【Python】科研代码学习:十六 Model与网络架构 的代码细节:Llama 为例(v4.28.0)
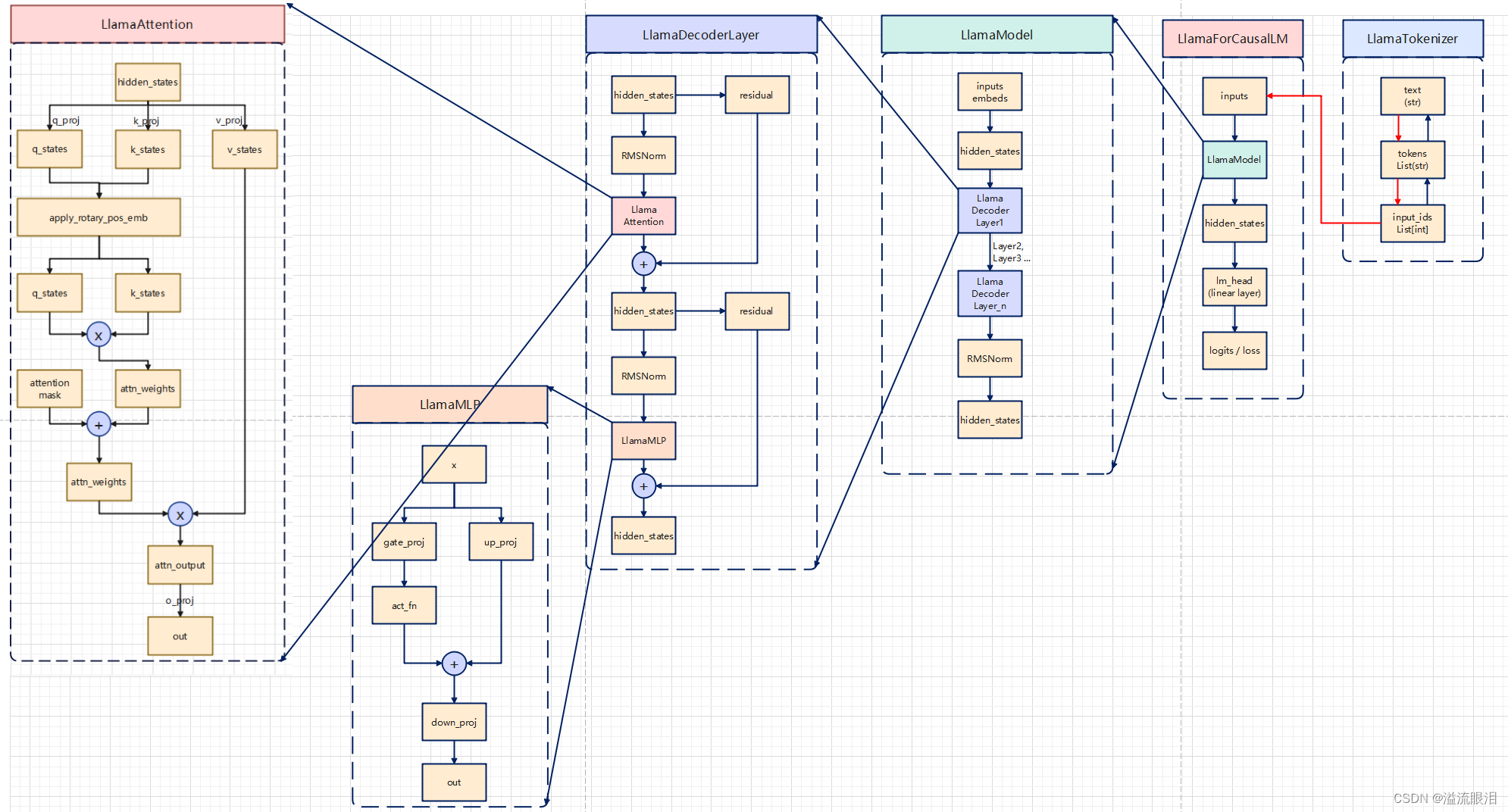
【Github:Transformers/llama】 modeling_llama.py 这个重要脚本了※ 本文使用的版本为 v4.28.0,不同版本的源码会有所不同。 整理完的架构图如下: 代码一共八百多行,一口气看完不现实,我们按照功能分区,一块一块了解math, typingtorch 实现的网络架构,而不是 tensorflow / Flax... 表示的是上级的包中的代码,也就是说这些代码都是这个 Github 中自己实现的代码了activations 肯定是设置了激活函数modeling_outputs 设置了模型的输出utils 字样的都是功能代码,不用大在意,就发现他用了 PreTrainedModel, logging 等类LlamaConfig 如果想很细致的学习的话,做包依赖图有时候可以帮助理清很多代码之间的逻辑。 """ PyTorch LLaMA model."""
