







目录
1. 数组
一种数据结构,特点是不可变,有索引,有序。
1.1 初始化
- 静态初始化:int[] nums=[1,2,3]
- 动态初始化:int[] nums2 = new int[5]
1.2 遍历
- for循环
- 增强for循环
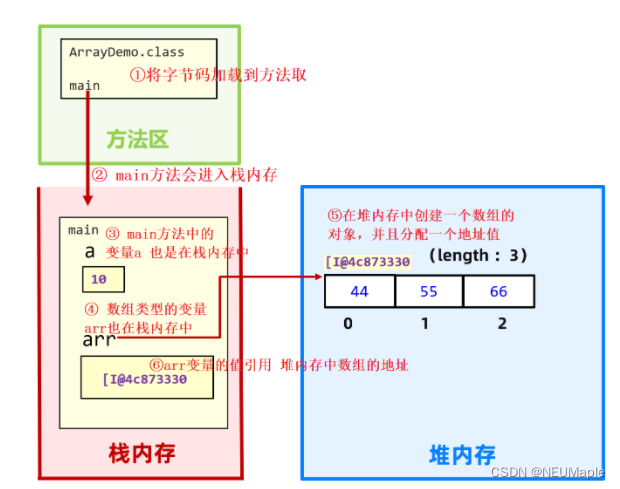
1.3 数组执行原理
JAVA是把编译后的字节码加载到Java虚拟机中执行的。
为了方便虚拟机执行程序,将虚拟机划分为方法区、堆、栈、本地方法栈、寄存器五块区域。重点关注方法区、堆、栈。
- 方法区:字节码文件先加载到这里。
- 堆:存储new出来的对象,并分配地址。
- 栈:方法运行时进入的区域,变量在这个区域中。
1.4 Arrays操作数组
JAVA定义了Arrays工具类来操作数组。常用方法有:
- Arrays.toString(); //将数组中的内容全部打印出来
- Arrays.sort(); //数组排序
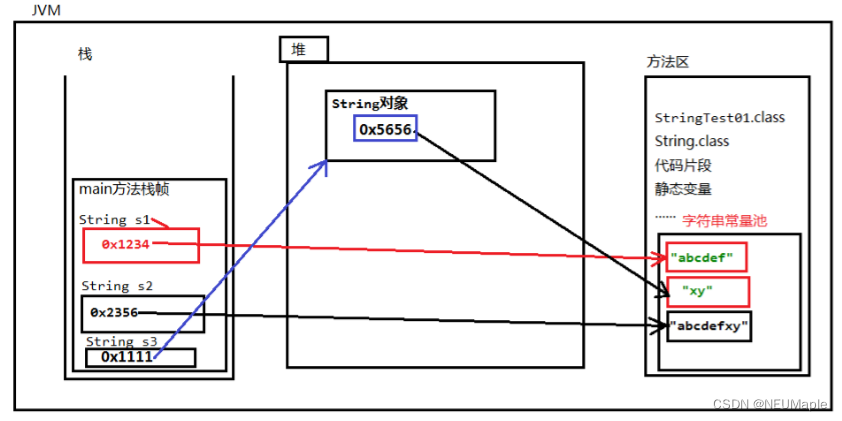
2. String字符串
表示字符串类型,属于引用类型,不属于基本类型。
双括号括起来的字符串,是不可变的,会存储在方法区的常量池中。
但new出来的String存储在堆中,且分配不同地址。
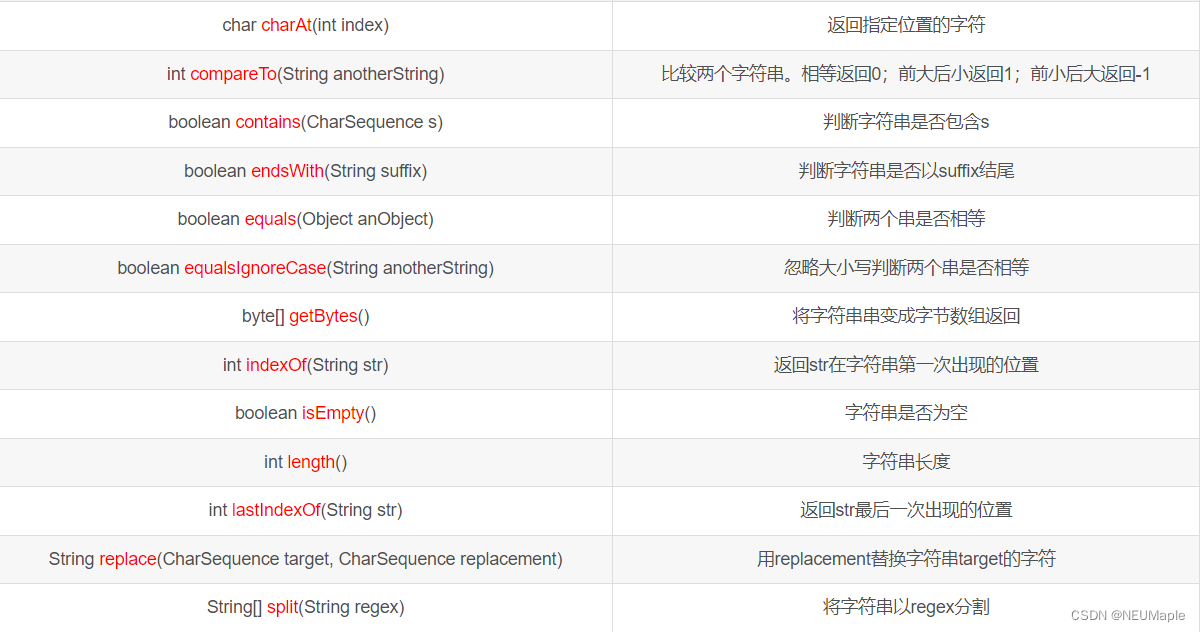
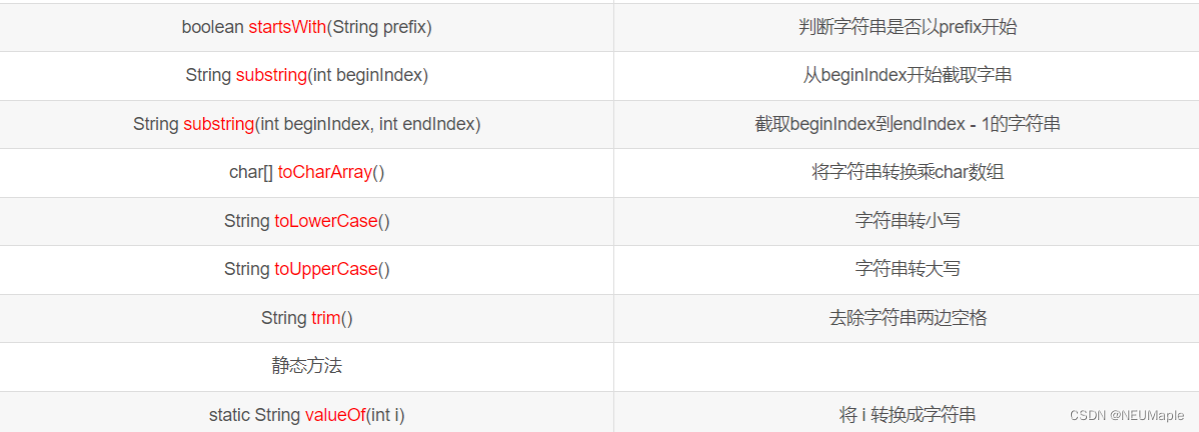
