






DDPM相关
这里是与DDPM相关的专题文章的代码解释
文章目录
前言
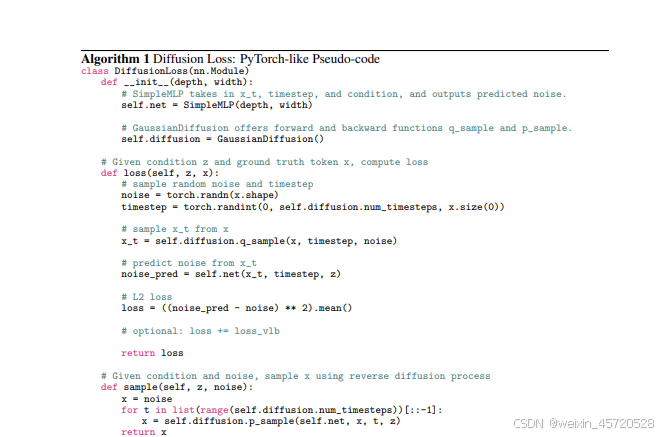
这里附上原始的DDPM讲解的链接,这篇文章是关于对《Autoregressive Image Generation without Vector Quantization》的关于diffusion loss 的讲解,简而言之就是讲明白下面这幅图究竟做了什么,或者说可以参看下面原始论文给出的伪代码。至于mae部分的讲解我会另开一篇博客的,还有就是原始的ddpm和这里的区别。
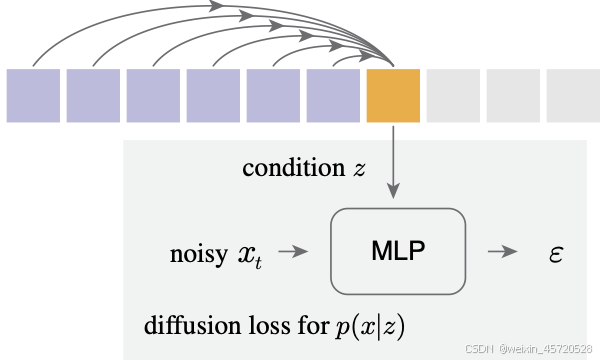
一、前向传播过程
这里是mar算loss 的过程
def forward_loss(self, z, target, mask):
bsz, seq_len, _ = target.shape
# target.shape torch.Size([16, 256, 16])
target = target.reshape(bsz * seq_len, -1).repeat(self.diffusion_batch_mul, 1)
# target.shape torch.Size([4096, 16])
#z.shape torch.Size([16, 256, 768])
z = z.reshape(bsz*seq_len, -1).repeat(self.diffusion_batch_mul, 1)
# z.shape torch.Size([4096, 768])
mask = mask.reshape(bsz*seq_len).repeat(self.diffusion_batch_mul)
#mask.shape torch.Size([4096])
将这个过程对应为上面这幅图
loss = self.diffloss(z=z, target=target, mask=mask)
return loss
然后这个mar 中的每一个token是怎么算loss的呢 就会进入到diffLoss里的前向传播过程
def forward(self, target, z, mask=None):
t = torch.randint(0, self.train_diffusion.num_timesteps, (target.shape[0],), device=target.device)
# t.shape torch.Size([4096])
model_kwargs = dict(c=z)
loss_dict = self.train_diffusion.training_losses(self.net, target, t, model_kwargs)
loss = loss_dict["loss"]
if mask is not None:
loss = (loss * mask).sum() / mask.sum()
return loss.mean()
至此下一步我们将深入到这个self.train_diffusion.training_losses 这里去一探究竟。
二、training losses
在了解这个函数之前,我们先来了解一些基本的定义
class ModelMeanType(enum.Enum):
"""
Which type of output the model predicts.
"""
PREVIOUS_X = enum.auto() # the model predicts x_{t-1}
START_X = enum.auto() # the model predicts x_0
EPSILON = enum.auto() # the model predicts epsilon
class ModelVarType(enum.Enum):
"""
What is used as the model's output variance.
