







1.前言
我们上一节介绍了MC强化学习方式和TD强化学习学习方式(五)强化学习——蒙特卡罗强化学习(MC) and 时序差分强化学习(TD)。从这一结开始,我们开始介绍一些具体的运用了这两种强化学习方式的强化学习算法。
2.同轨策略和离轨策略
先来看看两种学习方式。同轨策略方法(on-policy,在线学习)方法,在同轨方法中,用于生成采样数据序列的策略和用于实际决策的待评估和改进的策略是相同的。而在离轨策略(off-policy,离线学习) 中,用于评估或者改进的策略与生成采样数据的策略是不同的,即生成的数据“离开”了待优化的策略所决定的决策序列轨迹。后面所介绍的Sarsa算法就属于同轨策略下的时序差分控制。Q-learning算法属于离轨策略下的时序差分控制。
3.Sarsa算法
在学习经典的强化学习算法DQN之前,我们先来看看什么是Sarsa算法,Sarsa算法是使用时序差分方法来解决控制(优化)问题的一种算法。如下图所示,Sarsa的名字拼写是有意义的。S表示的是状态,A表示的是基于某个策略agent在状态S下所做出的动作。S´表示的是环境接受到动作A后,返回的下一个状态,R是环境接受到动作后放回的奖励值。A´表示的是agent接受S´后的下一个动作。这就是一个5元组(S,A,R,S´,A´),sarsa的名字就是这样来的。这里需要注意的是,个体在状态 S’ 时遵循当前的行为策略产生一个新行为 A’,个体此时并不执行该行为,而是通过动作价值函数(什么是动作价值函数)得到后一个状态行为对 (S’,A’) 的价值,利用这个新的价值和即时奖励 R 来更新前一个状态行为对 (S,A) 的价值。

Sarsa 算法在单个状态序列内的每一个时间步,在状态 S 下采取一个行为 A 到达状态 S’ 后都要更新状态行为对 (S,A) 的价值 Q(S,A)。这一过程同样使用 ϵ-贪婪策略来更新策略。这里需要注意的是这里的A’动作,不仅仅是用来更新,而是真正的下一步需要执行的动作。


4.Saras(λ)算法
这个算法的名字相比于Saras算法就多了个λ符号。这个其实就是步数的意思。如下图图4.1所示,这里的 qt 对应的是一个状态行为对 (st, at),表示的是在某个状态下采取某个行为的价值大小,也就是动做价值函数。如果 n = 1,则表示状态行为对 (st, at) 的 Q 价值可以用两部分表示,一部分是离开状态 st得到的即时奖励 Rt+1,即时奖励只与状态有关,与该状态下采取的行为无关;另一部分是考虑了衰减因子的状态行为对 (st+1, at+1) 的价值:环境给了个体一个后续状态 st+1,观察在该状态基于当前策略得到的行为 at+1 时的价值 Q(st+1, at+1)。当 n = 2 时,就向前用 2 步的即时奖励,然后再用后续的 Q(st+2, at+2) 代替;如果 n 趋向于无穷大,则表示一直用带衰减因子的即时奖计算 Q 值,直至状态序列结束。


5.Q-Learning算法
离轨策略下的时序差分控制算法的提出是强化学习早期的一个重要突破。这个突破性算法就叫做Q学习,其定义为:
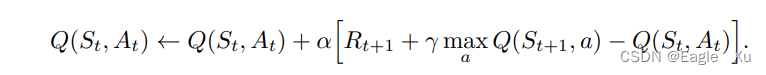
这里的maxQ指的是选取在状态St+1下所有动作中的最大Q值来参与更新,这里的动作a,只是仅仅用来更新Q(st,at),具体下一个动作选啥,现在还没有选出,不要和sarsa算法搞混了。

6.总结
对于sarsa算法和Q-learning算法,我们可以从他们的动作-状态价值函数的更新可以看出,sarsa算法在更新Q值的时候是考虑了未来下一个动作的Q值的,因为在更新Q(s,a)的时候,用到了Q(s’,a’),下一个动作已经被选出。而Q-learning没有,只是用下一个状态的最大动作的Q值来更新,但是并没有选出来执行。之后的强化学习算法应用中,我们虽然很少用到这两种算法来解决问题,但学习这两种算法对后面其他算法的理解至关重要。















 800
800











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









