





ICLR 2022
文章目录
摘要
时间序列中异常点的无监督检测是一个具有挑战性的问题,它要求模型推导出一个可区分的准则。以前的方法主要通过学习逐点表示或成对关联来解决这个问题,然而,这两种方法都不足以解释复杂的动力学。近年来,Transformers在点态表示和成对关联的统一建模方面表现出了强大的能力,我们发现每个时间点的自注意权重分布能够体现出与整个序列的丰富关联。我们的关键观察是,由于异常的罕见性,从异常点到整个序列的非平凡关联是非常困难的,因此,异常的关联应主要集中在其相邻的时间点。这种邻近集中偏差意味着一个基于关联的标准,它本质上可以区分正常点和异常点,我们通过关联离散度来强调这一点。在技术上,我们提出了一个新的异常注意力机制计算关联差异的异常Transformer。设计了一种极大极小策略来放大关联差异的正常-异常可分辨性。Anomaly Transformer在三个应用的六个无监督时间序列异常检测基准上取得了最先进的结果:服务监控、空间和地球探测以及水处理。
1、介绍
现实世界中的系统总是以连续的方式工作,这可能会产生多个传感器监测的连续测量,如工业设备,空间探测器等。从大规模系统监测数据中发现故障可以归结为从时间序列中检测异常时间点,这对于确保安全和避免经济损失具有重要意义。但是异常通常是罕见的,并且被大量的正常点隐藏,使得数据标记困难且昂贵。因此,我们专注于在无监督设置下的时间序列异常检测。无监督时间序列异常检测在实践中极具挑战性。该模型应该通过无监督任务从复杂的时间动态中学习信息表示。尽管如此,它还应该推导出一个可区分的标准,可以从大量的正常时间点检测到罕见的异常。各种经典的异常检测方法提供了许多无监督的范例,如局部离群因子中提出的密度估计方法(LOF,Breunig et al.(2000)),单类SVM中提出的基于聚类的方法(OC-SVM,Scholkopf et al.(2001))和SVDD(Tax & Duin,2004)。这些经典的方法没有考虑时间信息,很难推广到看不见的真实的场景。受益于神经网络的表示学习能力,最近的深度模型(Su et al.,2019年; Shen等人,2020年; Li等人,2021年)取得了上级的业绩。一个主要类别的方法专注于通过精心设计的递归网络RNN学习逐点表示,并通过重建或自回归任务进行自我监督。在这里,自然和实用的异常标准是逐点重建或预测误差。然而,由于异常的罕见性,逐点表示对于复杂的时间模式来说信息量较少,并且可以由正常时间点主导,使得异常难以区分。此外,重建或预测误差是逐点计算的,这不能提供时间上下文的全面描述。
另一类主要的方法基于显式关联建模来检测异常。向量自回归和状态空间模型属于这一类。该图还用于通过将不同时间点表示为顶点的时间序列和通过随机游走检测异常来明确地捕获关联(Cheng等人,2008; 2009)。一般来说,这些经典方法很难学习信息表示和建模细粒度的关联。最近,图神经网络(GNN)已经被应用于学习多变量时间序列中的多个变量之间的动态图(Zhao等人,2020; Deng & Hooi,2021)。虽然更有表现力,但学习的图仍然限于单个时间点,这对于复杂的时间模式是不够的。除此之外,基于序列的方法通过计算序列之间的相似性来检测异常(Boniol & Palpanas,2020)。这些方法在探索更广泛的时间背景时,无法捕捉每个时间点与整个序列之间的细粒度时间关联
细粒度模型,通俗的讲就是将业务模型中的对象加以细分,从而得到更科学合理的对象模型,直观地说就是划分出很多对象.
在本文中,我们采用了Transfomers(Vaswani等人,2017年)在无监督制度的时间序列异常检测。Transformer在各个领域都取得了巨大的进步,包括自然语言处理(Brown et al.,2020)、机器视觉(Liu等人,2021)和时间序列(Zhou et al.,2021年)。这一成功归功于它在全局表示和远程关系的统一建模方面的强大功能。将Transformers应用于时间序列,我们发现每个时间点的时间关联可以从自注意图中得到,自注意图表示为它的关联权重沿时间维度沿着分布到所有时间点。每个时间点的关联分布可以为时间上下文提供更多信息的描述,指示动态模式,例如时间序列的周期或趋势。我们将上述关联分布称为序列关联series-association,它可以通过Transformers从原始序列中发现。