The LEARNED_RANGE option has been added to allow the model to predict
values between FIXED_SMALL and FIXED_LARGE, making its job easier.
"""
LEARNED = enum.auto()
FIXED_SMALL = enum.auto()
FIXED_LARGE = enum.auto()
LEARNED_RANGE = enum.auto()
class LossType(enum.Enum):
MSE = enum.auto() # use raw MSE loss (and KL when learning variances)
RESCALED_MSE = (
enum.auto()
) # use raw MSE loss (with RESCALED_KL when learning variances)
KL = enum.auto() # use the variational lower-bound
RESCALED_KL = enum.auto() # like KL, but rescale to estimate the full VLB
def is_vb(self):
return self == LossType.KL or self == LossType.RESCALED_KL
def training_losses(self, model, x_start, t, model_kwargs=None, noise=None):
"""
Compute training losses for a single timestep.
:param model: the model to evaluate loss on.
:param x_start: the [N x C x ...] tensor of inputs.
:param t: a batch of timestep indices.
:param model_kwargs: if not None, a dict of extra keyword arguments to
pass to the model. This can be used for conditioning.
:param noise: if specified, the specific Gaussian noise to try to remove.
:return: a dict with the key "loss" containing a tensor of shape [N].
Some mean or variance settings may also have other keys.
"""
if model_kwargs is None:
model_kwargs = {}
if noise is None:
noise = th.randn_like(x_start)
#加噪过程
x_t = self.q_sample(x_start, t, noise=noise)
terms = {}
# 这里的if和elif 总的来说一个走的kl 一个走的mse 然后里面再有rescaled的分支
self.loss_type <LossType.MSE: 1>
if self.loss_type == LossType.KL or self.loss_type == LossType.RESCALED_KL:
terms["loss"] = self._vb_terms_bpd(
model=model,
x_start=x_start,
x_t=x_t,
t=t,
clip_denoised=False,
model_kwargs=model_kwargs,
)["output"]
if self.loss_type == LossType.RESCALED_KL:
terms["loss"] *= self.num_timesteps
elif self.loss_type == LossType.MSE or self.loss_type == LossType.RESCALED_MSE:
model_output = model(x_t, t, **model_kwargs)
#看看这个model_var_type 是属于上面枚举类型中的哪个
#self.model_var_type <ModelVarType.LEARNED_RANGE: 4>
if self.model_var_type in [
ModelVarType.LEARNED,
ModelVarType.LEARNED_RANGE,
]:
B, C = x_t.shape[:2]
# B 4096 C 16
assert model_output.shape == (B, C * 2, *x_t.shape[2:])
model_output, model_var_values = th.split(model_output, C, dim=1)
# Learn the variance using the variational bound, but don't let
# it affect our mean prediction.
frozen_out = th.cat([model_output.detach(), model_var_values], dim=1)
# frozen_out.shape torch.Size([4096, 32])
terms["vb"] = self._vb_terms_bpd(
model=lambda *args, r=frozen_out: r,
x_start=x_start,
x_t=x_t,
t=t,
clip_denoised=False,
)["output"]
if self.loss_type == LossType.RESCALED_MSE:
# Divide by 1000 for equivalence with initial implementation.
# Without a factor of 1/1000, the VB term hurts the MSE term.
terms["vb"] *= self.num_timesteps / 1000.0
target = {
ModelMeanType.PREVIOUS_X: self.q_posterior_mean_variance(
x_start=x_start, x_t=x_t, t=t
)[0],
ModelMeanType.START_X: x_start,
ModelMeanType.EPSILON: noise,
}[self.model_mean_type]
# self.model_mean_type <ModelMeanType.EPSILON: 3>
assert model_output.shape == target.shape == x_start.shape
terms["mse"] = mean_flat((target - model_output) ** 2)
if "vb" in terms:
terms["loss"] = terms["mse"] + terms["vb"]
else:
terms["loss"] = terms["mse"]
else:
raise NotImplementedError(self.loss_type)
return terms
这段代码让我感觉计算loss有点怪的,就是要不就是计算KL loss 要不就是计算MSE loss,然后计算MSE的loss 根据这个方差是模型学出来的呢还是固定的呢又设置了一个分支,如果是学出来的那么要依靠变分下界来学这个模型的方差.但是呢在loss加上了这个klloss 就相当于用了这个变分下界来把控模型的生成了.
