【Python】科研代码学习:十 evaluate
【HF官网-Doc-Evaluate:API】 Evaluate 是 HF 提供的便捷的库,方便输入 (模型,数据集,指标) 三元组就能快速得到该指标来。transformers / keras / scikit-learn 等库配合使用【安装】anaconda 环境,要求 python>3.7 pip install evaluate 直接安装即可github repo 的话: git clone https://github.com/huggingface/evaluate.git
cd evaluate
pip install -e .
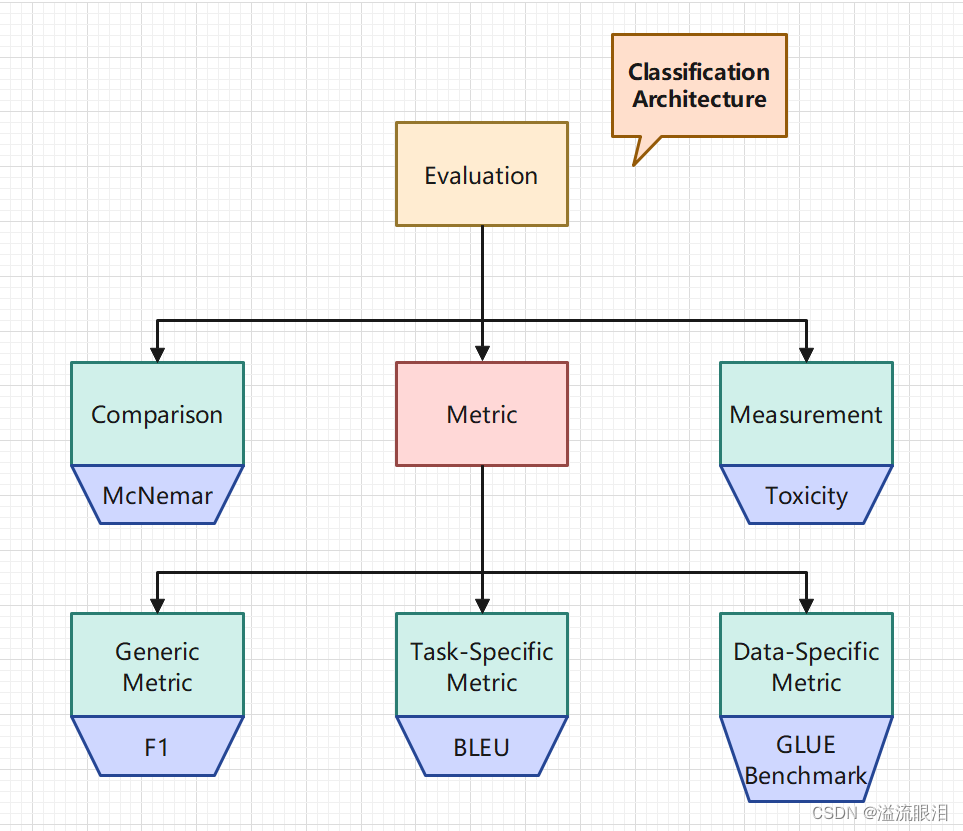
这是一个前置知识Metric(指标)【HF官网-metric列表】 :使用一个指标计算模型的表现,一般需要使用一些真值标签。如列表中所示,常见的有 ROUGE / BLEU / Perplexity / BERT Score / Accuracy / F1 / Precision / Recall / MSE / MASEComparison(对照):比较两个模型之间的表现Measurement(测量):模型与数据集都很重要,一般都是使用特定的数据集进行评估。 对于 Metric (指标),又有三个分类:Generic metric(通用指标):比如 precision, accuracy 等,在各种数据集下都可以直接用Task-specific metric(特定任务指标):与任务相关,比如机器翻译常用的 BLEU / ROUGE,以及命名实体检测常用的 seqevalData-specific metric(特定数据集指标):用某个特定的 benchmark 来评估模型的表现,比如 GLUE benchmark 等。 画了张分类图 第一步:加载一个指标module_type,特别是有重名的时候。 import evaluate
accuracy = evaluate. load( "accuracy" )
word_length = evaluate. load( "word_length" , module_type= "measurement" )
第二步(可选):展示指标的额外信息description 查看模组介绍,citation 获取 BibTex,features 获取输入格式 accuracy = evaluate. load( "accuracy" )
accuracy. description
accuracy. citation
accuracy. features
第三步:计算compute 方法计算。输入格式记得查看上面的 features 打印查看。All-in-one),一种是增量式(Incremental) 一口气式: accuracy. compute( references= [ 0 , 1 , 0 , 1 ] , predictions= [ 1 , 0 , 0 , 1 ] )
for ref, pred in zip ( [ 0 , 1 , 0 , 1 ] , [ 1 , 0 , 0 , 1 ] ) :
accuracy. add( references= ref, predictions= pred)
accuracy. compute( )
for refs, preds in zip ( [ [ 0 , 1 ] , [ 0 , 1 ] ] , [ [ 1 , 0 ] , [ 0 , 1 ] ] ) :
