







GPU能够通过内部极多进程的并行运算,取得比CPU高一个数量级的运算速度。所以本文描述一下如何在GPU上训练模型。
要想在GPU上训练那么就必须要有NVIDIA独显。如果没有下面提供的代码也可以在CPU上运行。
GPU上训练模型和CPU上操作差不多,只需把驱动改为GPU即可
方法1:在 网络模型、数据(输入inputs,标注targets)、损失函数 三处后面加上 .cuda()
flag = torch.cuda.is_available()
# 网络模型
model = Model()
if flag:
model = model.cuda()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
if flag:
loss_fn = loss_fn.cuda()
# 数据(输入inputs,标注targets)
imgs, targets = data
if flag:
imgs = imgs.cuda()
targets = targets.cuda()
方法2(常用):1.获取gpu[或cpu(防止没有gpu的时候报错)]device;2在 网络模型、数据(输入inputs,标注targets)、损失函数 三处后面加上 .to(device)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 网络模型
model = Model()
model.to(device)
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn.to(device)
# 数据(输入inputs,标注targets)
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
下面是在GPU上训练一个简单的模型,用来进行图像分类。
准备工作
首先需要安装anaconda平台,安装pytorch,在pytorch官网上选择自己的系统、cuda版本(如果没有独立显卡就选择CPU),将命令复制到conda中执行。
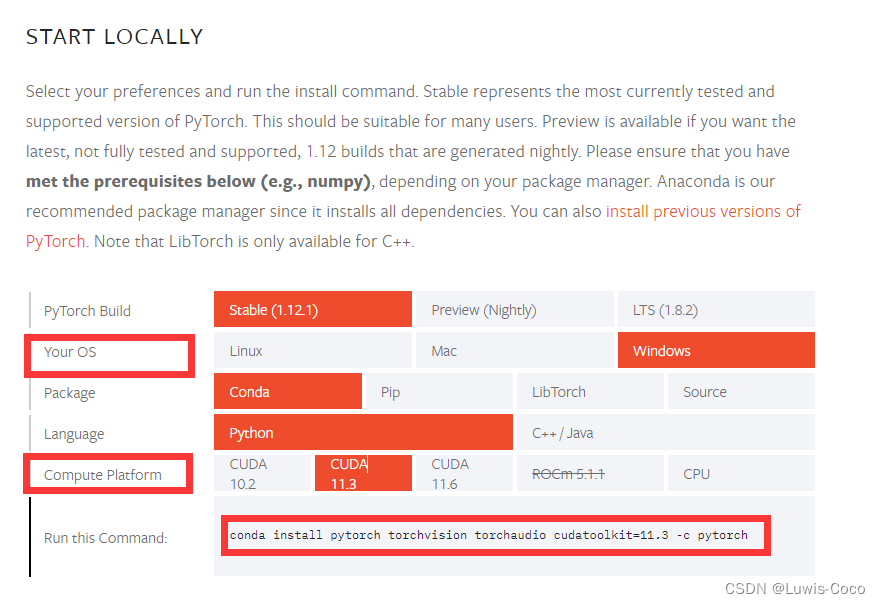
具体如何操作,网上有很多帖子。
模型训练
网络模型来自the model structural of CRFAR10
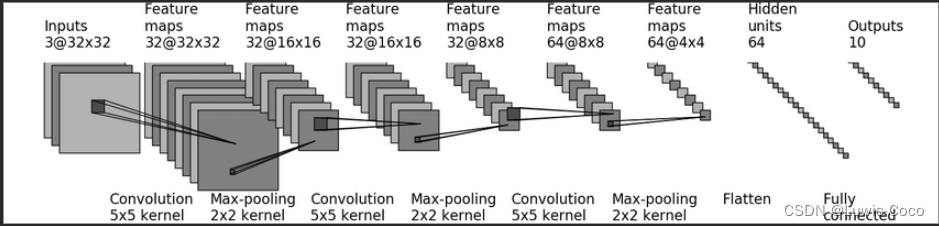
注意:需要在当前的路径下建立一个model_data文件夹用来保存每几轮训练后模型的参数。保存的模型参数要在下一步用来恢复模型。
# 准备数据集
import time
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 定义训练设备,默认为gpu,若没有gpu则在cpu上训练
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_data = torchvision.datasets.CIFAR10('../dataset', True, transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10('../dataset', False, transform=torchvision.transforms.ToTensor(), download=True)
train_data_size = len(train_data) # 获取训练集长度