常用方法
3. 集合
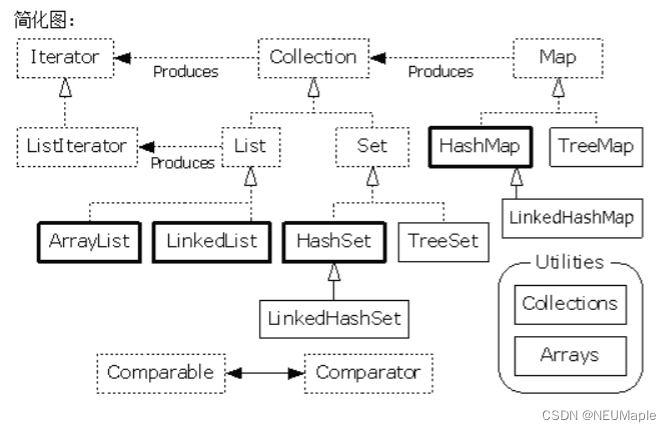
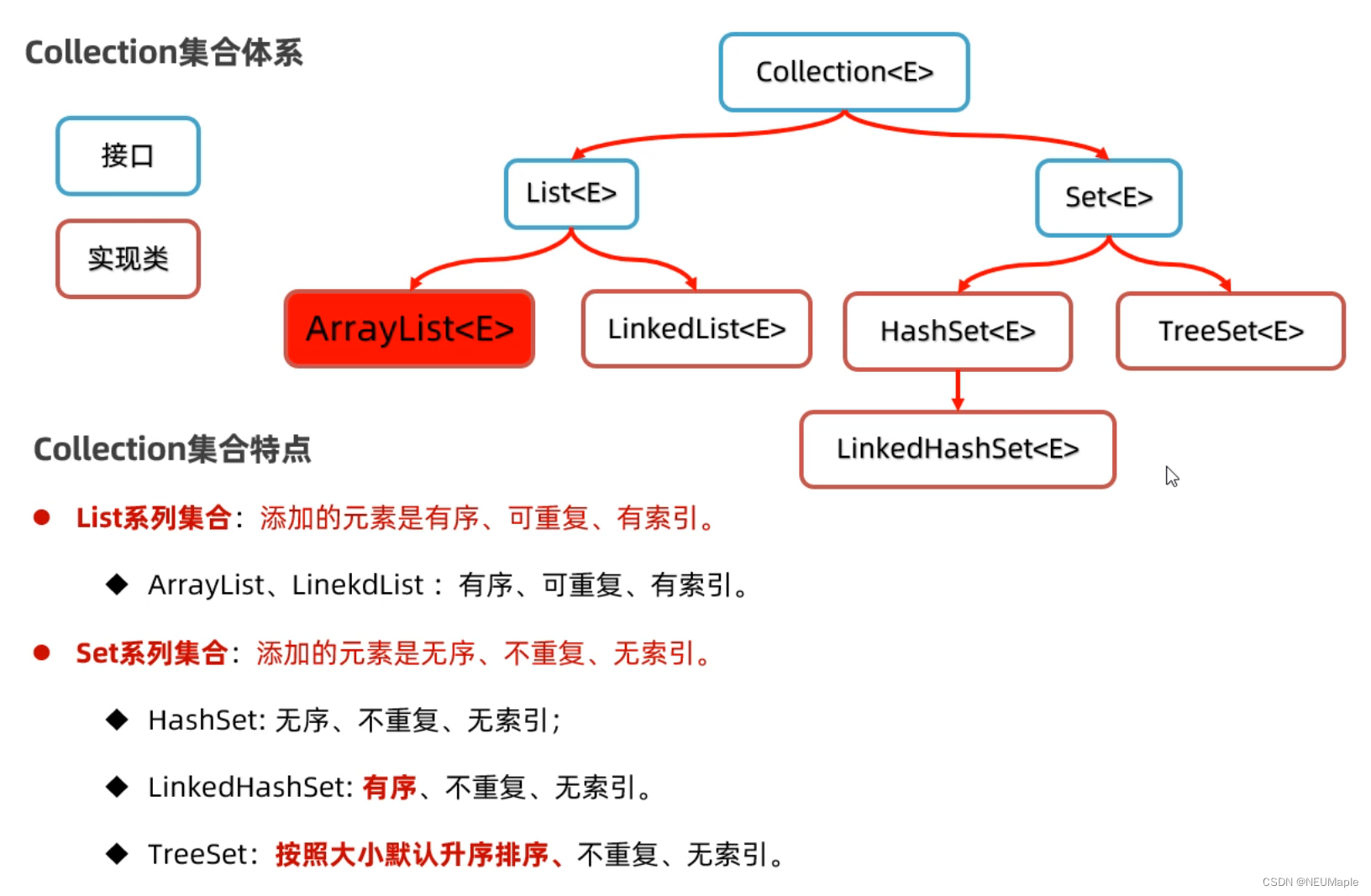
大框架分为单列集合Collection和双列集合Map。
List元素有序,可重复,有索引。
Set元素无序,不可重复,无索引。
Map是无序,无索引的键值对。
3.1 Collection
3.1.1 常用方法
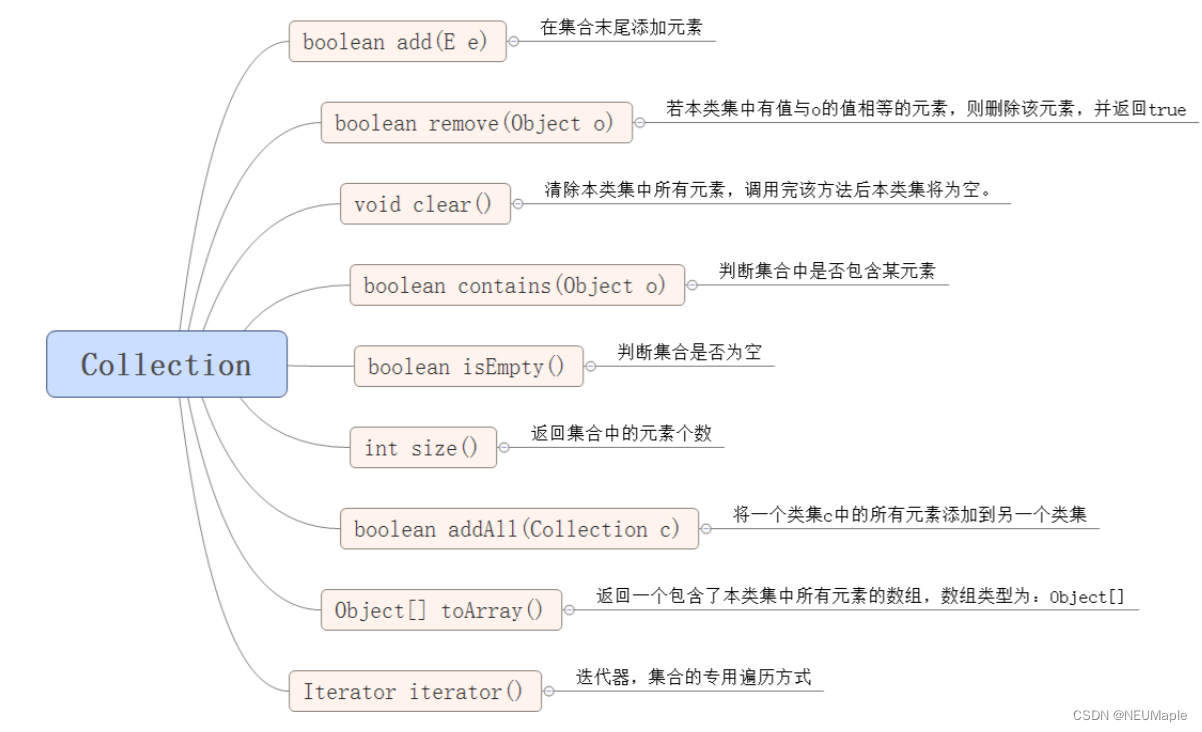
3.1.2 分类
List:元素有序,可重复,有索引
- ArrayList:数组实现,查询快,没有同步,线程不安全
- LinkedList:链表实现,增删快,没有同步,线程不安全
- Vector:数组实现,同步,线程安全。Stack是Vector的实现类
Set:元素无序,不重复,无索引
- HashSet:Hash表存储元素,LinkedHashSet维护元素插入顺序
- TreeSet:二叉树实现,做内部排序
3.1.3 遍历方式
- 迭代器遍历:Iterator<String> it = c.iterator(); t.hasNext(); it.next()
- 增强for循环
- forEach遍历,也就是Lambda表达式遍历。list.forEach(e->sout(e))
3.1.4 List

ArrayList底层原理: 基于数组结构实现。
数组长度固定,ArrayList可变原理:
- 利用无参构造器创建的集合,会在底层默认创建长度为0的数组。
- 添加第一个元素时,底层会创建一个新的长度为10的数组。
- 存满时,会扩容1.5倍。
- 如果一次添加多个元素,1.5倍放不下,会以实际内容为准
数组扩容并不是在原数组上扩容,而是创建一个新的数组,将原来数组内容复制过去。
遍历方式:可以使用普通For循环,外加上面三种方式。
3.1.5 Set
Set具有与Collection完全一样的接口,因此没有任何额外的功能,不像前面有两个不同的List。实际上Set就是Collection,只 是行为不同。(这是继承与多态思想的典型应用:表现不同的行为。)Set不保存重复的元素。
(1)HashSet
底层原理:HashSet底层时基于Hash表实现的。
- JDK8以前:Hash表=数组+链表
- JDK8以后:Hash表=数组+链表+红黑树

所以说要想使用HashSet存储元素,此元素对象要有两个方法:一个是hashCode方法获取元素的hashCode值(哈希值);另一个是调用了元素的equals方法,用来比较新添加的元素和集合中已有的元素是否相同。
-
只有新添加元素的hashCode值和集合中以后元素的hashCode值相同、新添加的元素调用equals方法和集合中已有元素比较结果为true, 才认为元素重复。
-
如果hashCode值相同,equals比较不同,则以链表的形式连接在数组的同一个索引为位置(如上图所示)
