






7天实现Go分布式缓存(day1)
1.分布式缓存概念
第一次请求时将一些耗时操作的结果暂存,以后遇到相同的请求,直接返回暂存的数据。我想这是大部分童鞋对于缓存的理解。在计算机系统中,缓存无处不在,比如我们访问一个网页,网页和引用的 JS/CSS 等静态文件,根据不同的策略,会缓存在浏览器本地或是 CDN 服务器,那在第二次访问的时候,就会觉得网页加载的速度快了不少;比如微博的点赞的数量,不可能每个人每次访问,都从数据库中查找所有点赞的记录再统计,数据库的操作是很耗时的,很难支持那么大的流量,所以一般点赞这类数据是缓存在 Redis 服务集群中的。
商业世界里,现金为王;架构世界里,缓存为王。
缓存中最简单的莫过于存储在内存中的键值对缓存了。说到键值对,很容易想到的是字典(dict)类型,Go 语言中称之为 map。那直接创建一个 map,每次有新数据就往 map 中插入不就好了,这不就是键值对缓存么?这样做有什么问题呢?
1)内存不够了怎么办?
那就随机删掉几条数据好了。随机删掉好呢?还是按照时间顺序好呢?或者是有没有其他更好的淘汰策略呢?不同数据的访问频率是不一样的,优先删除访问频率低的数据是不是更好呢?数据的访问频率可能随着时间变化,那优先删除最近最少访问的数据可能是一个更好的选择。我们需要实现一个合理的淘汰策略。
2)并发写入冲突了怎么办?
对缓存的访问,一般不可能是串行的。map 是没有并发保护的,应对并发的场景,修改操作(包括新增,更新和删除)需要加锁。
3)单机性能不够怎么办?
单台计算机的资源是有限的,计算、存储等都是有限的。随着业务量和访问量的增加,单台机器很容易遇到瓶颈。如果利用多台计算机的资源,并行处理提高性能就要缓存应用能够支持分布式,这称为水平扩展(scale horizontally)。与水平扩展相对应的是垂直扩展(scale vertically),即通过增加单个节点的计算、存储、带宽等,来提高系统的性能,硬件的成本和性能并非呈线性关系,大部分情况下,分布式系统是一个更优的选择。
2 关于 GeeCache
设计一个分布式缓存系统,需要考虑资源控制、淘汰策略、并发、分布式节点通信等各个方面的问题。而且,针对不同的应用场景,还需要在不同的特性之间权衡,例如,是否需要支持缓存更新?还是假定缓存在淘汰之前是不允许改变的。不同的权衡对应着不同的实现。
groupcache 是 Go 语言版的 memcached,目的是在某些特定场合替代 memcached。groupcache 的作者也是 memcached 的作者。无论是了解单机缓存还是分布式缓存,深入学习这个库的实现都是非常有意义的。
GeeCache 基本上模仿了 groupcache 的实现,为了将代码量限制在 500 行左右(groupcache 约 3000 行),裁剪了部分功能。但总体实现上,还是与 groupcache 非常接近的。支持特性有:
- 单机缓存和基于 HTTP 的分布式缓存
- 最近最少访问(Least Recently Used, LRU) 缓存策略
- 使用 Go 锁机制防止缓存击穿
- 使用一致性哈希选择节点,实现负载均衡
- 使用 protobuf 优化节点间二进制通信
- …
GeeCache 分7天实现,每天完成的部分都是可以独立运行和测试的,就像搭积木一样,每天实现的特性组合在一起就是最终的分布式缓存系统。每天的代码在 100 行左右。
3 LRU 算法实现
3.1 核心数据结构
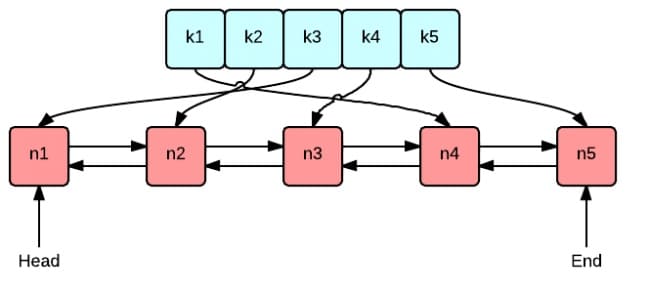
这张图很好地表示了 LRU 算法最核心的 2 个数据结构
- 绿色的是字典(map),存储键和值的映射关系。这样根据某个键(key)查找对应的值(value)的复杂是
O(1),在字典中插入一条记录的复杂度也是O(1)。 - 红色的是双向链表(double linked list)实现的队列。将所有的值放到双向链表中,这样,当访问到某个值时,将其移动到队尾的复杂度是
O(1),在队尾新增一条记录以及删除一条记录的复杂度均为O(1)。
接下来我们创建一个包含字典和双向链表的结构体类型 Cache,方便实现后续的增删查改操作。
day1-lru/geecache/lru/lru.go - github
package lru
import "container/list"
// Cache is a LRU cache. It is not safe for concurrent access.
type Cache struct {
maxBytes int64
nbytes int64
ll *list.List
cache map[string]*list.Element
// optional and executed when an entry is purged.
