





系列文章目录
基于条件加权增量扩散模型的时间序列异常检测 KDD2023
摘要
现有的时间序列异常检测模型主要是用正态点为主的数据进行训练,当异常点集中出现在特定时间段时,异常检测模型就会失效。为了解决这个问题,我们从时间序列imputation的角度提出了一种新的方法,称为DiffAD。与以往基于预测和重建的方法采用部分或完整数据作为观测值进行估计不同,DiffAD采用基于密度比的策略灵活选择正常观测值,可以轻松适应异常浓度场景。为了缓解异常集中情况下的模型偏差问题,我们设计了一种新的基于去噪扩散的方法,通过条件加权增量扩散来提高缺失值的输入性能。该方法可以保留观测值的信息,大大提高数据生成质量,实现稳定的异常检测。此外,我们自定义了一个多尺度状态空间模型,以捕获具有不同异常模式的事件之间的长期依赖关系。在真实数据集上的大量实验结果表明,DiffAD的性能优于最先进的基准测试。
https://github.com/ChunjingXiao/DiffAD
•计算方法→异常检测;•计算数学→时间序列分析。
提示:以下是本篇文章正文内容
一、引言
时间序列异常检测的目的是识别出在时间序列中明显偏离大多数的异常样本。它可以提前提供警告和预防措施,从而潜在地防止大型故障,这对于各种各样的应用程序都非常有意义,例如发现底层系统[55]的异常,监视大规模数据集[44]中的数据故障,以及检测业务操作中KPI的急剧变化[48]。
在实际应用中,异常点往往很少,并且与大量的正态点混合在一起,给数据标注带来困难。因此,大多数研究都集中在使用无监督方法识别异常[4,37]。例如,密度估计[6,50]和聚类方法[38,40]已经被设计用于异常检测,特别是在时间序列的背景下。近年来,得益于神经网络的表征学习能力,基于深度学习的异常检测技术取得了优异的性能,受到了学术界和工业界的广泛关注。它们主要可以归纳为两类:基于预测的[12,51]和基于重建的[49,56]。前者利用历史数据建立预测模型,对后续数据进行推断,然后根据预测值与实测值之间的预测误差判断异常。基于重构的方法基于训练实例重构测试数据,然后基于重构误差进行异常检测。
虽然以往的研究取得了很大的成功,但是当异常点在整个时间序列上不是均匀分布的,而是集中在某些区域时,仍然可能会导致性能下降,我们称之为异常集中现象。在这种情况下,基于预测和重建的方法都可能无法准确识别异常点,因为它们的模型通常是针对正常数据占主导地位的区域进行训练的[4,37]。当异常点集中在某些区域时,在这种情况下,密集的异常点会对估计产生明显的影响,使得现有的方法不合适甚至无效。图1给出了集中异常的示例,其中蓝色点和红色点分别表示正常点和异常点。e2期存在异常浓度事件。典型的基于预测的模型使用过去的值来预测未来,可能会错误地将第三集中的一些点视为异常。这可能导致事件e3中正常点的预测误差较大,并相应地损害异常检测性能。同样的问题也适用于基于重建的方法。我们对实际数据的分析表明,许多异常点彼此相邻(参见2.2节)。因此,需要在考虑异常集中的同时开发一个鲁棒的异常检测模型。
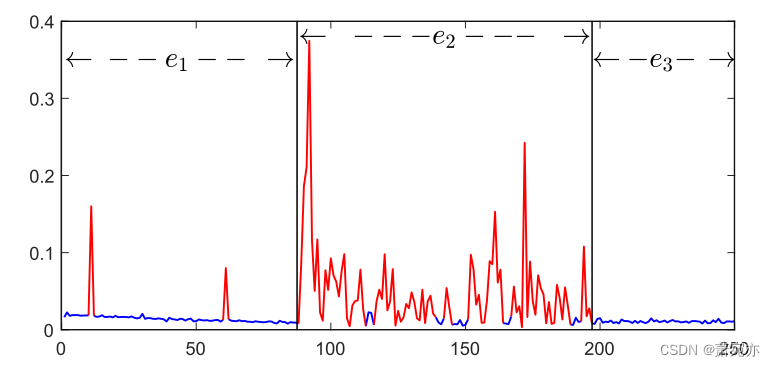
图1:从服务器机器数据集中抽取的异常集中示例。蓝色点和红色点分别表示正常点和异常点。e2为异常集中区,e1和e3为正常资料优势区。
在这项工作中,我们引入了一种时间序列imputation解决方案,用于异常检测,同时解决了异常集中问题。主要思想如下。我们首先选择一小部分离散点作为观测数据(即已知值),其余的作为屏蔽样本(即缺失值)。然后根据观测值估算缺失值。接下来,我们计算估计值与实际值之间的估计误差来检测异常。这样,估计误差越大,被识别为异常的概率就越高。与基于预测和重建的方法不同,该方法可以灵活地选择观测值进行数据估计。该方法在异常优势区选取较少(甚至为零)点作为观测点,减少了异常密集点的影响,缓解了异常集中带来的问题。
本文提出了一种基于扩散的时间序列异常检测插值框架(DiffAD),该框架可以有效地缓解异常集中时的性能下降问题。为了减少异常浓度的影响,我们提出了一种基于密度比的点选择策略,选择更多的正态点作为观测点进行数据估计。选择法线点并不容易,因为它们通常是未知的。幸运的是,一些变化点识别方法可以提供帮助,例如基于密度比的方法,如分离距离变化点检测算法(SEP)[2]。这背后的原理是,对于时间序列数据,大多数变化点都是异常[5,11]。因此,对于时间序列中没有变化点的某些区域,区域越长,所有点为正态的概率越高。这样可以从这些区域中选择更多的点作为观测值。
此外,我们设计了一个条件加权增量扩散模型,根据观测值估计缺失值。该模型以高斯噪声为输入,对反向扩散迭代施加不同权值的条件(即观测值),生成被蒙蔽点的值。与一般以准确估计缺失值为目标的imputation任务不同[26,43],异常检测期望观测点的估计值与真实观测值之间的偏差更小,估计值的失真更小。然而,对于典型的扩散模型,反向扩散迭代产生的观测点值可能会偏离真实的观测值。但是,直接对生成的数据施加条件因子(即在每个时间步长将生成的值替换为实际观测值)可能会使更新后的数据失真。为此,在用力过程中,我们根据迭代次数调整条件的权值,即为以后的迭代增加更大的权值。随着迭代次数的增加,生成的值越来越清晰,偏差和失真逐渐减小。因此,施加较大权重的条件不会造成严重的失真。因此,我们的增量权重策略有助于生成偏差和失真较小的值。这些估计值最终将用于计算估计误差,以用于最终的异常检测。