在JDK8开始后,为了提高性能,当链表的长度超过8时,就会把链表转换为红黑树,如下图所示:

(2)LinkedHashSet
底层原理:也是Hash表,多了双向链表来维护元素的存取顺序。
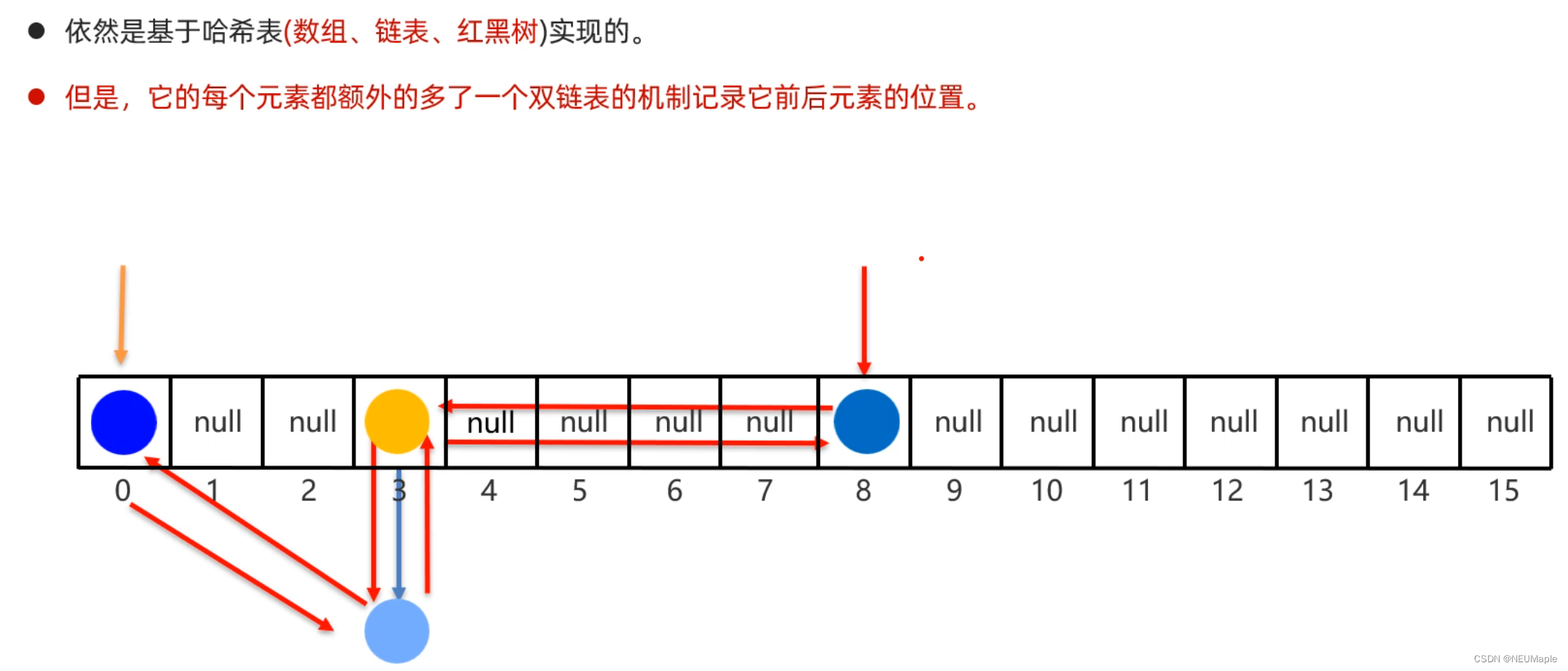
(3)TreeSet
底层原理:二叉树(红黑树数据结构)
有序,不重复,无索引。
排序时必须指定规则,tring类型的元素,或者Integer类型的元素,它们本身就具备排序规。
两种方式定义排序规则:
- 让元素的类实现Comparable接口,重写compareTo方法
- 在创建TreeSet集合时,通过构造方法传递Compartor比较器对象。
@Override
public int compareTo(Student o) {
//this:表示将要添加进去的Student对象
//o: 表示集合中已有的Student对象
return this.age-o.age;
}
Set<Student> set = new TreeSet<>(((o1, o2) -> o1.getAge()- o2.getAge()));3.1.6 适用场景
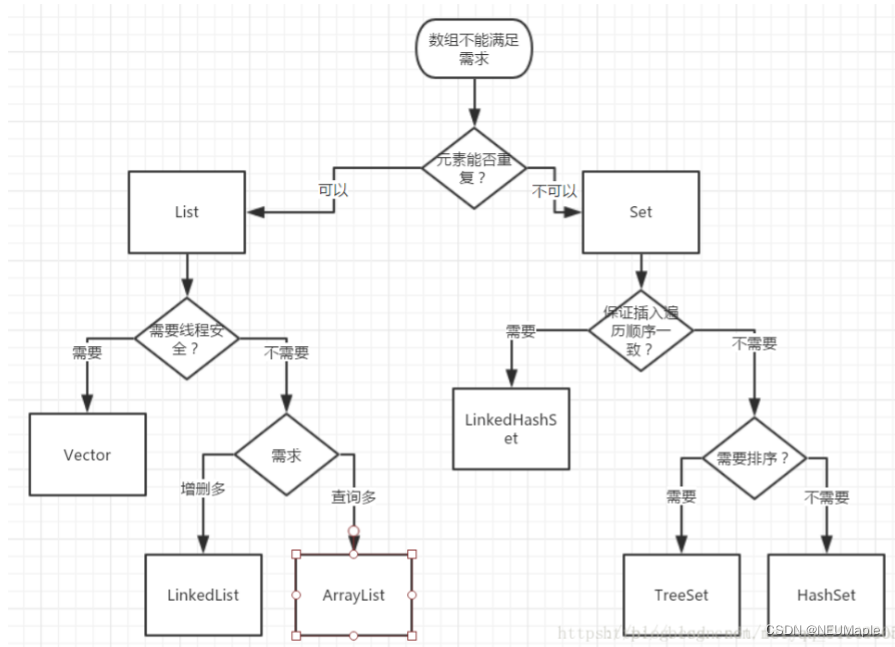
3.1.7 Collection总结
3.2 Collection其他操作
3.2.1 并发修改异常
在使用迭代器遍历集合时,可能存在并发修改异常。
List<String> list = new ArrayList<>();