三、模型架构
相比于原始的ddpm,此处的模型架构为了快捷和验证连续loss的有效性,原文只用了一个简单的mlp。
class _WrappedModel:
def __init__(self, model, timestep_map, original_num_steps):
self.model = model
self.timestep_map = timestep_map
# self.rescale_timesteps = rescale_timesteps
self.original_num_steps = original_num_steps
def __call__(self, x, ts, **kwargs):
map_tensor = th.tensor(self.timestep_map, device=ts.device, dtype=ts.dtype)
new_ts = map_tensor[ts]
# if self.rescale_timesteps:
# new_ts = new_ts.float() * (1000.0 / self.original_num_steps)
return self.model(x, new_ts, **kwargs)
我们会发现在进去模型之前会经过这里,但是经过处理后发现new_ts 和原来的ts是一样的,因此可以先把这里当作一个黑箱,直接没有这步就是传了参数后直接到模型内部。
1、构造函数
class SimpleMLPAdaLN(nn.Module):
"""
The MLP for Diffusion Loss.
:param in_channels: channels in the input Tensor.进来的tensor的通道
:param model_channels: base channel count for the model.进了模型后,tensor此时的通道
:param out_channels: channels in the output Tensor.刚出模型时 tensor的通道
:param z_channels: channels in the condition. 条件z的channels,这里应该是16
:param num_res_blocks: number of residual blocks per downsample. 下采样中含有的残差块的数量
"""
def __init__(
self,
in_channels,
model_channels,
out_channels,
z_channels,
num_res_blocks,
):
super().__init__()
self.in_channels = in_channels
self.model_channels = model_channels
# self.model_channels = 1536
self.out_channels = out_channels
self.num_res_blocks = num_res_blocks
self.time_embed = TimestepEmbedder(model_channels)
self.cond_embed = nn.Linear(z_channels, model_channels)
self.input_proj = nn.Linear(in_channels, model_channels)
res_blocks = []
for i in range(num_res_blocks):
res_blocks.append(ResBlock(
model_channels,
))
self.res_blocks = nn.ModuleList(res_blocks)
self.final_layer = FinalLayer(model_channels, out_channels)
self.initialize_weights()
2、前向传播函数
def forward(self, x, t, c):
"""
Apply the model to an input batch.
:param x: an [N x C x ...] Tensor of inputs.
:param t: a 1-D batch of timesteps.
:param c: conditioning from AR transformer.
:return: an [N x C x ...] Tensor of outputs.
"""
# input x.shape torch.Size([4096, 16])
x = self.input_proj(x)
#output x.shape torch.Size([4096, 1536])
#input t torch.Size([4096])
t = self.time_embed(t)
#output t torch.Size([4096, 1536])
# input c
c = self.cond_embed(c)
# output c torch.Size([4096, 1536])
y = t + c
# output y torch.Size([4096, 1536])
for block in self.res_blocks:
x = block(x, y)
output x torch.Size([4096, 1536])
return self.final_layer(x, y)
3、里面的细分block
modulate
modulate函数功能分析
从数学形式上看:
当scale = 0时,函数退化为x + shift,此时相当于对x进行了简单的平移操作,平移量由shift决定。
当shift = 0时,函数变为x * (1 + scale),这相当于对x进行了缩放操作,缩放因子为1 + scale。
一般情况下,该函数同时结合了平移和缩放操作,通过shift和scale来对输入x进行灵活的变换。
在ResBlock类中的作用
在ResBlock类的forward方法中,modulate函数用于对经过层归一化(self.in_ln(x))后的输入x进行调制。
具体来说,shift_mlp和scale_mlp是由self.adaLN_modulation(y)计算得到的,它们分别作为shift和scale参数传入modulate函数。
这种调制操作有助于根据y的数据特征来动态地调整输入x的分布,可能有助于模型更好地学习数据中的特征和关系,进而提高模型的性能。
def modulate(x, shift, scale):
return x * (1 + scale) + shift
Resblock
结合调制函数的物理意义,残差网络本身的定义,以及改变张量的通道数。
class ResBlock(nn.Module):
"""
A residual block that can optionally change the number of channels.