test_data_size = len(test_data) # 获取测试集长度
print("训练集长度:{}, 测试集长度:{}".format(train_data_size, test_data_size))
# 用 DataLoader加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
model = Model()
model.to(device)
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn.to(device)
# 优化器
learning_rate = 0.01 # 1e-2 = 10^-2
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# 设置训练网络的参数
total_train_step = 0 # 训练次数
total_test_step = 0 # 测试次数
epoch = 10 # 训练轮数
# 添加tensorboard
writer = SummaryWriter("../logs_train")
for i in range(epoch):
print("--------------第{}轮训练开始---------------".format(i+1))
# 训练开始
model.train()
for data in train_dataloader:
if total_train_step % 100 == 1:
start_time = time.time()
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = model(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
end_time = time.time()
print("训练次数:{},loss:{:.3f},time:{:.3f}".format(total_train_step, loss.item(), end_time-start_time))
writer.add_scalar('train_loss', loss.item(), total_train_step)
# 测试开始
model.eval()
total_test_loss = 0
total_accuracy = 0 # 整体正确预测的个数
with torch.no_grad(): # 清空梯度
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = model(imgs)
loss = loss_fn(outputs, targets)
total_test_loss += loss
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy
print("测试集上的平均loss: {:.3f}".format(total_test_loss/len(test_dataloader)))
print("整体测试集上的正确率:{:.3f}".format(total_accuracy/test_data_size))
writer.add_scalar('test_loss', total_test_loss, total_test_step)
writer.add_scalar('test_accuracy', total_accuracy/test_data_size, total_test_step)