import math
from typing import List, Optional, Tuple, Union
import torch
import torch. utils. checkpoint
from torch import nn
from torch. nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
from . . . activations import ACT2FN
from . . . modeling_outputs import BaseModelOutputWithPast, CausalLMOutputWithPast, SequenceClassifierOutputWithPast
from . . . modeling_utils import PreTrainedModel
from . . . utils import add_start_docstrings, add_start_docstrings_to_model_forward, logging, replace_return_docstrings
from . configuration_llama import LlamaConfig
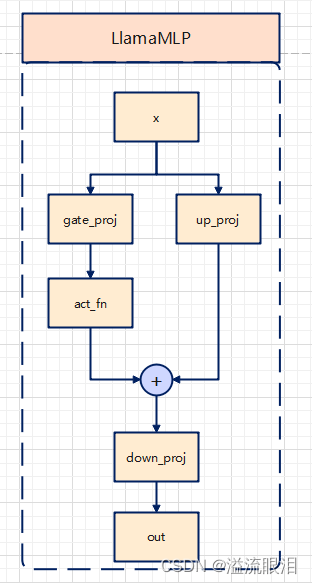
LlamaRMSNorm:改进的 层正则化LlamaRotaryEmbedding:旋转式位置编码LlamaMLP:多层感知机(人工神经网络)直接上源码,这个比较短MLP 其实就是三个线性层加上一个 ACT2FN 的激活函数forward 前向的话,先计算 gate_proj(x) 然后做一次激活函数,然后与 up_proj(x) 相乘,最后计算 down_proj class LlamaMLP ( nn. Module) :
def __init__ (
self,
hidden_size: int ,
intermediate_size: int ,
hidden_act: str ,
) :
super ( ) . __init__( )
self. gate_proj = nn. Linear( hidden_size, intermediate_size, bias= False )
self. down_proj = nn. Linear( intermediate_size, hidden_size, bias= False )
self. up_proj = nn. Linear( hidden_size, intermediate_size, bias= False )
self. act_fn = ACT2FN[ hidden_act]
def forward ( self, x) :
return self. down_proj( self. act_fn( self. gate_proj( x) ) * self. up_proj( x) )
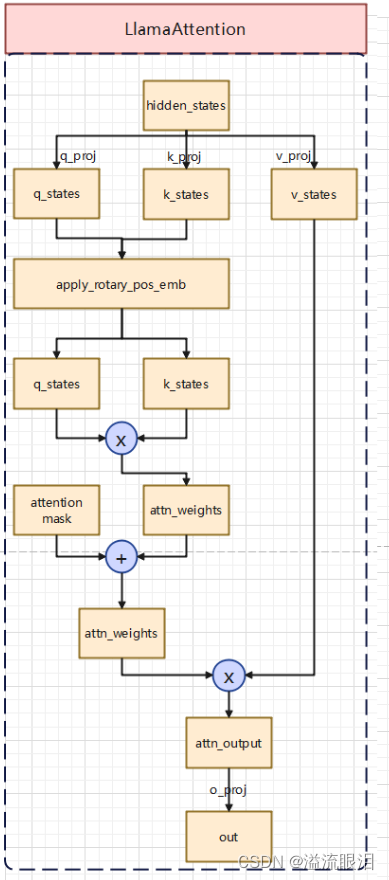
LlamaAttention:多头注意力层主要内容是从 Attention is All you need 这篇paper来的q_proj, k_proj, v_proj, o_proj 这几个线性层rotary_emb 这个旋转位置编码工具 def __init__ ( self, config: LlamaConfig) :
super ( ) . __init__( )
self. config = config
self. hidden_size = config. hidden_size
self. num_heads = config. num_attention_heads
self. head_dim = self. hidden_size // self. num_heads
self. max_position_embeddings = config. max_position_embeddings
if ( self. head_dim * self. num_heads) != self. hidden_size:
raise ValueError(
f"hidden_size must be divisible by num_heads (got `hidden_size`: { self. hidden_size} " f" and `num_heads`: { self. num_heads} )." )
self. q_proj = nn. Linear( self. hidden_size, self. num_heads * self. head_dim, bias= False )
self. k_proj = nn. Linear( self. hidden_size, self. num_heads * self. head_dim, bias= False )
self. v_proj = nn. Linear( self. hidden_size, self. num_heads * self. head_dim, bias= False )
self. o_proj = nn. Linear( self. num_heads * self. head_dim, self. hidden_size, bias= False )