此外,我们观察到,由于异常的罕见性和正常模式的主导地位,异常很难与整个系列建立强关联。异常的关联应集中在相邻时间点,由于连续性,这些时间点更可能包含类似的异常模式。这种相邻浓度感应偏置被称为先验关联prior-association。相比之下,占主导地位的正常时间点可以发现与整个系列的信息关联,而不限于相邻区域。基于这一观察,我们试图利用关联分布固有的正态-异常可解释性。这导致了每个时间点的新的异常标准,通过每个时间点的先验关联prior-association与其序列关联series-association之间的距离来量化,称为关联离散度Association Discrepancy。如前所述,由于异常的关联更可能是相邻集中的,因此异常将呈现比正常时间点更小的关联差异。
超越以前的方法,我们将 Transformer 引入无监督时间序列异常检测,并提出用于关联学习的 Anomaly Transformer。为了计算关联差异,我们将自注意力机制更新为异常注意力,其中包含一个两分支结构来分别对每个时间点的先验关联prior-association和序列关联series-association进行建模。先验关联采用可学习的高斯核来呈现每个时间点的相邻浓度归纳偏差,而序列关联对应于从原始序列中学习的自注意力权重。此外,在两个分支之间应用极小极大策略,可以放大关联差异的正常与异常可区分性,并进一步导出新的基于关联的标准。 Anomaly Transformer 在六个基准测试中取得了优异的成绩,涵盖了三个实际应用。贡献总结如下:
- 基于关联离散性Association Discrepancy的关键观察,提出了带有异常注意机制的异常Transformer,它可以同时对先验关联和序列关联进行建模,以体现关联离散性。
- 我们提出了一个极大极小策略,以放大正常异常的关联离散性Association Discrepancy,并进一步推导出一个新的基于关联的检测标准。
- Anomaly Transformer在三个真实的应用程序的六个基准测试中实现了最先进的异常检测结果。广泛的消融和有见地的案例研究。
2、相关工作
2.1 无监督时间序列异常检测
作为一个重要的现实问题,无监督时间序列异常检测已被广泛探索。按异常判定标准分类,范式大致包括密度估计方法、基于聚类的方法、基于重构的方法和基于自回归的方法。
对于密度估计方法,经典方法局部异常值因子(LOF,Breunig et al.(2000))和连通性异常值因子(COF,Tang et al.(2002))计算局部密度和局部连通性以进行异常值确定分别。 DAGMM (Zong et al., 2018) 和 MPPCACD (Yairi et al., 2017) 整合高斯混合模型来估计表示的密度。
在基于聚类的方法中,异常分数始终被形式化为到聚类中心的距离。 SVDD (Tax & Duin, 2004) 和 Deep SVDD (Ruff et al., 2018) 将正常数据的表示收集到一个紧凑的集群中。 THOC(Shen et al., 2020)通过层次聚类机制融合中间层的多尺度时间特征,并通过多层距离检测异常。 ITAD(Shin et al., 2020)对分解张量进行聚类。
基于重建的模型试图通过重建误差来检测异常。帕克等人 (2018) 提出了 LSTM-VAE 模型,该模型采用 LSTM 主干进行时间建模,并使用变分自动编码器 (VAE) 进行重建。 Su等人提出的OmniAnomaly (2019) 通过归一化流进一步扩展了 LSTM-VAE 模型,并使用重建概率进行检测。 Li 等人的 InterFusion。 (2021) 将主干更新为分层 VAE,以同时对多个系列之间的相互依赖和内部依赖进行建模。 GAN(Goodfellow 等人,2014)也用于基于重建的异常检测(Schlegl 等人,2019;Li 等人,2019a;Zhou 等人,2019)并作为对抗性正则化。
基于自回归的模型通过预测误差来检测异常。 VAR 扩展了 ARIMA(Anderson & Kendall,1976)并根据滞后相关协方差预测未来。自回归模型也可以用 LSTM 替代(Hundman et al., 2018;Tariq et al., 2019)。
本文的特点是一种新的基于关联的标准。与随机游走和基于子序列的方法(Cheng et al., 2008;Boniol & Palpanas, 2020)不同,我们的标准通过时间模型的共同设计来体现,以学习更多信息时间点关联。