total_test_step += 1
# 保存训练模型
# torch.save(model, "../model_data/model_{}.pth".format(i+1))
if i % 100 == 0:
torch.save(model.state_dict(), "../model_data/model_{}.pth".format(i + 1))
print("模型已保存!")
writer.close()
可以是由tensorboard查看模型训练的数据,打开终端输tensorboard --logdir=logs_train,把下面地址复制到浏览器就可以看到训练是的数据了
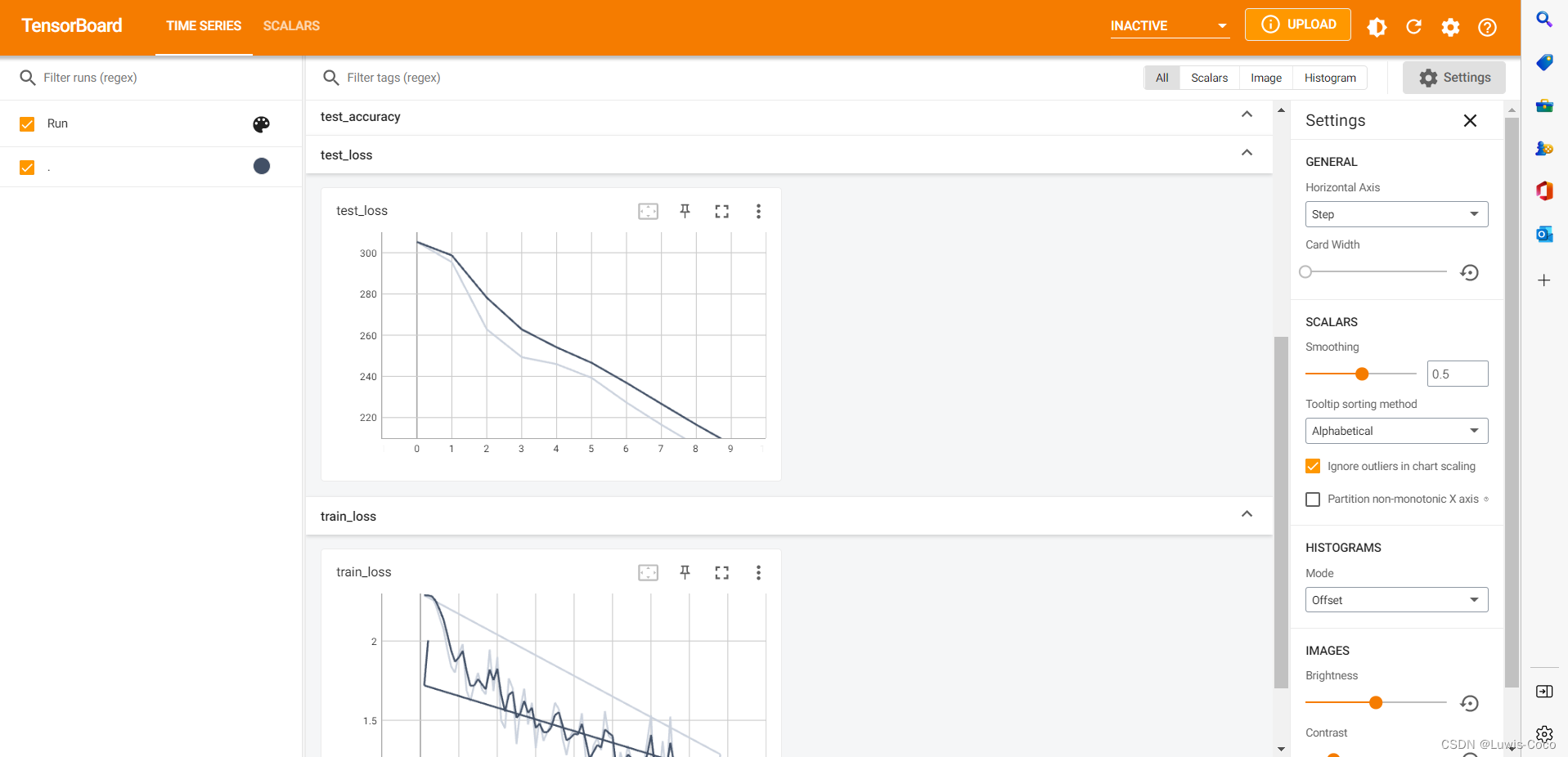
可以看到模型在训练集和测试集上的loss都在减小
模型测试
可以下载一些图片测试模型是否能够分类正确,我这里为了方便只下载了一张图片,如果想要测试多张照片可以修改代码完成测试(在image_path获取图片的list,然后分别输入模型中)
import torch
import torchvision
from PIL import Image
from torch import nn
image_path = "../images/dog.jpg"
image = Image.open(image_path)
image = image.convert('RGB')
print(image)
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()
])
image = transform(image)
print(image.shape)
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
model = Model()
model.load_state_dict(torch.load("../model_data/model_10.pth", map_location=torch.device('cuda:0')))
image = torch.reshape(image, (1, 3, 32, 32))
model.eval()
with torch.no_grad():
output = model(image)
print(output)
classes = torchvision.datasets.CIFAR10('../dataset', True, transform=torchvision.transforms.ToTensor(), download=True).classes
print(classes[output.argmax(1)])
这是我测试的图

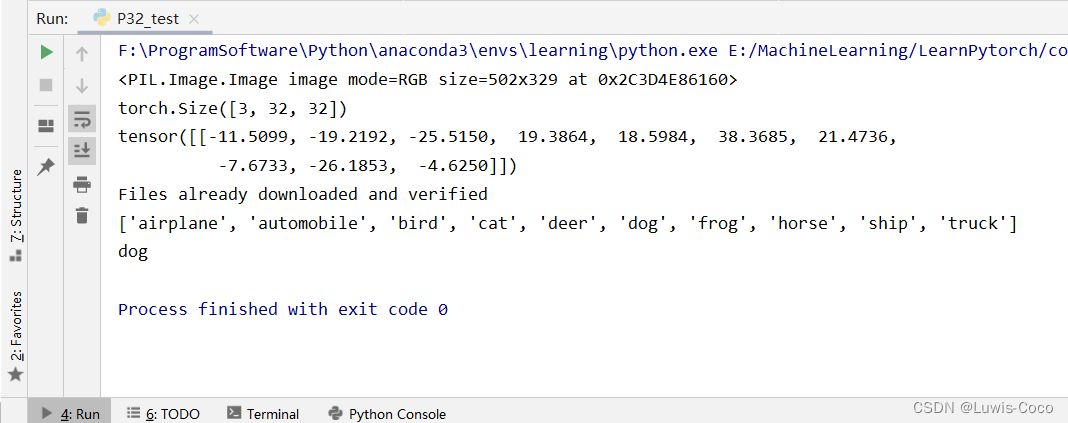
这里是只经过10轮的训练(epoch=10,learning_rate=0.01),可能会在一些照片上出现分类错误的情况,我在服务器上对模型进行了epoch=200,learn_rate=0.0001和epoch=400,learning_rate=0.01的训练,模型参数在这para.zip,需要的话可以下载领取。
学习率太高或者太低都会导致模型的泛化效果不好,可以参考O2U-Net中的环形学习率,个人觉得应该可以提高精度。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