self. rotary_emb = LlamaRotaryEmbedding( self. head_dim, max_position_embeddings= self. max_position_embeddings)
接下来,我们看一下 forward 的逻辑。hidden_statesq_proj, k_proj, v_proj 三个层计算后,得到 q_states, k_states, v_statesq_states, k_states 进行旋转位置编码q_states * k_states(矩阵乘法),得到 attn_weightsattn_weights 与 attention_mask 相加,做一下 softmax 操作,然后与 v_states 矩阵乘得到 attn_outputattn_output 进入 o_proj 后输出结果即为最终的 out 由于它是序列化数据,对于当前位置的 q_states, k_states 我们计算后,可以把它存储到 past_key_value=tuple( list[k_states], list[v_states]) 里面,方便后续直接调用。 def forward (
self,
hidden_states: torch. Tensor,
attention_mask: Optional[ torch. Tensor] = None ,
position_ids: Optional[ torch. LongTensor] = None ,
past_key_value: Optional[ Tuple[ torch. Tensor] ] = None ,
output_attentions: bool = False ,
use_cache: bool = False ,
) - > Tuple[ torch. Tensor, Optional[ torch. Tensor] , Optional[ Tuple[ torch. Tensor] ] ] :
bsz, q_len, _ = hidden_states. size( )
query_states = self. q_proj( hidden_states) . view( bsz, q_len, self. num_heads, self. head_dim) . transpose( 1 , 2 )
key_states = self. k_proj( hidden_states) . view( bsz, q_len, self. num_heads, self. head_dim) . transpose( 1 , 2 )
value_states = self. v_proj( hidden_states) . view( bsz, q_len, self. num_heads, self. head_dim) . transpose( 1 , 2 )
kv_seq_len = key_states. shape[ - 2 ]
if past_key_value is not None :
kv_seq_len += past_key_value[ 0 ] . shape[ - 2 ]
cos, sin = self. rotary_emb( value_states, seq_len= kv_seq_len)
query_states, key_states = apply_rotary_pos_emb( query_states, key_states, cos, sin, position_ids)
if past_key_value is not None :
key_states = torch. cat( [ past_key_value[ 0 ] , key_states] , dim= 2 )
value_states = torch. cat( [ past_key_value[ 1 ] , value_states] , dim= 2 )
past_key_value = ( key_states, value_states) if use_cache else None
attn_weights = torch. matmul( query_states, key_states. transpose( 2 , 3 ) ) / math. sqrt( self. head_dim)
if attn_weights. size( ) != ( bsz, self. num_heads, q_len, kv_seq_len) :
raise ValueError(
f"Attention weights should be of size { ( bsz * self. num_heads, q_len, kv_seq_len) } , but is" f" { attn_weights. size( ) } " )
if attention_mask is not None :
if attention_mask. size( ) != ( bsz, 1 , q_len, kv_seq_len) :
raise ValueError(