2.2 用于时间序列分析的Transformer
最近,Transformers (Vaswani et al., 2017) 在顺序数据处理方面表现出了强大的能力,例如自然语言处理 (Devlin et al., 2019; Brown et al., 2020)、音频处理 (Huang et al., 2019) )和计算机视觉(Dosovitskiy 等人,2021;Liu 等人,2021)。对于时间序列分析,受益于自注意力机制的优势,Transformers 用于发现可靠的长程时间依赖性(Kitaev et al., 2020;Li et al., 2019b;Zhou et al., 2021;吴等人,2021)。特别是对于时间序列异常检测,Chen等人提出的GTA。 (2021) 采用图结构来学习多个物联网传感器之间的关系,以及用于时间建模的 Transformer 和用于异常检测的重建标准。与之前 Transformers 的使用不同,Anomaly Transformer 将 self-attention 机制革新为基于关联差异关键观察的 Anomaly-Attention。
3、方法
假设监视连续的 d 测量系统并记录一段时间内的等间隔观测值。观察到的时间序列X由一组时间点{x1,x2,···,xN}表示,其中xt ∈ Rd表示时间t的观察。无监督时间序列异常检测问题是在没有标签的情况下判断xt是否异常。
如上所述,我们强调无监督时间序列异常检测的关键是学习信息表示和找到可区分的标准。我们提出Anomaly Transformer来发现更多信息关联,并通过学习关联差异Association Discrepancy来解决这个问题,关联差异Association Discrepancy本质上是正常与异常可区分的。从技术上讲,我们提出了异常注意力来体现先验关联prior-association和系列关联series-associations,以及极小极大优化策略以获得更容易区分的关联差异Association Discrepancy。与架构共同设计,我们根据学习到的关联差异得出基于关联的标准。
3.1 Anomaly Transformer
鉴于 Transformer(Vaswani 等人,2017)在异常检测方面的局限性,我们将普通架构改造为具有 Anomaly-Attention 机制的 Anomaly Transformer(图 1)。
总体架构 Anomaly Transformer 的特点是交替堆叠 Anomaly-Attention 块和前馈层。这种堆叠结构有利于从深层多级特征中学习底层关联。
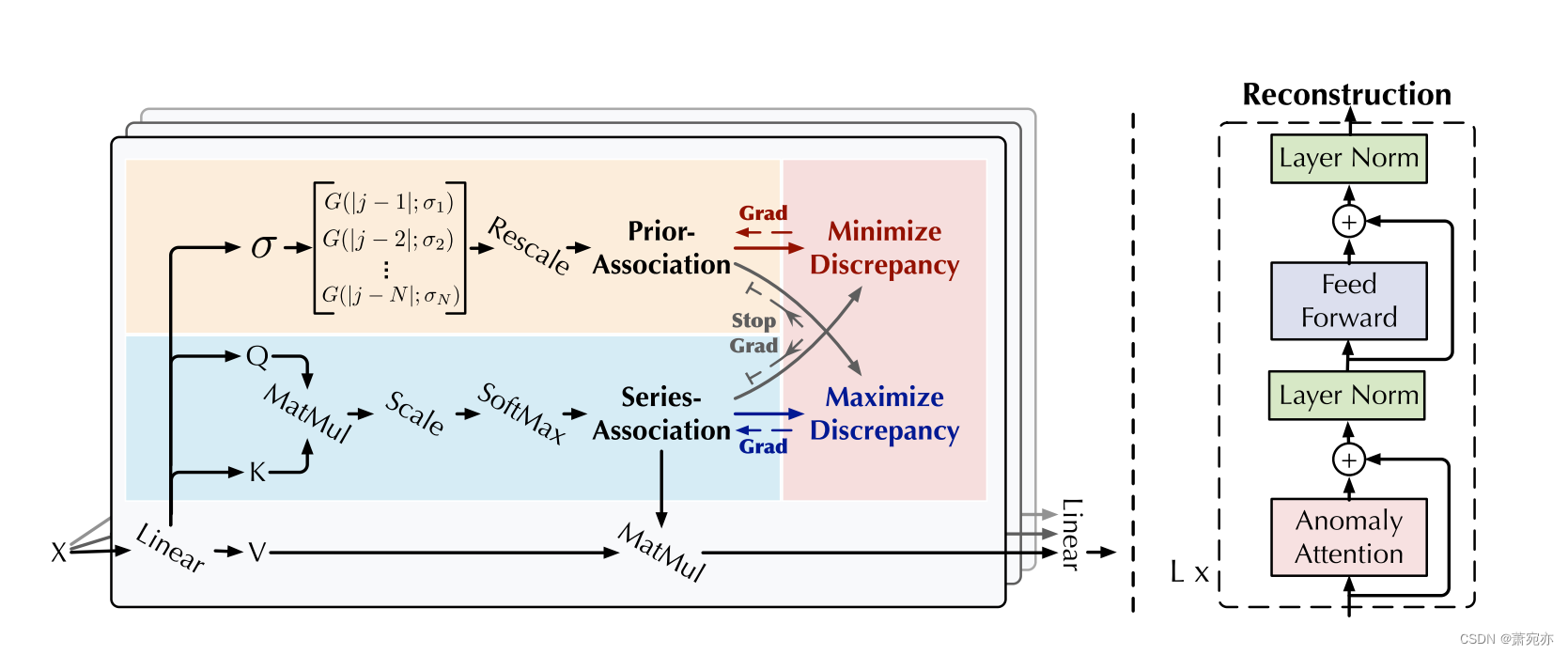
假设模型包含 L 层,长度为 N 的输入时间序列 X ∈ RN×d。第l层的整体方程形式化为:
Z
l
=
Layer-Norm
(
Anomaly-Attention
(
X
l
−
1
)
+
X
l
−
1
)
X
l
=
Layer-Norm
(
Feed-Forward
(
Z
l
)
+
Z
l
)
,
(
1
)
\begin{aligned}\mathcal{Z}^l&=\text{Layer-Norm}\Big(\text{Anomaly-Attention}(\mathcal{X}^{l-1})+\mathcal{X}^{l-1}\Big)\\\mathcal{X}^l&=\text{Layer-Norm}\Big(\text{Feed-Forward}(\mathcal{Z}^l)+\mathcal{Z}^l\Big),\end{aligned}(1)
ZlXl=Layer-Norm(Anomaly-Attention(Xl−1)+Xl−1)=Layer-Norm(Feed-Forward(Zl)+Zl),(1)
X l ∈ R N × d m o d e l , l ∈ { 1 , ⋯ , L } \mathcal{X}^l\in\mathbb{R}^{N\times d_{\mathrm{model}}},l\in\{1,\cdots,L\} Xl∈RN×dmodel,l∈{1,⋯,L} 表示具有 dmodel 通道的第 l 层的输出。初始输入 X0 = Embedding(X) 表示嵌入的原始序列。 Zl ∈ RN×dmodel 是第 l 层的隐藏表示。 Anomaly-Attention(·)是计算关联差异。
3.1 Anomaly-Attention
