







CNN—— Convolutional Neural Network
CNN是为影像设计的。
一、Image Classfication

每一个neural对于每一个像素点都有一个weight。
Observation 1

某个neural看到鸟的眼睛,某个neural看到鸟的爪子,综合起来,机器判断这是一只鸟。对于看到这只鸟的眼睛特征的神经元,没有必要对所有的像素点进行查看。
因此,某些neural只需要将一小部分图片作为输入即可。
Simplification 1
- 在cnn中,设定一个receptive field,自己设定大小。
- 不同的receptive field可以相互重叠。
- 不同一个neural可以作用同一块区域。
- 不同的neural可以有不同的大小。
- 某些neural可以考虑其中一个通道

Simplification 1-Typical Setting
all channels——kernel size(3*3)
each receptive filed has a set of neurons(64个neurons)一组神经元关照一个范围
stride表示的是向右平移的一个步伐,一般设置为1或者2,因为希望每一个receptive有很高的重合性,以防止损失信息。
直到平移到边缘部分,超出范围了,补值(用0填充、边缘补充等)。
垂直方向也会移动。

Observation 2
相同的特征出现在图片不同的位置。
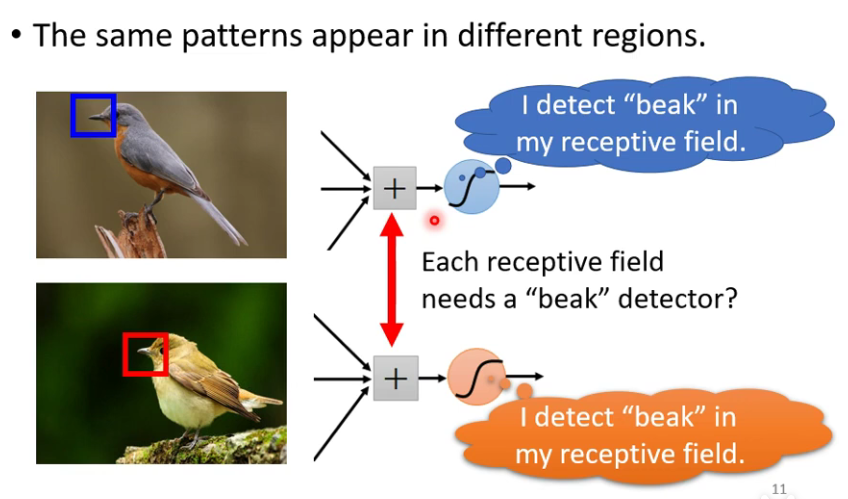
Simplification 2
让不同的neural共享参数parameter sharing,但是处理同一个receptive filed的neural不会共享参数。

Simplification 2-Typical Setting
常见的在影像辨识上的共享方法设置。相同颜色代表参数相同。

Benefit of convolutional layer
CNN是全连接神经网络加上receptive filed和parameter sharing之后形成的,具有较大的模型偏差,但是对于影像处理表现得较好。