f"Attention mask should be of size { ( bsz, 1 , q_len, kv_seq_len) } , but is { attention_mask. size( ) } " )
attn_weights = attn_weights + attention_mask
attn_weights = torch. max ( attn_weights, torch. tensor( torch. finfo( attn_weights. dtype) . min ) )
attn_weights = nn. functional. softmax( attn_weights, dim= - 1 , dtype= torch. float32) . to( query_states. dtype)
attn_output = torch. matmul( attn_weights, value_states)
if attn_output. size( ) != ( bsz, self. num_heads, q_len, self. head_dim) :
raise ValueError(
f"`attn_output` should be of size { ( bsz, self. num_heads, q_len, self. head_dim) } , but is" f" { attn_output. size( ) } " )
attn_output = attn_output. transpose( 1 , 2 )
attn_output = attn_output. reshape( bsz, q_len, self. hidden_size)
attn_output = self. o_proj( attn_output)
if not output_attentions:
attn_weights = None
return attn_output, attn_weights, past_key_value
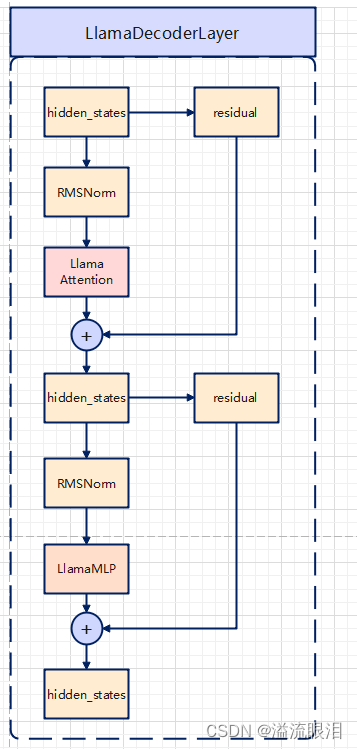
LlamaDecoderLayer:解码层llama 等模型,都是主要利用了 transformer 架构中的 Decoder 解码层为主题架构LlamaAttention, LlamaMLP, LlamaRMSNorm 等主要来看前向传播的逻辑hidden_states 张量,并且取了它一个副本,叫做 residual 剩余网络hidden_states 经过一个 LlamaRMSNormhidden_states 经过一个 LlamaAttention 层hidden_states 与 residual 剩余网络相加residual 剩余网络为目前的 hidden_stateshidden_states 再经过一个 LlamaRMSNormhidden_states 再经过一个全连接层 LlamaMLPhidden_states 与 residual 剩余网络相加,作为最终输出 class LlamaDecoderLayer ( nn. Module) :
def __init__ ( self, config: LlamaConfig) :
super ( ) . __init__( )
self. hidden_size = config. hidden_size
self. self_attn = LlamaAttention( config= config)
self. mlp = LlamaMLP(
hidden_size= self. hidden_size,
intermediate_size= config. intermediate_size,
hidden_act= config. hidden_act,
)
self. input_layernorm = LlamaRMSNorm( config. hidden_size, eps= config. rms_norm_eps)
self. post_attention_layernorm = LlamaRMSNorm( config. hidden_size, eps= config. rms_norm_eps)
def forward (
self,
hidden_states: torch. Tensor,
attention_mask: Optional[ torch. Tensor] = None ,
position_ids: Optional[ torch. LongTensor] = None ,
past_key_value: Optional[ Tuple[ torch. Tensor] ] = None ,
output_attentions: Optional[ bool ] = False ,
use_cache: Optional[ bool ] = False ,
) - > Tuple[ torch. FloatTensor, Optional[ Tuple[ torch. FloatTensor, torch. FloatTensor] ] ] :
"""
Args:
hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
(see `past_key_values`).