请注意,单分支自注意力机制(Vaswani et al., 2017)无法同时对先验关联和系列关联进行建模。我们提出了具有两分支结构的 AnomalyAttention(图 1)。对于先验关联,我们采用可学习的高斯核来计算相对时间距离的先验。受益于高斯核的单峰性质,该设计可以在本质上更加关注相邻层。我们还为高斯核使用可学习的尺度参数 σ,使先验关联适应各种时间序列模式,例如不同长度的异常段。系列关联分支是从原始系列中学习关联,可以自适应地找到最有效的关联。请注意,这两种形式维护了每个时间点的时间依赖性,这比逐点表示提供更多信息。它们还分别反映了相邻浓度先验和学习到的真实关联,其差异应是正常-异常可区分的。第l层的Anomaly-Attention为:
初始化:
Q
,
K
,
V
,
σ
=
X
l
−
1
W
Q
l
,
X
l
−
1
W
K
l
,
X
l
−
1
W
V
l
,
X
l
−
1
W
σ
l
{\mathcal Q},{\mathcal K},{\mathcal V},\sigma={\mathcal X}^{l-1}W_{\mathcal Q}^{l},{\mathcal X}^{l-1}W_{\mathcal K}^{l},{\mathcal X}^{l-1}W_{\mathcal V}^{l},{\mathcal X}^{l-1}W_{\sigma}^{l}
Q,K,V,σ=Xl−1WQl,Xl−1WKl,Xl−1WVl,Xl−1Wσl
Prior-Association:
P
l
=
Rescale
(
[
1
2
π
σ
i
exp
(
−
∣
j
−
i
∣
2
2
σ
i
2
)
]
i
,
j
∈
{
1
,
⋯
,
N
}
)
\mathcal{P}^l=\text{Rescale}\left(\left[\frac1{\sqrt{2\pi}\sigma_i}\exp\left(-\frac{|j-i|^2}{2\sigma_i^2}\right)\right]_{i,j\in\{1,\cdots,N\}}\right)
Pl=Rescale([2πσi1exp(−2σi2∣j−i∣2)]i,j∈{1,⋯,N})
Series-Association:
S
l
=
Softmax
(
Q
K
T
d
m
o
d
e
l
)
\begin{aligned}\mathcal{S}^l&=\text{Softmax}\left(\frac{\mathcal{QK}^\mathrm{T}}{\sqrt{d_{\mathrm{model}}}}\right)\end{aligned}
Sl=Softmax(dmodelQKT)
Reconstruction:
Z
^
l
=
S
l
V
\widehat{\mathcal{Z}}^l=\mathcal{S}^l\mathcal{V}
Z
l=SlV
其中 Q, K, V ∈ RN×dmodel , σ ∈ RN×1 分别表示 self-attention 的q、k、v和学习尺度。 Wl Q,Wl K,Wl V ∈ Rdmodel×dmodel ,Wl σ ∈ Rdmodel×1 分别表示第 l 层 Q、K、V、σ 的参数矩阵。先验关联 Pl ∈ RN×N 是基于学习的尺度 σ ∈ RN×1 生成的,第 i 个元素 σi 对应于第 i 个时间点。具体来说,对于第i个时间点,通过高斯核计算其与第j个点的关联权重 G(|j −i|; σi) = √ 1 2πσi exp(−|j−i|2 2σ2 i ) w.r.t.距离|j −i|。此外,我们使用 Rescale(·) 通过除以行总和将关联权重转换为离散分布 Pl。 Sl ∈ RN×N 表示级数关联。 Softmax(·) 沿最后一个维度标准化注意力图。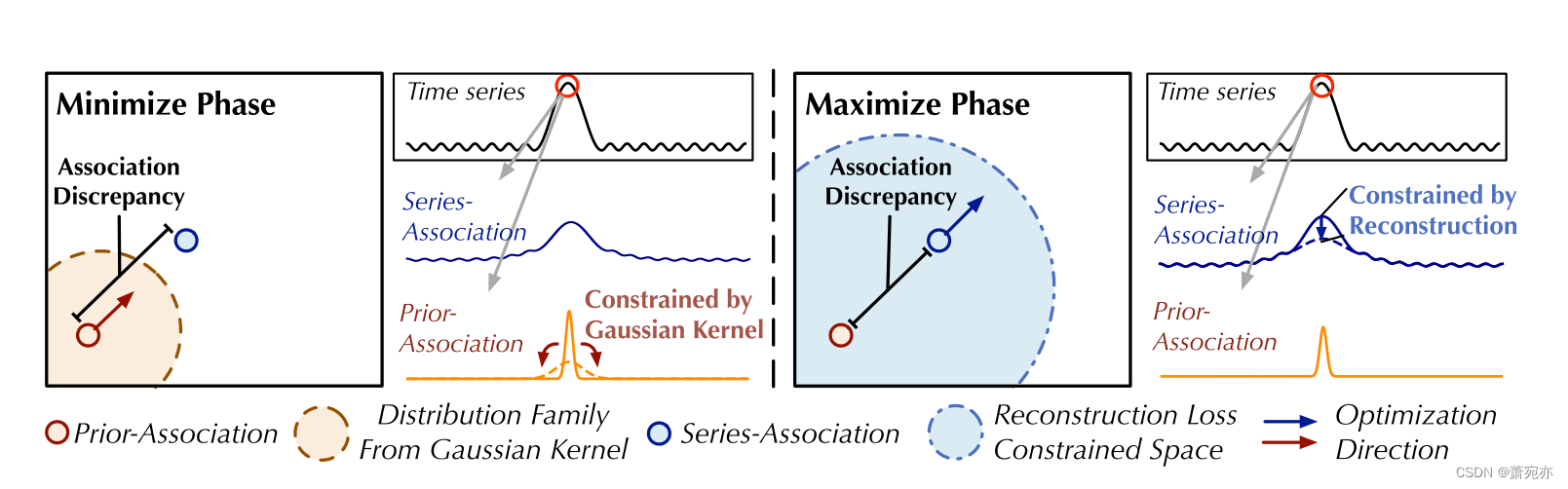
图 2:极小极大关联学习。在最小化阶段,先验关联最小化由高斯核导出的分布族内的关联差异。在最大化阶段,级数关联在重建损失下最大化关联差异。
因此,Sl的每一行形成离散分布。
Z
^
l
∈
R
N
×
d
m
o
d
e
l
\widehat{\mathcal{Z}}^l\in\mathbb{R}N\times d_{\mathrm{model}}
Z
l∈RN×dmodel是第 l 层中 Anomaly-Attention 之后的隐藏表示。我们使用 Anomaly-Attention(·) 来总结方程 2。
