什么是并发,这个问题一直困扰着我,于是我抽出一些时间专门来学习这个事情。
步骤
从发展历史上看
1、最初的计算机只能接受一些特定的指令,用户每输入一个指令,计算机就做出一个操作。当用户在思考或者输入时,计算机就在等待。这样效率非常低下,在很多时候,计算机都处在等待状态。
2、批处理操作系统
把一系列需要操作的指令写下来,形成一个清单,一次性交给计算机,批处理操作系统的指令运行方式仍然是串行的,内存中始终只有一个程序在运行,后面的程序需要等待前面的程序执行完成后才能开始执行,而前面的程序有时会由于 I/O 操作、网络等原因阻塞,所以批处理操作效率也不高
3、进程就是应用程序在内存中分配的空间,也就是正在运行的程序,各个进程之间互不干扰。同时进程保存着程序每一个时刻运行的状态。进程让操作系统的并发成为了可能。
4、人们并不满足一个进程在一段时间只能做一件事情,如果一个进程有多个子任务时,让一个线程执行一个子任务,这样一个进程就包含了多个线程,每个线程负责一个单独的子任务。进程让操作系统的并发性成为了可能,而线程让进程的内部并发成为了可能。
进程是操作系统进行资源分配的基本单位,而线程是操作系统进行调度的基本单位。
5、多线程需要注意的点
线程安全
原子性
(转账问题)
可见性
(主存和自己内存之间的同步问题)
活跃性
死锁和活锁的问题
性能问题
创建线程+cpu上下文切换
处理方式:
无锁并发编程:可以参照 ConcurrentHashMap 锁分段的思想,不同的线程处理不同段的数据,这样在多线程竞争的条件下,可以减少上下文切换的时间。
CAS 算法,利用 Atomic + CAS 算法来更新数据,采用乐观锁的方式,可以有效减少一部分不必要的锁竞争带来的上下文切换。
使用最少线程:避免创建不必要的线程,如果任务很少,但创建了很多的线程,这样就会造成大量的线程都处于等待状态。
协程:在单线程里实现多任务的调度,并在单线程里维持多个任务间的切换。
内存模型
是什么
定义了 Java 程序中的变量、线程如何和主存以及工作内存进行交互的规则。它主要涉及到多线程环境下的共享变量可见性、指令重排等问题,是理解并发编程中的关键概念。
共享变量
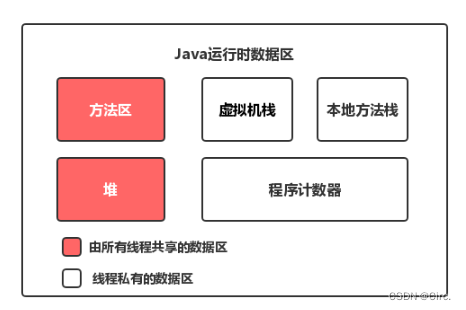
对于每一个线程来说,栈都是私有的,而堆是共有的。
也就是说,在栈中的变量(局部变量、方法定义的参数、异常处理的参数)不会在线程之间共享,也就不会有内存可见性的问题,也不受内存模型的影响。而在堆中的变量是共享的,一般称之为共享变量。

线程之间的共享变量存在于主存中,每个线程都有一个私有的本地内存,存储了该线程的读、写共享变量的副本。本地内存是 Java 内存模型的一个抽象概念,并不真实存在。它涵盖了缓存、写缓冲区、寄存器等。
内存可见性问题通常发生在多线程编程中,特别是在多个线程访问和修改共享数据的时候。这是因为每个线程可能在其自己的处理器或核心上运行,并且每个处理器或核心可能有自己的缓存。当线程修改一个共享变量的值时,这个修改可能首先只发生在该线程的本地缓存中,而不是立即反映到主内存或其他线程的缓存中。这就是所谓的“内存不可见性问题”。
关键字学习
volatile关键字
volatile 会禁止指令重排
原理:
写屏障(Write Barrier):当一个 volatile 变量被写入时,写屏障确保在该屏障之前的所有变量的写入操作都提交到主内存。
读屏障(Read Barrier):当读取一个 volatile 变量时,读屏障确保在该屏障之后的所有读操作都从主内存中读取。