past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
"""
residual = hidden_states
hidden_states = self. input_layernorm( hidden_states)
hidden_states, self_attn_weights, present_key_value = self. self_attn(
hidden_states= hidden_states,
attention_mask= attention_mask,
position_ids= position_ids,
past_key_value= past_key_value,
output_attentions= output_attentions,
use_cache= use_cache,
)
hidden_states = residual + hidden_states
residual = hidden_states
hidden_states = self. post_attention_layernorm( hidden_states)
hidden_states = self. mlp( hidden_states)
hidden_states = residual + hidden_states
outputs = ( hidden_states, )
if output_attentions:
outputs += ( self_attn_weights, )
if use_cache:
outputs += ( present_key_value, )
return outputs
LlamaPreTrainedModel:一个 PretrainedModel 的简单封装接下来,定义了一个 LlamaPreTrainedModel,它继承了 PretrainedModelLlamaConfig 和其他一些配置参数_init_weights 初始化权重方法_set_gradient_checkpointing 设置梯度中继点方法 class LlamaPreTrainedModel ( PreTrainedModel) :
config_class = LlamaConfig
base_model_prefix = "model"
supports_gradient_checkpointing = True
_no_split_modules = [ "LlamaDecoderLayer" ]
_keys_to_ignore_on_load_unexpected = [ r"decoder\.version" ]
def _init_weights ( self, module) :
std = self. config. initializer_range
if isinstance ( module, nn. Linear) :
module. weight. data. normal_( mean= 0.0 , std= std)
if module. bias is not None :
module. bias. data. zero_( )
elif isinstance ( module, nn. Embedding) :
module. weight. data. normal_( mean= 0.0 , std= std)
if module. padding_idx is not None :
module. weight. data[ module. padding_idx] . zero_( )
def _set_gradient_checkpointing ( self, module, value= False ) :
if isinstance ( module, LlamaModel) :
module. gradient_checkpointing = value
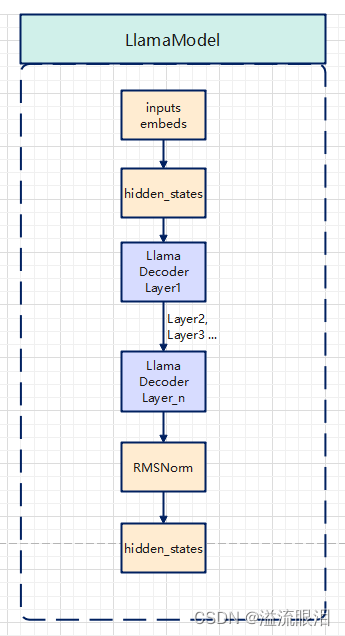
LlamaModel:Llama模型的本体LlamaModel 是继承了 LlamaPreTrainedModel,并提供了其他网络参数和网络架构等成员和方法。vocab_size(从 config 中获取的)embed_tokens ,即输入的嵌入向量(即已经经过 tokenizer 后的产出)layers 中间层nrom 也是 RMSNorm 正则化层继续看前向传播的逻辑hidden_states 为输入的 inputs_embedsLlamaDecoderLayer,一共进入了 num_hidden_layers 个这样的解码器层hidden_states 经过了一次 RMSNorm 正则化层output_hidden_states = True,那么将 all_hidden_states 加上最后一个 hidden_statesreturn_dict 的值,选择返回字典,或者返回一个 BaseModelOutputWithPastlast_hidden_state(最后隐藏状态),past_key_values(缓存机制,保存最后层的一些输出),hidden_states(全部的隐藏状态),attentions (全部的注意力状态) class LlamaModel ( LlamaPreTrainedModel) :
"""
Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`LlamaDecoderLayer`]
Args:
config: LlamaConfig
"""
def __init__ ( self, config: LlamaConfig) :
super ( ) . __init__( config)
self. padding_idx = config. pad_token_id
self. vocab_size = config. vocab_size
self. embed_tokens = nn. Embedding( config. vocab_size, config. hidden_size, self. padding_idx)
self. layers = nn. ModuleList( [ LlamaDecoderLayer( config) for _ in range ( config. num_hidden_layers) ] )
self. norm = LlamaRMSNorm( config. hidden_size, eps= config. rms_norm_eps)
self. gradient_checkpointing = False
self. post_init( )
def get_input_embeddings ( self) :
return self. embed_tokens
def set_input_embeddings ( self, value) :
self. embed_tokens = value
def _prepare_decoder_attention_mask ( self, attention_mask, input_shape, inputs_embeds, past_key_values_length) :
combined_attention_mask = None
if input_shape[ - 1 ] > 1 :
combined_attention_mask = _make_causal_mask(
input_shape,
