







1、线性回归模型
1、广义线性模型
也就是x和y的线性组合也就是:
y = w1x1+w2x2…+wnxn+b
coef_是系数矩阵w =[w1,w2…wn],intercept_就是截距
2、普通最小二乘法
拟合一个带有系数 w = (w_1, …, w_p) 的线性模型,使得数据集实际观测数据和预测数据(估计值)之间的残差平方和最小。
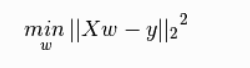
普通最小二乘依赖于数据的相关独立性,也就是矩阵的各列都是相关的,设计矩阵会趋向于奇异矩阵,这种特性导致最小二乘估计对于随机误差非常敏感,可能产生很大的方差。我们真实操作中,可能收集的数据高度相关,会严重影响结果。
2.1、使用函数说明
使用函数说明复制的知乎苹果小姐ye
最小二乘法线性回归:sklearn.linear_model.LinearRegression(fit_intercept=True, normalize=False,copy_X=True, n_jobs=1)
参数:
1、fit_intercept:boolean,optional,default True。是否计算截距,默认为计算。如果使用中心化的数据,可以考虑设置为False,
不考虑截距。注意这里是考虑,一般还是要考虑截距。
2、normalize:boolean,optional,default False。标准化开关,默认关闭;该参数在fit_intercept设置为False时自动忽略。如果为
True,回归会标准化输入参数:(X-X均值)/||X||,当然啦,在这里还是建议将标准化的工作放在训练模型之前;若为False,在训练
模型前,可使用sklearn.preprocessing.StandardScaler进行标准化处理。
3、copy_X:boolean,optional,default True。默认为True, 否则X会被改写。
4、n_jobs:int,optional,default 1int。默认为1.当-1时默认使用全部CPUs ??(这个参数有待尝试)。
属性:
coef_:array,shape(n_features, ) or (n_targets, n_features)。回归系数(斜率)。
intercept_: 截距
方法:
1、fit(X,y,sample_weight=None)
X:array, 稀疏矩阵 [n_samples,n_features]
y:array [n_samples, n_targets]
sample_weight:array [n_samples],每条测试数据的权重,同样以矩阵方式传入(在版本0.17后添加了sample_weight)。
2、predict(x):预测方法,将返回值y_pred
3、get_params(deep=True): 返回对regressor 的设置值
4、score(X,y,sample_weight=None):评分函数,将返回一个小于1的得分,可能会小于0
1.2、代码
from sklearn import linear_model
import numpy as np
reg = linear_model.LinearRegression(copy_ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2652
2652











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









