






Python Scrapy框架爬取58二手房信息
一、前提条件
需要安装Python3环境,博主为mac电脑,已经安装为Python 3.9.16
二、安装scrapy框架
pip3 install scrapy
三、创建scrapy工程
第一种:scrapy startproject 工程名
第二种:scrapy genspider 爬虫文件名 待爬取的网站域名
四、爬虫需求
爬取58同城北京二手房信息,包房屋标题,房屋布局信息,小区以及小区地址信息房屋总价,单价等信息。(当然,其他城市小伙伴可以调整爬取地址更改城市信息同样可以爬取)
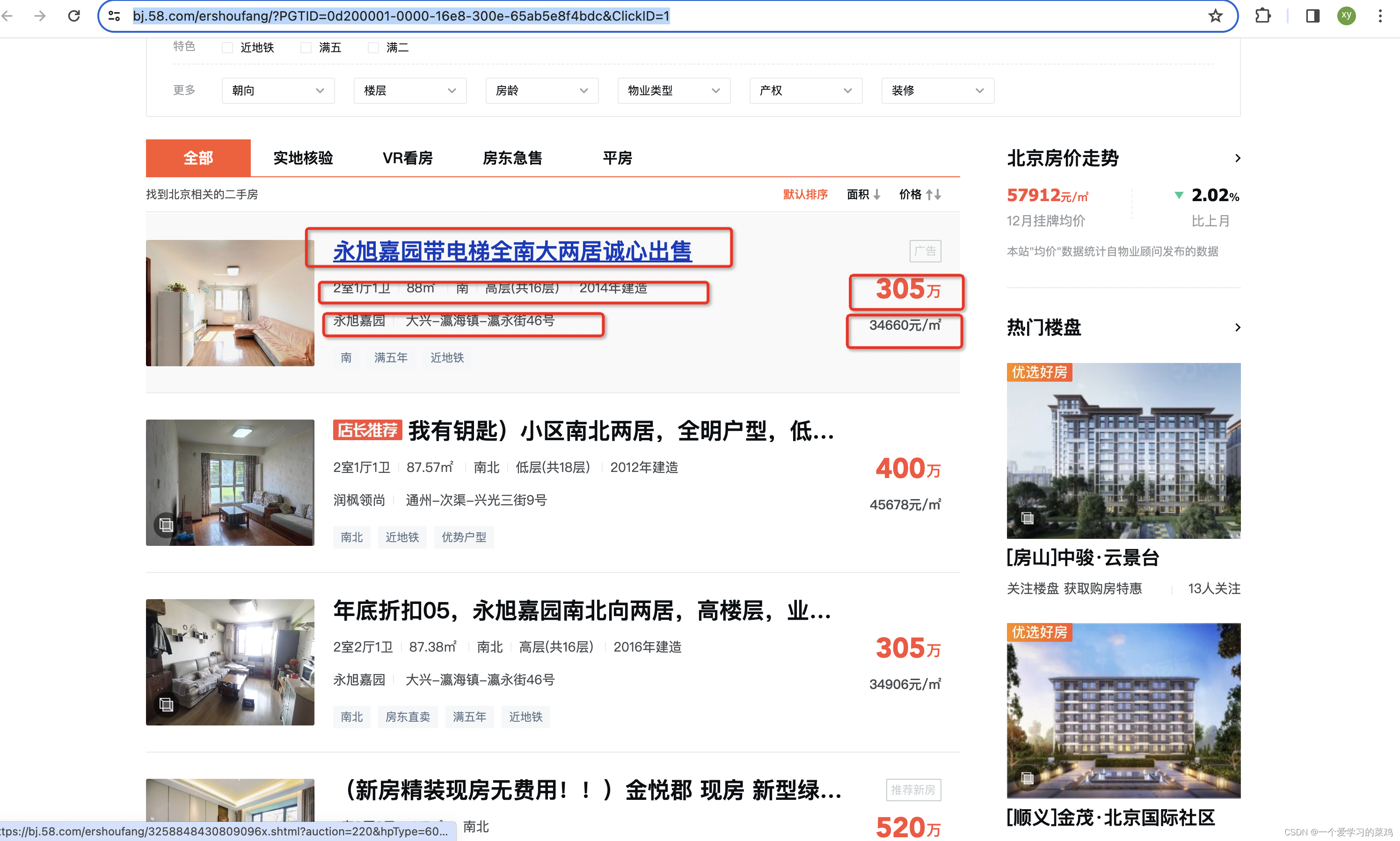
五、scrapy程序内容
first_scrapy # 项目名
first_scrapy # 项目同名文件夹
spiders # 文件夹,存放一个个爬虫
***.py # 其中一个爬虫,重点写代码的地方(解析数据,发起请求)
items.py # 类比 djagno 的 models,表模型(类)
middlewares.py # 中间件,爬虫中间件和下载中间件都在里面
pipelines.py # 管道,做持久化需要在这写代码
settings.py # 配置文件
scrapy.cfg # 上线配置,开发阶段不用
六、爬虫程序
主程序写在spiders下,需要在spiders文件夹下创建文件
本次咱们就写主程序(爬虫主要代码)、items.py、piplines.py和settings.py文件
另外最后还有启动程序start_spd.py
1、settings.py文件
#在settings.py文件中将此行改为False,否则无法爬取
ROBOTSTXT_OBEY = False
2、主程序 spd.py
程序结构,注意每个程序的目录结构
# spd.py
import scrapy
from spider_wuba.items import SpiderWubaItem
class Spd58(scrapy.Spider):
name = 'spd'
start_urls=["https://bj.58.com/majuqiao/ershoufang/?PGTID=0d200001-0000-102d-fdcb-e85191a2e80c&ClickID=7"]
log_counter = 0 # 类变量用于计数
def parse(self, response):
# 房屋信息标题
title = response.css('h3.property-content-title-name::text').getall()
# 房屋价格
price = response.css('span.property-price-total-num::text').getall()
# 通过次属性获取访问信息
property_info = response.css('div.property-content-info')
# 房间信息
room_info_list = property_info.css('p.property-content-info-text.property-content-info-attribute span::text').getall()
room_info = "".join(room_info_list[:6]) # 前六个元素是房屋格局信息
# 朝向信息
area = property_info.css('p.property-content-info-text:nth-child(2)::text').getall()
# 层数信息
orientation = property_info.css('p.property-content-info-text:nth-child(3)::text').getall()
# 朝向信息
floor_info = property_info.css('p.property-content-info-text:nth-child(4)::text').getall()
# 建造年限
build_year = property_info.css('p.property-content-info-text:nth-child(5)::text').getall()
# 地址信息
address = response.css('p.property-content-info-comm-address span::text').getall()