inputs_embeds. dtype,
device= inputs_embeds. device,
past_key_values_length= past_key_values_length,
)
if attention_mask is not None :
expanded_attn_mask = _expand_mask( attention_mask, inputs_embeds. dtype, tgt_len= input_shape[ - 1 ] ) . to(
inputs_embeds. device
)
combined_attention_mask = (
expanded_attn_mask if combined_attention_mask is None else expanded_attn_mask + combined_attention_mask
)
return combined_attention_mask
@add_start_docstrings_to_model_forward ( LLAMA_INPUTS_DOCSTRING)
def forward (
self,
input_ids: torch. LongTensor = None ,
attention_mask: Optional[ torch. Tensor] = None ,
position_ids: Optional[ torch. LongTensor] = None ,
past_key_values: Optional[ List[ torch. FloatTensor] ] = None ,
inputs_embeds: Optional[ torch. FloatTensor] = None ,
use_cache: Optional[ bool ] = None ,
output_attentions: Optional[ bool ] = None ,
output_hidden_states: Optional[ bool ] = None ,
return_dict: Optional[ bool ] = None ,
) - > Union[ Tuple, BaseModelOutputWithPast] :
output_attentions = output_attentions if output_attentions is not None else self. config. output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self. config. output_hidden_states
)
use_cache = use_cache if use_cache is not None else self. config. use_cache
return_dict = return_dict if return_dict is not None else self. config. use_return_dict
if input_ids is not None and inputs_embeds is not None :
raise ValueError( "You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time" )
elif input_ids is not None :
batch_size, seq_length = input_ids. shape
elif inputs_embeds is not None :
batch_size, seq_length, _ = inputs_embeds. shape
else :
raise ValueError( "You have to specify either decoder_input_ids or decoder_inputs_embeds" )
seq_length_with_past = seq_length
past_key_values_length = 0
if past_key_values is not None :
past_key_values_length = past_key_values[ 0 ] [ 0 ] . shape[ 2 ]
seq_length_with_past = seq_length_with_past + past_key_values_length
if position_ids is None :
device = input_ids. device if input_ids is not None else inputs_embeds. device
position_ids = torch. arange(
past_key_values_length, seq_length + past_key_values_length, dtype= torch. long , device= device
)
position_ids = position_ids. unsqueeze( 0 ) . view( - 1 , seq_length)
else :
position_ids = position_ids. view( - 1 , seq_length) . long ( )
if inputs_embeds is None :
inputs_embeds = self. embed_tokens( input_ids)
if attention_mask is None :
attention_mask = torch. ones(
( batch_size, seq_length_with_past) , dtype= torch. bool , device= inputs_embeds. device
)
attention_mask = self. _prepare_decoder_attention_mask(
attention_mask, ( batch_size, seq_length) , inputs_embeds, past_key_values_length
)
hidden_states = inputs_embeds
if self. gradient_checkpointing and self. training:
if use_cache:
logger. warning_once(
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
)
use_cache = False
all_hidden_states = ( ) if output_hidden_states else None
all_self_attns = ( ) if output_attentions else None
next_decoder_cache = ( ) if use_cache else None
for idx, decoder_layer in enumerate ( self. layers) :
if output_hidden_states:
all_hidden_states += ( hidden_states, )
past_key_value = past_key_values[ idx] if past_key_values is not None else None
if self. gradient_checkpointing and self. training:
def create_custom_forward ( module) :
def custom_forward ( * inputs) :
return module( * inputs, output_attentions, None )
return custom_forward
layer_outputs = torch. utils. checkpoint. checkpoint(
create_custom_forward( decoder_layer) ,
hidden_states,
attention_mask,
position_ids,
None ,
)
else :
layer_outputs = decoder_layer(
hidden_states,
attention_mask= attention_mask,
position_ids= position_ids,
past_key_value= past_key_value,
output_attentions= output_attentions,
use_cache= use_cache,
)
hidden_states = layer_outputs[ 0 ]
if use_cache:
next_decoder_cache += ( layer_outputs[ 2 if output_attentions else 1 ] , )
if output_attentions:
all_self_attns += ( layer_outputs[ 1 ] , )
hidden_states = self. norm( hidden_states)
if output_hidden_states:
all_hidden_states += ( hidden_states, )
next_cache = next_decoder_cache if use_cache else None
if not return_dict:
return tuple ( v for v in [ hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None )
return BaseModelOutputWithPast(
last_hidden_state= hidden_states,
past_key_values= next_cache,
hidden_states= all_hidden_states,
attentions= all_self_attns,
)
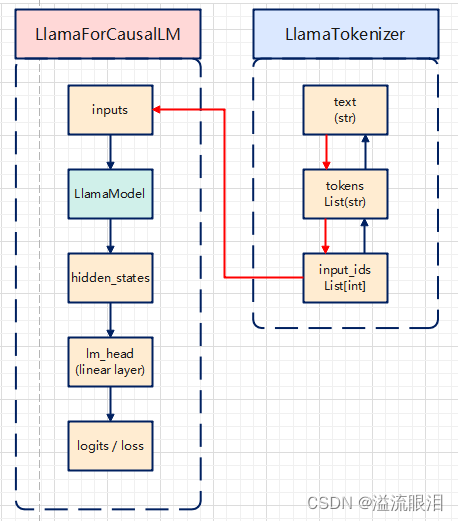
LlamaForCausalLM:给 CLM 用的 LlamaModelLlamaForCausalLM 也是继承自 LlamaPreTrainedModel 的,只不过是为了 CLM 的特有任务self.model = LlamaModel(config) ,它主要成员还是一个 LlamaModelself.lm_head = nn.Linear在看一下它自己的前向传播方法LlamaModel 的网络,输出为 outputs,然后最后的隐藏状态即为 hidden_states = outputs[0]hidden_states 经过这个 lm_head 的线性层,输出为 logitsloss,使用的方法为交叉熵损失 CrossEntropyLossloss, logits, past_key_values, hidden_states, attentions class LlamaForCausalLM ( LlamaPreTrainedModel) :
def __init__ ( self, config) :
super ( ) . __init__( config)
self. model = LlamaModel( config)
self. lm_head = nn. Linear( config. hidden_size, config. vocab_size, bias= False )
self. post_init( )
def get_input_embeddings ( self) :
return self. model. embed_tokens
def set_input_embeddings ( self, value) :
self. model. embed_tokens = value
def get_output_embeddings ( self) :
return self. lm_head
def set_output_embeddings ( self, new_embeddings) :
self. lm_head = new_embeddings
def set_decoder ( self, decoder) :
self. model = decoder
def get_decoder ( self) :
return self. model
@add_start_docstrings_to_model_forward ( LLAMA_INPUTS_DOCSTRING)
@replace_return_docstrings ( output_type= CausalLMOutputWithPast, config_class= _CONFIG_FOR_DOC)
def forward (
self,
input_ids: torch. LongTensor = None ,
attention_mask: Optional[ torch. Tensor] = None ,
position_ids: Optional[ torch. LongTensor] = None ,
past_key_values: Optional[ List[ torch. FloatTensor] ] = None ,
inputs_embeds: Optional[ torch. FloatTensor] = None ,
labels: Optional[ torch. LongTensor] = None ,
use_cache: Optional[ bool ] = None ,
output_attentions: Optional[ bool ] = None ,
output_hidden_states: Optional[ bool ] = None ,
return_dict: Optional[ bool ] = None ,
) - > Union[ Tuple, CausalLMOutputWithPast] :
r"""
Args:
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
(masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
Returns:
Example:
```python
>>> from transformers import AutoTokenizer, LlamaForCausalLM
>>> model = LlamaForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
>>> tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
>>> prompt = "Hey, are you consciours? Can you talk to me?"