list.add("王麻子");
list.add("小李子");
list.add("李爱花");
list.add("张全蛋");
list.add("晓李");
list.add("李玉刚");
System.out.println(list); // [王麻子, 小李子, 李爱花, 张全蛋, 晓李, 李玉刚]
//需求:找出集合中带"李"字的姓名,并从集合中删除
Iterator<String> it = list.iterator();
while(it.hasNext()){
String name = it.next();
if(name.contains("李")){
list.remove(name);
}
}
System.out.println(list);运行上面的代码,会出现下面的异常。这就是并发修改异常

为什么会出现这个异常呢?那是因为迭代器遍历机制,规定迭代器遍历集合的同时,不允许集合自己去增删元素,否则就会出现这个异常。
怎么解决?交给迭代器就行
//需求:找出集合中带"李"字的姓名,并从集合中删除
Iterator<String> it = list.iterator();
while(it.hasNext()){
String name = it.next();
if(name.contains("李")){
//list.remove(name);
it.remove(); //当前迭代器指向谁,就删除谁
}
}3.2.2 可变参数
-
可变参数是一种特殊的形式参数,定义在方法、构造器的形参列表处,它可以让方法接收多个同类型的实际参数。
-
可变参数在方法内部,本质上是一个数组
public class ParamTest{
public static void main(String[] args){
//不传递参数,下面的nums长度则为0, 打印元素是[]
test();
//传递3个参数,下面的nums长度为3,打印元素是[10, 20, 30]
test(10,20,30);
//传递一个数组,下面数组长度为4,打印元素是[10,20,30,40]
int[] arr = new int[]{10,20,30,40}
test(arr);
}
public static void test(int...nums){
//可变参数在方法内部,本质上是一个数组
System.out.println(nums.length);
System.out.println(Arrays.toString(nums));
System.out.println("----------------");
}
}注意:
-
一个形参列表中,只能有一个可变参数;否则会报错
-
一个形参列表中如果多个参数,可变参数需要写在最后;否则会报错
3.2.3 Collections工具类

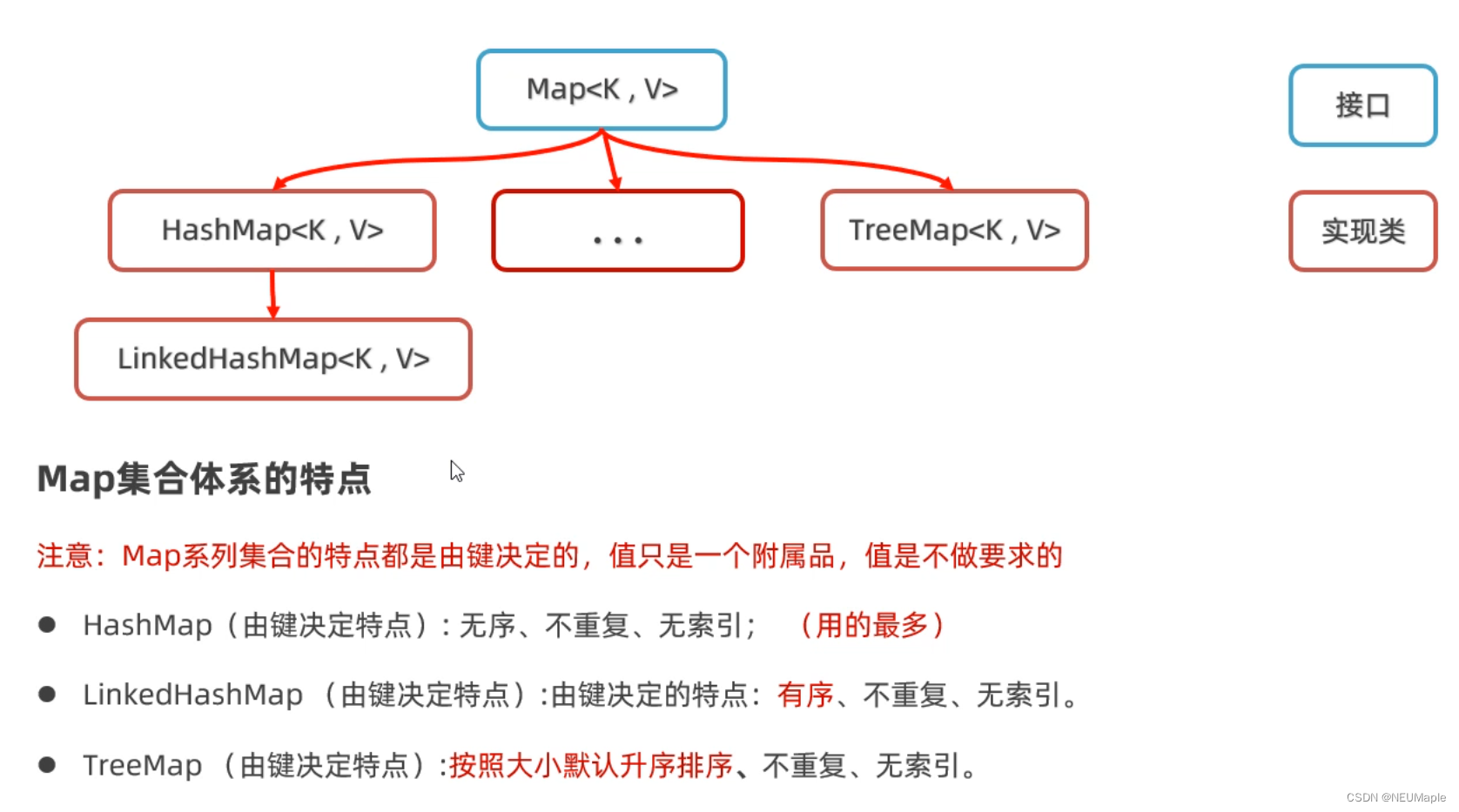
3.2 Map
键不能重复,值可以重复,每一个键只能找到自己对应的值。