此外,我们利用扩散模型U-Net中超出异常浓度范围的长期相互作用来减轻异常浓度引起的问题。对于一般扩散模型,如去噪扩散概率模型(DDPM)[19],利用U-Net[35]作为去噪神经网络去噪,产生干净样本。然而,在U-Net中广泛使用的卷积和池化操作不能有效地捕获远程依赖关系[17,18]。结构化状态空间序列(S4)[17]模型在音频波形、电影剪辑和神经语言处理等许多时间序列应用中取得了成功[17,18,21]。在DiffAD中,我们将S4整合到U-Net中,并设计了一个基于S4的多尺度U-Net,该U-Net整合了不同分辨率下不同层的信息,并利用更远距离的相互作用来减轻异常集中的影响。
本研究的贡献有四个方面:
•据我们所知,DiffAD是第一个用于时间序列异常检测的去噪扩散概率模型。我们将异常检测描述为一个生成时间序列的输入过程,这开启了探索时间序列异常检测的DDPM和输入范式的尝试。
•我们提出了一种新的解决方案,使DDPM适应异常检测任务,并确保观测值与生成值之间的一致性,并伴随着一种新的条件加权增量扩散模型,该模型具有特殊设计的多尺度状态空间模型。
•我们提供了一个基于密度比的选择策略,可以灵活地选择正态值作为观测点。这种策略使得检测模型在异常密集的情况下更容易识别出异常点。
•在五个数据集上进行的大量实验证明了DiffAD优于最先进的时间序列异常检测基准。该代码可在线获取1。
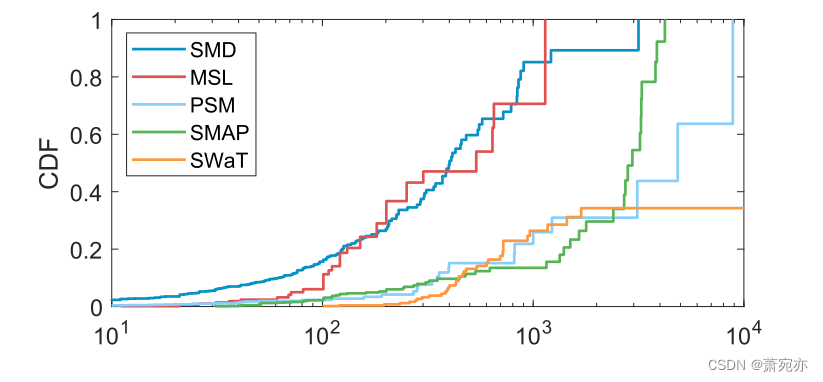
图2:连续异常点的CDFs。
二、 PRELIMINARIES
在本节中,我们对时间序列异常检测问题、异常集中和去噪扩散概率模型进行了初步概述,这些模型是研究问题的基本背景和本工作中提出解决方案的动机。
2.1问题表述
本文主要研究多变量时间序列的无监督异常检测问题。在训练集中,每个样本X表示为一组时间点 { c 1 , c 2 , . . . , c N } \{c_1,c_2,...,c_N\} {c1,c2,...,cN},其中 c i ∈ R d c_i\in\mathbb{R}^d ci∈Rd表示在时间的观测值。无监督时间序列异常检测问题是确定𝑐序列是否异常。
我们假设几个时间点被选择为已知的(观察到的),其余的被掩盖(缺失的)。为了检测异常,我们首先采用时间序列imputation技术来估计掩蔽点的值。然后,通过比较实值和估计值的估计误差来识别异常点。估计误差越高,点异常的可能性越大。
2.2异常集中程度Degree of Anomaly Concentration
异常集中是指在时间序列中某些区域连续出现大量异常点的现象。为了了解异常集中程度,我们研究了5个真实数据集(SMD[41]、PSM[1]、SWaT[29]、MSL和SMAP[20])中连续异常点的数量。连续异常数量的分布如图2所示,其中x轴表示相邻的异常数量。
从数据统计中可以看出,异常现象是连续发生的。即使对于分散异常的数据集,如SMD,也有80%以上的异常点落在连续异常点数大于100的区域。PSM、SMAP、SWaT等大部分数据异常集中度较高,超过70%的异常点落在长度为1000 +的连续异常序列中。这些结果表明,异常集中在整个数据中广泛存在,在异常检测模型中应予以考虑。
2.3扩散概率模型去噪
T步去噪扩散概率模型(DDPM)[19]由两个过程组成:步骤𝑡 ∈ {0, 1, · · · , 𝑇} 的扩散过程和逆过程
t
∈
{
T
,
T
−
1
,
⋯
,
0
}
t\in\{T,T-1,\cdots,0\}
t∈{T,T−1,⋯,0}。 扩散过程
q
(
x
t
∣
x
t
−
1
)
q(x^{t}|x^{t-1})
q(xt∣xt−1)逐渐将某些目标分布
q
d
a
t
a
(
x
0
)
q_{\mathrm{data}}(x^0)
qdata(x0)中的数据破坏为高斯噪声,而反向过程
p
(
x
t
−
1
∣
x
t
)
p(x^{t-1}|x^t)
p(xt−1∣xt)通过将噪声转化为样本来生成样本 来自
X
T
\mathcal{X}^{{T}}
XT。
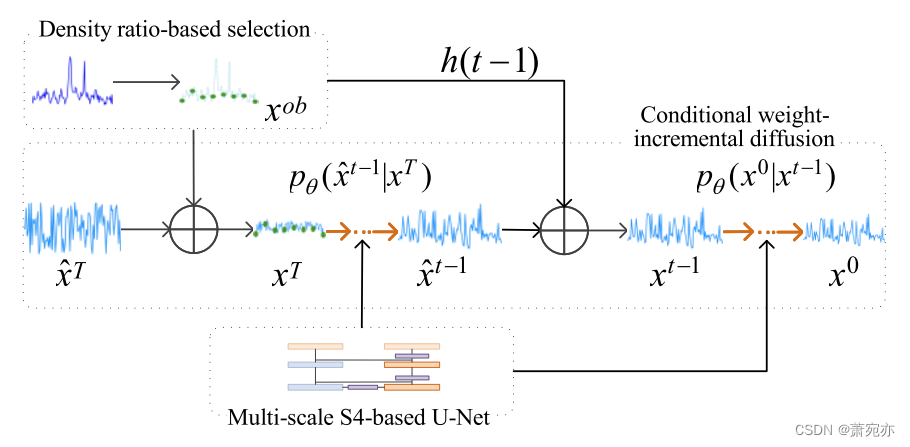
图 3:DiffAD 框架概述。 在估计过程中,首先通过基于密度比的选择策略提取观测值
x
o
b
x^{ob}
xob(绿点)。 然后,通过条件权重增量扩散模型估计缺失值。 对于每次反向扩散迭代,条件
x
o
b
x^{ob}
xob 被施加到生成的数据
x
^
t
−
1
\hat{x}^{t-1}