:param channels: the number of input channels.
"""
def __init__(
self,
channels
):
super().__init__()
self.channels = channels
self.in_ln = nn.LayerNorm(channels, eps=1e-6)
self.mlp = nn.Sequential(
nn.Linear(channels, channels, bias=True),
nn.SiLU(),
nn.Linear(channels, channels, bias=True),
)
self.adaLN_modulation = nn.Sequential(
nn.SiLU(),
nn.Linear(channels, 3 * channels, bias=True)
)
def forward(self, x, y):
shift_mlp, scale_mlp, gate_mlp = self.adaLN_modulation(y).chunk(3, dim=-1)
h = modulate(self.in_ln(x), shift_mlp, scale_mlp)
h = self.mlp(h)
return x + gate_mlp * h
这里和原版的UNET中的ResNet处其实可以对比着分析,有类似的操作
FinalLayer
这里是Diffusion Transformer的最后一层,核心的物理意义应该就是modulate的那个,以及将张量的通道从mlp内部的通道变成输出的通道。
class FinalLayer(nn.Module):
"""
The final layer of DiT.
"""
def __init__(self, model_channels, out_channels):
super().__init__()
self.norm_final = nn.LayerNorm(model_channels, elementwise_affine=False, eps=1e-6)
self.linear = nn.Linear(model_channels, out_channels, bias=True)
self.adaLN_modulation = nn.Sequential(
nn.SiLU(),
nn.Linear(model_channels, 2 * model_channels, bias=True)
)
def forward(self, x, c):
shift, scale = self.adaLN_modulation(c).chunk(2, dim=-1)
x = modulate(self.norm_final(x), shift, scale)
x = self.linear(x)
# x torch.Size([4096, 32])
return x
四. sample过程
inference的代码改自 ,我会放到最后.
我们可以看到一开始传进去的mask是全1的,所以当step为0的时候,64是指只有64个位置的classembedding被送进去编码了,其他都没编码上,然后整个x送进去decoder
def sample_tokens(self, bsz, num_iter=64, cfg=1.0, cfg_schedule="linear", labels=None, temperature=1.0, progress=False):
# init and sample generation orders
mask = torch.ones(bsz, self.seq_len).cuda()
# mask torch.Size([8, 256])
tokens = torch.zeros(bsz, self.seq_len, self.token_embed_dim).cuda()
# tokens torch.Size([8, 256, 16])
orders = self.sample_orders(bsz)
# orders torch.Size([8, 256])
indices = list(range(num_iter))
if progress:
indices = tqdm(indices)
# generate latents
for step in indices:
cur_tokens = tokens.clone()
# class embedding and CFG
if labels is not None:
class_embedding = self.class_emb(labels)
else:
class_embedding = self.fake_latent.repeat(bsz, 1)
if not cfg == 1.0:
tokens = torch.cat([tokens, tokens], dim=0)
# output tokens torch.Size([16, 256, 16])
class_embedding = torch.cat([class_embedding, self.fake_latent.repeat(bsz, 1)], dim=0)
# class_embedding.shape torch.Size([16, 768])
mask = torch.cat([mask, mask], dim=0)
#output mask torch.Size([16, 256])
# mae encoder
x = self.forward_mae_encoder(tokens, mask, class_embedding)
# x.shape torch.Size([16, 64, 768])
# mae decoder
z = self.forward_mae_decoder(x, mask)