3.2.1 常用方法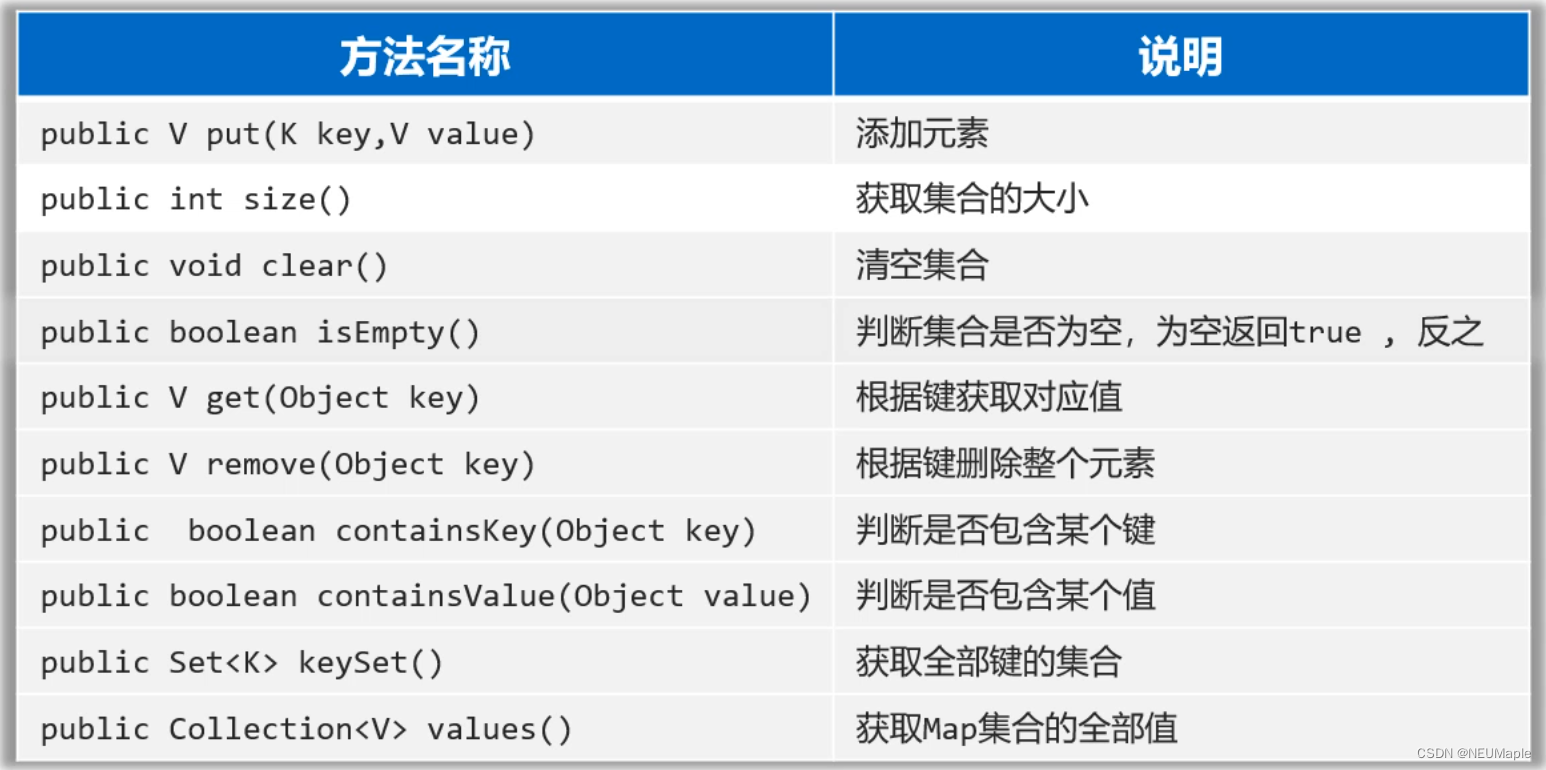
3.2.2 遍历方式
- 键找值:keySet(),get()
- 获取整个键值对:Set<Map.Entry<K,V>> entrySet()
- forEach+Lambda表达式:map.forEach((k,v) -> sout(k+":"v))
3.2.3 Map底层原理
其实Map和Set说白了底层是一个东西。都是基于Hash表实现的。
- Map,HashMap,LinkedHashMap,TreeMap
- Set,HashSet,LinkedHashSet,TreeSet
很像对吧
- Hashxxx都是无序,不重复,无索引,基于HashTable实现
- LinkedHashxxx都是有序,不重复,无索引,基于HashTable+链表实现
- Treexxx都是按大小默认升序排序,不重复,无索引,基于红黑树实现
HashMap追溯到最底层构造方法里其实new了一个HashMap,只保留了键,省略了值。
所以Set和Map都是基于HashTable实现的。保证不重复的原理就是hashCode()和equals()。
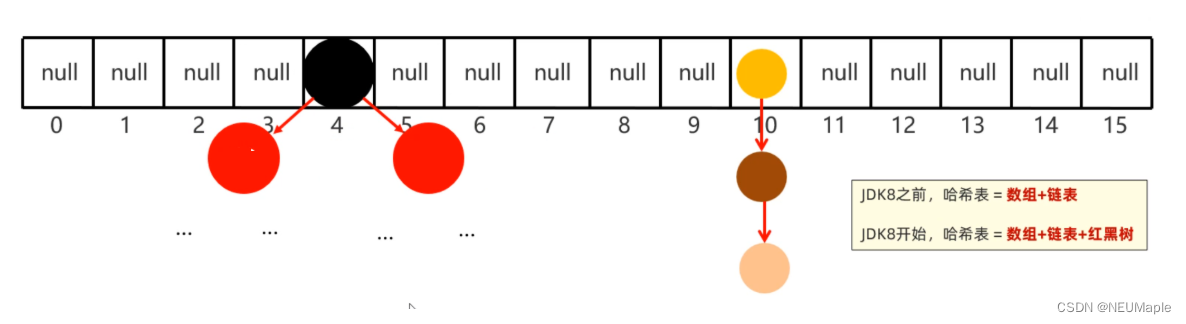
HashMap底层数据结构: 哈希表结构
JDK8之前的哈希表 = 数组+链表
JDK8之后的哈希表 = 数组+链表+红黑树
哈希表是一种增删改查数据,性能相对都较好的数据结构