x^t−1上,权重 ℎ(𝑡 − 1) 随着迭代而增加。 此外,基于 S4 的多尺度 U-Net 旨在学习长期依赖关系。 最后,利用估计值与实际值之间的估计误差来识别异常。
给定数据 χ 0 \chi^{0} χ0,第一步(𝑡 = 0)中的扩散过程 q d a t a ( x 0 ) q_{data}(x^0) qdata(x0)被定义为 R L \mathbb{R}^{L} RL上的数据分布 x 0 x^{0} x0,其中L是样本中的信号长度。 从数据 x 0 \ x^{0} x0到变量 x T \ x^{T} xT的扩散过程可以基于固定马尔可夫链来制定。 相反的过程将潜在变量 x T ∼ N ( 0 , I ) x^T\sim\mathcal{N}(0,I) xT∼N(0,I)转换为 x 0 x^{0} x0,这也是基于马尔可夫链。 典型 DDPM 的数学基础可以在 [19] 中找到。
三、 方法
DiffAD由三个部分组成:基于密度比的点选择策略、条件权重增量扩散模型和基于S4的多尺度U-Net。 这些组成部分的概述如图3所示。为了减少异常浓度的负面影响,基于密度比的点选择策略选择更多正常点作为观测点进行数据估计。 然后,条件权重增量扩散模型尝试根据观测值估计缺失值。 在扩散模型中,涉及基于 S4 的多尺度 U-Net 来捕获远程依赖性,以缓解异常集中引起的问题。 估计值与真实值之间的差异用于识别异常情况,即估计误差越大,出现异常的概率就越高。 为了获得观测点的估计误差,我们首先选择观测点的一组相邻点作为新的观测点。 然后我们用这些新的观测点来估计原始观测点的值,以确定原始观测点是否异常。
3.1 Density Ratio-based Point Selection Strategy基于密度比的选点策略
与基于预测和基于重建的方法不同,我们的异常检测方法中的观测值可以灵活选择。 为了减轻异常浓度的负面影响并提高检测性能,应将更多的正常点指定为观测点。 原因很直观:如果观察到的数据中有更多的正常值,则估计值(例如,根据观察到的数据推断)更有可能接近正常值。 这可能会导致异常情况的估计误差更大,从而产生卓越的检测性能。 因此,选择更多的正常点作为观测点可以显着提高检测性能。
为了实现这一目标,我们设计了一种基于密度比的点选择策略,以选择更多的正常值作为观察值来估计掩模值。 密度比是异常值和变化点检测的有效度量[2,30,47,53],变化点是时间序列行为突然变化的时间点[45]。 对于时间序列数据,大多数变化点可以被视为一种异常[5, 11]。 我们采用基于密度比的敏感变化分数,通过将这些分数与阈值进行比较来确定变化点。 我们策略的主要思想是,对于一段没有变化点的数据,其长度越长,它们是正常点的概率就越高。 相应地,应该选择该数据中更多的点作为观测值。
特别地,我们根据两个连续窗口的密度比来识别变化点,这可以反映窗口之间的变化程度。 为了计算变化分数,我们首先将时间序列数据划分为 ℎ 不相交的窗口,并计算窗口 𝑘 的密度比,如下所示:
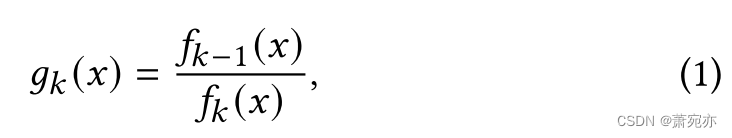
其中
f
k
−
1
(
x
)
a
n
d
f
k
(
x
)
f_{k-1}(x)\mathrm{~and~}f_k(x)
fk−1(x) and fk(x) 分别对应于两个连续窗口的估计概率密度。 然后,计算变化分数:

其中 𝑠 是窗口长度。 CHG 分数越大表明出现变化点的概率越高 [2]。 因此,CHG 分数高于阈值的点被视为变化点 [2]。 由于我们不知道变化点,因此可以根据所有 CHG 分数的分布(例如第 30 个百分位值)来设置阈值。 请注意,我们主要关注降低变化点检测的漏报率,这可以通过使用较低的阈值来增强。 根据 CHG 分数,我们能够提取所有没有显着变化点的区域。
为了获得合适的观测值,选择策略必须满足两个约束:(𝑖)所选点应具有较小的CHG分数,表明它们不是变化点,因此不是异常; (𝑖𝑖) 两个相邻选定点之间的间隔不应该太大,因为大的间隔可能会增加估计缺失值的难度。
因此,对于每个没有变化点的窗口,我们遍历每个点来计算其被选为观测值的概率。 对于第 𝑖 个点,其概率为:
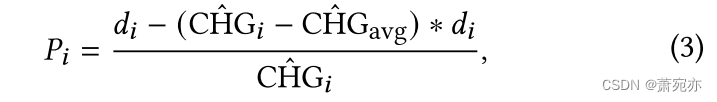
其中
d
i
d_{i}
di 指点 𝑖 与最后选择的观测点之间的距离,
C
H
G
^
i
\hat{\mathrm{CHG}}_i
CHG^i是第 𝑖 点的窗口的 CHG 分数,
C
H
G
^
a
v
g
\hat{\mathrm{CHG}}_{avg}
CHG^avg表示所有窗口的平均 CHG 分数:
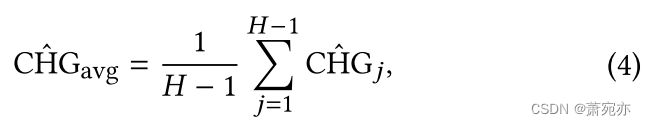
其中𝐻是区域中所有窗口的数量。
P
i
P_{i}
Pi表示点 𝑖 被选择为观察到的概率。 我们可以选择给定比例的点作为观测点,例如概率最高的前 10% 的点。 该概率与该点与最后选择的点之间的距离正相关,与 CHG 分数负相关。 也就是说,它符合上面提到的两条规则。 我们在分子中添加
(
C
H
G
^
i