OnEvicted func(key string, value Value)
}
type entry struct {
key string
value Value
}
// Value use Len to count how many bytes it takes
type Value interface {
Len() int
}
- 在这里我们直接使用 Go 语言标准库实现的双向链表
list.List。 - 字典的定义是
map[string]*list.Element,键是字符串,值是双向链表中对应节点的指针。 maxBytes是允许使用的最大内存,nbytes是当前已使用的内存,OnEvicted是某条记录被移除时的回调函数,可以为 nil。- 键值对
entry是双向链表节点的数据类型,在链表中仍保存每个值对应的 key 的好处在于,淘汰队首节点时,需要用 key 从字典中删除对应的映射。 - 为了通用性,我们允许值是实现了
Value接口的任意类型,该接口只包含了一个方法Len() int,用于返回值所占用的内存大小。
方便实例化 Cache,实现 New() 函数:
// New is the Constructor of Cache
func New(maxBytes int64, onEvicted func(string, Value)) *Cache {
return &Cache{
maxBytes: maxBytes,
ll: list.New(),
cache: make(map[string]*list.Element),
OnEvicted: onEvicted,
}
}
3.2 查找功能
查找主要有 2 个步骤,第一步是从字典中找到对应的双向链表的节点,第二步,将该节点移动到队尾。
// Get look ups a key's value
func (c *Cache) Get(key string) (value Value, ok bool) {
if ele, ok := c.cache[key]; ok {
c.ll.MoveToFront(ele)
kv := ele.Value.(*entry)
return kv.value, true
}
return
}
- 如果键对应的链表节点存在,则将对应节点移动到队尾,并返回查找到的值。
c.ll.MoveToFront(ele),即将链表中的节点ele移动到队尾(双向链表作为队列,队首队尾是相对的,在这里约定 front 为队尾)
查找通过map,找到对应的list 的node,然后访问对应的Value,这里是自定义为(entry接口),然后返回entry的value即可。
3.3 删除
这里的删除,实际上是缓存淘汰。即移除最近最少访问的节点(队首)
// RemoveOldest removes the oldest item
func (c *Cache) RemoveOldest() {
ele := c.ll.Back()
if ele != nil {
c.ll.Remove(ele)
kv := ele.Value.(*entry)
delete(c.cache, kv.key)
c.nbytes -= int64(len(kv.key)) + int64(kv.value.Len())
if c.OnEvicted != nil {
c.OnEvicted(kv.key, kv.value)
}
}
}
c.ll.Back()取到队首节点,从链表中删除。delete(c.cache, kv.key),从字典中c.cache删除该节点的映射关系。- 更新当前所用的内存
c.nbytes。 - 如果回调函数
OnEvicted不为 nil,则调用回调函数。
删除就是每次删除队首的,从list 和map里删除,修改占用的内存nbytes,调用回调函数。
3.4 新增/修改
// Add adds a value to the cache.
func (c *Cache) Add(key string, value Value) {
if ele, ok := c.cache[key]; ok {
c.ll.MoveToFront(ele)
kv := ele.Value.(*entry)
c.nbytes += int64(value.Len()) - int64(kv.value.Len())
kv.value = value
} else {
ele := c.ll.PushFront(&entry{key, value})
c.cache[key] = ele
c.nbytes += int64(len(key)) + int64(value.Len())
}
for c.maxBytes != 0 && c.maxBytes < c.nbytes {
c.RemoveOldest()
}
}
- 如果键存在,则更新对应节点的值,并将该节点移到队尾。
- 不存在则是新增场景,首先队尾添加新节点
&entry{key, value}, 并字典中添加 key 和节点的映射关系。 - 更新
c.nbytes,如果超过了设定的最大值c.maxBytes,则移除最少访问的节点。
最后,为了方便测试,我们实现 Len() 用来获取添加了多少条数据。
// Len the number of cache entries
func (c *Cache) Len() int {
return c.ll.Len()
}
4.总结
查找
查找通过map,找到对应的list 的node,然后访问对应的Value,这里是自定义为(entry接口),然后返回entry的value即可。
删除
删除就是每次删除队首的,从list 和map里删除,修改占用的内存nbytes,调用回调函数。
新增/修改
新增首先判断是否判断是否map中存在,存在直接加入到链表队尾,然后修改nbytes。否则直接插入新结点到队尾。每次新增时特判是否超过设定的最大内存。















 304
304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











