







目录
说明(详细的说明请看代码注释)
1.程序所需的识别图片,可自己手写,然后放到与代码相同目录下即可。
这里有提供实例图片下载链接:
https://www.aliyundrive.com/s/M5SBkJ1D35s
代码
说明:
halcon12.0版本的
read_ocr_class_mlp的第一个参数,手写识别功能的字段名称是 'HandWritten_0-9.omc'
与halcon19.0版本的有区别,19.0的版本为'HandWritten_0-9_Rej.omc' 请注意!!!
如果以19.0的版本打开,且参数还是read_ocr_class_mlp 'HandWritten_0-9.omc'的话会报错!!
因为新版本的名称已经修改!!!
代码已默认改为'Document_0-9_NoRej.omc'
*作者:胡一鸣 202230152102
********************************
*程序功能:识别0-9数字(修改参数可识别字母,或者同时识别)
*识别场景:白色or米黄色背景和黑色字体,如果识别率不高,请稍微调整threshold阈值
*识别结果:会在图片的左上角以蓝色字体呈现
********************************
dev_close_window ()
*读取图片
*提供一张文档数字图片 one,后缀为png
*提供手写数字图片 three,six,seven,four,eight,后缀为png
*提供一张手写字母图片 letter,后缀为png
read_image(image,'seven.png')
*获取图片尺寸
get_image_size (image, Width, Height)
dev_open_window (0, 0, 640, 400, 'black', WindowHandle)
dev_set_line_width (3)
dev_set_draw ('margin')
*设置字体
set_display_font (WindowHandle, 25, 'mono', 'true', 'false')
*创建OCR识别
*第一个参数说明:(可根据情况修改)
* 'HandWritten_0-9_Rej.omc' ->识别手写数字