二、another story based on filter
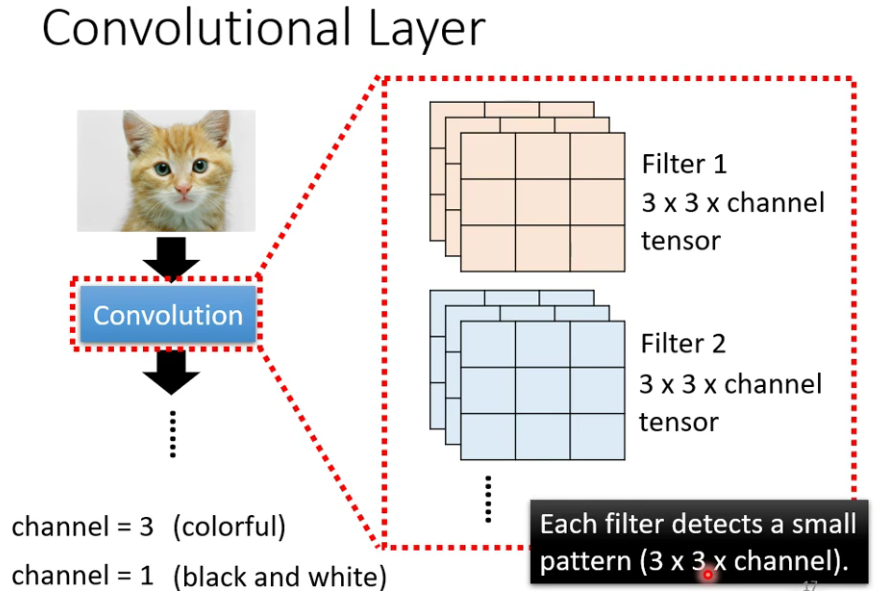
通过gredient decent找出每个filter的未知参数。
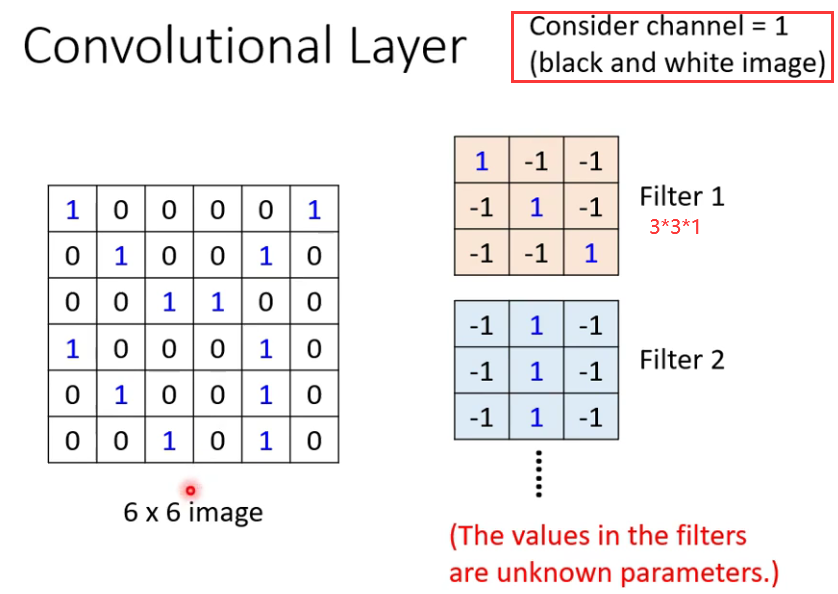
运作方式类似图像处理里面的模板和图片的处理方式。
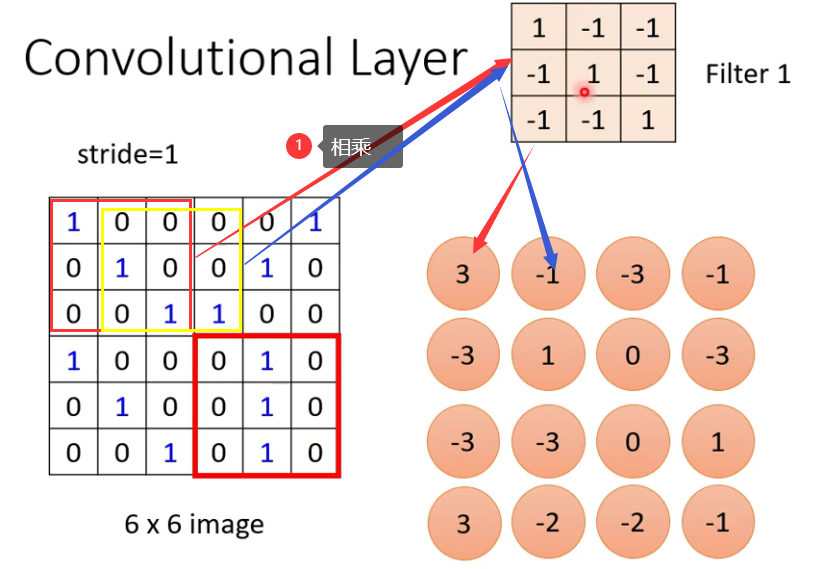
filter如何在侦测pattern呢?观察filter1,斜对角线全1,当它看到image里面出现对角线1时它的值会最大,
当所有的运行完毕以后,一个convolution卷积结束,得到feature map(6个filter就会的到64组上图),将feature map看成另外一张图片,其channels不是RGB,而是64.
接着进行第二层convolution,这个卷积里面也有一堆filter,但是这些filter的尺寸应该和前一层的输出相匹配,也就是3*3 *64 (filter 的高度就是要处理的影像的channels)

问题:如果filter的大小一直设置为3 *3 会不会导致只能侦测很小的一部分图片?
回答:不会,因为第二层的3 * 3 已经相当于包含第一层的5 * 5大小的信息了

对比前两个故事
不同的receptive filed——neural可以共用参数,这组共用的参数就叫filter

Observation 3
缩小图像(或称为下采样(subsampled)或降采样(downsampled))的主要目的:
1、使得图像符合显示区域的大小;
2、生成对应图像的缩略图。
放大图像(或称为上采样(upsampling)或图像插值(interpolating))的主要目的是放大原图像,从而可以显示在更高分辨率的显示设备上。
**下采样原理:**对于一幅图像I尺寸为MN,对其进行s倍下采样,即得到(M/s)(N/s)尺寸的得分辨率图像,当然s应该是M和N的公约数才行,如果考虑的是矩阵形式的图像,就是把原始图像s*s窗口内的图像变成一个像素,这个像素点的值就是窗口内所有像素的均值:


Pooling——Max Pooling
pooling最主要的理由是减少运算量,同时会损失一些信息。但是近年来,计算机算力逐渐变大,一些cnn会摒弃pooling

当然也有别的pooling,比如mean就是取均值,这个2 * 2 一组也是自定义的,max pooling就是取一组中最大值作为代表。

交替出现。

三、Application:Playing Go
3.1 背景

3.2 一些pattern会比整个图像要小

3.3 相同的pattern会出现在不同的区域

3.4 go没有使用pooling

another application
CNN也可以应用在图片和语音,但是一定要注意作者对filter和receptive filed的设计,不能盲目套用。
四、CNN缺陷
对于CNN来说,不能处理图像放大缩小和图片旋转。
CNN is not invaiant to scaling and rotation(we need data augmentation,在训练时将同一张图片放大缩小或者旋转以增加数据)
tive filed的设计,不能盲目套用。
四、CNN缺陷
对于CNN来说,不能处理图像放大缩小和图片旋转。
CNN is not invaiant to scaling and rotation(we need data augmentation,在训练时将同一张图片放大缩小或者旋转以增加数据)
















 841
841











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









