






ElasticSearch安装运行
下载并解压ElasticSearch
下载地址: https://www.elastic.co/cn/downloads/past-releases#elasticsearch
选择版本:7.17.3
# 创建文件夹
mkdir /mnt/esdata -p
# 解压
tar -zxvf elasticsearch-7.17.3-linux-x86_64.tar.gz -C /mnt/esdata/
# 添加es用户
adduser esuser
# 打开创建文件夹目录并创建data logs 目录
cd /mnt/esdata/
mkdir data logs
# 为elaticsearch创建用户并赋予相应权限
chown -R esuser:esuser /mnt/esdata/
# 复制一份elasticsearch配置文件
cd elasticsearch-7.17.3/config/
cp elasticsearch.yml elasticsearch.yml.bak
# 修改配置内容
sed -i 's/#path.data: \/path\/to\/data/path.data: \/mnt\/esdata\/data/g' elasticsearch.yml
sed -i 's/#path.logs: \/path\/to\/logs/path.logs: \/mnt\/esdata\/logs/g' elasticsearch.yml
sed -i 's/#network.host: 192.168.0.1/network.host: 0.0.0.0/g' elasticsearch.yml
sed -i 's/#http.port: 9200/http.port: 9200/g' elasticsearch.yml
# 启动ES
su - esuser -c "/mnt/esdata/elasticsearch-7.17.3/bin/elasticsearch -d"
# 添加开机启动
echo 'su - esuser -c "/app/esdata/elasticsearch-7.17.3/bin/elasticsearch -d"' >> /etc/rc.local
注意:es默认不能用root用户启动,生产环境建议为elasticsearch创建用户。
修改JVM配置
修改config/jvm.options配置文件,调整jvm堆内存大小
vim jvm.options
-Xms1g
-Xmx1g
配置的建议
Xms和Xms设置成—样
Xmx不要超过机器内存的50%
不要超过30GB - https://www.elastic.co/cn/blog/a-heap-of-trouble
运行http://localhost:9200/
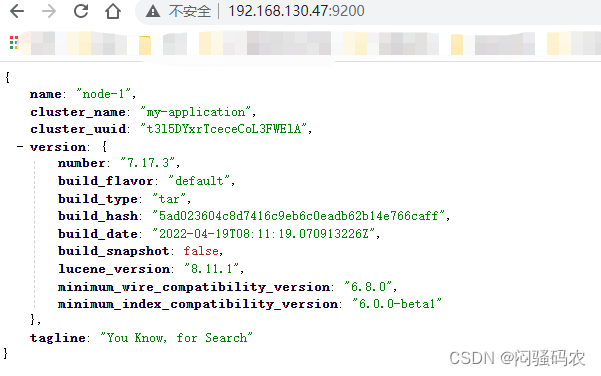
如果ES服务启动异常,会有提示:

启动ES服务常见错误解决方案
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
ES因为需要大量的创建索引文件,需要大量的打开系统的文件,所以我们需要解除linux系统当中打开文件最大数目的限制,不然ES启动就会抛错
echo '* soft nofile 65536' >> /etc/security/limits.conf
echo '* hard nofile 65536' >> /etc/security/limits.conf
echo '* soft nproc 65535' >> /etc/security/limits.conf
echo '* hard nproc 65535' >> /etc/security/limits.conf
echo 'vm.max_map_count=655360' >> /etc/sysctl.conf
sysctl -p
[2]: max number of threads [1024] for user [es] is too low, increase to at least [4096]
无法创建本地线程问题,用户最大可创建线程数太小
vim /etc/security/limits.d/20-nproc.conf
改为如下配置:
* soft nproc 4096
[3]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
最大虚拟内存太小,调大系统的虚拟内存
vim /etc/sysctl.conf
追加以下内容:
vm.max_map_count=262144
保存退出之后执行如下命令:
sysctl -p
[4]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured.
缺少默认配置,至少需要配置discovery.seed_hosts/discovery.seed_providers/cluster.initial_master_nodes中的一个参数.
discovery.seed_hosts: 集群主机列表
discovery.seed_providers: 基于配置文件配置集群主机列表
cluster.initial_master_nodes: 启动时初始化的参与选主的node,生产环境必填
vim config/elasticsearch.yml
#添加配置
discovery.seed_hosts: ["127.0.0.1"]
cluster.initial_master_nodes: ["node-1"]
#或者 单节点(集群单节点)
discovery.type: single-node
Kibana安装
Kibana是一个开源分析和可视化平台,旨在与Elasticsearch协同工作。
1)下载并解压缩Kibana
下载地址:https://www.elastic.co/cn/downloads/past-releases#kibana
选择版本:7.17.3
2)修改Kibana.yml
vim config/kibana.yml
server.port: 5601
server.host: "localhost" #服务器ip
elasticsearch.hosts: ["http://localhost:9200"] #elasticsearch的访问地址
i18n.locale: "zh-CN" #Kibana汉化
server.publicBaseUrl: "http://localhost:5601" #服务器ip
3)运行Kibana
注意:kibana也需要非root用户启动
# root用户先授权
chown -R esuser /usr/local/kibana-7.17.3-linux-x86_64/
#切换到es用户启动服务,root用户启动会报错
su esuser
#cd到启动目录
cd /usr/local/kibana-7.17.3-linux-x86_64/bin/
# 直接启动
./kibana
#后台启动
nohup bin/kibana &
#查询kibana进程
netstat -tunlp | grep 5601
访问Kibana: http://localhost:5601/
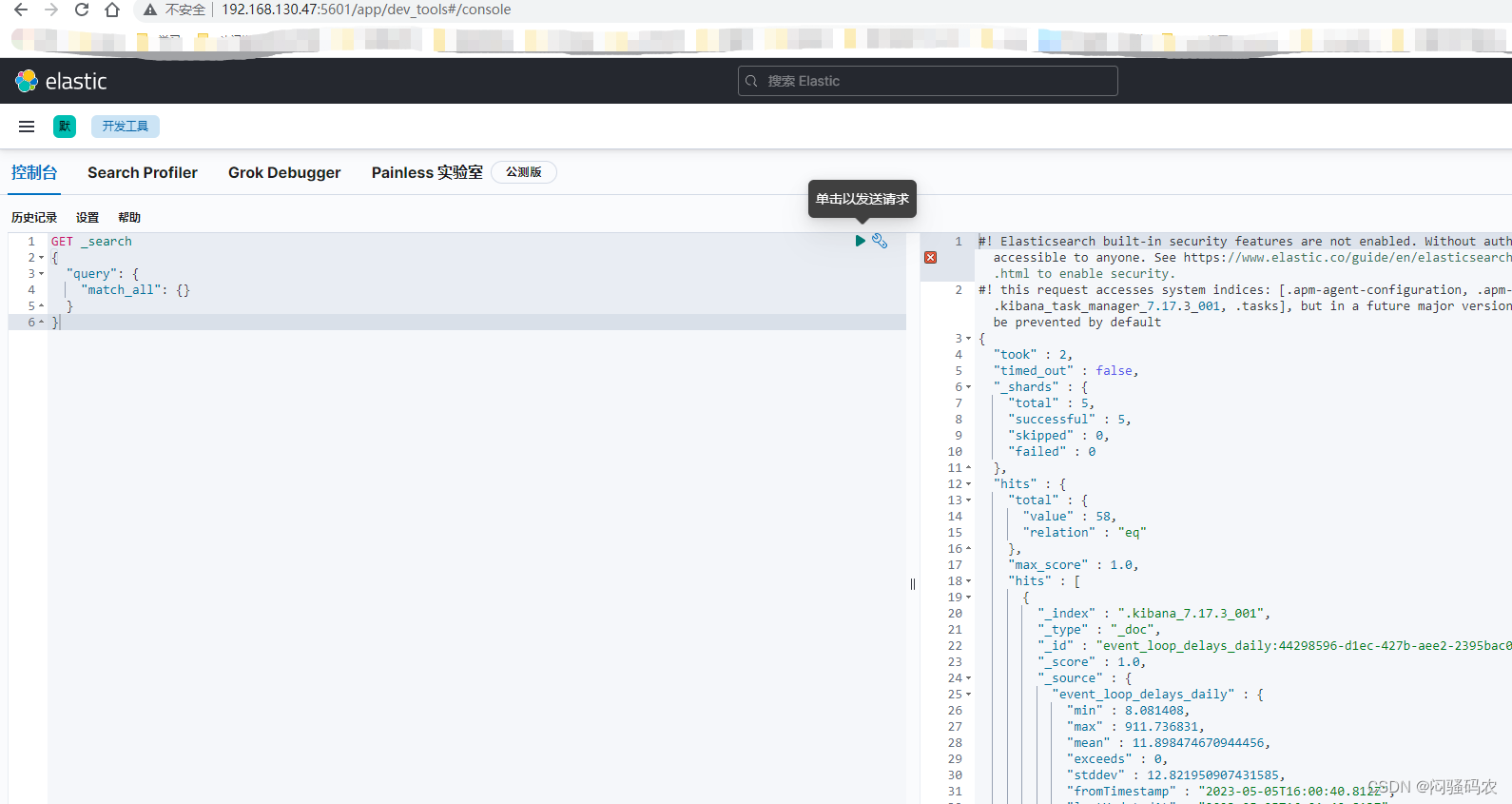
cat API
/_cat/allocation #查看单节点的shard分配整体情况
/_cat/shards #查看各shard的详细情况
/_cat/shards/{index} #查看指定分片的详细情况
/_cat/master #查看master节点信息
/_cat/nodes #查看所有节点信息
/_cat/indices #查看集群中所有index的详细信息
/_cat/indices/{index} #查看集群中指定index的详细信息
/_cat/segments #查看各index的segment详细信息,包括segment名, 所属shard, 内存(磁盘)占用大小, 是否刷盘
/_cat/segments/{index} #查看指定index的segment详细信息
/_cat/count #查看当前集群的doc数量
/_cat/count/{index} #查看指定索引的doc数量
/_cat/recovery #查看集群内每个shard的recovery过程.调整replica。
/_cat/recovery/{index} #查看指定索引shard的recovery过程
/_cat/health #查看集群当前状态:红、黄、绿
/_cat/pending_tasks #查看当前集群的pending task
/_cat/aliases #查看集群中所有alias信息,路由配置等
/_cat/aliases/{alias} #查看指定索引的alias信息
/_cat/thread_pool #查看集群各节点内部不同类型的threadpool的统计信息,
/_cat/plugins #查看集群各个节点上的plugin信息
/_cat/fielddata #查看当前集群各个节点的fielddata内存使用情况
/_cat/fielddata/{fields} #查看指定field的内存使用情况,里面传field属性对应的值
/_cat/nodeattrs #查看单节点的自定义属性
/_cat/repositories #输出集群中注册快照存储库
/_cat/templates #输出当前正在存在的模板信息
Elasticsearch安装分词插件
Elasticsearch提供插件机制对系统进行扩展
以安装analysis-icu这个分词插件为例
在线安装
#查看已安装插件
bin/elasticsearch-plugin list