# z.shape torch.Size([16, 256, 768])
# mask ratio for the next round, following MaskGIT and MAGE.
mask_ratio = np.cos(math.pi / 2. * (step + 1) / num_iter)
# 随着轮数的增大 mask ratio 逐渐减少
mask_len = torch.Tensor([np.floor(self.seq_len * mask_ratio)]).cuda()
# np.floor 是向下取整
# masks out at least one for the next iteration 并且保证masklen的长度不超过mask的长度
mask_len = torch.maximum(torch.Tensor([1]).cuda(),
torch.minimum(torch.sum(mask, dim=-1, keepdims=True) - 1, mask_len))
# get masking for next iteration and locations to be predicted in this iteration
mask_next = mask_by_order(mask_len[0], orders, bsz, self.seq_len)
if step >= num_iter - 1:
mask_to_pred = mask[:bsz].bool()
else:
mask_to_pred = torch.logical_xor(mask[:bsz].bool(), mask_next.bool())
mask = mask_next
if not cfg == 1.0:
mask_to_pred = torch.cat([mask_to_pred, mask_to_pred], dim=0)
# sample token latents for this step
一般来说0 是 false
z = z[mask_to_pred.nonzero(as_tuple=True)]
# z.shape torch.Size([16, 768])
这里sample的配置传入 cfg = 4 , cfg_schedule = "constant"
# cfg schedule follow Muse
if cfg_schedule == "linear":
cfg_iter = 1 + (cfg - 1) * (self.seq_len - mask_len[0]) / self.seq_len
elif cfg_schedule == "constant":
cfg_iter = cfg
else:
raise NotImplementedError
# 前面是mae中的sample过程,那么这里就是这篇文章的重点,正常在mae中到这部,这个patch 已经被生成出来了,但是由于我们要采用连续性的diffusion loss ,所以还要再过一下的去噪函数.
sampled_token_latent = self.diffloss.sample(z, temperature, cfg_iter)
if not cfg == 1.0:
sampled_token_latent, _ = sampled_token_latent.chunk(2, dim=0) # Remove null class samples
# sampled_token_latent.shape torch.Size([8, 16])
mask_to_pred, _ = mask_to_pred.chunk(2, dim=0)
# mask_to_pred torch.Size([8, 256])
cur_tokens[mask_to_pred.nonzero(as_tuple=True)] = sampled_token_latent
tokens = cur_tokens.clone()
# unpatchify
tokens = self.unpatchify(tokens)
return tokens
mask_to_pred.nonzero(as_tuple = True)的结果如下

sampled_token_latent = self.diffloss.sample(z, temperature, cfg_iter)
def sample(self, z, temperature=1.0, cfg=1.0):
# diffusion loss sampling
if not cfg == 1.0:
noise = torch.randn(z.shape[0] // 2, self.in_channels).cuda()
noise = torch.cat([noise, noise], dim=0)
# noise.shape torch.Size([16, 16])
model_kwargs = dict(c=z, cfg_scale=cfg)
sample_fn = self.net.forward_with_cfg
else:
noise = torch.randn(z.shape[0], self.in_channels).cuda()
model_kwargs = dict(c=z)
sample_fn = self.net.forward
sampled_token_latent = self.gen_diffusion.p_sample_loop(
sample_fn, noise.shape, noise, clip_denoised=False, model_kwargs=model_kwargs, progress=False,
temperature=temperature
)
然后这个过程就类似于原始的DDPM的sample过程了,至于这里和原始的DDPM的区别.由于这里篇幅讲的是生成模型怎么通过diffusion loss取进行生成.区别详见[]
总结
我想这篇文章中能够更好的生成图片离不开两个更重要的点,一个是连续的loss,without vector Quantization 意味着不用原始的离散的loss 意味着减少了信息损失的可能性,第二点可能是因为逐层的架构取分散了生成的压力,就是vae mae mlp 层用不同的方式来分散了生成的压力.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