−
C
H
G
^
a
v
g
)
∗
h
i
(\hat{\mathrm{CHG}}_{i}-\hat{\mathrm{CHG}}_{\mathrm{avg}})*h_{i}
(CHG^i−CHG^avg)∗hi以进一步增强 CHG 分数的作用。 这样,CHG 分数较低且间隔较长的点往往是正常的,并将被选择作为估计屏蔽值的观测值。
3.2 Conditional Weight-Incremental Diffusion条件权重增量扩散
由于扩散模型在数据生成和插补方面的优越性[26,33,43],我们利用DDPM作为基本插补框架。 然而,异常检测与插补不同,前者追求对异常较大的估计误差,以区分异常数据,而后者则旨在准确估计缺失值。 为了弥补这一差距,我们设计了一个条件权重增量扩散模型,以根据观测点生成估计。 目标是生成失真较少的数据,并通过调整观测值的权重来保留观测值的信息,这对于异常检测特别有用。
具体来说,观测值被视为反向扩散迭代期间要施加的条件。 为了保持条件
χ
o
b
\chi^{ob}
χob的维度和
x
^
T
∈
N
(
0
,
I
)
\hat{x}_T\in\mathcal{N}(0,I)
x^T∈N(0,I)的初始状态一致,我们采用双三次插值将
x
o
b
x^{ob}
xob调整为与
x
^
T
\hat{x}^{T}
x^T相同。 然后,我们将调整大小的
x
o
b
x^{ob}
xob和
x
^
T
\hat{x}^{T}
x^T 组合起来,生成扩散模型的输入。 组合如下:
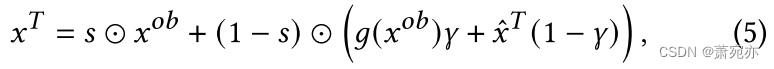
其中𝑠是一个二进制序列,表示观察到数据中的哪个点(例如,011000表示第二个和第三个是观察点,其余的是屏蔽点)。 ( 1 − s ) ⊙ ( ⋅ ) (1-s)\odot(\cdot) (1−s)⊙(⋅) 表示屏蔽点的值。 𝑔(·)是双三次插值函数,𝛾是调整两项相对重要性的权重参数。
然后,我们对反向扩散迭代施加条件。 根据马尔可夫链,条件反向扩散过程的目的是根据 x t x^{t} xt 和 x o b x^{ob} xob 预测 x ^ t − 1 \hat{x}^{t-1} x^t−1 。 添加条件 x o b x^{ob} xob后,DDPM的逆过程变为:
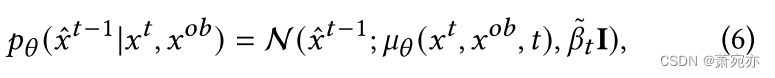
其中 μ θ ( x t , x o b , t ) \mu_{\theta}(x^{t},x^{ob},t) μθ(xt,xob,t)是条件逆过程的估计平均值, β ~ t \tilde{\beta}_{t} β~t是固定常数。 反向过程从高斯噪声 χ ^ T \hat{\chi}^{T} χ^T开始,并通过采样反向步骤 p θ ( x ^ t − 1 ∣ x t , x o b ) p_\theta(\hat{x}^{t-1}|x^t,x^{ob}) pθ(x^t−1∣xt,xob) 生成干净的样本 x 0 \ x^{0} x0。
为了参数化 μ θ ( x t , x o b , t ) \mu_\theta(x^t,x^{ob},t) μθ(xt,xob,t),我们训练神经去噪模型 f θ ( x t , x o b , t ) f_\theta(x^t,x^{ob},t) fθ(xt,xob,t)来预测噪声向量𝜖。 目标定义如下:
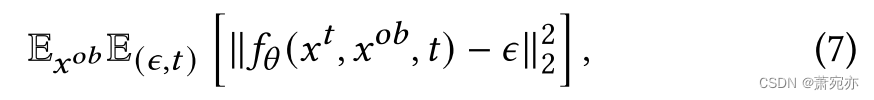
和
μ
θ
(
x
t
,
x
o
b
,
t
)
\mu_\theta(x^t,x^{ob},t)
μθ(xt,xob,t)可以从
f
θ
(
x
t
,
x
o
b
,
t
)
f_\theta(x^t,x^{ob},t)
fθ(xt,xob,t) 导出:
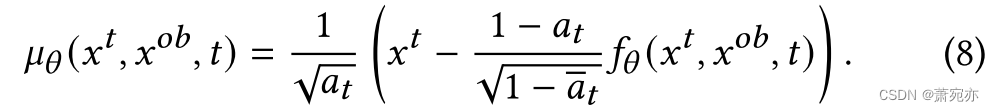
因此,生成(反向扩散)过程是:
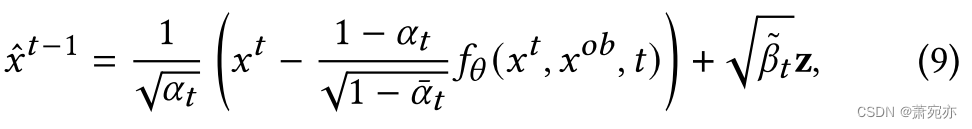 其中 z ∼ 𝑁(0, I),意味着每个生成步骤都是随机的。 这个生成过程迭代地细化分布,直到达到干净的样本
x
0
\ x^{0}
x0。
其中 z ∼ 𝑁(0, I),意味着每个生成步骤都是随机的。 这个生成过程迭代地细化分布,直到达到干净的样本
x
0
\ x^{0}
x0。
然而,简单地将条件注入去噪网络并期望网络自动利用条件信息生成预期数据可能会遇到偏差问题。 换句话说,经过多次迭代后,观测点的生成值可能会偏离其真实值。 另一种方法是对生成的数据强行施加条件因子(即在每个时间步用真实观测值替换生成值),但这可能会导致失真问题。
为此,我们提出了一种新颖的权重增量条件注入方法来有效解决这个问题。 换句话说,我们引入一个单调函数ℎ(·)来调整条件的权重(例如,观测值 x o b x^{ob} xob)。 ℎ(·)具有从0到1的共域,可以根据指数衰减方程得到:
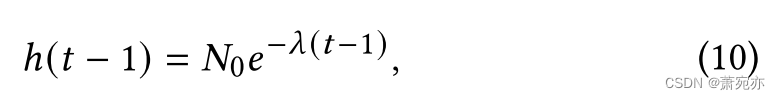
