







DataFrame数据的增删改
DataFrame查询操作参见:https://blog.csdn.net/weixin_45760274/article/details/123448770
DataFrame增加数据
构建数据:
import pandas as pd
import numpy as np
# 创建DataFrame
df = pd.DataFrame(
data=[
['zs', 18, 1],
['ls', 19, 1],
['ww', 17, 2]
],
index=['stu0', 'stu1', 'stu2'],
columns=['name', 'age', 'group']
)
print('df:\n', df)

增加一行
# 行的方向上增加----> 增加一行----> 给数据集添加一个新的数据对象
df.loc['stu3', :] = ['zl', 20, 2]
# 将 age 和 group 的类型修改为 int64
df.loc[:, ['age', 'group']] = df.loc[:, ['age', 'group']].astype(np.int64)
print('df:\n', df)
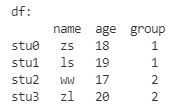
增加列
列的方向上增加----> 增加一列----> 给每个数据对象增加一个新的属性
df.loc[:, 'next_year_age'] = 20
print('df:\n', df)
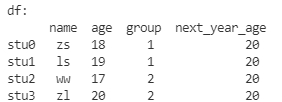
如果直接这么增加,会导致增加的这一列值完全一样。那么在分析数据对象的不同点时,那么该列将无法区分数据对象的不同点! 如果这么增加列只能是用来
占位。
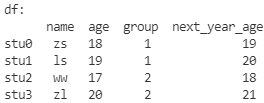
根据原有数据增加列
一般情况下的增加是通过对现有属性的计算、操作、提取等得到新的属性。
df.loc[:, 'next_year_age'] = df['age'] + 1
print('df:\n', df)
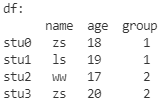
DataFrame修改数据
原始数据如下:
修改单个数据
取出数据后直接赋值(一般用不到)
df["age"]["stu0"] = 20
print('df:\n', df)

修改一列数据
直接修改(不建议),同样会导致增加的这一列值完全一样。
df['age'] = 20
print('df:\n', df)
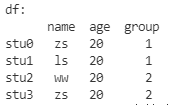
一般情况下的修改是满足一定的条件才进行修改!
# 将年龄为奇数的同学的 小组 设置为 3!
msk = df['age'] % 2 != 0
print('msk:\n', msk)
df.loc[msk, 'group'] = 3
print('df:\n', df)
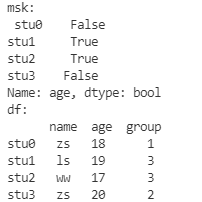
# 将 zs 同学的 年龄设置为 21
msk = df['name'] == 'zs'
df.loc[msk, 'age'] = 21
print('df:\n', df)
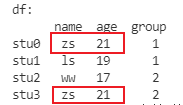
DataFrame删除数据
原始数据如下:
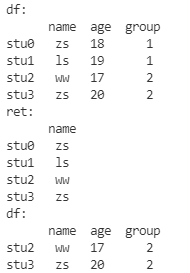
直接删除指定的行 或 列
ret = df.drop(
labels=['group', 'age'], # 要删除的行或者列的名称列表
axis=1, # 如果要删除的是列 --那么axis=1,如果要删除的是行,那么axis = 0
inplace=False, # 如果为True,则直接删除,对原df进行操作; 如果为False,那么返回一个结果,不会对原df操作!
)
print('df:\n', df)
print('ret:\n', ret)
df.drop(
labels=['stu0', 'stu1'],
axis=0,
inplace=True
)
print('df:\n', df)
根据条件删除行 或 列
一般情况下的删除很少去删除某列属性,一般情况下都是删除
指定条件下的数据对象!
# 删除 group为 1即 1组的学员
msk = df['group'] == 1
print('msk:\n', msk)
print("*"*20)
# 获取满足条件的索引
drop_labels = df.loc[msk, :].index
print('drop_labels:\n', drop_labels)
print("*"*20)
# 删除
df.drop(
labels=drop_labels,
axis=0,
inplace=True
)
print('df:\n', df)

又或者反过来:
保留不满足条件的数据对象
# 要删除 1组的学员---->理解为: 要保留 非1组的学员
msk = df['group'] != 1
# 取出非1组的学员
df = df.loc[msk, :]
print('df:\n', df)
















 4160
4160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