往HashMap集合中键值对数据时,底层步骤如下
第1步:当你第一次往HashMap集合中存储键值对时,底层会创建一个长度为16的数组
第2步:把键然后将键和值封装成一个对象,叫做Entry对象
第3步:再根据Entry对象的键计算hashCode值(和值无关)
第4步:利用hashCode值和数组的长度做一个类似求余数的算法,会得到一个索引位置
第5步:判断这个索引的位置是否为null,如果为null,就直接将这个Entry对象存储到这个索引位置
如果不为null,则还需要进行第6步的判断
第6步:继续调用equals方法判断两个对象键是否相同
如果equals返回false,则以链表的形式往下挂
如果equals方法true,则认为键重复,此时新的键值对会替换就的键值对。
HashMap底层需要注意这几点:
1.底层数组默认长度为16,如果数组中有超过12个位置已经存储了元素,则会对数组进行扩容2倍
数组扩容的加载因子是0.75,意思是:16*0.75=12
2.数组的同一个索引位置有多个元素、并且在8个元素以内(包括8),则以链表的形式存储
JDK7版本:链表采用头插法(新元素往链表的头部添加)
JDK8版本:链表采用尾插法(新元素我那个链表的尾部添加)
3.数组的同一个索引位置有多个元素、并且超过了8个,则以红黑树形式存储

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











