







想不到我也能更新这种东西了
原文链接~~~~~
[小技巧] 使用tabula批量提取pdf中的表格 https://mp.weixin.qq.com/s/HWLneqJj42ywLghPR-ushA
https://mp.weixin.qq.com/s/HWLneqJj42ywLghPR-ushA
起因是这段时间在写发展报告,需要摘出来XX年鉴(pdf)中的数据,大家懂的,有很多表格,倒是可以复制,但粘贴到excle里格式也会乱。恰巧看到青大公众号【技能分享】一行代码从PDF中提取表格的这个文章,幸亏没什么代码,只需要装个tabula_py库。
然后我就把代码粘过来试了试。
import tabula
#读取pdf数据,并取pdf中的第一个表格
df = tabula.read_pdf(r'C:\Users\yidianguihua\Desktop\tst.pdf',pages='all')[0]
#不带索引写出表格到磁盘
df.to_excel(r'C:\Users\yidianguihau\Desktop\tst.xlsx',index=None)雀食很快。
但我的pdf有十几页,手动改这个[0]也很麻烦的,我这种认知水平也不要求太多,能批量提取出来便好了。因此进行修改,可以从test0到test10,每次都建立一个新的表格出来。
import pandas as pd
import tabula
df = [0]*2
path = [0]*2
pathroot = 'C:/Users/yidianguihua/Desktop/'
for i in range(0, 2):
df[i] = tabula.read_pdf(r'C:\Users\yidianguihua\Desktop\test.pdf',pages='all')[i]
path[i] = pathroot +'test' + str(i)+ '.xlsx'
#不带索引写出表格到磁盘
df[i].to_excel(path[i] , index=None)导出前2页,两个excle静静的躺在了桌面
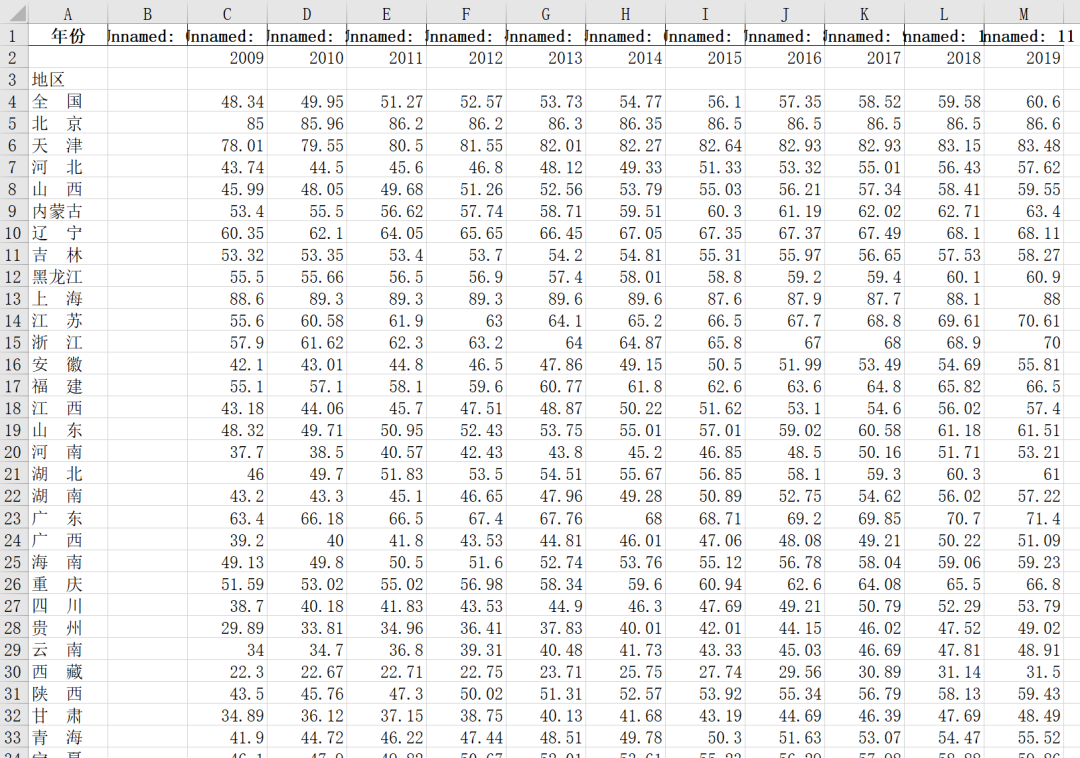
我知道格式还是有些问题,但已经为我省了不少时间了

















 1565
1565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









