








Sarsa在状态发生变化后仅仅对前一状态行为对的Q值进行更新,而不会更新其他Q值。
Sarsa(λ)在状态每次发生变化后都会对整个状态空间的Q和E进行更新,会体现出获得当前奖励/惩罚对到达当前过程中的状态行为对的影响。它表现的是一个结果与某一个状态行为对的因果关系,与得到该结果最近的状态行为对,以及那些在此之前频繁发生的状态行为对得到这个结果的影响最大。(假设当前误差δt,则会对之前过程中的状态行为对的q值都进行一定程度的修改)
因此在假定寻找一条完整路径的问题中,除了终点处即时奖励为1其他点即时奖励都为0,假定初始化Q为全0,使用这两种算法会发生如下的区别。在到达终点前Sarsa(λ)的所有Q值也都为0,但到达终点后,Sarsa(λ)的δt将不为0,因此会对所有状态行为对根据E进行更新,Q也不再都为0。
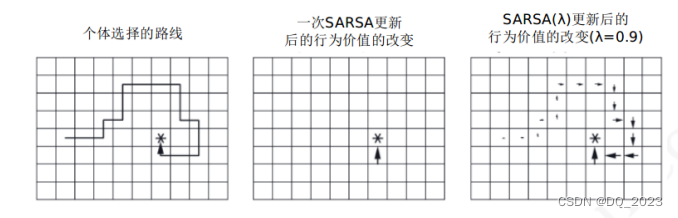
Sarsa(λ)中在每一个状态序列里,只有个体经历过的状态行为对的 E 才可能不为 0,为什么不仅仅对该状态序列涉及到的状态行为对进行更新呢?
答:因为我们不能通过先验的方式地知道整个状态序列中的状态行为对的信息(否则就等同于MC需要整个序列的信息),除非我们维护一个额外的表来纪录新出现的状态行为对,而往这个额外的表里添加新的状态行为对的E和Q值比更新总的状态行为空间要麻烦,特别是在早期个体没有一个较好的策略的时候需要花费很长时间才能找到终点位置,这在一定程度上反而没有更新状态空间省时。不过随着学习深入,策略得到优化,此表的规模会变小。
















 233
233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