* 'Document_0-9_NoRej.omc' ->识别文档数字(手写的识别率也可以)
* 'Document_A-Z+_NoRej.omc' ->识别文档字母(手写的识别率也可以)
* 'Document_0-9A-Z_NoRej.omc' ->识别文档数字和字母
read_ocr_class_mlp ('Document_0-9_NoRej.omc',OCRHandle)
*平滑处理
mean_image (image, Mean, 3, 3)
*转灰度图
rgb1_to_gray (Mean, GrayImage)
*阈值分割(如果识别率比较低,请调整阈值!!)
threshold (GrayImage, ForegroundRaw, 0, 128)
*分割连通的区域,便于数字排序
connection (ForegroundRaw, NumberParts)
*数字排序(从左到右)
sort_region (NumberParts, FinalNumbers, 'character', 'true', 'row')
*获取字符数量
count_obj (FinalNumbers, NumNumbers)
*将所有区域变为一个整体,准备识别
union1 (FinalNumbers, NumberRegion)
*OCR识别
do_ocr_multi_class_mlp (FinalNumbers, image, OCRHandle, RecChar, Confidence)
dev_display (image)
*打印识别结果
disp_message (WindowHandle, '识别结果: ' + sum(RecChar), 'window', 0, -1, 'blue', 'false')
效果展示
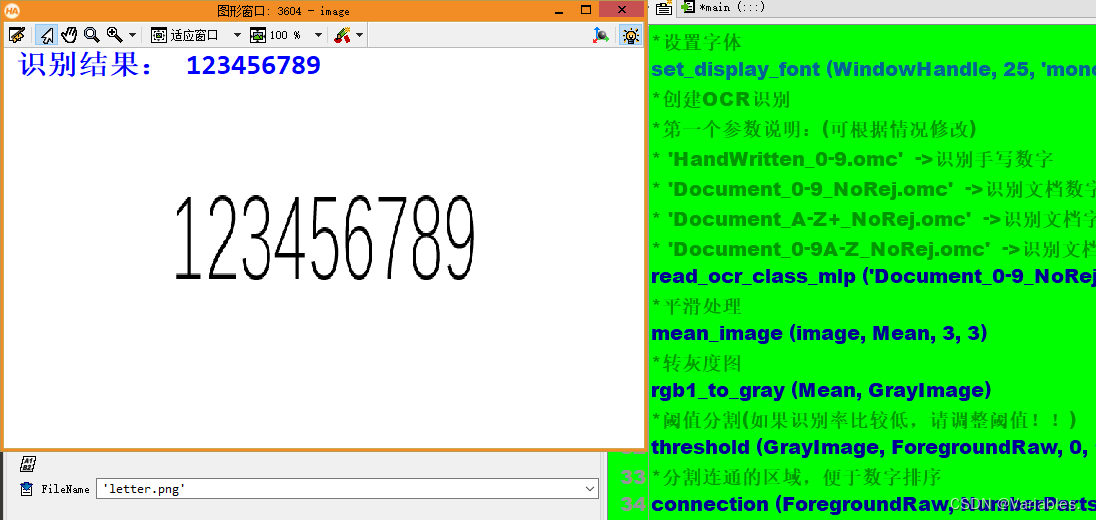
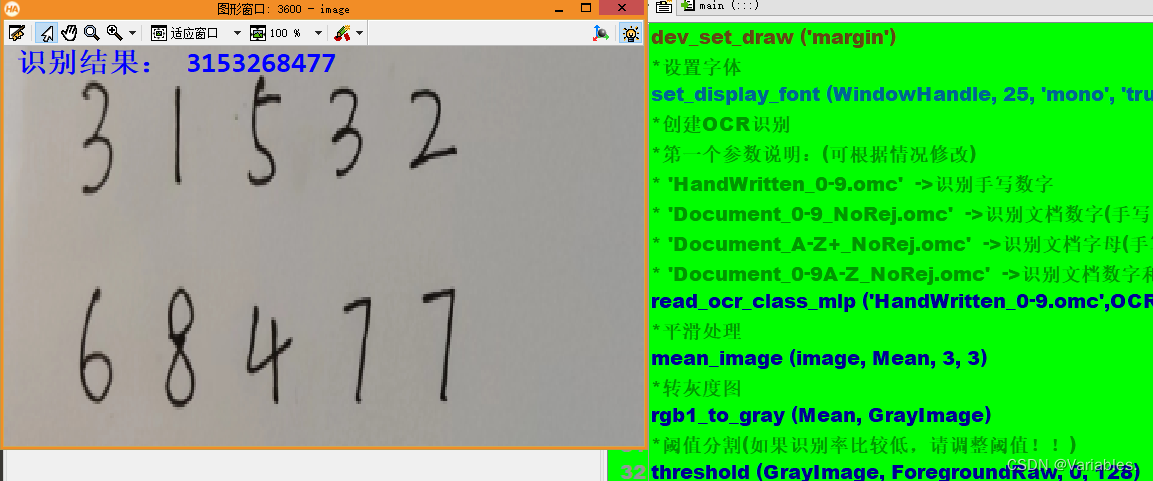
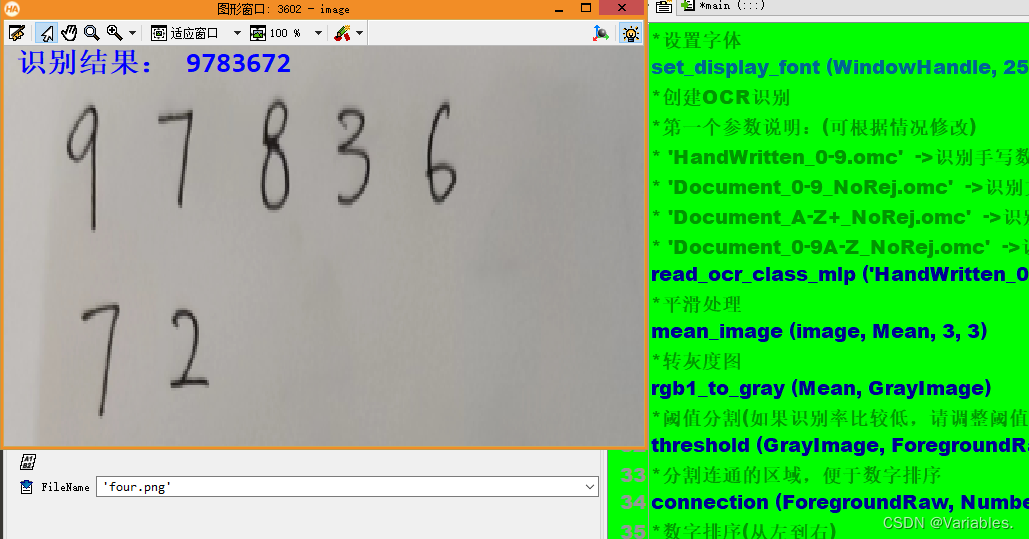

















 278
278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