accuracy. add_batch( references= refs, predictions= preds)
accuracy. compute( )
增量式,在调用模型时很常用,因为一般数据是一条一条跑出来的,除非提前存好。 for model_inputs, gold_standards in evaluation_dataset:
predictions = model( model_inputs)
metric. add_batch( references= gold_standards, predictions= predictions)
metric. compute( )
第三步(可选):复合多种指标,使用 combine 方法 clf_metrics = evaluate. combine( [ "accuracy" , "f1" , "precision" , "recall" ] )
clf_metrics. compute( predictions= [ 0 , 1 , 0 ] , references= [ 0 , 1 , 1 ] )
第三步(可选):使用 Evaluator ,方便 (模型,数据集,指标) 三元组评估,在后文讲 第四步(可选):使用官方提供的一个可视化,但看了下只支持 ComplexRadar 和 radar_plot 类,就不赘述了。 metric对于 Generic metric,可以直接在这个 【HF官网-metric列表】 里面查看,根据里面的 card 指引操作, 对于 Task-specific metric,首先在 【HF官网-Task索引】 里面找到自己在做的任务,比如 QA 吧 进入后,在右下角可以找到 Datasets for QA 以及 Metrics for QA,看到这里有 exact-match & F1 对于 Dataset-specific metric,我们在 HF 寻找相关的 dataset 后,在 Dataset Preview 或者 dataset card 中都可以看到具体的操作方式。 Evaluator使用 Evaluator,可以方便评估 (模型,数据集,指标) 三元组 "text-classification" : will use the TextClassificationEvaluator.
"token-classification" : will use the TokenClassificationEvaluator.
"question-answering" : will use the QuestionAnsweringEvaluator.
"image-classification" : will use the ImageClassificationEvaluator.
"text-generation" : will use the TextGenerationEvaluator.
"text2text-generation" : will use the Text2TextGenerationEvaluator.
"summarization" : will use the SummarizationEvaluator.
"translation" : will use the TranslationEvaluator.
"automatic-speech-recognition" : will use the AutomaticSpeechRecognitionEvaluator.
"audio-classification" : will use the AudioClassificationEvaluator.