在我们使用的多头版本中,对于 h 个头来说,学习尺度是 σ ∈ RN×h。 Qm、Km、Vm ∈ R N × d m o d e l h \mathbb{R}^{N\times\frac{d_{\mathrm{model}}}h} RN×hdmodel 分别表示第 m 个头的查询、键和值。该块连接多个头的输出 { Z ^ m l ∈ R N × d m o d e l h } 1 ≤ m ≤ h \{\widehat{\mathcal{Z}}_{m}^{l}\in\mathbb{R}^{N\times\frac{d_{\mathrm{model}}}{h}}\}_{1\leq m\leq h} {Z ml∈RN×hdmodel}1≤m≤h并得到最终结果 Z ^ l ∈ R N × d m o d e l \widehat{\mathcal{Z}}^l\in\mathbb{R}N\times d_{\mathrm{model}} Z l∈RN×dmodel 。
Association Discrepancy 我们将关联差异形式化为先验关联和序列关联之间的对称 KL 散度,它代表这两个分布之间的信息增益(Neal,2007)。我们对多层的关联差异进行平均,以将多级特征的关联组合成信息更丰富的度量,如下所示:
A
s
s
D
i
s
(
P
,
S
;
X
)
=
[
1
L
∑
l
=
1
L
(
K
L
(
P
i
,
:
l
∥
S
i
,
:
l
)
+
K
L
(
S
i
,
:
l
∥
P
i
,
:
l
)
)
]
i
=
1
,
⋯
,
N
(
3
)
\mathrm{AssDis}(\mathcal{P},\mathcal{S};\mathcal{X})=\left[\frac{1}{L}\sum_{l=1}^{L}\left(\mathrm{KL}(\mathcal{P}_{i,:}^{l}\|\mathcal{S}_{i,:}^{l})+\mathrm{KL}(\mathcal{S}_{i,:}^{l}\|\mathcal{P}_{i,:}^{l})\right)\right]_{i=1,\cdots,N}(3)
AssDis(P,S;X)=[L1l=1∑L(KL(Pi,:l∥Si,:l)+KL(Si,:l∥Pi,:l))]i=1,⋯,N(3)
其中 KL(·||·) 是对应于 Pl 和 Sl 的每一行的两个离散分布之间计算的 KL 散度。 AssDis(P, S; X) ∈ RN×1 是 X 相对于多层的先验关联 P 和系列关联 S 的逐点关联差异。结果的第i个元素对应于X的第i个时间点。根据之前的观察,会出现异常
3.2 极小极大关联学习
作为一项无监督任务,我们利用重建损失来优化我们的模型。重建损失将指导系列关联找到信息最丰富的关联。为了进一步放大正常时间点和异常时间点之间的差异,我们还使用额外的损失来放大关联差异。由于先验关联的单峰特性,差异损失会引导序列关联更多地关注非相邻区域,这使得异常的重建更加困难,也使得异常更容易识别。输入序列 X ∈ RN×d 的损失函数形式化为
L
T
o
t
a
l
(
X
^
,
P
,
S
,
λ
;
X
)
=
∥
X
−
X
^
∥
F
2
−
λ
×
∥
A
s
s
D
i
s
(
P
,
S
;
X
)
∥
1
(
4
)
\mathcal{L}_{\mathrm{Total}}(\widehat{\mathcal{X}},\mathcal{P},\mathcal{S},\lambda;\mathcal{X})=\|\mathcal{X}-\widehat{\mathcal{X}}\|_{\mathrm{F}}^2-\lambda\times\|\mathrm{AssDis}(\mathcal{P},\mathcal{S};\mathcal{X})\|_1\quad\quad\quad(4)
LTotal(X
,P,S,λ;X)=∥X−X
∥F2−λ×∥AssDis(P,S;X)∥1(4)
其中 X ^ ∈ R N × d \widehat{\mathcal{X}}\in\mathbb{R}^{N\times d} X ∈RN×d 表示 X 的重构。 ∥ ⋅ ∥ F , ∥ ⋅ ∥ k \|\cdot\|_{\mathrm{F}},\|\cdot\|_k ∥⋅∥F,∥⋅∥k 表示Frobenius 和k-范数。 λ 是权衡损失项。当 λ > 0 时,优化是放大关联差异。提出了极小极大策略以使关联差异更加可区分。