其中𝜆是代表指数衰减常数的超参数,𝑁0是初始量。 其动机是,随着时间戳𝑡的减小和反向采样的继续,观测点的生成值应该越来越接近真实的观测值——相应地,权重ℎ(·)应该变大,以保证生成值和观测值之间的一致性。
有了权重函数ℎ(·),我们将观测值组合到生成值中以产生
x
t
−
1
\ x^{t-1}
xt−1:
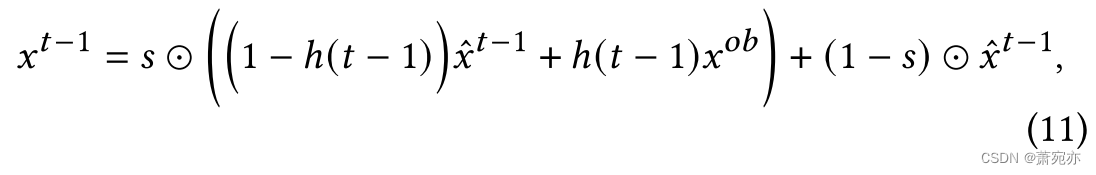
其中
s
⊙
(
⋅
)
a
n
d
(
1
−
s
)
⊙
x
^
t
−
1
s\odot(\cdot)\mathrm{~and~}(1-s)\odot\hat{x}^{t-1}
s⊙(⋅) and (1−s)⊙x^t−1分别指观测点和屏蔽点的生成值。 请注意,所提出的条件权重增量扩散学习具有一些吸引人的特性: (𝑖) 当 𝑡 →𝑇 时,ℎ(𝑡) 限制为 0,因此条件因子对 DDPM 的初始状态(几乎)没有影响; (𝑖𝑖) 由于 ℎ(𝑡) 是单调递减函数,因此满足上述动机(时间戳越小,条件约束越严格)。 由于指数函数的连续性,可以温和、渐进地修正偏差。 (𝑖𝑖𝑖) 当𝑡 → 0 时,ℎ(𝑡) 获得最大值:ℎ(𝑡) =
N
0
{N_{0}}
N0。 并且,根据式(11)和我们的实验设置,我们可以保证观测点的位置将完全被地面真实观测值替代。
如图3所示,估计过程从高斯噪声\hat{\chi}^{T}开始,通过迭代细化生成干净的样本 x 0 x^{0} x0,即 x ^ T → x T ⋯ → x ^ t − 1 → x t − 1 → ⋯ → x 0 \hat{x}^{T}\to x^{T}\cdots\to \hat{x}^{t-1}\to x^{t-1}\to \cdots\to x^{0} x^T→xT⋯→x^t−1→xt−1→⋯→x0。 在每个反向步骤 𝑡 ∈ {𝑇, 𝑇 − 1, · · · , 0} 中,我们首先根据方程(9)生成噪声候选者 x ^ t − 1 \hat{x}^{t-1} x^t−1。 然后,我们应用方程(11)对 x ^ t − 1 \hat{x}^{t-1} x^t−1显式施加条件以获得 x t − 1 x^{t-1} xt−1。 最后,可以通过将高斯噪声 x ^ T \hat{\ x}^{T} x^T 转换为干净样本 x 0 \ x ^{0} x0 来估计屏蔽值,以观察点 x o b \ x^{ob} xob 为条件。
3.3 基于S4的多尺度U-Net
在扩散模型中,通常使用基于Wide ResNet [54]的U-Net [35]作为去噪神经网络[19]。 然而,该 U-Net 主干中的卷积和池化操作等组件无法有效处理具有远程依赖关系的数据 [17, 18]。 在存在异常浓度的情况下,利用长期相互作用对于捕获异常浓度事件之外的时间序列模式特别重要。 在这里,我们引入了 U-Net 的结构化状态空间序列模型(S4)[17]来处理这种长期依赖关系。 S4 最近被提出用于对序列建模任务 [17] 的远程依赖关系进行建模,并已成功应用于各种应用的自回归和 Transformer 模型,例如语音分类 [18]、音频生成 [16] 和电影分类 [21] ]。
具体来说,我们定制了一个基于 S4 的多尺度 U-Net 主干网,以多种分辨率整合来自不同层的信息。 我们提出的网络架构由多层组成,每层都包含一堆剩余的 S4 块。 顶层以其原始采样率处理原始时间序列数据,而较低层则处理输入信号的下采样版本。 下层的输出被上采样并与上层的输入相结合,以提供更强的调节信号。 由于多尺度策略,不同的块可以学习不同尺度的特征,这有助于模型学习长时间序列数据上的复杂时间依赖性。 这种基于 S4 的多尺度 U-Net 将用作条件权重增量扩散模型中的去噪神经网络 f θ ( ⋅ ) f_{\theta}(\cdot) fθ(⋅)。
3.4 检测标准
对于异常检测,我们将异常分数与给定阈值进行比较以确定异常。 对于测试点,其异常分数是根据估计误差计算的:
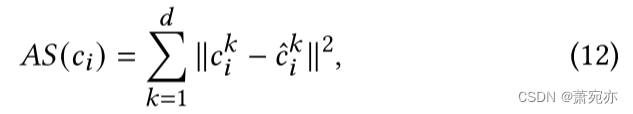
其中
c
i
a
n
d
c
^
i
c_{i}\mathrm{~and~}\hat{c}_{i}
ci and c^i分别是真实值和估计值,𝑑指多元时间序列的维度。
与之前的工作[57]类似,我们根据训练数据获得阈值。 给定训练数据 X = { c 1 , c 2 , . . . , c N } , \mathcal{X}=\{c_{1},c_{2},...,c_{N}\}, X={c1,c2,...,cN},,相应的决策阈值 T 为:
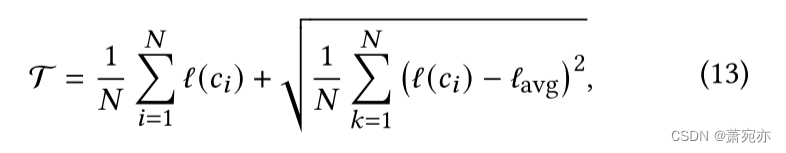
表1:数据集的描述性统计

其中 ℓ(𝑐𝑖 ) 是指 𝑐𝑖 的损失函数之和, ℓ a v g ℓ_{avg} ℓavg 表示平均值。 如果 𝐴𝑆(𝑐𝑖 ) > T,则测试样本被视为异常,否则视为正常。
四、 实验评价
在本节中,我们从异常检测性能、消融研究以及点选择策略和观察数量的作用方面评估模型的有效性。