# 循环获取所以需要信息
for i in range(min(len(title), len(price),len(room_info),len(area),len(orientation),len(floor_info),len(build_year),len(address))):
item = SpiderWubaItem()
item["title"] = title[i].strip().replace("'", '"').replace("(", "").replace(")", "").replace(" ", "")
item["price"] = price[i] + "万"
item["room_info"] = room_info.strip()
item["orientation"] = orientation[i]
item["area"] = area[i].strip()
item["floor_info"] = floor_info[i].strip()
item["build_year"] = build_year[i].strip()
item["address"] = '-'.join(address[i:i+3])
self.log_counter += 1 # 每次处理一个item,计数器加1
self.logger.debug(f"Item {self.log_counter}: {item}") # 记录日志
print(item) # 可以打印检查一下每个item是否正确
yield item
# 翻页信息(此翻页信息并不太好使,博主并为找到如何翻页,有懂行的小伙伴欢迎帮忙,谢谢)
next_page = response.css('a.next::attr(href)').get()
if next_page and not next_page.startswith('javascript:'):
yield scrapy.Request(url=next_page, callback=self.parse)
3、items.py 数据结构信息
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class SpiderWubaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
price = scrapy.Field()
room_info = scrapy.Field()
orientation = scrapy.Field()
area = scrapy.Field()
floor_info = scrapy.Field()
build_year = scrapy.Field()
address = scrapy.Field()
# pepo = scrapy.Field()
4、pipeline.py 数据处理入库信息(如不需要入库,测不需要修改此文件内容)
博主使用本地mac中docker跑的mysql8
# 数据库建表语句,需要在你的数据库中进行操作
CREATE TABLE `spd_wuba` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(100) NOT NULL,
`price` varchar(50) DEFAULT NULL,
`room_info` varchar(50) DEFAULT NULL,
`orientation` varchar(50) DEFAULT NULL,
`area` varchar(50) DEFAULT NULL,
`floor_info` varchar(50) DEFAULT NULL,
`build_year` varchar(50) DEFAULT NULL,
`address` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;
from itemadapter import ItemAdapter
import pymysql
class SpiderWubaPipeline:
def open_spider(self, spider):
# 连接mysql
try:
self.db = pymysql.connect(
host='localhost',
user='root',
password='写入自己数据库密码',
database="写入数据库",
charset="utf8"
)
spider.log("Successfully connected to MySQL database.")