最小最大策略 请注意,直接最大化关联差异将极大地减小高斯核的尺度参数(Neal,2007),使得先验关联变得毫无意义。为了更好地控制关联学习,我们提出了极小极大策略(图 2)。具体来说,对于最小化阶段,我们驱动先验关联 Pl 来近似从原始序列中学习到的序列关联 Sl。这个过程将使先验关联适应各种时间模式。对于最大化阶段,我们优化系列关联以扩大关联差异。这个过程迫使系列关联更多地关注非相邻的地平线。因此,整合重建损失,两个阶段的损失函数为:
Minimize Phase:
L
Total
(
X
^
,
P
,
S
detach
,
−
λ
;
X
)
\mathcal{L}_\text{Total}(\widehat{\mathcal{X}},\mathcal{P},\mathcal{S}_\text{detach},-\lambda;\mathcal{X})
LTotal(X
,P,Sdetach,−λ;X)
Maxmize Phase:
L
T
o
t
a
l
(
X
^
,
P
d
e
t
a
c
h
,
S
,
λ
;
X
)
\mathcal{L}_{\mathrm{Total}}(\widehat{\mathcal{X}},\mathcal{P}_{\mathrm{detach}},\mathcal{S},\lambda;\mathcal{X})
LTotal(X
,Pdetach,S,λ;X)
其中 λ > 0 和 ∗detach 意味着停止关联的梯度反向传播(图 1)。当P在最小化阶段逼近Sdetach时,最大化阶段将对串联关联进行更强的约束,迫使时间点更多地关注非相邻区域。在重建损失下,异常比正常时间点更难实现,从而放大了关联差异的正常与异常可区分性。
基于关联的异常标准 我们将归一化关联差异纳入重建标准,这将受益于时间表示和可区分的关联差异。 X ∈ RN×d 最终的异常得分如下:
AnomalyScore
(
X
)
=
Softmax
(
−
AssDis
(
P
,
S
;
X
)
)
⊙
[
∥
X
i
,
⋮
−
X
^
i
,
⋮
∥
2
2
]
i
=
1
,
⋯
,
N
(
6
)
\text{AnomalyScore}(\mathcal{X})=\text{Softmax}\Big(-\text{AssDis}(\mathcal{P},\mathcal{S};\mathcal{X})\Big)\odot\Big[\|\mathcal{X}_{i,\vdots}-\widehat{\mathcal{X}}_{i,\vdots}\|_2^2\Big]_{i=1,\cdots,N}\quad(6)
AnomalyScore(X)=Softmax(−AssDis(P,S;X))⊙[∥Xi,⋮−X
i,⋮∥22]i=1,⋯,N(6)
4、实验
我们根据三个实际应用的六个基准对 Anomaly Transformer 进行了广泛评估。
数据集 以下是对六个实验数据集的描述:(1)SMD(Server Machine Dataset,Su et al.(2019))是从一家大型互联网公司收集的为期 5 周的数据集,具有 38 个维度。 (2) PSM(Pooled Server Metrics,Abdulaal et al. (2021))是从 eBay 的多个应用服务器节点内部收集的,具有 26 个维度。 (3) MSL(火星科学实验室漫游车)和 SMAP(土壤湿度主动被动卫星)都是 NASA 的公共数据集(Hundman et al., 2018),分别有 55 维和 25 维,包含来自事件的遥测异常数据航天器监测系统的意外异常(ISA)报告。 (4) SWaT(安全水处理,Mathur & Tippenhauer (2016))是从连续运行的关键基础设施系统的 51 个传感器获得的。 (5)NeurIPS-TS(NeurIPS 2021 Time Series Benchmark)是Lai等人提出的数据集。 (2021),包括按行为驱动分类法分类的五种时间序列异常场景,分别为点全局、模式上下文、模式 shapelet、模式季节性和模式趋势。统计详情总结于附录表13。