4.1 实验设置
数据集。 我们对时间序列异常检测的基准进行了实验,如表1所示。(1)SWaT(安全水处理)是从连续运行的关键基础设施系统的51个传感器获得的[29]。 (2) PSM(池化服务器指标)是从 eBay 的多个应用程序服务器节点内部收集的[1]。 (3)SMD(服务器机器数据集)是从大型互联网公司收集的为期5周的数据集[41]。 (4)MSL(火星科学实验室漫游车)和SMAP(土壤湿度主动被动卫星)都是NASA的公共数据集,其中包含来自航天器监测系统事件意外异常报告的遥测异常数据[20]。 基线。 我们将我们的模型 DiffAD 与来自五个主要类别的各种基线进行比较:(1)密度估计方法(例如 DAGMM [60]、MPPCACD [50] 和 LOF [6]),用于评估时间序列数据的密度以检测异常; (2)基于聚类的方法(例如ITAD[40]、THOC[39]和Deep-SVDD[36])将数据序列划分为簇,并通过比较它们与簇的距离来识别异常; (3)时间序列插补技术(例如,CSDI [43]和STING [31])旨在根据观测值插补缺失值。 请注意,它们主要是为数据插补而不是异常检测而设计的。 在这里,我们使用它们的插补误差使它们适应时间序列异常检测; (4) 基于预测的模型(例如 CL-MPPCA [42] 和 LSTM [20])学习预测模型,根据当前上下文窗口中的值预测多个时间步中的值,并根据 预测误差; (5) 基于重建的方法(例如 LSTM-VAE [32]、BeatGAN [59]、OmniAnomaly [41]、InterFusion [24] 和 ATransformer [49])通过编码子序列来构建模型来理解正常行为 潜在空间中的正常训练时间序列,并根据重建误差确定异常。
实验设置。 我们使用 Adam 优化器 [22],初始学习率为 3 * 10−6,并根据验证集将 SMD 的批量大小设置为 16,将其他四个数据集的批量大小设置为 32。 我们对扩散模型使用 100 个扩散步骤。 同时估计一点的不同维度的值。 我们根据经验设置方程(5)中的𝛾 = 0.9,方程(10)中的𝜆 = 25 和𝑁0 = 1。 我们采用广泛使用的调整策略[39,41,48]:如果检测到某个连续异常段中的某个时间点,则认为该异常段中的所有异常都被正确检测到。 这种策略的合理性是通过观察到异常时间点会引起警报并进一步使整个片段在实际应用中引起注意来证明的[39]。
至于观测点的数量,我们选择使用式(3)计算出的选择概率最高的前6%的点作为MSL的观测点,其他四个数据集选择12%。 观察到的点用作我们设计的扩散模型的条件来估计掩模点的值。
4.2 异常检测结果
我们在表2中报告了DiffAD的异常检测结果和基线,其中P、R和F1分别代表Precision、Recall和F1分数。 从表中,我们有以下观察结果。 首先,我们提出的 DiffAD 方法在大多数评估指标中比跨数据集的基线方法实现了更好的性能。 虽然 CL-MPPCA 的召回率略高于我们的模型,但其 F1 分数和精度明显低于我们的模型。 值得注意的是,我们的模型在 SwaT 上大大超出了最佳基线,因为 SwaT 上的异常更加集中。 这一结果验证了我们的方法在存在较高异常浓度的情况下提高检测性能的优越性。
其次,与密度估计和基于聚类的方法相比,时间序列插补方法(即 CSDI 和 STING)实现了相对较好的性能。 这表明插补模型是时间序列异常检测的潜在技术。 令人惊讶的是,这两个社区非常接近,但很少有交叉。 然而,我们的模型优于两种最先进的插补模型,这验证了所提出的多尺度学习网络和观察点选择策略在时间序列异常检测中的效果。
第三,ATransfomer是一种专门为Transformers设计的异常检测方法,它超越了其他基线,这表明Transformers等先进的深度学习技术可以提高时间序列异常检测的性能。 然而,我们的 DiffAD 通过引入基于扩散模型的插补技术优于 ATransfomer,验证了所提出的权重增量扩散模型在异常检测中的有效性。
4.3 消融研究
接下来,我们评估 DiffAD 中重要组件的作用:条件权重增量扩散模型、基于多尺度 S4 的 U-Net 和基于密度比的点选择策略。 我们主要研究以下变体:(1)DiffAD-Base是一个基本的扩散模型,不具有三个组件(即增加条件权重、基于多尺度S4的U-Net和基于密度比的选择策略)。 (2) DiffAD-Wei是一个具有条件权重增量扩散的模型。 (3) DiffAD-MS4 是一个配备了我们设计的基于 S4 的多尺度 U-Net 的模型。 (4) DiffADCHG 是一个基于密度比的选择策略的模型。
五个数据集上的异常检测性能如表 3 所示。如图所示,与 DiffAD-Base 相比,DiffADWeight 获得了更好的检测结果,这表明我们对条件扩散的权重变化确实增强了异常检测性能。 此外,通过考虑基于S4的多尺度U-Net,DiffAD-MS4与DiffAD-Base相比在检测精度上取得了很大的提高。 这表明多尺度网络可以捕获长期依赖性。 此外,DiffAD-Change 在一定程度上优于 DiffAD-Base,这意味着选择合适的点作为观测值至关重要。