except pymysql.Error as e:
spider.log(f"Error connecting to MySQL: {e}")
raise
def close_spider(self, spider):
# 关闭mysql连接
self.db.close()
def process_item(self, item, spider):
mycursor = self.db.cursor()
# 插入语句,使用参数化查询
sql = "INSERT INTO spd_wuba(title,price,room_info,orientation,area,floor_info,build_year,address) VALUES (%s, %s, %s, %s, %s, %s, %s, %s)"
values = (
item["title"],
item["price"],
item["room_info"],
item["orientation"],
item["area"],
item["floor_info"],
item["build_year"],
item["address"]
)
try:
mycursor.execute(sql, values)
self.db.commit()
spider.log(f"Item {item} inserted into database.")
except pymysql.Error as e:
self.db.rollback()
spider.log(f"Error inserting item into database: {e}")
finally:
mycursor.close()
return item
5、运行代码
# 在scrapy.cfg文件平级下创建一个start_spd.py程序,进行启动爬虫框架开始爬虫工作的开关
from scrapy.cmdline import execute
if __name__ == '__main__':
# 将爬取结果输出到wuba.csv中
execute("scrapy crawl spd -o wuba.csv".split(" "))
#如果不需要将结果输出到 wuba.csv则使用下面这行。
# execute("scrapy crawl spd".split(" "))
启动程序点击运行此处

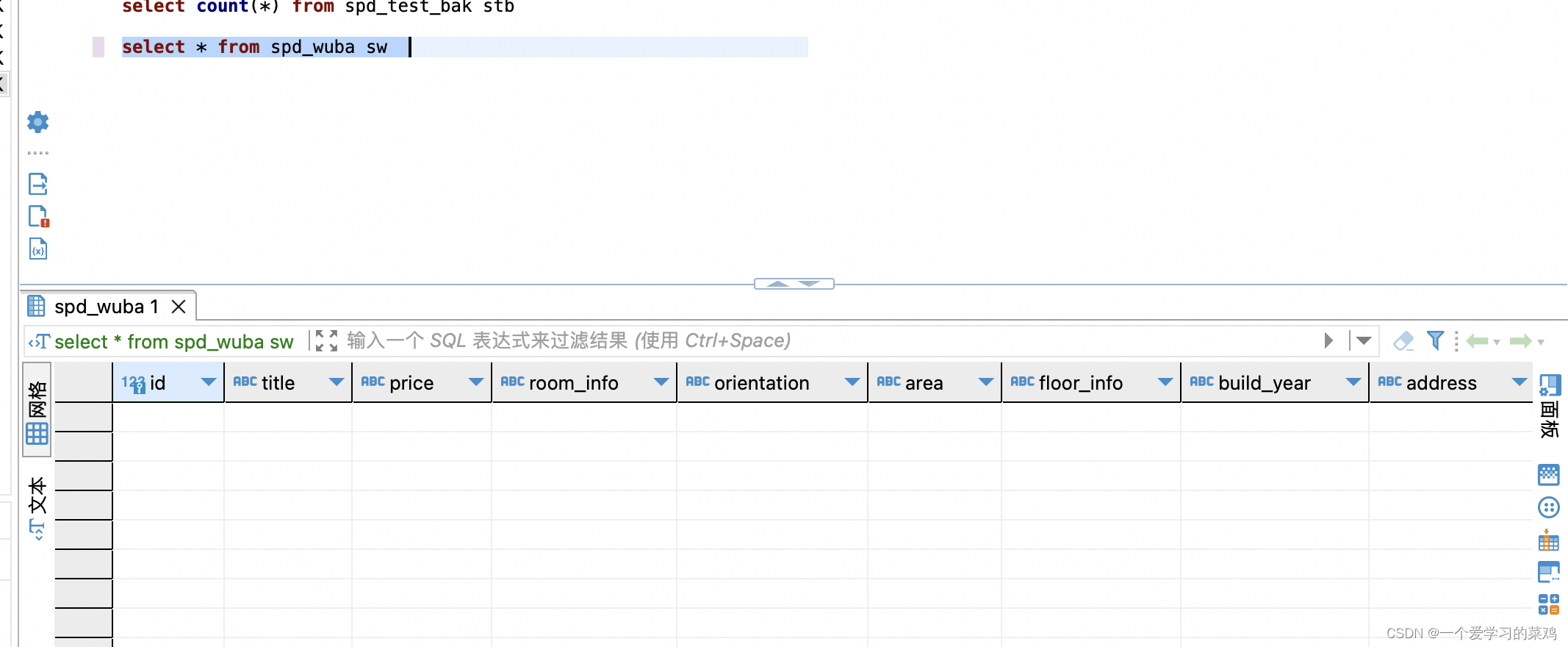
运行程序前查看mysql数据
启动程序后查看mysql数据

这是程序运行日志中数据结构。
{'address': '永兴路7号-丰台-角门',
'area': '128㎡',
'build_year': '2010年建造',
'floor_info': '中层(共12层)',
'orientation': '南北',
'price': '1060万',
'room_info': '3室1厅2卫',
'title': '华纺三居,前后不临街,中楼层,位置好!'}
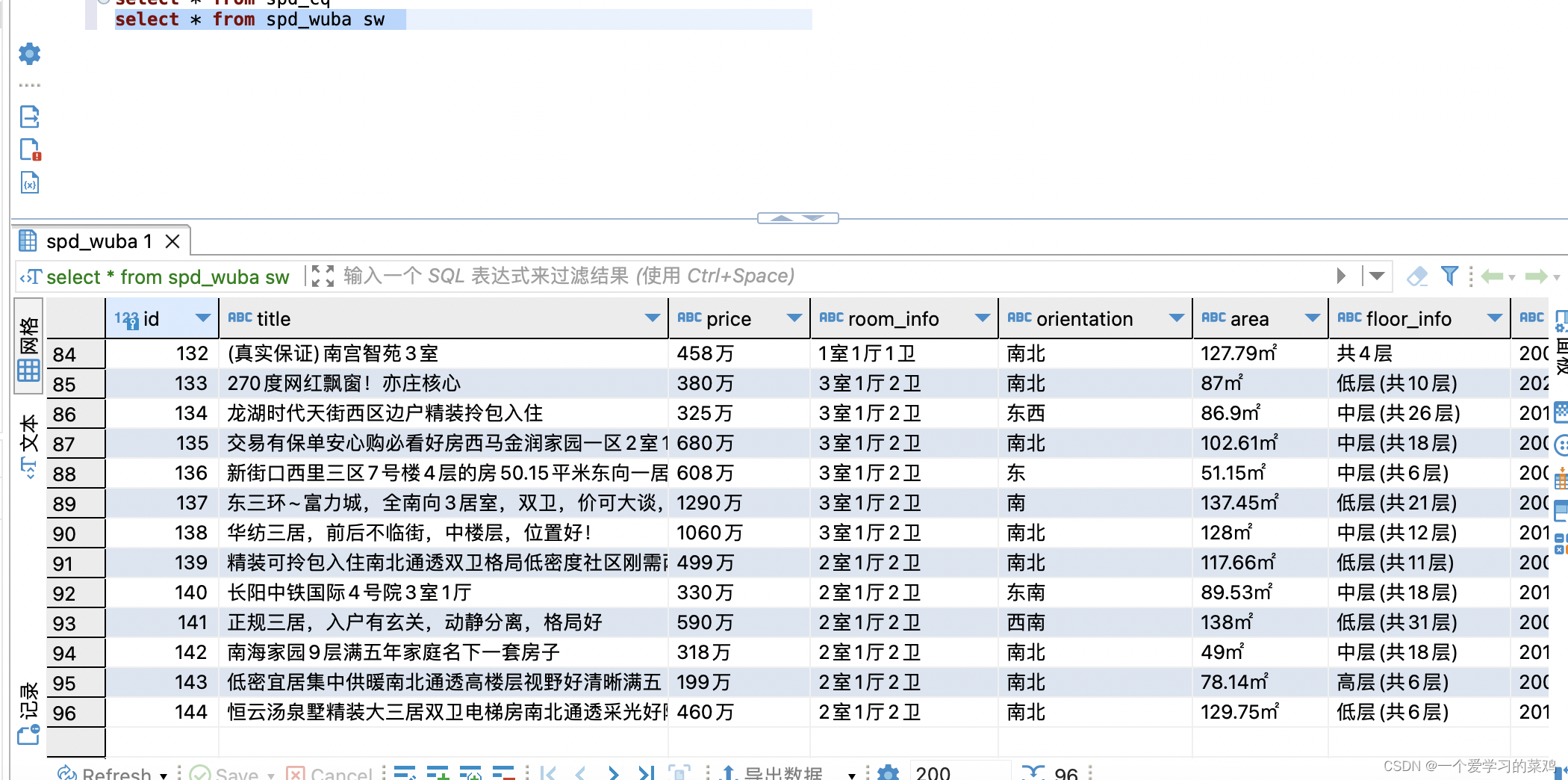
数据已经入库,但是58应该是反爬限制,博主第一次入库错表,入库到spd_cq表中,表中新增数据为差不多300条,但是第二次运行到正确表中就只有90多条。
问题遗留
1、翻页不正常。爬取数据不知是被限制还是为何,爬取数据并不是正常的数据数量。
2、可能会遇到访问频繁验证,此问题还未进行解决,只能手动点击验证。

3、58应该是有反爬,第一次爬取数据为限制接近300条,第二次为90多条。(不知是58的反爬机制,还是博主代码有问题有懂得大佬可以指出来),在setting文件中进行设置过爬取间隔时间和user_agent信息,并没用。
















 3289
3289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