实施细节 遵循 Shen 等人的完善协议。 (2020),我们采用非重叠滑动窗口来获得一组子系列。所有数据集的滑动窗口大小固定为 100。如果时间点的异常分数(公式 6)大于某个阈值 δ,我们将其标记为异常。确定阈值δ以使验证数据集中的r比例数据被标记为异常。对于主要结果,我们为 SWaT 设置 r = 0.1%,为 SMD 设置 r = 0.5%,为其他数据集设置 r = 1%。我们采用广泛使用的调整策略(Xu et al., 2018; Su et al., 2019; Shen et al., 2020):如果检测到某个连续异常段中的某个时间点,则该异常段中的所有异常被视为被正确检测到。从观察到异常时间点会引起警报并进一步使整个分段在实际应用中引起注意的观察来看,该策略是合理的。 Anomaly Transformer 包含 3 层。我们将隐藏状态 dmodel 的通道数设置为 512,头数 h 为 8。所有数据集的超参数 λ(方程 4)设置为 3,以权衡损失函数的两部分。我们使用 ADAM (Kingma & Ba, 2015) 优化器,初始学习率为 10−4。训练过程在 10 个 epoch 内提前停止,批量大小为 32。所有实验均在 Pytorch (Paszke et al., 2019) 中使用单个 NVIDIA TITAN RTX 24GB GPU 实施。
基线 我们将我们的模型与 18 个基线进行了广泛比较,包括基于重建的模型:InterFusion (2021)、BeatGAN (2019)、OmniAnomaly (2019)、LSTM-VAE (2018);密度估计模型:DAGMM (2018)、MPPCACD (2017)、LOF (2000);基于聚类的方法:ITAD (2020)、THOC (2020)、Deep-SVDD (2018);基于自回归的模型:CL-MPPCA (2019)、LSTM (2018)、VAR (1976);经典方法:OC-SVM (2004)、IsolationForest (2008)。来自变化点检测和时间序列分割的另外 3 个基线被推迟到附录 I。InterFusion (2021) 和 THOC (2020) 是最先进的深度模型。
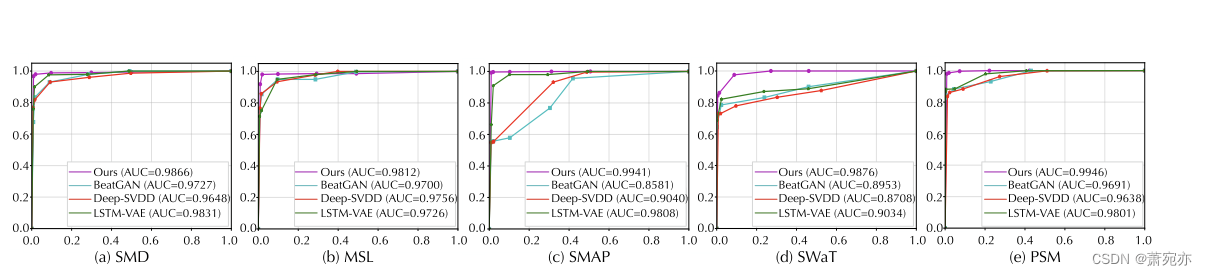
图 3:五个相应数据集的 ROC 曲线(横轴:假阳性率;纵轴:真阳性率)。 AUC 值(ROC 曲线下面积)越高,表明性能越好。预定义阈值比例r的取值为{0.5%,1.0%,1.5%,2.0%,10%,20%,30%}。
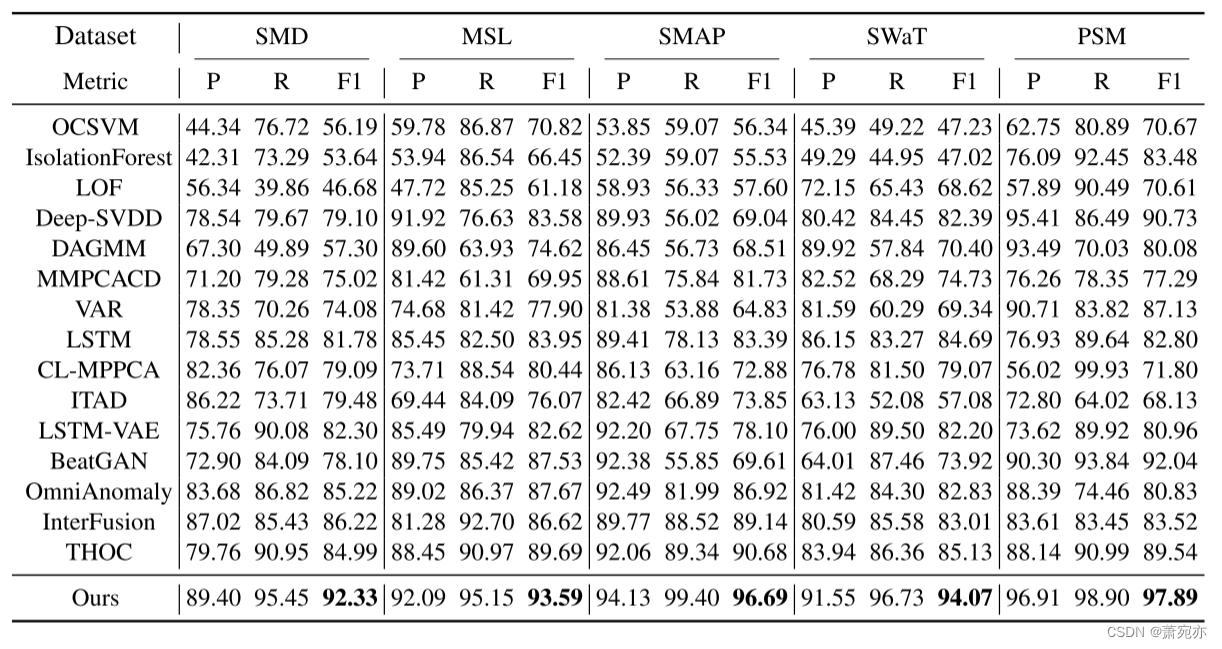
表 1:Anomaly Transformer(我们的)在五个真实世界数据集中的定量结果。 P、R 和 F1 分别表示精度、召回率和 F1 分数(以 % 表示)。 F1 分数是精确率和召回率的调和平均值。对于这三个指标,值越高表示性能越好。
4.1 主要结果
真实世界数据集 我们在五个真实世界数据集和十个竞争基线上广泛评估我们的模型。如表 1 所示,Anomaly Transformer 在所有基准测试中均达到了一致的最新水平。我们观察到考虑时间信息的深度模型优于一般的异常检测模型,例如 Deep-SVDD (Ruff et al., 2018) 和 DAGMM (Zong et al., 2018),这验证了时间建模的有效性。我们提出的 Anomaly Transformer 超越了 RNN 学习的逐点表示,并模拟了信息更丰富的关联。表1中的结果对于关联学习在时间序列异常检测中的优势具有说服力。另外,我们绘制了图3中的ROC曲线来进行完整的比较。 Anomaly Transformer 在所有五个数据集上具有最高的 AUC 值。这意味着我们的模型在各种预选阈值下的假阳性率和真阳性率方面表现良好,这对于实际应用非常重要。
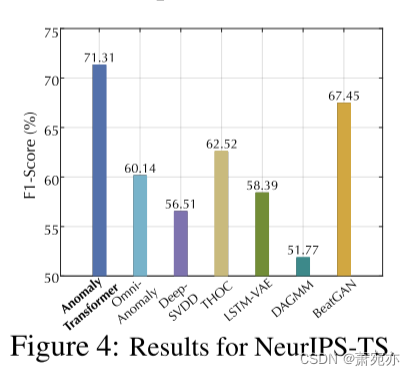
NeurIPS-TS 基准 该基准是根据 Lai 等人提出的精心设计的规则生成的。 (2021),它完全包括所有类型的异常,涵盖点异常和模式异常。如图 4 所示,Anomaly Transformer 仍然可以实现最先进的性能。这验证了我们的模型对各种异常的有效性
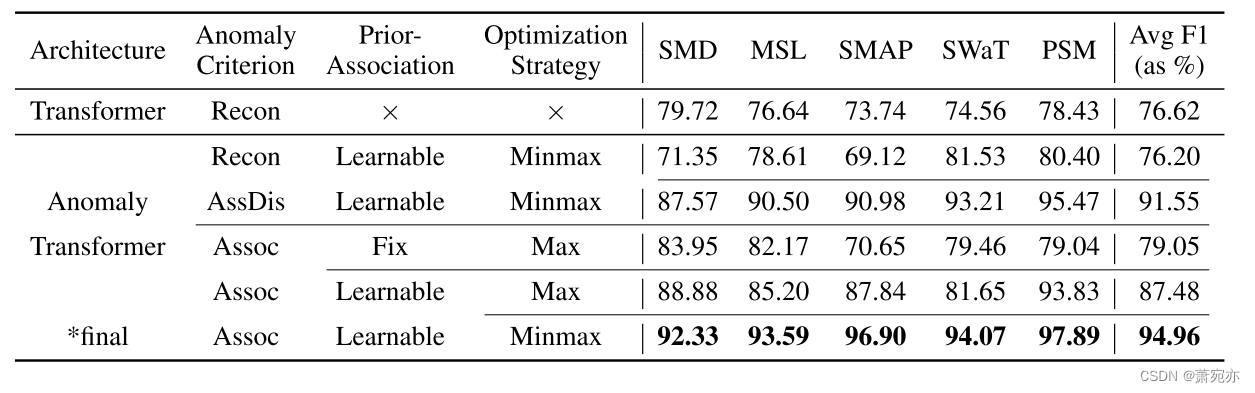