表 2:DiffAD 与五个数据集上的基线之间的性能比较。
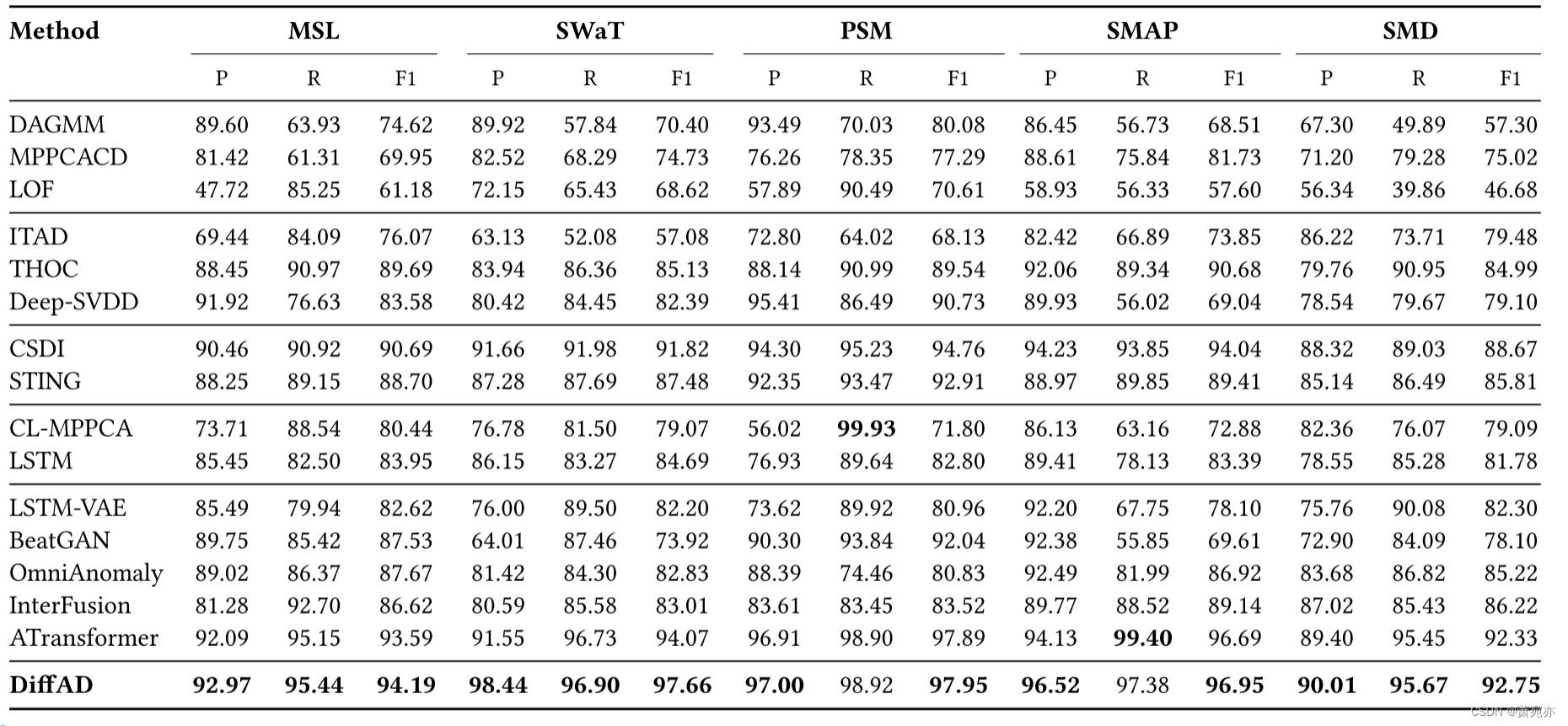
表 3:不同组件的作用
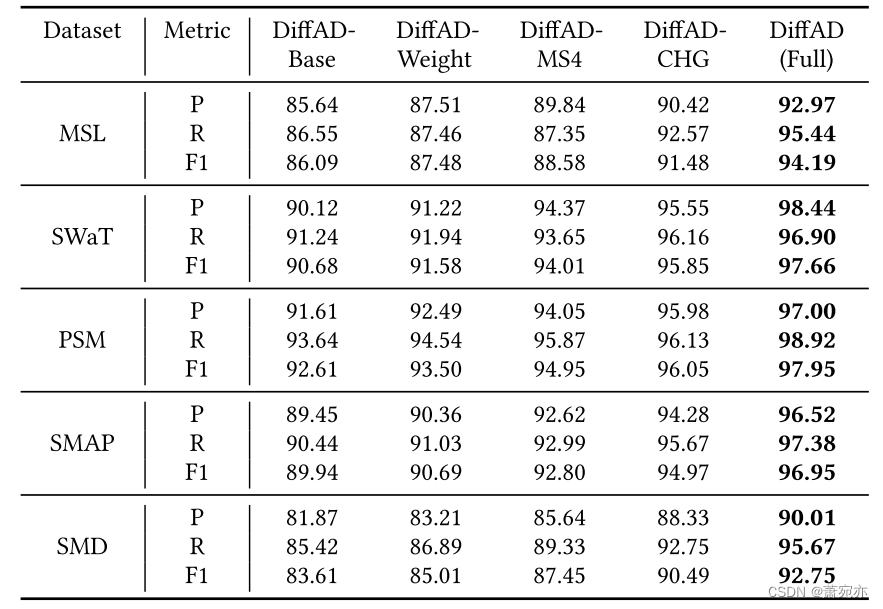
4.4 选择策略的作用
我们的工作与典型插补任务之间的主要区别之一是,可以灵活选择这项工作中的观察点。 因此,我们研究了所选点如何影响检测性能。我们将我们设计的选择策略与以下策略进行比较:(𝑖)随机策略:随机选择一定百分比的点作为观察点。 (𝑖𝑖) 固定间隔策略:以固定间隔选择观测点。 (𝑖𝑖𝑖) 预测策略:模拟时间序列预测任务,迭代地选择过去的值作为观测值来预测未来的值。 除了预测策略外,包括我们在内的其他策略都选择相同百分比的数据作为观测点,即MSL为6%,SWaT、PSM、SMAP和SMD为12%。
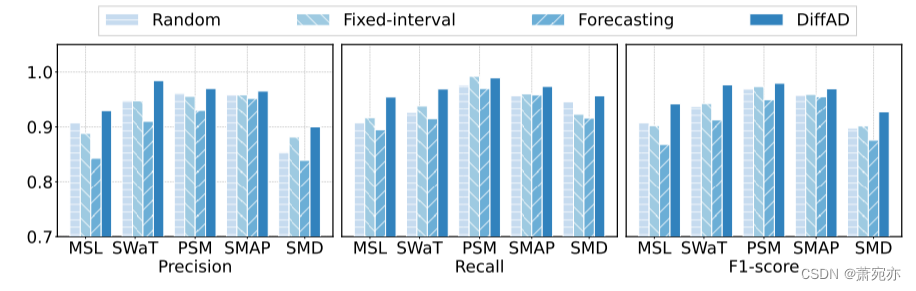
图 4:不同选择策略的性能。
图 4 显示了五个数据集的检测结果。 首先,我们基于密度比的选择策略在所有三个指标方面都实现了最佳性能,这意味着我们的策略可以有效地选择更多正常值作为观察值,并进一步协助下游异常检测。 其次,预测策略在所有策略中表现最差。 当历史值和未来值都包含许多正常值时,可以准确估计未来值,即该模型在异常检测方面是有效的。 然而,当异常在过去的值中占主导地位时,未来的正常点可能会被错误地标记为异常,不幸的是,这可能会大大恶化模型的性能。 第三,随机策略和固定间隔策略获得相似的性能,因为两种方法选择的观测点中正常点的比例非常接近。 由于其他设置相同,所选择的观察点决定了检测性能,从而使两种策略相似。
图 5 进一步绘制了 SMD 的插补结果示例以及使用不同策略选择的观察点。 视觉结果支持了上述分析,即我们的方法可以选择更多的正常点作为观测点,并获得更大的异常估计误差,从而产生更好的异常检测性能。 此外,当过去的点(例如,𝑒2 中的点)以异常为主时,预测策略可能会错误地将正常点(例如,𝑒3 中的点)注释为异常点。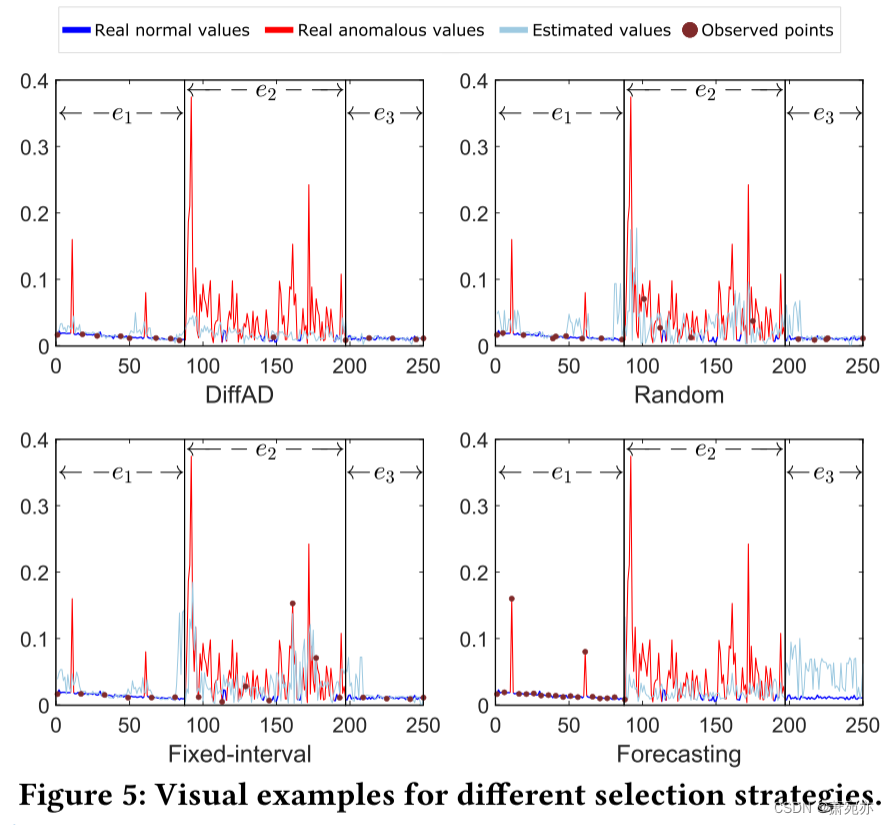
4.5 观测点的影响
观测点的数量对于缺失值估计至关重要,它决定了估计误差,并随后影响异常检测结果。 因此,我们通过改变观察点的数量来检查性能。 在本实验中,我们将 DiffAD 与两个时间序列插补基线(即 STING 和 CSDI)进行比较。
五个数据集上的 F1 和 Recall 分数如图 6 所示。显然,当观察点的数量较小(例如 3%)和较大(例如 24%)时,DiffAD 获得相对较低的性能。 一方面,少数点可能并不能代表数据集中所有正常点的整体分布,尤其是MSL在不同时间点存在较大波动。 少量的点不足以让模型估计屏蔽点的值,导致检测性能较低。 另一方面,当选择过多的观测点时,可能会选择一些异常作为观测点来估计屏蔽点的值,这可能会导致异常的估计误差较小,从而导致检测性能较差。 此外,无论观察点的数量有多少,我们的模型 DiffAD 始终优于两个插补基线。 这一结果进一步验证了DiffAD在选择有意义的观测值进行异常检测方面的有效性。
4.6 案例研究
为了提供更直观的 DiffAD 案例,我们在图 7 中提供了一些示例。它显示了 DiffAD 在五个数据集上学习的输入数据和结果。 这里,原始输入数据绘制在上行(蓝线)中,其相应的估计结果显示在下行中。 逐点异常由红色框界定。 我们可以发现我们提出的 DiffAD 能够区分数据中的异常情况。 对于具有正常点的数据块,估计误差(橙色线)保持稳定。 但由于异常点的存在,它们的波动很大。 此功能提供了一种选择适当标准的简单方法。 它还验证了我们的标准可以突出异常并为正常点和异常点提供不同的值,从而使检测更加精确并降低误报率。
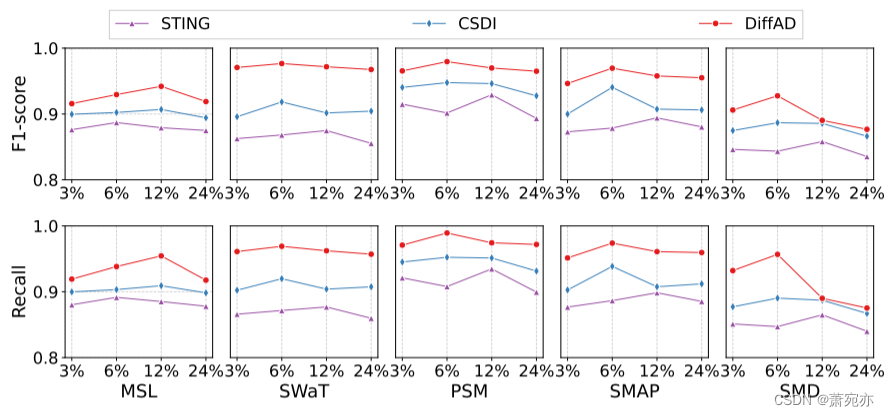
图 6:观察点数量的影响。
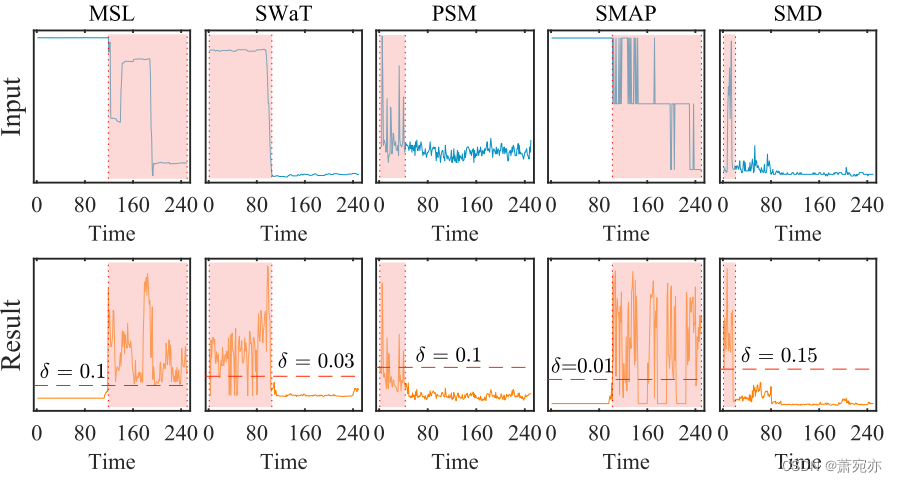
图 7:使用 DiffAD 进行异常检测的示例。 蓝线(上行)是输入。 橙色线是估计误差,红色虚线是用于检测异常的阈值(即高于红线时的异常)。
五、 相关工作
5.1 时间序列异常检测
由于其不同的应用,异常检测是一个广泛研究的课题。 近年来,受深度学习成功的启发,许多深度异常检测模型被提出,并在时间序列异常检测上取得了显着的成功。 现有模型通常分为两类:基于重建的方法和基于预测的方法。
