






1.创建文件
f = open("new_file.txt", "w") # 创建并打开
f.write("some text...") # 在文件里写东西
f.close() # 关闭
这个文件会被保存在哪呢?正常来说,他会保存在你脚本的当前目录下,比如所你运行的是 me.py 脚本, 那么 new_file.txt 就会被创建在这个脚本的同级目录中。"w"中的w规定必须是小写,否则报错!
|- me.py |- new_file.txt
a=[1,2,3,5]
with open("new_file2.txt", "w") as f:
for i in range(4):
f.writelines([f"{a[i]}\n"])上面 这个方式把打开和关闭嵌入到了一个 with 架构中,这样就不用担心忘记关闭文件了, 下面这个案例,这个地方还用了一种写入数据的方式 writelines(), 当你传入的时候像列表样的数据时, 列表中的每个元素就是一行记录,数据会分行来写。注意,在列表里,每个元素最后都最好写一个\n来表示要另起一行。不然读出来的时候就黏在一起了。
ps:输出语句中 f "{ xxxxx a[i] xxxxxx } ",可以实现将一个字符串中的列表元素进行输出
2.读文件
f = open("new_file2.txt", "r")
print(f.read())
f.close()读文件就是把"w" 改成"r" , 进行f.read()操作就可以看到文件的内容。
with open("new_file2.txt", "r") as f:
print(f.readlines())在读文件的时候, 也可以 readlines() 直接读出来一个列表。
with open("new_file2.txt", "r") as f:
while True:
line = f.readline()
print(line)
if not line:
break如果一次性读取一个这么大的文件,很有可能你的内存都放不下。 我们可以一行一行读取,取代一次性读取,不让内存被一次性占满 。注意:readlines() 一次性直接读取了一个列表,而readline()读取了列表的一个元素。
3.文件编码,中文乱码
在做中文项目的时候,有一个很头疼的事情,很有可能你的文件是从不同平台拿过来的,比如 Windows 的文件要在 MacOS 里打开。 英文的还好,一般不会有什么问题,但是中文的就很容易出现编码不一的情况,出现中文乱码。这时候我们怎么办呢? 首先你要弄清楚原文件的编码,通常来说是 utf-8、gbk、gb2312其中的某一种。
下面我模拟一下,有些文件在 Windows 存储的时候,是以 gbk 的格式存储的,下面的 chinese.txt 我就模拟用 gbk 编码保存。 注意这里我选用的写模式 w 还多了一个 b,合起来是 wb,意思是 write binary 形式,取代默认的 text 形式。所以我读的时候, 也加上了一个 b,变成了 rb,read binary。你点运行试试,他会给你出一段乱码,因为Python不识别这段编码后的文本。
with open("chinese.txt", "wb") as f:
f.write("这是中文的,this is Chinese".encode("gbk"))
with open("chinese.txt", "rb", ) as f:
print(f.read())
#print(f.read().decode('gbk')) # windows在本机尝试,可以试试这个,
# 我的win10可以正常输出运行结果:
b'\xd5\xe2\xca\xc7\xd6\xd0\xce\xc4\xb5\xc4\xa3\xacthis is Chinese'
那直接用原始的 r 来读文本呢?mac系统甚至都会报一个错。读不了(我的win10可以正常输出)。
怎么办?方法还是有的,先确认是哪一种文件编码,然后在读的时候,需要传入一个 encoding 的参数,表示用这一种编码来读。 这样中文乱码的问题就顺利解决了(win10和mac都可以正常输出)。
with open("chinese.txt", "r", encoding="gbk") as f:
print(f.read())运行结果:
这是中文的,this is Chinese
4.一些常见的模式
r+ 可读可写,没有文件报错,这个模式下 写入内容,会将原内容进行替换。
with open("new_file.txt", "r") as f:
print(f.read())
with open("new_file.txt", "r+") as f:
f.write("text has been replaced")
f.seek(0) # 将开始读的位置从写入的最后位置调到开头
print(f.read())运行结果:
some text.....
text has been replaced
如果使用 r+ 模式写入内容,不用f.seek(0),不输出内容。
运行结果:
a+ 可读写,此模式可在原文本内容的末尾添加新内容
with open("new_file.txt", "a+") as f:
print(f.read())
f.write("\nadd new line")
f.seek(0) # 将开始读的位置从写入的最后位置调到开头
print(f.read())
此模式下,如果不用f.seek(0),原始文本内容和更新以后的文本内容都不会输出。
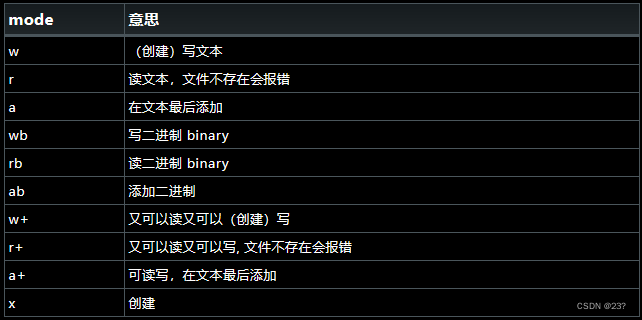
5.更多读写模式















 773
773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