#安装插件
bin/elasticsearch-plugin install analysis-icu
#删除插件
bin/elasticsearch-plugin remove analysis-icu

注意:安装和删除完插件后,需要重启ES服务才能生效。
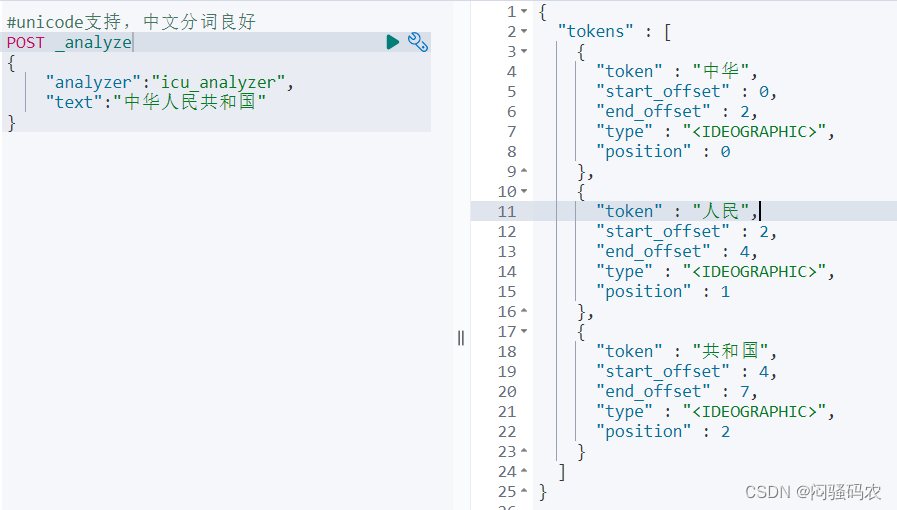
测试分词效果
POST _analyze
{
"analyzer":"icu_analyzer",
"text":"中华人民共和国"
}
离线安装
本地下载相应的插件,解压,然后手动上传到elasticsearch的plugins目录,然后重启ES实例就可以了。
比如ik中文分词插件:https://github.com/medcl/elasticsearch-analysis-ik
测试分词效果
#ES的默认分词设置是standard,会单字拆分
POST _analyze
{
"analyzer":"standard",
"text":"中华人民共和国"
}
#ik_smart:会做最粗粒度的拆
POST _analyze
{
"analyzer": "ik_smart",
"text": "中华人民共和国"
}
#ik_max_word:会将文本做最细粒度的拆分
POST _analyze
{
"analyzer":"ik_max_word",
"text":"中华人民共和国"
}
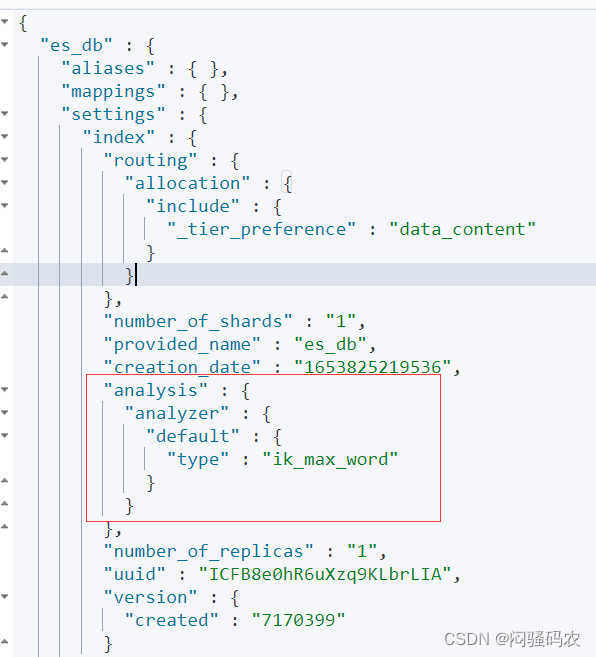
创建索引时可以指定IK分词器作为默认分词器
PUT /es_db
{
"settings" : {
"index" : {
"analysis.analyzer.default.type": "ik_max_word"
}
}
}















 2238
2238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