基于重建的方法旨在学习整个时间序列的潜在表示以进行数据重建,并使用重建误差进行异常检测。 人们已经采用了不同的深度生成技术来构建此类重建模型,包括变分自动编码器(VAE)和生成对抗网络(GAN)。 例如,Donut[48]引入VAE来重建正常点,并计算每个时间点的重建概率以进行异常判断。 此外,LSTM 被纳入 VAE 中以检测机器人辅助喂养系统中的异常情况 [32]。 提出了一种正则化编码器-解码器架构来检测心电图时间序列中的序列异常[8]。 变压器和图关系学习也被探索来区分多元时间序列数据的异常[46,49,56]。
受 GAN 进步的启发,MAD-GAN 通过对抗性学习增强了多变量时间序列中的异常检测,其中异常得分被定义为重建损失和判别损失的组合[23]。 TadGAN [15]是一种基于重构GAN的架构,使用循环一致的GAN架构来防止编码器和解码器之间的矛盾。 另一个名为 BeatGAN [59] 的模型旨在检测时间序列中的异常节律。 它由一个在训练中具有对抗性正则化的自动编码器和一个用于区分真实序列和重建序列的鉴别器组成。 OmniAnomaly [41] 使用随机循环神经网络来寻找多元时间序列的稳健表示。 USAD [3] 提出了一种自动编码器架构,其对抗式学习也受到 GAN 的启发。
基于预测的方法利用先进的深度学习根据过去的值来预测未来,然后使用预测值和实际观察值之间的预测误差来确定异常情况。 例如,LSTM 模型旨在根据历史遥测数据 [20] 预测未来的遥测数据,以识别多通道遥测数据中的航天器异常。 MTAD-GAT [58]结合了面向特征的图注意力网络(GAT)和面向时间的GAT来处理预测的空间依赖性和时间依赖性。 KfreqGAN [51] 采用对抗训练的序列预测器来预测未来序列。 GDN [12]提出了一种基于 GNN 的方法来聚合传感器之间的信息。
差异:我们基于插补的方法采用不同的数据来推断测试数据的值。 相比之下,基于重建的方法使用所有测试数据来重建其值,而基于预测的模型则利用历史值来预测未来。 由于我们基于插补的方法使用离散观测值,这使得它能够灵活地选择观测值来估计掩蔽值。 屏蔽值属于观测值,可以为数据估计提供更有价值的信息,并提供预期结果。 此外,我们设计了一种基于密度比的点选择策略来选择合适的观测点,并提出了一种基于多尺度S4网络的条件权重增量扩散模型,以提高检测性能。
5.2 时间序列插补
时间序列插补旨在根据观测值估计缺失数据。 一般来说,深度学习模型可以捕获时间序列中的时间依赖性,并实现比统计方法更准确的插补[13]。 其中,基于 RNN 的方法使用各种 RNN(包括 LSTM 和 GRU)来对时间序列进行建模。 在这一行中,GRU-D [9]解决了时间序列分类问题中的缺失数据问题。 M-RNN [52] 和 BRITS [7] 根据双向 RNN 的隐藏状态插入缺失值。
基于 GAN 和基于 VAE 的方法利用生成模型来生成插补值。 例如,VAE 架构已被用于[14]中的时间序列插补,其中在潜在空间中考虑了高斯过程先验。 L-VAE [34] 在容纳辅助协变量信息之前使用加性多输出高斯过程。 GRUI [27](GRU for Imputation)增强了 GAN 模型的生成器和判别器,以学习不完整时间序列插补的时间模式。 罗等人。 [28]提出了一种名为𝐸2GAN的端到端方法,采用基于GRUI的自动编码器形成生成器,以减轻模型训练的难度。 NAOMI [25]是一种用于时空序列插补的非自回归模型,由双向编码器和多分辨率解码器组成。 最近,扩散模型和图神经网络也被引入用于时间序列插补[10, 43]。
区别:数据插补和异常检测任务之间有两个主要区别。 (𝑖)异常检测任务的目标是扩大异常的估计误差,而插补任务的目标是准确估计缺失值; (𝑖𝑖) 异常检测任务可以灵活选择观测点,但数据插补通常使用相邻数据进行缺失值插值。 考虑到差异,我们设计了用于异常检测的条件权重增量扩散模型和基于密度比的点选择策略以获得适当的观测点。
六、结论
在本文中,我们提出了一种用于时间序列异常检测的基于扩散的插补框架 DiffAD。 可以有效缓解异常集中情况下的性能下降问题。 我们设计了一个条件权重增量扩散模型,该模型将具有增量权重的观测值应用于反向扩散迭代,以逐渐细化估计结果。 此外,我们为扩散模型实现了一个基于 S4 的多尺度 U-Net,以捕获时间序列数据中的长期依赖性,并实现了基于密度比的选择策略,以选择更多正常值作为观测值来估计缺失值 准确的异常检测。 大量的实验证明了我们提出的方法相对于时间序列基准上最先进的基线的优越性。
局限性和未来的工作。 与基于预测和重建的方法相比,我们提出的 DiffAD 必须选择观察点。 这增加了异常检测的计算成本。 有一些替代策略,例如随机策略、固定间隔策略和预测策略,可以平衡检测效率和有效性,如 4.4 节中研究的那样。 同时,DiffAD 中的异常检测实际上执行了两次:一次用于屏蔽值插补,另一次用于选定的观测值。 为了计算观测点的估计误差,我们的模型将选择一批新的观测点。 一般选择原观测点的相邻点作为新的观测点进行数据估计。 尽管可以使用 GPU 并行执行,但此过程也会稍微增加工作负载。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