消融研究 如表 2 所示,我们进一步研究了模型中每个部分的效果。我们基于关联的标准始终优于广泛使用的重建标准。具体来说,基于关联的标准带来了 18.76%(76.20→94.96)平均绝对 F1 分数的显着提升。此外,直接以关联差异为标准仍然取得了良好的性能(F1-score:91.55%),并超越了之前最先进的模型 THOC(F1-score:根据表 1 计算的 88.01%)。此外,可学习的先验关联(对应于方程2中的σ)和极小极大策略可以进一步改进我们的模型,并获得8.43%(79.05→87.48)和7.48%(87.48→94.96)的平均绝对p THOC(F1-score: 88.01% 根据表 1 计算)。此外,可学习的先验关联(对应于方程2中的σ)和极小极大策略可以进一步改进我们的模型,分别获得8.43%(79.05→87.48)和7.48%(87.48→94.96)的平均绝对提升。最后,我们提出的 Anomaly Transformer 比纯 Transformer 提高了 18.34% (76.62→94.96) 的绝对改进。这些验证了我们设计的各个模块是有效的、必要的。更多关联差异的消除可以在附录 D 中找到。
表 2:异常标准、先验关联和优化策略的消融结果(F1 分数)。 Recon、AssDis 和 Assoc 分别表示纯重建性能、纯关联差异和我们提出的基于关联的标准。 Fix 是将先验关联的可学习尺度参数 σ 固定为 1.0。 Max 和 Minimax 分别指最大化(公式 4)和极小最大(公式 5)方式的关联差异策略.
4.2 模型分析
为了直观地解释我们的模型如何工作,我们提供了三个关键设计的可视化和统计结果:异常标准、可学习的先验关联和优化策略。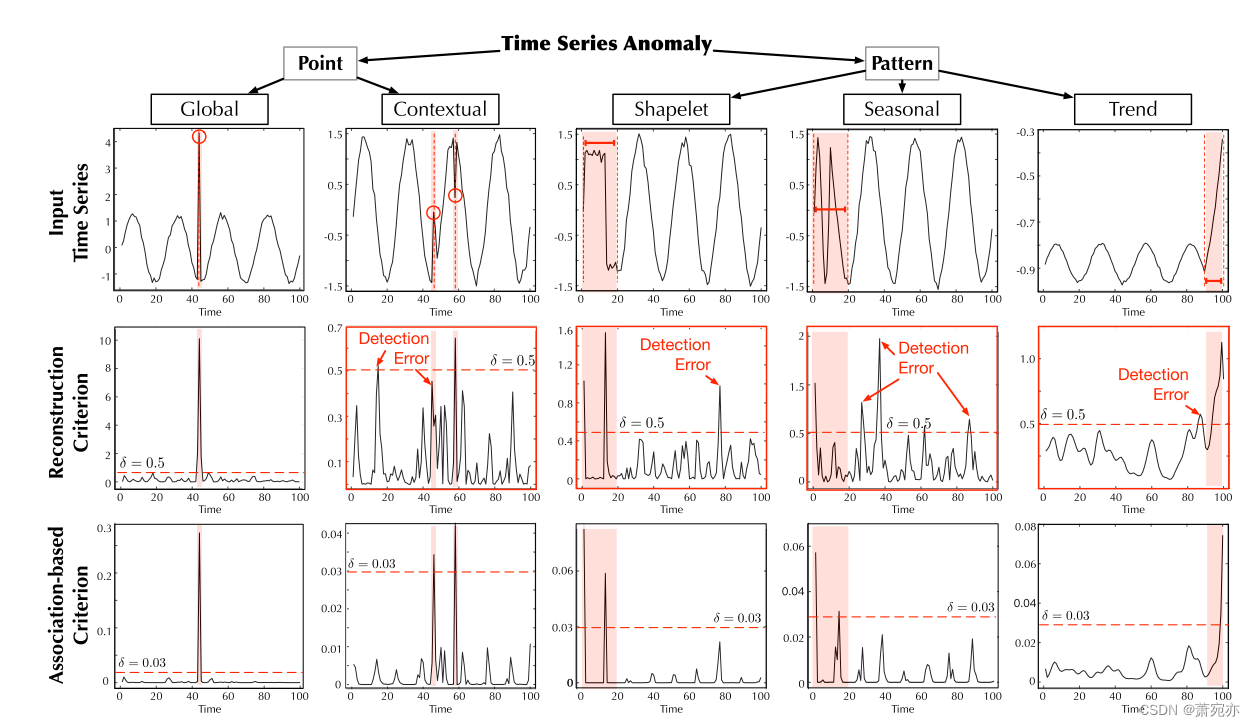

异常标准可视化
为了更直观地了解基于关联的标准如何工作,我们在图 5 中提供了一些可视化,并探索了不同类型异常下的标准性能,其中分类法来自 Lai 等人。 (2021)。我们可以发现我们提出的基于关联的标准总体上更具区分性。具体来说,基于关联的标准可以获得正常部分一致的较小值,这在点上下文和模式季节性情况下形成鲜明对比(图5)。相反,在上述两种情况下,重建准则的抖动曲线使检测过程变得混乱并失败。这验证了我们的标准可以突出异常并为正常点和异常点提供不同的值,从而使检测更加精确并降低误报率。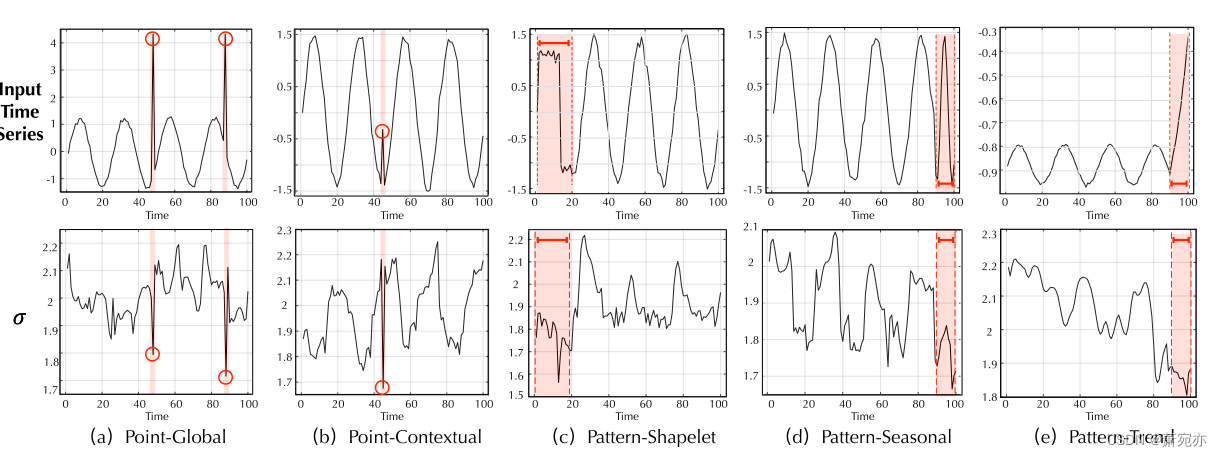
图 6:不同类型异常的学习尺度参数 σ(以红色突出显示)。
先验关联可视化
在极小极大优化期间,先验关联被学习以接近级数关联。因此,学习到的σ可以反映时间序列的相邻集中程度。如图 6 所示,我们发现 σ 会发生变化以适应时间序列的各种数据模式。特别是,异常的先验关联通常比正常时间点具有更小的 σ,这与我们对异常的邻近浓度归纳偏差相匹配。
优化策略分析
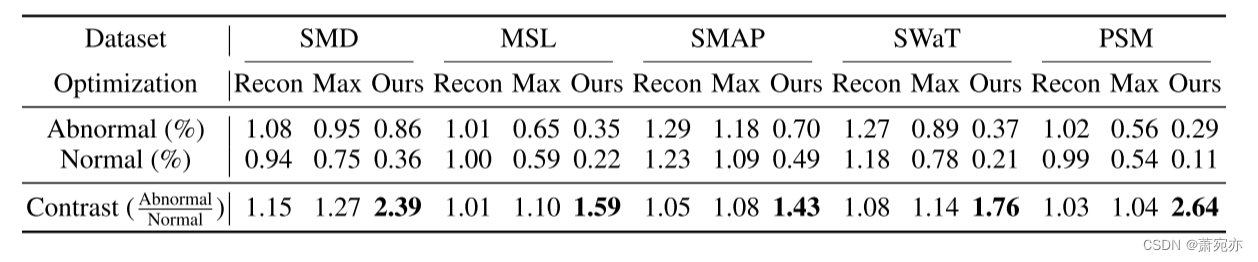
仅考虑重建损失,异常时间点和正常时间点在与相邻时间点的关联权重上表现相似,对应对比值接近1(表3)。最大化关联差异将迫使系列关联更多地关注非相邻区域。然而,为了获得更好的重建,异常点必须保持比正常时间点大得多的相邻关联权重,对应于更大的对比度值。但直接最大化会导致高斯核的优化问题,无法如预期那样强烈放大正常时间点和异常时间点之间的差异(SMD:1.15→1.27)。极小极大策略优化先验关联,为序列关联提供更强的约束。因此,极小极大策略比直接最大化(SMD:1.27→2.39)获得更多可区分的对比度值,从而表现更好。
表3:异常时间点和正常时间点相邻关联权重的统计结果。 Recon、Max和Minimax分别表示由重建损失、直接最大化和极小极大策略监督的关联学习过程。对比度值(异常/正常)越高,表明正常时间点和异常时间点的区分能力越强。
5、结论和未来工作
本文研究无监督时间序列异常检测问题。与以前的方法不同,我们通过 Transformers 学习了信息更丰富的时间点关联。基于对关联差异的关键观察,我们提出了 Anomaly Transformer,包括具有两分支结构的 AnomalyAttention 来体现关联差异。采用极小极大策略进一步放大正常时间点和异常时间点之间的差异。通过引入关联差异,我们提出了基于关联的准则,使得重构性能和关联差异相协调。 Anomaly Transformer 通过一系列详尽的实证研究取得了最先进的结果。未来的工作包括根据自回归和状态空间模型的经典分析对 Anomoly Transformer 进行理论研究。
















 463
463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