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> # Generate
>>> generate_ids = model.generate(inputs.input_ids, max_length=30)
>>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
"Hey, are you consciours? Can you talk to me?\nI'm not consciours, but I can talk to you."
```"""
output_attentions = output_attentions if output_attentions is not None else self. config. output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self. config. output_hidden_states
)
return_dict = return_dict if return_dict is not None else self. config. use_return_dict
outputs = self. model(
input_ids= input_ids,
attention_mask= attention_mask,
position_ids= position_ids,
past_key_values= past_key_values,
inputs_embeds= inputs_embeds,
use_cache= use_cache,
output_attentions= output_attentions,
output_hidden_states= output_hidden_states,
return_dict= return_dict,
)
hidden_states = outputs[ 0 ]
logits = self. lm_head( hidden_states)
loss = None
if labels is not None :
shift_logits = logits[ . . . , : - 1 , : ] . contiguous( )
shift_labels = labels[ . . . , 1 : ] . contiguous( )
loss_fct = CrossEntropyLoss( )
shift_logits = shift_logits. view( - 1 , self. config. vocab_size)
shift_labels = shift_labels. view( - 1 )
shift_labels = shift_labels. to( shift_logits. device)
loss = loss_fct( shift_logits, shift_labels)
if not return_dict:
output = ( logits, ) + outputs[ 1 : ]
return ( loss, ) + output if loss is not None else output
return CausalLMOutputWithPast(
loss= loss,
logits= logits,
past_key_values= outputs. past_key_values,
hidden_states= outputs. hidden_states,
attentions= outputs. attentions,
)
def prepare_inputs_for_generation (
self, input_ids, past_key_values= None , attention_mask= None , inputs_embeds= None , ** kwargs
) :
if past_key_values:
input_ids = input_ids[ : , - 1 : ]
position_ids = kwargs. get( "position_ids" , None )
if attention_mask is not None and position_ids is None :
position_ids = attention_mask. long ( ) . cumsum( - 1 ) - 1
position_ids. masked_fill_( attention_mask == 0 , 1 )
if past_key_values:
position_ids = position_ids[ : , - 1 ] . unsqueeze( - 1 )
if inputs_embeds is not None and past_key_values is None :
model_inputs = { "inputs_embeds" : inputs_embeds}
else :
model_inputs = { "input_ids" : input_ids}
model_inputs. update(
{
"position_ids" : position_ids,
"past_key_values" : past_key_values,
"use_cache" : kwargs. get( "use_cache" ) ,
"attention_mask" : attention_mask,
}
)
return model_inputs
@staticmethod
def _reorder_cache ( past_key_values, beam_idx) :
reordered_past = ( )
for layer_past in past_key_values:
reordered_past += ( tuple ( past_state. index_select( 0 , beam_idx) for past_state in layer_past) , )
return reordered_past
最后还有 LlamaForSequenceClassification,基础逻辑跟 LlamaForCausalLM 相似

























 512
512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