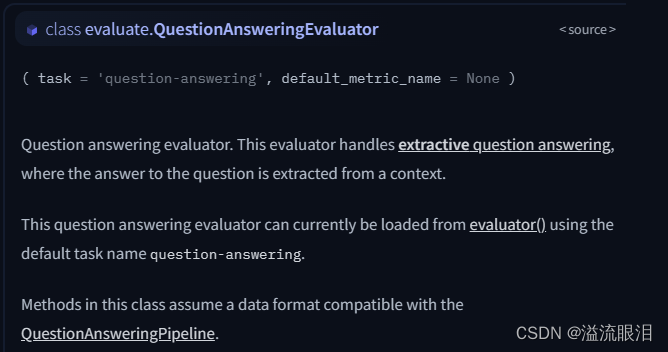
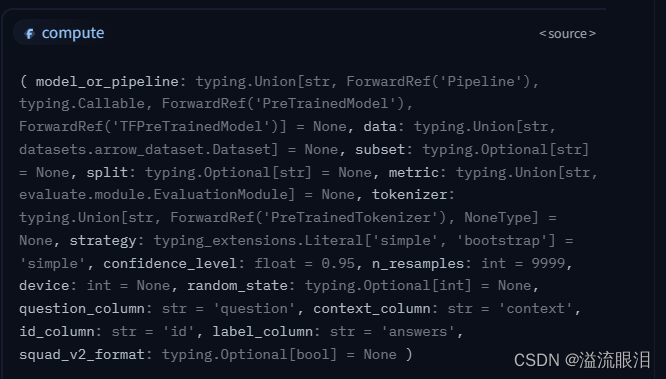
可以看到,使用不同的任务,就需要使用不同的 Evaluator 类。QuestionAnsweringEvaluator 类中查询使用方法 可以从源码或者API中看到,QuestionAnsweringEvaluator 类其实就是继承了 Evaluator 类,在初始化中设置了 task='question-answering' 并且重载了 compute 方法,这个肯定是唯一重要的方法,稍微介绍一下参数model_or_pipeline :也就是说,我们可以提供 PretrainedModel,也可以提供 Pipelinedata:可以是 Dataset 类型,也可以提供字符串,表示数据集的名字(貌似这里是不支持提供本地路径的?)subset :如果数据集有子数据集的话,在这里提供它的名字split(str):怎么划分,比如可以提供 split="validation[:2]"metric (str or EvaluationModule):指标名tokenizer:如果我们提供的是 model 而不是 pipeline 的话,就需要提供 tokenizer 了strategy :如果设置成 "bootstrap" 的话,就可以设置 confidence_level 置信区间;否则默认为 "simple"device :显卡号。 例子: from evaluate import evaluator
from datasets import load_dataset
task_evaluator = evaluator( "question-answering" )
data = load_dataset( "squad" , split= "validation[:2]" )
results = task_evaluator. compute(
model_or_pipeline= "sshleifer/tiny-distilbert-base-cased-distilled-squad" ,
data= data,
metric= "squad" ,
)
transformers.trainer 配合使用前面的功能感觉还是有点鸡肋?在训练时和 trainer 配合使用,不就可以在训练的时候显示我需要的指标了嘛 看下面的例子metric = evaluate.load("accuracy"),表示要计算 accucompute_metrics,对于输入的预测 eval_pred,我们获取它的 logits, labels, predictions 值,然后用 metric.compute 方法,计算出指标。trainer 我们直接提供给它 compute_metrics 即可。 from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer
import numpy as np
import evaluate
dataset = load_dataset( "yelp_review_full" )
tokenizer = AutoTokenizer. from_pretrained( "bert-base-cased" )
def tokenize_function ( examples) :
return tokenizer( examples[ "text" ] , padding= "max_length" , truncation= True )
tokenized_datasets = dataset. map ( tokenize_function, batched= True )
small_train_dataset = tokenized_datasets[ "train" ] . shuffle( seed= 42 ) . select( range ( 200 ) )
small_eval_dataset = tokenized_datasets[ "test" ] . shuffle( seed= 42 ) . select( range ( 200 ) )
metric = evaluate. load( "accuracy" )
def compute_metrics ( eval_pred) :
logits, labels = eval_pred
predictions = np. argmax( logits, axis= - 1 )
return metric. compute( predictions= predictions, references= labels)
model = AutoModelForSequenceClassification. from_pretrained( "bert-base-cased" , num_labels= 5 )
training_args = TrainingArguments( output_dir= "test_trainer" , evaluation_strategy= "epoch" )
trainer = Trainer(
model= model,
args= training_args,
train_dataset= small_train_dataset,
eval_dataset= small_eval_dataset,
compute_metrics= compute_metrics,
)
trainer. train( )
看了上面这么多代码,感觉只能单卡跑啊?感觉意义突然不大了起来。HF 支持使用 accelerate 来多卡运行。在 trainer 里只要设置单卡的 batch 即可。GPU Inference 。deepspeed,HF 也是封装的比较好了。 虽然能中间显示指标了,我怎么看到呢?wandb 了。 还有微调常用的内容,PEFT,optimization(optimizer, scheduler)
























 2483
2483











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