不符合原子性的不要使用volatile
volatile 实现单例模式的双重锁
public class penguin {
private static volatile penguin m_penguin = null;
// 避免通过new初始化对象
private void penguin() {}
public void beating() {
System.out.println("打豆豆");
};
public static penguin getInstance() { //1
if (null == m_penguin) { //2
synchronized(penguin.class) { //3
if (null == m_penguin) { //4
m_penguin = new penguin(); //5
}
}
}
return m_penguin; //6
}
}
其中,使用 volatile 关键字是为了防止 m_penguin = new penguin() 这一步被指令重排序。实际上,new penguin() 这一步分为三个子步骤:
分配对象的内存空间。
初始化对象。
将 m_penguin 指向分配的内存空间。
如果不使用 volatile 关键字,JVM 可能会对这三个子步骤进行指令重排序,如果步骤 2 和步骤 3 被重排序,那么线程 A 可能在对象还没有被初始化完成时,线程 B 已经开始使用这个对象,从而导致问题。而使用 volatile 关键字可以防止这种指令重排序。
synchronized关键字
关键字 synchronized 可以保证在同一个时刻,只有一个线程可以执行某个方法或者某个代码块(主要是对方法或者代码块中存在共享数据的操作),同时我们还应该注意到 synchronized 的另外一个重要的作用,synchronized 可保证一个线程的变化(主要是共享数据的变化)被其他线程所看到(保证可见性,完全可以替代 volatile 功能)。
三种用法
原理:monitor
可重入锁
synchronized四种锁
无锁状态
偏向锁状态
轻量级锁状态
重量级锁状态
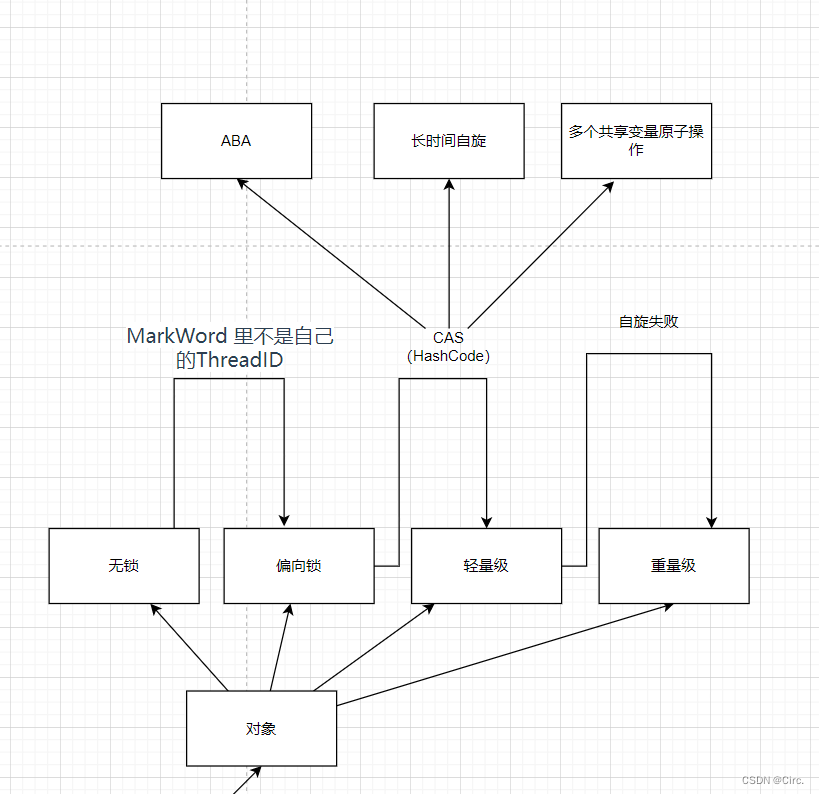
发展历史是什么样的呢?
每一个线程在准备获取共享资源时:
第一步,检查 MarkWord 里面是不是放的自己的 ThreadId ,如果是,表示当前线程是处于 “偏向锁” 。
第二步,如果 MarkWord 不是自己的 ThreadId,锁升级,这时候,用 CAS 来执行切换,新的线程根据 MarkWord 里面现有的 ThreadId,通知之前线程暂停,之前线程将 Markword 的内容置为空。
第三步,两个线程都把锁对象的 HashCode 复制到自己新建的用于存储锁的记录空间,接着开始通过 CAS 操作,把锁对象的 MarKword 的内容修改为自己新建的记录空间的地址的方式竞争 MarkWord。
第四步,第三步中成功执行 CAS 的获得资源,失败的则进入自旋 。
第五步,自旋的线程在自旋过程中,成功获得资源(即之前获的资源的线程执行完成并释放了共享资源),则整个状态依然处于 轻量级锁的状态,如果自旋失败 。
第六步,进入重量级锁的状态,这个时候,自旋的线程进行阻塞,等待之前线程执行完成并唤醒自己。
总结
并发还是得交流一下,有点不明白

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











